🌟
rinnaをdeepspeedとaccelerate使ってlora&並列学習させてみる
はじめに
alpaca-loraのコードを参考にrinnaを学習せるコードを書いてみたけどどうやらそのままでは複数のGPUに1個のモデルを載せてそれぞれのGPUが順番に計算するみたいな挙動になるっぽい。
それだと大きなモデルを学習できるというメリットはあるけど小さいモデルを学習するにはリソースがもったいねぇ!&遅い!ということでrinnaを複数GPUで並列学習するコードを書いてみた。
並列化の手法
hugginfaceのEfficient Training on Multiple GPUsに全部書いてある
並列学習にはAccelerateとDeepSpeedというライブラリを使えば良いらしい。
並列学習の準備
0. 環境
- AWS Ec2 p3.8xlage
- Deep Learning AMI GPU PyTorch 2.0.0 (Amazon Linux 2) 20230406
1. 必要なライブラリのインストール
require.txt
deepspeed
accelerate
transformers
peft
datasets
mpi4py
langchain
2. 学習コード
基本はtransformesのexsampleのpeft_lora_clm_accelerate_ds_zero3_offload.pyを参考にしました
2.1 必要なライブラリ達
train.py
import gc
import os
import sys
import csv
import yaml
import json
import time
import datetime
import numpy as np
import psutil
import torch
import glob
from accelerate import Accelerator
from datasets import load_dataset, Dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
from transformers import AutoModelForCausalLM, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from peft import LoraConfig, TaskType, get_peft_model, PeftModel
from langchain import PromptTemplate
from collections import OrderedDict
2.2 データセット読み込む関数
.txtかjsonのlist
train.py
def read_yaml_file(file_path):
with open(file_path, 'r') as file:
try:
yaml_data = yaml.safe_load(file)
return yaml_data
except yaml.YAMLError as e:
print(f"Error reading YAML file: {e}")
def dir_setup(output_dir,train_config):
try:
os.makedirs(output_dir)
except FileExistsError:
pass
with open(output_dir + "/trian_log.csv", 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["epoch","step","loss","ppl","time"])
with open(output_dir + "/train_config.yaml", "w") as yamlfile:
yaml.dump(train_config,yamlfile,default_flow_style=False)
def read_dataset_files(filename):
if filename.endswith((".json")):
with open(filename, "r") as jsonfile:
dataset = json.load(jsonfile)
#dataset = load_dataset("json", data_files=filename)
elif filename.endswith((".txt")):
dataset = []
with open(filename, 'r') as textfile:
for line in textfile:
text = line.strip()
json_data = {"text": text}
dataset.append(json_data)
return dataset
def load_dataset_files(dataset_path_or_name):
dataset = []
file_list = glob.glob(dataset_path_or_name)
pbar = tqdm(file_list,leave=False)
pbar.set_description("loading files")
for file_name in pbar:
if file_name.endswith((".txt",".json")):
dataset.extend(read_dataset_files(file_name))
if len(dataset) == 0:
print("dataset Not Found!")
return Dataset.from_list(dataset)
2.3 train.config.yamlから設定値読み込み
train.py
def main():
# load config file
train_config = read_yaml_file("train_config.yaml")
with open("prompt_template.json", 'r') as file:
prompt_template = json.load(file)
# common config
lr = float(train_config["parameter_config"]["common"]["lr"])
num_epochs = int(train_config["parameter_config"]["common"]["epoch"])
batch_size = int(train_config["parameter_config"]["common"]["batch_size"])
cutoff_len = int(train_config["parameter_config"]["common"]["cutoff_len"])
output_dir = train_config["directory_config"]["output"]
prompt_type = train_config["prompt_type"]
logging_steps = train_config["logging_steps"]
if "check_point" in train_config["directory_config"]:
check_point = train_config["directory_config"]["check_point"]
else:
check_point = None
# make output dir and log files
dir_setup(output_dir,train_config)
# lora hyperparams
lora = False
if "lora" in train_config["parameter_config"]:
lora = True
lora_r = int(train_config["parameter_config"]["lora"]["r"])
lora_alpha = int(train_config["parameter_config"]["lora"]["alpha"])
lora_dropout = float(train_config["parameter_config"]["lora"]["drop_out"])
lora_target_modules: list[str] =['query_key_value']
peft_config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=lora_target_modules,
lora_dropout=lora_dropout,
bias="none",
