【新NISAに備えよう!】Pythonで最適な投資信託ポートフォリオを調べてみた
✅目的
- Pythonを使って現代ポートフォリオ理論の計算をします。
- 現代ポートフォリオ理論を利用することでリスクを最小化し、リターンを最大化する投資比率を調べることができます。
- 今回は投資信託の過去の価格変動をもとに、リスクとリターンを計算し最適なポートフォリオ比率を求めます。
- 今回求めるのはあくまで数学的な将来予想の結果であり、収益を保証するものではありません。
- 最終的な投資判断は自己責任となりますのでよろしくお願いします。
- 最大限注意をして、この記事を作成していますが、誤りがありましたらご指摘いただけると幸いです。
📃現代ポートフォリオ理論とは
- 1950年代にハリー・マーコビッツにより構築された分散投資の基礎理論です。
- 彼はこの業績により1990年にノーベル経済学賞を受賞しています。
- かねてよりアノマリーとして言われていた分散投資の有効性を数学的に証明した理論です。
- ポートフォリオ全体の価格変動リスクは、
組み込み銘柄の個別価格変動リスク、組み入れ比率に加えて相関係数により決まることが示されました。 - ただし、〇〇ショック発生時はあらゆる銘柄が値下がりし過去の値動きの相関が崩れるため
理論の限界を示す指摘もあります。
📃効率的フロンティアとは
-
あるリスク水準で最大のリターンを獲得できるポートフォリオの集合のことです。 - 以下、リスクをX軸にリターンをY軸にとり、各投資比率がそれぞれどこにあたるかをプロットした図です。
- あたりまえですが投資家はリスクをおさえてリターンを最大化したいためポートフォリオ集合の上部ラインの比率を狙う必要があります。
- この上部ラインの投資比率を効率的フロンティアと呼びます。
- 今回は実際の計算結果をもとにポートフォリオの形を確認できるグラフを表示する実装をします。

📃シャープレシオとは
- シャープレシオとは、ウィリアム・シャープにより提案されたリスクあたりの超過リターンを図る指標です。
- 数値が高いほど運用効率がよいことを意味します。
- 今回はシャープレシオを計算しどの比率の運用が効率的かを判断できるようにします。
📃計算の流れ
今回、実施する計算処理の流れは以下となります。
- 投資信託の過去の価格情報CSVを取得する。
- 取得したCSVを各銘柄ごとにデータフレームにまとめる。
- 各銘柄ごとの期待収益率を求める。
- 各銘柄ごとの共分散を求める。
- 銘柄ごとの投資比率のパターンをランダム値をもとに生成する。
- 各銘柄の投資比率と期待収益率をもとに複数銘柄を組み合わせた場合の予想リターンを計算する。
- 各銘柄の投資比率と分散をもとに複数銘柄を組み合わせた場合の予想リスクを計算する。
- 予想リスクと予想リターンをもとにシャープレシオを計算する。
- リスクとリターンをグラフにプロットし効率的なフロンティアを目視で確認する。
- リスク/リターン/シャープレシオなどを表として一覧表示し、どの銘柄比率が投資家にとって効率的かを確認する。
🐍 pythonで計算してみる
計算にはGoogle Colaboratoryを使用しました。
全処理内容は以下を参照してください。
実行方法と実装解説
1. 投資信託の過去の価格情報CSVを取得する。
Seleniumの実行について
過去の値動きのCSVデータ取得はSeleniumで実行しています。
ただ、Google ColaboratoryでSeleniumを動かそうとすると事前の設定処理を実装する必要があります。
その設定については以下を参照ください。
CSVのダウンロード処理について
## WEALTH ADVISORの投資信託ID
# ポートフォリオに組み入れたい投資信託のIDを指定
TRUST_IDS = ['2018103105', '2017022702','201707310D']
FUND_DICT = {}
shutil.rmtree(download_path)
#urlの指定
for trust_id in TRUST_IDS:
url="https://www.wealthadvisor.co.jp/FundData/Download.do?fnc=" + trust_id
