【株式投資】機械学習を用いた株価の騰落予測とバックテスト



✅目的
- 機械学習ライブラリを使用して株式投資のストラテジの立て方について紹介します。
- 今回は
XGBoostを使用した2値分類による株価の騰落予想を実施し、バックテストを行います。 - バックテストの結果は
単純移動平均およびロングオンリーストラテジの収益率と比べて有効なのかを確認します。 - また、機械学習で分類をおこなったときに使用する評価指標である
混合行列についてまとめます。 - ストラテジを立てる過程、バックテストについては実際にGoogle Colaboratoryで実施し手法を公開しています。
- 最終的な投資判断は自己責任となりますのでよろしくお願いします。
- 最大限注意をして、この記事を作成していますが、誤りがありましたらご指摘いただけると幸いです。
📃XGBoostについて
-
XGBoost(eXtreme Gradient Boosting)とは決定木系の機械学習アルゴリズムです。 - 決定木とはデータの特性をもとに階層的に再起分割を行い判断ツリーを作成し判断を行う機械学習アルゴリズムです。
- 決定木は過学習を起こしやすいという弱点があります。
- XGBoostは複数の弱学習機を作成し組み合わせる
アンサンブル学習の手法の一つであるブースティングを行い過学習しやすいという弱点を補っています。 - XGBoostは強力なアルゴリズムで過去にKaggleなどのコンペで多くの賞を獲得したという話をよく聞きます。
📃評価について
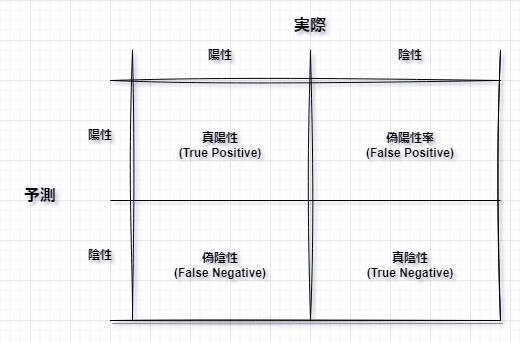
混合行列
-
混合行列とは分類モデルの性能を評価するための表形式の行列です。 - 2値分類および多クラス分類の評価に使用しますが、今回はわかりやすく2値分類を例に記載します。
- 2値分類を評価する場合、パターン分けをすると以下4つに分かれます。
-
真陽性(True Positive, TP):陽性と判断し正解した数 -
真陰性(True Negative, TN):陰性と判断し正解した数 -
偽陽性(False Positive, FP):陽性と判断し不正解した数、陽性と判断し実際は陰性だった数 -
偽陰性(False Negative, FN):陰性と判断し不正解した数、陰性と判断し実際は陰性だった数
-
- 上記を表にまとめると以下のようになります。これが
混合行列です。
💬 混合行列を使うメリットについて
混合行列を使うメリットは以下が考えられます。
-
混合行列を用いることで分類機の判断の偏りに気付ける。
機械学習による分類機を作成しているとすべて陰性/陽性と判断する分類機が生まれることがあります。
このような場合に混合行列を使うことで分類機の問題に気付くことができます。 -
評価指標を計算できる。
用途や目標にあわせて以下評価指標を計算することができます。
正解率(Accuracy)
- すべての予測のうち正解した予測の割合
- 仮に株価の値上がり回数が99日/100日で、値下がり回数が1日/100日だった場合を想定します。
- 100日すべて値上がりすると判定した場合、正解率が99%と驚異的な正答率になりますが、値下がり見逃し率が100%となってしまいます。
- そのため、正解率だけで判定すると見逃しや誤検出を評価することができません。
適合率(Precision)
- 陽性と予測して、実際に陽性であった割合です。
