生成AIのファインチューニングに挑戦 19日目
ファインチューニングって何なんでしょ
今回はChatGPTのAPIでファインチューニングを試してみて、回答をコントロールしてみたいと思います。
ファインチューニングとは
公式のホームページを参照するとこんな感じの説明。
ファインチューニング⇒Fine tuning⇒微調整
つまり回答の微調整をする技術、ということですね。
OpenAIのテキスト生成モデルは、膨大な量のテキストに対して事前にトレーニングされています。モデルを効果的に使用するために、プロンプトに指示と場合によってはいくつかの例を含めます。事前の例を基にタスクの実行方法を示すことを「few-shot learning」というらしい。
これはプロンプトに回答例を載せて返答を調整することを指していると思われる。
ファインチューニングとは、プロンプトに収まらないほど多くの例でトレーニングすることで学習を改善し、さまざまなタスクでより良い結果を返答させるようにする。
ファインチューニングは事前に回答訓練をする技術だとも言えます。OKOK、理解した。
ファインチューニングの手順
公式説明だと
- トレーニング データの準備とアップロード
- 微調整された新しいモデルをトレーニングする
- 結果を評価し、必要に応じてステップ 1 に戻ります
- 微調整されたモデルを使用する
実際にやってみる
今回はよく記事で見るCUIではなくて、GUIで試してみます。
1. トレーニング データの準備とアップロード
試したい人がいるかもしれないので投入データはそのまま記載します。
- トレーニングデータ準備(ファイル名:dataset.jsonl)
{"messages": [{"role": "user", "content": "おはようございます。今日はどんな予定がありますか?"}, {"role": "assistant", "content": "おはようございます。本日は会議とプロジェクトの進捗確認があります。"}]}
{"messages": [{"role": "user", "content": "最近おすすめの映画はありますか?"}, {"role": "assistant", "content": "はい、『君の名は。』がおすすめです。ストーリーも映像も素晴らしいですよ。"}]}
{"messages": [{"role": "user", "content": "東京から大阪までの新幹線の料金はいくらですか?"}, {"role": "assistant", "content": "東京から大阪までの新幹線の指定席料金は約14,720円です。"}]}
{"messages": [{"role": "user", "content": "簡単なパスタのレシピを教えてください。"}, {"role": "assistant", "content": "はい、ペペロンチーノはいかがでしょうか。オリーブオイル、ニンニク、唐辛子、塩で作れます。"}]}
{"messages": [{"role": "user", "content": "英語を効率的に勉強する方法は何ですか?"}, {"role": "assistant", "content": "毎日英語で日記を書くことや、英語のポッドキャストを聞くことがおすすめです。"}]}
{"messages": [{"role": "user", "content": "富士山の高さはどれくらいですか?"}, {"role": "assistant", "content": "富士山の高さは3,776メートルです。"}]}
{"messages": [{"role": "user", "content": "次の週末におすすめの旅行先はありますか?"}, {"role": "assistant", "content": "京都はいかがでしょうか。紅葉が美しい季節です。"}]}
{"messages": [{"role": "user", "content": "日本の首都はどこですか?"}, {"role": "assistant", "content": "日本の首都は東京です。"}]}
{"messages": [{"role": "user", "content": "今日のニュースの主な話題を教えてください。"}, {"role": "assistant", "content": "本日は経済対策に関する政府の発表が主なニュースです。"}]}
{"messages": [{"role": "user", "content": "簡単に作れるデザートのレシピはありますか?"}, {"role": "assistant", "content": "はい、フルーツヨーグルトパフェがおすすめです。ヨーグルトとお好みのフルーツを重ねるだけです。"}]}
- Fine-tuning画面へ遷移
https://platform.openai.com/finetune -
fine-tuning jobsを作成

+Createをクリック - Base Modelを選択
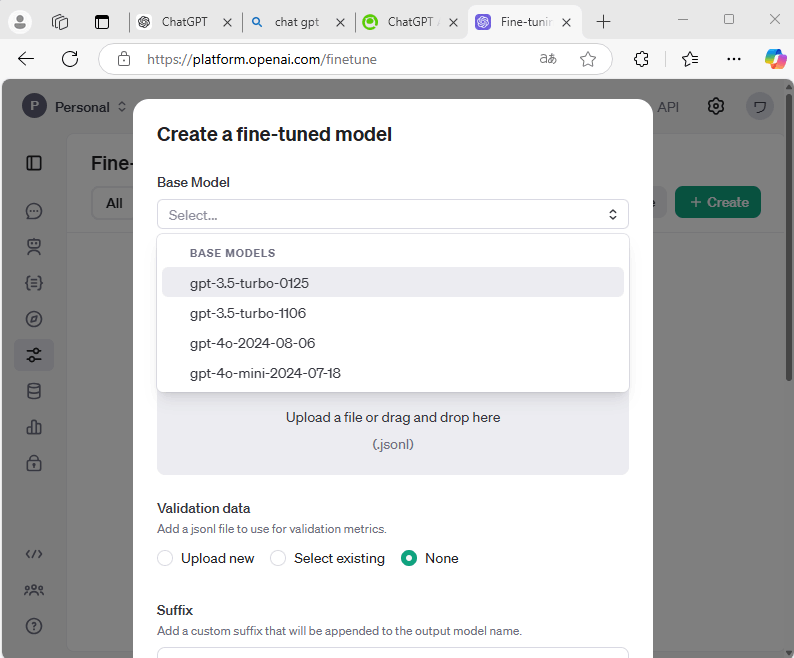
ここでは安価なgpt-3.5-turbo-0125を選択 - トレーニングデータをアップロード

