Open9
AWS Certified Data Engineer - Associate(DEA)受験に向けてメモ
試験内容の確認
試験概要
- 試験時間: 130分
- 問題数: 65問
- 合格スコア: 720 (得点範囲 100〜1,000)
出題範囲と割合
| 分野 | 割合 |
|---|---|
| 第1分野: データの取り込みと変換 | 34% |
| 第2分野: データストア管理 | 26% |
| 第3分野: データ運用とサポート | 22% |
| 第4分野: データセキュリティとガバナンス | 18% |
まずは公式練習問題にチャレンジ
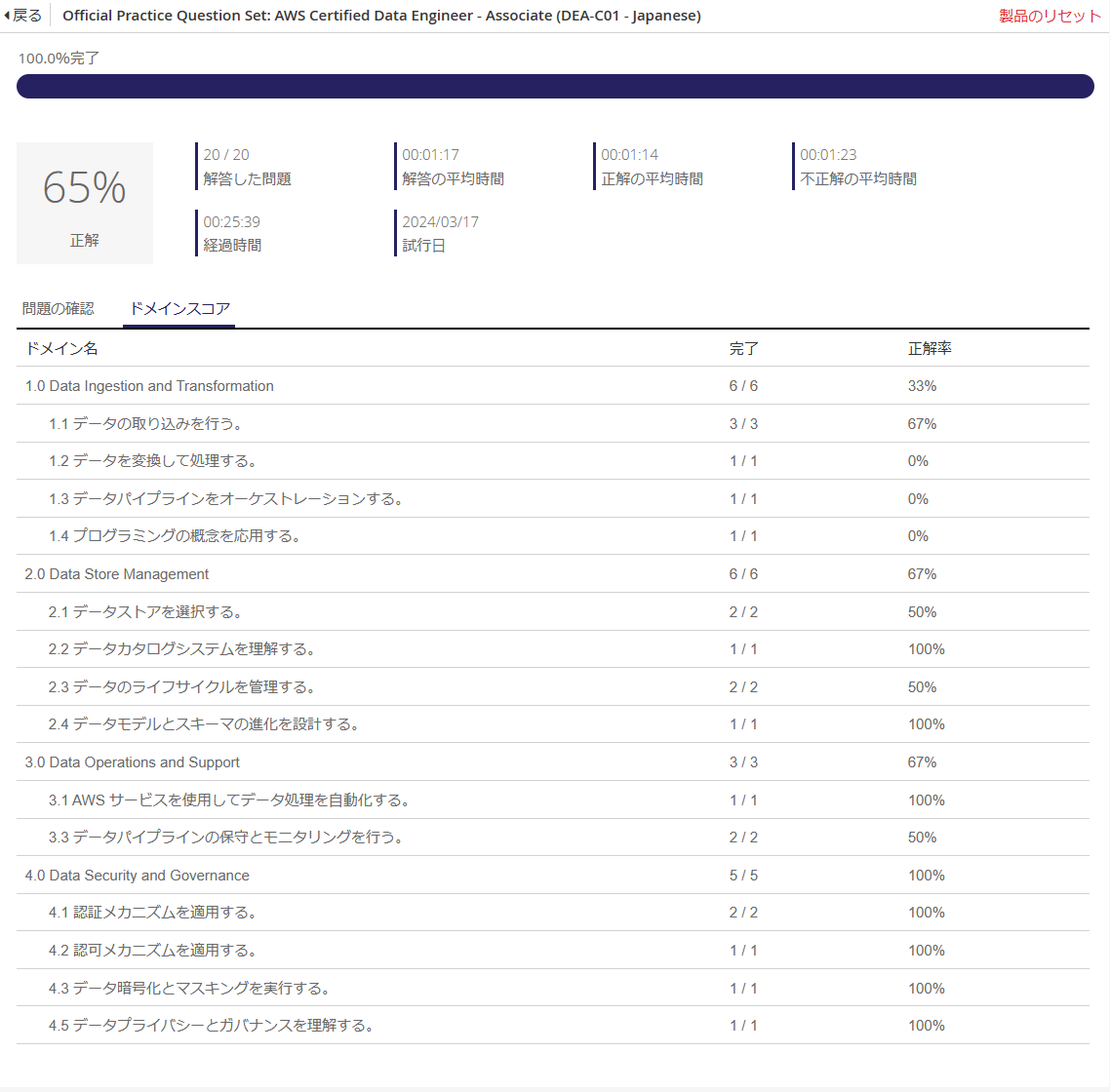
正答率65%で合格ラインには届かず。
Kinesis, Redshift, EKSあたりの正答率が悪い。
Skill Builderの試験準備コンテンツを見る
Fundamentals of Data Analytics on AWS - Part 1
レッスン3 アナリティクス
- 分析(Analysis)と解析(Analytics)は違うよ
- 分析(Analysis)は単一のデータセットを使用して行う分析行為を指す
- 解析(Analytics)は分析行為だけでなくデータの管理から加工、分析、活用などのプロセス全般を指す
- 分析には以下の4つのタイプがあるよ
- 記述的分析(何が起こったか)
- 診断的分析(なぜ起こったか)
- 予測的分析(これから何が起こるか)
- 処方的分析(どう対処すべきか)
(Fundamentals of Data Analytics on AWS - Part 1 続き)
レッスン4 機械学習
- ML(機械学習)ではデータに基づいて予測的分析や処方的分析を行うことができる
- 昨今の膨大なデータを迅速に分析するためにはMLが不可欠
- AWSのAIとMLサービスを使うことで、開発者はMLの専門知識なしにアプリケーションにインテリジェンスを追加できる
- データ抽出と分析の自動化
- 不正なアクティビティの検出
- など
- AWSでMLベースのワークロードを構築できる3つのレベル
- AIサービス
- MLサービス
- MLフレームワークとインフラストラクチャ
- 生成AIは基盤モデル(FM)と呼ばれる膨大なデータ量で事前にトレーニングされたモデルを使用し、入力されたユーザープロンプトに従ってコンテンツを生成する
- AWSのコード生成サービス「CodeWhisperer」を使用することでソフトウェアの開発スピード、セキュリティ、品質を向上することができる
(Fundamentals of Data Analytics on AWS - Part 1 続き)
レッスン5 ビッグデータの5V
ビッグデータには5つの特徴、5Vがある。
- Volume(量)
- 分析基盤が取り込むデータサイズの合計
- Variety(多様性)
- 分析基盤が取り込むデータのソースの数と種類
- Velocity(速度)
- 分析基盤が取り込むデータの入力速度と処理速度(=分析にかけられる時間)
- Veracity(真実性)
- 分析基盤が取り込むデータの正確性
- Value(価値)