driver.get(url)
fundname = driver.find_element(By.XPATH, '//div[@class="fundnamea"]/h1').text
FUND_DICT.update({trust_id: fundname})
~~省略~~
driver.find_element(By.XPATH, '//p[@class="mt10"]/input').click()
time.sleep(5)
os.rename(download_path + "/DownloadStdYmd.do", download_path + "/" + trust_id + ".csv")
print(FUND_DICT)
過去の値動きCSVはWEALTH ADVISORから取得しています。
WEALTH ADVISORのページからポートフォリオに組み入れたい銘柄のIDをURL欄から調べてTRUST_IDSに代入します。
3. 各銘柄ごとの期待収益率を求める。
6. 各銘柄の投資比率と期待収益率をもとに複数銘柄を組み合わせた場合の予想リターンを計算する。
# リターン計算
port_return.append(np.dot((concat_df.mean() * 250), weight))
上記の処理を分解すると以下です。
-
concat_df.mean() * 250
各銘柄ごとの1日の期待収益(平均)を取得します。その後* 250し年間収益率にします。
年率変換に使用する数字に関しては以下を参考にしました。
https://www.nomura.co.jp/terms/japan/hi/A02397.html#:~:text=標準偏差は求めた,年率換算値になる。 -
np.dot(期待値, weight)
複数銘柄のリターン計算式は以下です。
<2銘柄 株式,債券を組み合わせた場合のリターン計算式>
上記の計算では2銘柄の例の計算ですが、プログラム側では銘柄数は投資家が投資したい銘柄数にあわせて可変する必要があります。
普通に変数を使って上記式をコーディングすると処理が複雑になりそうです。
そのため、1次元配列の内積の特性を使って上記式を計算しています。
4. 各銘柄ごとの分散を求める。
7. 各銘柄の投資比率と分散をもとに複数銘柄を組み合わせた場合の予想リスクを計算する。
# ボラティリティ計算
port_risk.append((np.dot(weight.T, np.dot(concat_df.cov() * 250, weight))) ** 0.5)
リスク(ボラティリティ)を計算する式は以下です。
<2銘柄のリスク(ボラティリティ)計算>
-
concat_df.cov() * 250
年間の共分散を求めています。 -
np.dot(年間の共分散, weight)
共分散の値を列ごとにweight配列をかけ合わせます。 -
np.dot(weight,上記配列)
各配列に再度weightの値をかけて合計します。 -
** 0.5
ルートの計算をして共分散を標準偏差に変換しています。
この処理で、前述したポートフォリオの共分散を求める式になるのかは以下で示します。
なぜポートフォリオの共分散を求める式になるのか?
上記計算で使用する銘柄ごとの比率を生成する。
for r in range(10000):
weight = np.random.random(len(TRUST_IDS))
weight = weight/np.sum(weight)
各銘柄ごとの投資比率を生成しています。
8. 予想リスクと予想リターンをもとにシャープレシオを計算する。
# シャープレシオ
sharpe_ratio.append(port_return[r]/port_risk[r])
シャープレシオの計算式は以下です。今回は無リスク資産は考慮していません。
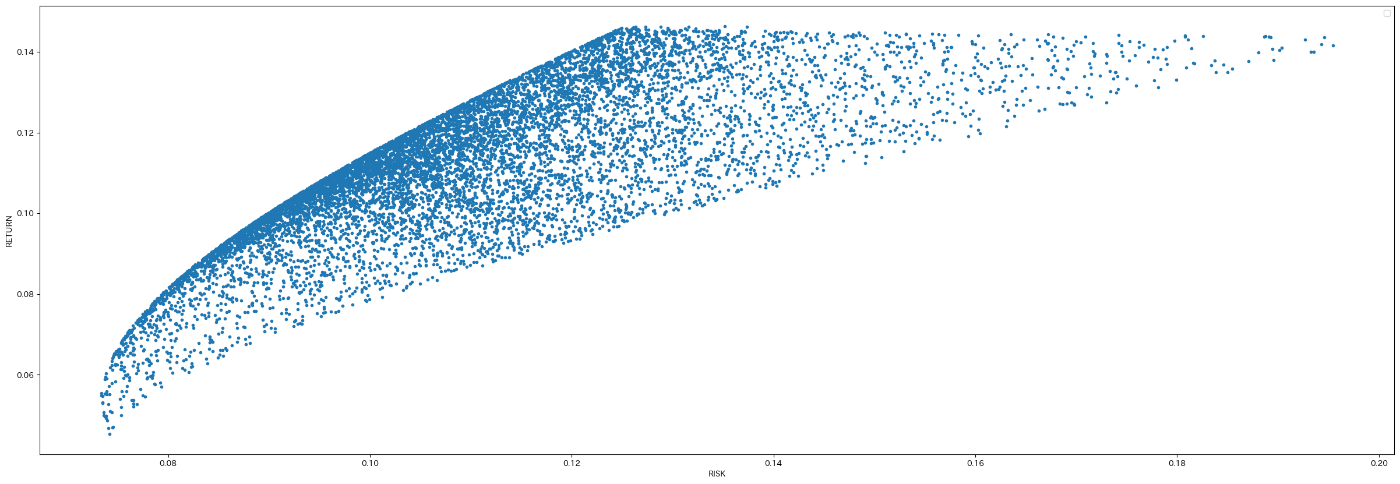
9. リスクとリターンをグラフにプロットし効率的なフロンティアを目視で確認する。
# 効率的なフロンティアを表にプロットする。
%matplotlib inline