task_type="CAUSAL_LM",
)
2.4 tokenizerの設定
train.py
# load tokenizer
tokenizer = AutoTokenizer.from_pretrained(train_config["directory_config"]["model"], use_fast=False)
def tokenize(prompt):
result = tokenizer(
prompt,
truncation=True,
max_length=cutoff_len,
padding="max_length",
return_tensors="pt"
)
result["labels"] = result["input_ids"]
return result
def collate_fn(examples):
return tokenizer.pad(examples,max_length=cutoff_len, padding="max_length",return_tensors="pt")
2.5 設定確認
train.py
# load accelerater
accelerator = Accelerator()
# check config
if accelerator.is_local_main_process:
accelerator.print("\n####################### train config #######################\n")
for key in train_config.keys():
if key == "directory_config" or key == "parameter_config":
for key2 in train_config[key].keys():
accelerator.print("{} : {}".format(key2,train_config[key][key2]))
else:
accelerator.print("{} : {}".format(key,train_config[key]))
accelerator.print("vocab sizse : " + str(len(tokenizer)))
accelerator.print("lora : " + str(lora))
accelerator.print("check_point : " + str(check_point))
accelerator.print("\n##############################################################\n")
2.6 データセット前処理
train.py
# dataset preprocces
def generate_and_tokenize_prompt(data_point):
prompt = PromptTemplate(
input_variables=prompt_template[prompt_type]["train"]["input_variables"],
template=prompt_template[prompt_type]["train"]["template"],
)
train_prompt = []
if prompt_type == "text":
for i in range(len(data_point["text"])):
train_prompt.append(prompt.format(text=data_point["text"][i]))
elif prompt_type == "jsquad":
for i in range(len(data_point["text"])):
train_prompt.append(prompt.format(text=data_point["text"][i],question=data_point["question"][i],answer=data_point["answer"][i]))
elif prompt_type == "wrap-up":
for i in range(len(data_point["text"])):
train_prompt.append(prompt.format(text=data_point["text"][i],wrap_up=data_point["wrap-up"][i]))
elif prompt_type == "QA-generation":
for i in range(len(data_point["text"])):
train_prompt.append(prompt.format(text=data_point["text"][i],answer=data_point["answer"][i],question=data_point["question"][i]))
tokenized_train_prompt = tokenize(train_prompt)
return tokenized_train_prompt
dataset = load_dataset_files(train_config["directory_config"]["dataset"])
if train_config["sample"] < 1:
dataset = dataset.train_test_split(train_size=train_config["sample"])
dataset = dataset["train"]
if accelerator.is_local_main_process:
print(dataset)
with accelerator.main_process_first():
processed_datasets = dataset.shuffle().map(
generate_and_tokenize_prompt,
batched=True,
batch_size = batch_size,
num_proc=1,
remove_columns=dataset.column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
accelerator.wait_for_everyone()
train_dataset = processed_datasets
train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=collate_fn, batch_size=batch_size, pin_memory=True)
2.7 モデル、optimizer、scheduler設定
ここで model, dataloader, optimizer, schedulerをaccelerator.prepareに渡すことで並列学習ができるようになる
train.py
# creating model
model = AutoModelForCausalLM.from_pretrained(
train_config["directory_config"]["model"],
torch_dtype=torch.float16,
)
if check_point:
accelerator.load_state(check_point)
if lora:
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# optimizer
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
# lr scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
model, train_dataloader, optimizer, lr_scheduler = accelerator.prepare(
model, train_dataloader, optimizer, lr_scheduler
)
accelerator.print(model)
# check deepspeed zero
is_ds_zero_3 = False
if getattr(accelerator.state, "deepspeed_plugin", None):
is_ds_zero_3 = accelerator.state.deepspeed_plugin.zero_stage == 3
2.8 学習
train.py
if accelerator.is_local_main_process:
