Act 24. Pythonでk平均法を試す


はじめに
Act 01. AIで外国為替を自動売買するまでの道のりをベースに学習を進めて行く。
前回はk平均法の概要について学習した。
なので今回は実際にpythonでk平均法を使ったデータのクラスタリングを行う。
データセットが必要になるため、お馴染みのpythonで提供されているデータセットを使用する。と言いたいが、今回に関してはデータセットが提供されていない。
代わりに人工的なデータセットを生成する関数が提供されているため、そちらを使用することに決定。
k平均法
結論
とりあえずコードを載せておく。
from sklearn.datasets import make_blobs, make_moons
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# データセットの生成
blobs_data, blobs_labels = make_blobs(n_samples=300, centers=3, cluster_std=1.0, random_state=42)
moons_data, moons_labels = make_moons(n_samples=300, noise=0.05, random_state=42)
# モデルの構築
kmeans_blobs = KMeans(n_clusters=3, random_state=42).fit(blobs_data)
kmeans_moons = KMeans(n_clusters=3, random_state=42).fit(moons_data)
# プロット
plt.figure(figsize=(12, 5))
# make_blobsデータセット
plt.subplot(1, 2, 1)
plt.scatter(blobs_data[:, 0], blobs_data[:, 1], c=kmeans_blobs.labels_, cmap='viridis', s=50, alpha=0.7)
plt.title("KMeans Clustering on make_blobs")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
# make_moonsデータセット
plt.subplot(1, 2, 2)
plt.scatter(moons_data[:, 0], moons_data[:, 1], c=kmeans_moons.labels_, cmap='viridis', s=50, alpha=0.7)
plt.title("KMeans Clustering on make_moons")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.tight_layout()
plt.show()
出力は以下の通り。
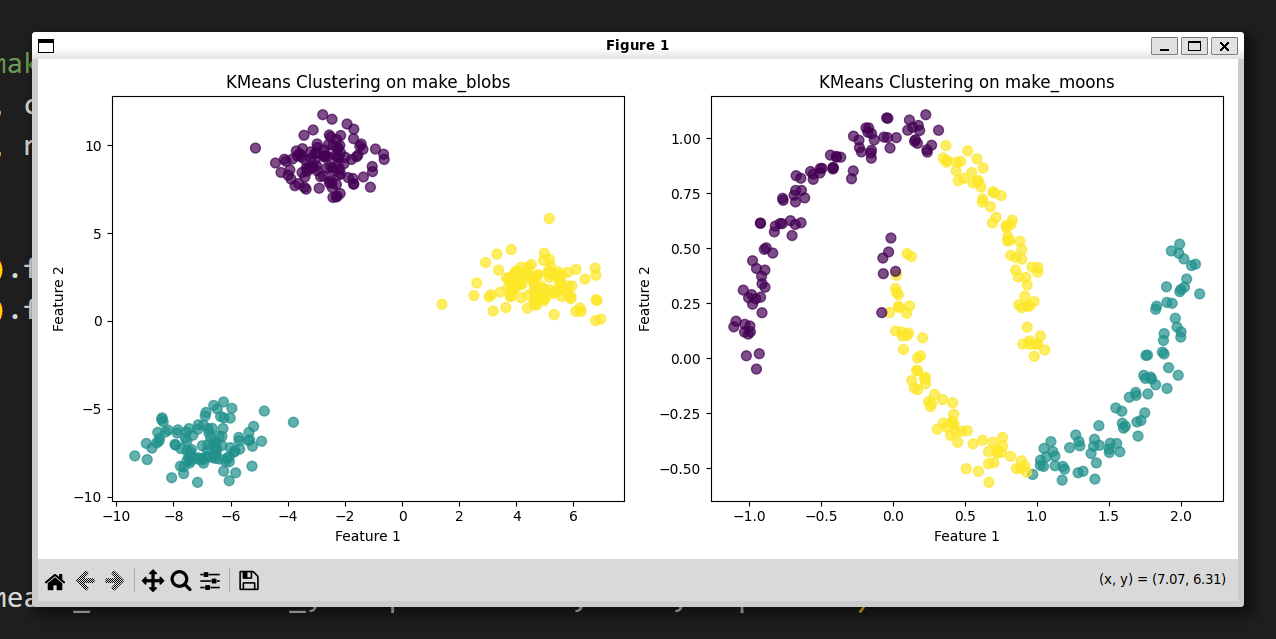
コードの説明
先ほど載せたコードについて、順に説明していく。
データセット
from sklearn.datasets import make_blobs, make_moonsの2つを使用する。
・make_blobsについて
make_blobsは、クラスタリングに適した、単純なデータセットを生成する関数。
データは指定したクラスタを中心にランダムに正規分布するらしい。
それぞれの引数について軽く記載しておく。
-
n_samples: サンプルデータの総数 -
centers: クラスタの数 -
cluster_std: クラスタの広がり具合(ばらつきの標準偏差) -
random_state: 再現性を確保するための乱数シード
返り値は以下の2種類となる。
- 特徴量: 任意の次元数の数値データ
- ラベル: 各点が属するクラスタを示す整数値(例: 0, 1, 2)
・make_moonsについて
make_moonsは半月型の2つのクラスに属するデータを生成する。
クラスの分離が非線形であるため、非線形モデルの動作確認に向いている。
それぞれの引数について軽く記載しておく。
-