- 予測した値の中でどの程度正解したかを確認する指標のため、ある程度の見落としを容認し誤検出を少なくしたい場合に使用されます。
再現率(Recall, True Positive Rate)
- 実際の陽性のうち、正しく陽性と予測できた割合
- 実際の陽性のうちでどの程度漏れがないかを確認する指標のため、不良品の検出など見落としを減らしたい場合に使用されます。
F値(F1-measure)
- 適合率と再現率の調和平均です。
- どちらの指標を使ったらよいかわからない時に使用されるようです。
- F1値で判定を行った場合、調和平均のためデータの不均衡に気付きづらいなどの欠点があります。
偽陽性率(False Positive Rate)
- 実際の陽性のうち、誤って陰性と陽性と予測した割合、誤検出率です。
- 小さければ小さいほど良い値になります。
📃処理の流れ
今回は当日の株価をもとに翌日の株価が値上がりするか値下がりするかを予測する教師あり学習を行います。
- yfinanceライブラリを使用してS&P500の株価を取得します。
- 対数収益率を計算しヒストグラムで分布を確認します。
- 対数収益率をもとに値上がりしたら
1を値下がりしたら0をラベル付けし正解ラベルを用意します。 - 取得した株価をトレーニング用データとテスト用データに分離します。
-
グリッドサーチを行い最適なパラメータを探索します。 - 最適と思われるパラメータをもとに
XGBoostで学習を行います。 - 学習したモデルをもとに予測を行います。
-
混合行列とROC曲線を確認します。 -
対数収益率合計を計算し当該モデルをもとに売買した場合とロングオンリーを比較します。
🐍Pythonで実行してみる
実行はGoogle Colaboratoryを使用しました。
全処理内容は以下を参照してください。
実装解説
「処理の流れ」の項番1:株価の取得および項番9:ロングオンリーとの比較に関しては
過去の記事で行った内容と同じため割愛します。以下をご参照ください。
2. ヒストグラムで分布を確認
以下、ヒストグラムによる収益率の分布の確認をしています。
# ヒストグラムを表示
sp500_master['return'].hist(bins=40)
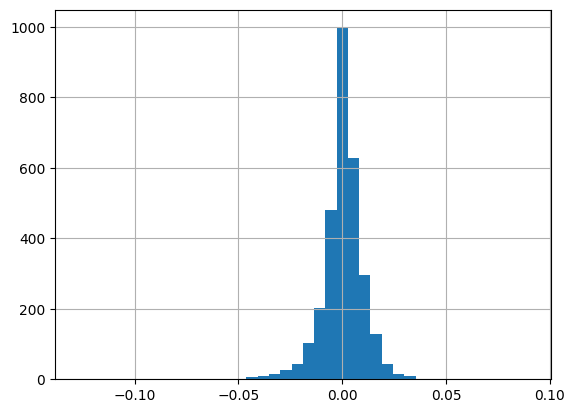
- ボラティリティの激しい異常な状態の株価を除き、基本的には株価のヒストグラムはベルカーブを描くことが多いです。
- このベルカーブの分布を
正規分布やガウス分布と呼んだりします。 - ランダムな値から生成された分布は
正規分布となるため株価がランダムであると言われる所以はここにあります。 - ただし、株価をよく見ると正確な左右対称ではなく+側に若干分布が偏っています。
- これは、株価が値下がり時は0で止まるのに対して値上がり時は青天井であるためと言われています。
3. 正解ラベルの用意
- 前日の各種説明変数が翌日の騰落に影響すると仮定しています。
- 対数収益率を計算し、収益が
+であれば1を-であれば0をy列に代入しています。
# 対数収益率を計算
sp500_master['return'] = np.log(sp500_master['Close']/sp500_master['Close'].shift(1))
# 前日の各種値が翌日の終値に影響すると仮定する。
# そのため目的変数yには翌日の騰落を表すフラグを代入する。
sp500_master['y'] = np.where(sp500_master['return'] > 0, 1, 0)