with open(output_dir+"/trian_log.csv", 'a', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([0,0,0,0,datetime.datetime.now()])
# train procces
total_step = 0
for epoch in range(1,num_epochs+1):
model.train()
total_loss = 0
step_loss_avg = 0
step_loss = 0
pbar = tqdm(train_dataloader)
pbar.set_description(f'[Epoch {epoch}/{num_epochs}]')
for step, batch in enumerate(pbar):
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
step_loss += loss.detach().float()
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
if accelerator.is_local_main_process:
if step % logging_steps == 0 and total_step != 0:
step_loss_avg = step_loss/logging_steps
step_ppl = torch.exp(step_loss_avg)
with open(output_dir+"/trian_log.csv", 'a', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([epoch,total_step,round(step_loss_avg.item(),3),round(step_ppl.item(),3),datetime.datetime.now()])
step_loss = 0
total_step += 1
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
accelerator.print(f"{epoch=}: {train_ppl=} {train_epoch_loss=}")
2.9 チェックポイント保存
train.py
# save checkpoint
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir+"/checkpoint-{}".format(epoch), save_function=accelerator.save, state_dict=accelerator.get_state_dict(model))
if lora == True:
accelerator.save_state(output_dir=output_dir+"/checkpoint-{}".format(epoch))
else:
tokenizer.save_pretrained(output_dir+"/checkpoint-{}".format(epoch))
設定ファイル
train_config.yaml
directory_config:
model: /home/llm/model/rinna/japanese-gpt-neox-3.6b
dataset: #使いたいデータセットのディレクトリをglob形式で
output: #outputディレクトリ
#check_point: 学習を続きから始めるときのcheckpoint(loraのみ)
parameter_config:
common:
lr: 3e-4
epoch: 5
batch_size: 2
cutoff_len: 256
lora:
r: 8
alpha: 16
drop_out: 0.05
prompt_type: text
logging_steps: 10
sample: 1 #データセットから実際に学習に使うサンプルの割合 0~1
prompt_template.json
{
"jsquad": {
"train": {
"input_variables": [
"text",
"question",
"answer"
],
"template": "文章を読み問題に答えなさい\n###文章:{text}\n###問題:{question}\n###回答:{answer}"
},
"inf": {
"input_variables": [
"input",
"instruction"
],
"template": "文章を読み問題に答えなさい\n###文章:{text}\n###問題:{question}\n###回答":
}
},
"text": {
"train": {
"input_variables": [
"text"
],
"template": "{text}"
},
"inf": {
"input_variables": [
"text"
],
"template": "{text}"
}
},
"wrap-up": {
"train": {
"input_variables": [
"text",
"wrap_up"
],
"template": "以下の文章を要約\n###文章:{text}\n###要約:{wrap_up}"
},
"inf": {
"input_variables": [
"text"
],
"template": "以下の文章を要約\n###文章:{text}\n###要約:"
}
},
"QA-generation": {
"train": {
"input_variables": [
"text",
"answer",
"question"
],
"template": "以下の文章から問題を作成\n###文章:{text}\n###回答:{answer}###問題:{question}"
},
"inf": {
"input_variables": [
"text"
],
"template": "以下の文章から問題を作成\n###文章:{text}\n###回答:"
}
}
}
3. accelerateの設定
環境とか使うモデルに応じてお好みで
deepspeedはモデルがGPU単体に乗り切ればoff乗らなければonにする
$ accelerate config
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
In which compute environment are you running?
This machine
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]: 1
Do you wish to optimize your script with torch dynamo?[yes/NO]:no
Do you want to use DeepSpeed? [yes/NO]: no
Do you want to use FullyShardedDataParallel? [yes/NO]: no
Do you want to use Megatron-LM ? [yes/NO]: no
How many GPU(s) should be used for distributed training? [1]:no
Please enter an integer.
How many GPU(s) should be used for distributed training? [1]:4
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Do you wish to use FP16 or BF16 (mixed precision)?
bf16
accelerate configuration saved at /home/gptapp/.cache/huggingface/accelerate/default_config.yaml
学習
$ accelerate launch train.py
あとは待つだけ
終わったらoutputdirにcheckpointとログファイルが出力される
今回はGPU4台の4並列にしたので学習時間も大体1/4
ただdeepspeedを使ってRAMにoffloadとかするとI/Oのオーバーヘッドがあるのでもう少し遅くなる
要約FT
GPT3.5にwikiから抜き出した500~1200文字の文章を300文字に要約させたサンプルを1000件ほど用意してrinna-baseを要約FTしてみた
学習前

学習後
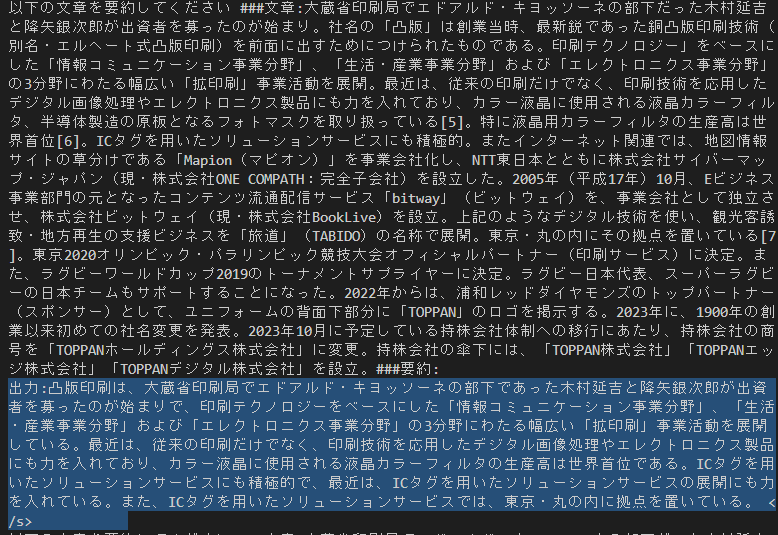
完璧ではないけどまあまあいいんじゃない?
Discussion