n_samples: サンプルデータの総数 -
noise: ノイズ(データのばらつき) -
random_state: 再現性を確保するための乱数シード
返り値は以下の2種類となる。
- 特徴量: 2次元平面上の座標(半月型の曲線に沿う)
- ラベル: 半月型のどちらのクラスに属するか示す整数値(例: 0, 1)
モデルの構築と学習
以下でKMeansクラスを使用して、モデルの構築を行っている。
また、モデル構築のコードと一緒にfit()メソッドを呼び出し、学習も行っている。
kmeans_blobs = KMeans(n_clusters=3, random_state=42).fit(blobs_data)
kmeans_moons = KMeans(n_clusters=3, random_state=42).fit(moons_data)
n_clusters=3を指定することで、何個のクラスタに分類するのかを指定する。
今回はどちらも3つにクラスタリングするように指定している。
また、fit(blobs_data)のように、教師なし学習では入力データのみを渡す。
今までだとfit(X_train, y_train)みたいな感じで引数を渡していたので少し違和感。
今回テスト用のデータが存在していないため、数値を使った評価を行うことは出来ない。
一応評価する方法もあるにはあるが、今回はプロットの内容を見てモデルを評価したということにする。
どのようなやり方があるかだけ、メモとして残しておく。
以下はChatGTPさんの回答。
教師なし学習の評価方法
教師なし学習では、データに正解ラベルが存在しないため、教師あり学習のように「予測結果と正解を比較して評価する」ことはできません。しかし、いくつかの方法でクラスタリングの良さを評価することができます。以下にその手法を簡単に説明します。
-
内部評価指標
- データそのものに基づいてクラスタリングの質を測る方法です。真のラベル(正解)は必要ありません。
- 主な指標:
-
シルエットスコア (Silhouette Score)
クラスタ内のデータの密集度と、他のクラスタからの分離度を測る指標。
値は -1 から 1 の範囲で、1 に近いほど良いクラスタリング。 -
エルボー法 (Elbow Method)
クラスタ数を変化させたときの「クラスタ内誤差和 (Within-Cluster Sum of Squares)」を計算し、クラスタ数の適切なポイントを見つける方法。
-
シルエットスコア (Silhouette Score)
-
外部評価指標
- データに真のラベル(正解)が存在する場合に限り、クラスタリングの結果を正解ラベルと比較します。
- 主な指標:
-
調整ランダム指数 (Adjusted Rand Index, ARI)
クラスタリング結果と正解ラベルの一致度を測る。 -
正規化相互情報量 (Normalized Mutual Information, NMI)
クラスタリング結果と正解ラベルの情報の重なり具合を測る。
-
調整ランダム指数 (Adjusted Rand Index, ARI)
-
視覚的評価
- データを2次元や3次元で可視化し、クラスタリングの分離が直感的に正しいかどうかを確認する方法。
- 特に教師なし学習では、可視化が結果の理解に役立ちます。
なぜ教師なし学習では評価が難しいのか?
- ラベルがないため、「正解」の定義が難しい。
- クラスタリングの結果が現実にどれだけ意味を持つかは、データのドメインや目的次第。
まとめ
- 教師なし学習の評価には「シルエットスコア」などの内部評価指標がよく使われる。
- 真のラベルがある場合は外部評価指標も利用可能。
- 最適なクラスタ数や結果の妥当性を判断するのは、実験的な要素やドメイン知識が関係する場合が多いです。
さいごに
結構雑な記事になってしまったが、k平均法については以上とする。
難しい仕組みのアルゴリズムではないため、また必要になったらしっかり学習しようと思う。
今は何よりも強化学習の勉強がしたい!!!
けど順番は守りたいので、次は主成分分析について学習する。
主成分分析は結構重要そうなのでは?と勝手に思っているので、結構ちゃんと学習するかも。
ではまた。
Discussion