sp500_master['y'] = sp500_master['y'].shift(-1)
# 確認のため騰落額もシフトする行を加える。
sp500_master['return-yest'] = sp500_master['return'].shift(-1)
4. 取得した株価をトレーニング用データとテスト用データに分離
-
トレーニングデータとテストデータの比率は本来7:3程度が良いのですが
前回のテクニカル分析の結果と比較するため2023年の1年間をテスト用データとして分離します。 -
データの大きさのばらつきを整えるために
MinMaxScalerで正規化します。
sc = MinMaxScaler()
data_train = sp500_droped[sp500_droped.index < '2023-01-01']
data_test = sp500_droped[sp500_droped.index >= '2023-01-01']
X_train = data_train.loc[:,['Open','High', 'Low', 'Close', 'Volume', 'return']]
X_train = sc.fit_transform(X_train)
y_train = data_train.loc[:,'y'].values
X_test = data_test.loc[:, ['Open','High', 'Low', 'Close', 'Volume', 'return']]
X_test = sc.fit_transform(X_test)
y_test = data_test.loc[:,'y'].values
5. グリッドサーチを行い最適なパラメータを探索
param_grid = {
'max_depth': [6, 7, 8],
'learning_rate': [0.5, 0.3, 0.1],
'n_estimators': [17,18,19],
'reg_alpha': [0.25, 0.3, 0.35],
'reg_lambda': [0.45, 0.5, 0.55],
}
model = xgb.XGBClassifier(objective="binary:logistic", eval_metric='auc')
grid_search = GridSearchCV(estimator=model, scoring="precision", param_grid=param_grid, cv=None)
grid_search.fit(X_train, y_train)
# 最適なハイパーパラメータを取得
best_params = grid_search.best_params_
print(grid_search.best_score_)
print("Best Hyperparameters:", best_params)
6. 最適と思われるパラメータをもとにXGBoostで学習
eval_set=[(X_train, y_train), (X_test, y_test)]
### グリッドサーチで見つけたパラメータを使用する場合
model = xgb.XGBClassifier(**best_params)
### グリッドサーチしたパラメータを使用しない場合
# model = xgb.XGBClassifier()
model.fit(X_train, y_train, eval_set=eval_set, eval_metric='auc', early_stopping_rounds=3)