- Validation Datの選択
トレーニングデータの効果を評価するために別の .jsonl ファイルを指定できるけど必須じゃないため、Noneで指定しない

- Suffixの入力
Suffixとは接尾辞で、Model+Suffixでファインチューニングのモデル名になります。ここではtestを入力。

- Seed
トレーニングの再現性を確保したい場合は、固定のシード値(数値)を指定する。ここではRandomのままにします。

- Batch Sizeを指定
トレーニング中の1バッチあたりのデータサイズを指定。自動で設定してくれるautoが推奨とのこと。

- Learning rate multiplierを指定
学習率の調整を行う設定。こちらもautoが推奨されている

- Number of epochsを指定
トレーニングデータ全体を何回学習するかを指定できる。こちらもauto推奨とのこと。

-
Createボタンを押下
ジョブが作成されて、自動で実行を始めます。(投入データ不備でエラーを連発。。。)
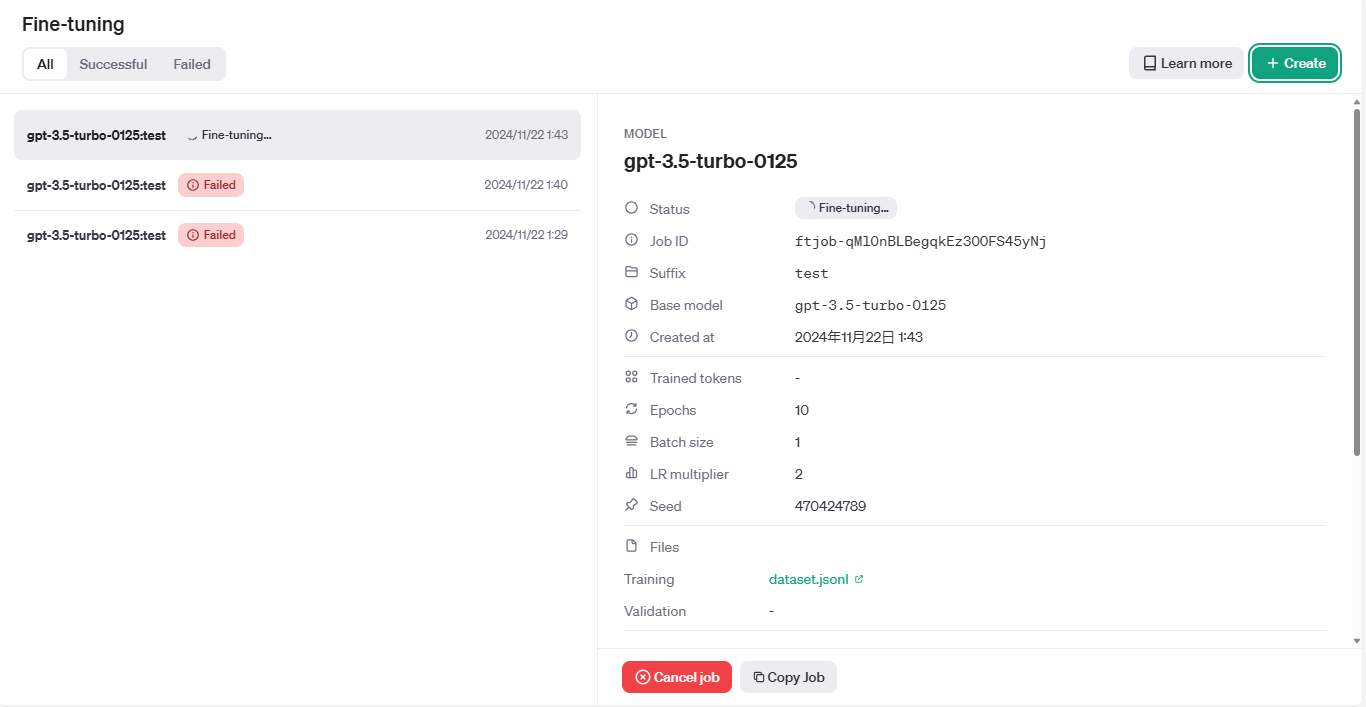
- 祈る(結構時間かかる 10分ちょっと)
無事成功しました。

2. Modelを指定する
実装しているChatアプリの指定モデルを変更します。

3. 動作確認
User: こんにちは
Bot: こんにちは、どうも。何かお手伝いできますか?
ちゃんと動きますね。
User: 東京から大阪までの新幹線の料金はいくらですか?
Bot: 新幹線のひかり号で大人料金は約14,720円です。
User: 最近おすすめの映画はありますか?
Bot: 最近では「君の名は。」が人気ですよ。
トレーニングデータに近い回答をしているので、ある程度は効果があるように思います。
まとめ
ファインチューニングを実行することは簡単でした。しかし、会社で業務利用するなら効果測定する必要があるので、そこをどのようにやるかは考える必要がありそうです。少なくとも期待値にどこまで寄った回答が出来るか、数字は求められると思います。
トレーニングデータを準備するのが面倒、だけどLLMを自分で作るよりは楽。
それが今回の感想です。ただ、うまく訓練できれば生成AIの回答コストも下げられるとも聞いています。
生成AIの大切な技術の一つだと理解しました。
次回は生成AIの回答レベルを向上させる実験実装を記事にしたいと思います。
お読みいただきありがとうございました。
Discussion