plt.figure(figsize=(30, 10))
plt.plot(port_risk, port_return, '.' )
plt.xlabel('RISK')
plt.ylabel('RETURN')
plt.legend()
plt.show()
各投資比率ごとのRISKをX軸にRETURNをY軸にプロットしています。
10. リスク/リターン/シャープレシオなどを表として一覧表示し、どの銘柄比率が投資家にとって効率的かを確認する。
#サマリではなく全行表示させたい場合は以下Optionをコメントインする。
pd.set_option('display.max_rows', 100)
#pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
result_df = pd.DataFrame({'RISK': port_risk,
'RETURN': port_return,
'SHARP_RATIO': sharpe_ratio})
for w,id in zip(np.array(port_weights).T,TRUST_IDS):
result_df[FUND_DICT[id]] = w
# シャープレシオでソート
#result_df.sort_values(by=['SHARP_RATIO'], ascending=True)
result_df[(result_df['RETURN'] <= 0.15) &
(result_df['RETURN'] >= 0.08)].sort_values(by=['SHARP_RATIO'])
#result_df[(result_df['RETURN'] <= 0.07) &
# (result_df['RETURN'] >= 0.05) &
# (result_df['RISK'] < 0.08)].sort_values(by=['RETURN','RISK'], ascending=[True,False])
#result_df.sort_values('RETURN')
pd.set_option('display.max_rows', 100)
すべての行を表示するとすごい量になるので簡易表示にしています。
全情報を表示したい場合は100をNoneにします。
result_df[(result_df['RETURN'] <= 0.15) &
(result_df['RETURN'] >= 0.08)].sort_values(by=['SHARP_RATIO'])
ここの処理は投資家がどのあたりのリスクとリターンを狙いたいかに合わせて値を変えます。
実行結果

参考文献リスト
バートン・マルキール.ウォール街のランダム・ウォーカー<原著第12版> 株式投資の不滅の真理.日本経済新聞出版
根岸 康夫.現代ポートフォリオ理論講義.金融財政事情研究会
大橋亮太.(Udemy)【世界で8万人が受講:Python for Finance】Pythonを使って学ぶ現代ファイナンス理論と実践.株式会社CODOR
Discussion
有用な記事の投稿ありがとうございます。大変わかりやすく、勉強になりました。
勝手ながら、下記記事の作成にあたりモンテカルロ法による探索の部分を参考にさせていただきました。
ご報告も兼ねて共有致します。ご笑覧頂けますと幸いです。
ご連絡ありがとうございます。
私の作成した記事が役にたったのであれば幸いに思います。
まだ、投資関連の記事はほとんどないですが、
ちょっとずつ記事を増やせればと思っていますので、気が向いたらまた読んでいただければと思います。
数年前、インデックス投資を始めるにあたって参考にした「マイインデックス」というサイトでは、各銘柄を直接指定できず、大体のジャンルでしか試算できませんでした。毎月数万チョビチョビとしかできないのでもう少し効率的に投資したいと考えており、おみずのみ太郎さんの記事に行きつきました。
早速実行して、いろいろ挙動を見ているところです。大変興味深く有用な記事を公開くださり、ありがとうございます。
コメントありがとうございます。大変励みになります。
ぜひ、いろいろいじって遊んでみてください。