7. 学習したモデルをもとに予測
pred = model.predict(X_test)
8. 混合行列とROC曲線を確認
混合行列表示
cm = confusion_matrix(y_test, pred)
sns.heatmap(cm, annot=True, fmt='d')
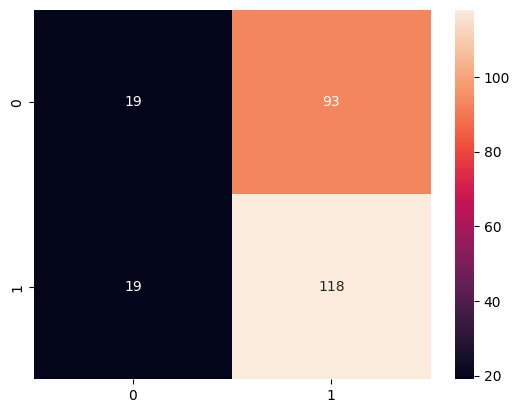
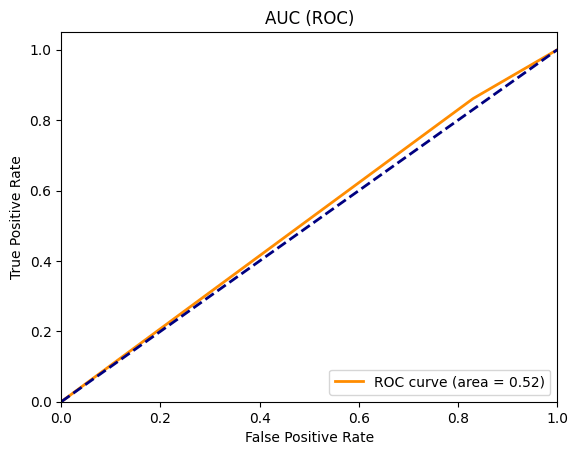
ROC曲線を確認
- ROC曲線はX軸に
False Positive RateをY軸にTrue Positive Rateをとっています。 - 下面のAUC面積が1に近いほど良いモデルと言われています。
- 今回はちょっと微妙な感じです。しっかり判定できているとは言い難いですが、若干は判定できているというところでしょうか。。。
fpr, tpr, thresholds = roc_curve(y_test, pred)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()
📃バックテストと結果比較
単純移動平均との収益率比較
厳密な比較ではないのですが、過去私が調査した2023年のSP500の単純移動平均の収益率と
当該、機械学習の収益率を比較してみます。
XGBoostによる判断で2023年売買した場合の対数収益率合計

単純移動平均での収益率の合計は1.006958%だったため厳密な比較ではありませんがXGBoostをもとに売買したほうが収益率が良いように見えます。
また、判定指標を増やす。厳密なパラメータチューニングを行うなどでさらなる勝率アップも望めると思います。
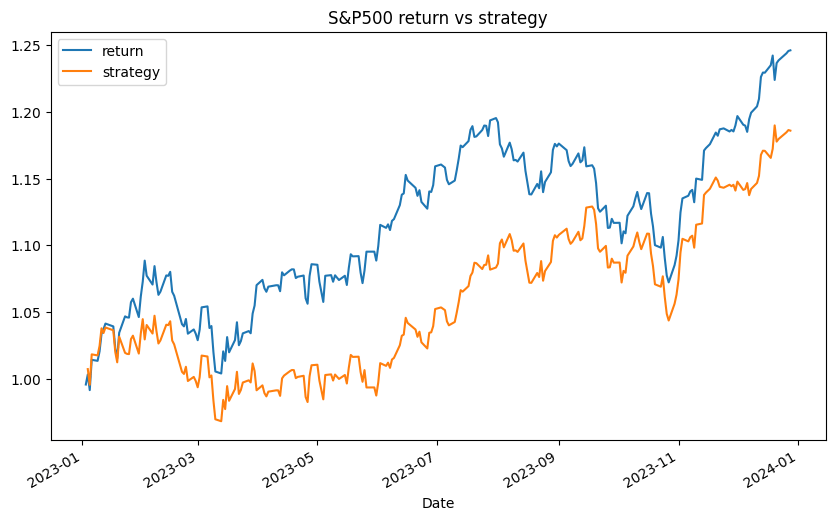
ロングオンリーの場合との比較
-
returnはロングオンリーの対数収益率合計です。strategyはXGBoostを使用した売買の対数収益率合計です。 - こちらは、移動平均と同じくやはり売買を繰り返さずロングオンリー戦術のほうが勝率が高いです。
- 個人投資家がちょっと機械学習を勉強したくらいで爆益を出せるほど市場は甘くないということがわかります。。。
📃まとめ
- 機械学習アルゴリズム(XGBoost)を使用しての騰落予測の方法について紹介しました。
- また、グリッドサーチによるパラメータの探索方法と分類機の性能判定方法について紹介しました。
- 機械学習アルゴリズムを使用しての投資判断は絶大な効果を発揮するわけではないが、
移動平均による売買より収益率が良いため無意味でもないということを確認しました。 - ただ、右肩上がりのトレンドを持つS&P500のような株式は無駄に売買するより放置がやはりパフォーマンスが良いようです。
- 説明変数への先行指標の追加や細かなパラメータチューニングにより性能をあげられる可能性もありそうです。
📃参考文献
Andreas C.Muller.Sarah Guido.Pythonではじめる機械学習(scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎).オライリー・ジャパン
Yves Hilpisch.Pythonからはじめるアルゴリズムトレード(自動売買の基礎と機械学習の本格導入に向けたPythonプログラミング).オライリー・ジャパン
Discussion