- 分析基盤が取り込んだデータから意味のあるデータを抽出する能力
レッスン6 Volume(量)
世界のデータ生成量は増加傾向であり、2025年までに180ゼタバイト以上になると予測されている。
大量のデータを収集するためにスケーラブルで耐久性のあるストレージを扱う必要がある。
大量のデータを処理するには膨大な量のコンピューティングリソースとストレージ容量が必要となる。
扱うデータの種類として3つ挙げられている。
- トランザクションデータ
- 主にDB内に保管されているデータ
- 顧客情報
- 製品購入
- 契約など
- 一時データ
- ブラウザキャッシュ
- オンラインゲームの操作など
- オブジェクト
- いわゆるファイル
- 画像動画、ドキュメント、メールなど
レッスン7 Variety(多様性)
データソースの種類として3つ挙げられている。
- 構造化データ(リレーショナルデータ)
- 決まったスキーマを持つデータ
- リレーショナルデータベースでよく見られる
- 表形式で整理され、列を含む行に格納される
- スキーマが決まっているため分析は容易
- 柔軟性に欠ける。新しいフィールドを追加するためにスキーマ変更が必要で、フィールドが不要なレコードに対しても追加を行う必要がある
- データはリレーショナルデータベースに保存される
- 半構造化データ
- JSON、YAML、CSV、XMLなど
- 構造化データと比べて柔軟であり、フィールドの追加が容易
- 分析が構造化データと比べて難しい。フィールドの予測が困難になる可能性がある。
- データはNoSQLデータベース、Key-Valueストア、ファイルに保存される
- 非構造化データ
- 半構造化データ以外のファイル
- 画像、動画、ドキュメントなど
- 分析するためにタグ付けとカタログ化が必要となる
- ファイルに保存される
レッスン8 Velocity(速度)
データ処理の速度として4つ挙げられている
- スケジュール済み
- 1回/週、1回/日のように決まったタイミングで大量のデータを処理する
- 各処理のデータ量は同じで予測可能
- 定期的
- 一定の時間間隔もしくは一定のデータ収集量ごとに実行されデータを処理する
- たいていの場合はデータ収集量ごとに実行されるため、実行タイミングが予測困難になる
- ほぼリアルタイム
- データ生成から数分以内に実行される
- リアルタイム
- データ生成から数ミリ秒以内に処理される
Veracity(正確性)
正確性とはデータのライフサイクル(作成、集約、保管、アクセス、共有、アーカイブ)それぞれのステージでデータの整合性の確保、つまりデータが正確であることを保証すること。
ETL(抽出、変換、格納)
抽出で計画すべきこと
- ソースの在り処を特定する。オンプレミスなのかオンラインなのか
- 抽出時に既存システムに影響をあたえないようにタイミングを図る
- 処理中のデータ保存場所を決める
- 抽出の頻度を決める
変換
分析しやすい形にデータを置き換える。
NULLをゼロにしたり、男性・女性をM・Fにしたり。
格納
変換したデータを格納する。格納場所はデータベース、データウェアハウス、データレイクなど。
ELT(抽出・格納、変換)
抽出したデータをそのまま格納しておき、分析で利用するシステム側で変換して使う。