DifyのDeepresearchワークフローをざっくり理解する
はじめに
こんにちは。大宮です。
今回はDifyのDeepresearchテンプレートについて、
一見複雑そうに見えるワークフローの内容を調査してまとめてみたので紹介します。
そもそもDifyとは
Difyは、AI アプリケーションを構築するためのオープンソースプラットフォームです。
生成AIソリューションの開発を効率化し、開発者でなくともワークフローやRAGパイプラインの作成が容易に行えます。
参考:Dify公式ドキュメント
DifyのDeepresearchテンプレート

※見やすくするために全体的にブロックの位置をずらしています。
※LLMについて使用するモデルをテンプレートのものから切り替えています。
処理の概要
検索したい内容を入力するだけで、検索を繰り返し実行し、レポートを作成
- ユーザー入力受付:最初の質問(sys.query)と検索の深さ(depth)を入力
- 検索の初期化:GPT-4oを用いて質問を分析&検索テーマを抽出。追加検索が必要かどうかを判断
-
反復検索:指定された深さに基づいて、複数回の反復検索を実行
- Tavily検索エンジンで以前に抽出した検索テーマに基づいて検索を実行、検索結果を収集
- LLMを用いてさらなる検索が必要かどうかを判断、反復処理を制御
- 分析と要約:反復検索が終了すると(またはさらなる検索が不要と判断されると)、deepseek-reasonerモデルを用いて収集された検索結果を包括的に分析、要約
動作させてみる
入力:
Difyで作成したアプリを運用するにあたって、取得できるログについて詳細にまとめてください。
出力:

ワークフローを"読む"
1. STARTノード
役割:ユーザー入力の受付。
入力項目:
sys.query(検索したい内容)
depth(検索の深さ)
ここでユーザーは 「何について調べたいか」 と 「何回程度深掘り検索を繰り返すか」 を指定
例)
sys.query = "AWSのコスト削減事例"
depth = 3

2. CREATE ARRAY ノード
役割:反復処理に使う配列を作成。
使い道:depth の回数分だけ空の配列やカウンターを作り、後の ITERATION ノードでループさせるための準備をする.
例:[0, 1, 2] のようなインデックス配列を生成して「3回繰り返す」きっかけを作る。
3. ITERATION ノード
一番処理の核心部分
各ループで「次の検索テーマを決める → Tavily検索 → 結果保存 → 続行判断」

3-1. LLM(最初の推論)
デフォルトモデル:GPT-4(画像例ではAmazon Nova)
役割:前回の検索結果や初期クエリから「次に検索すべきトピック」と「続けるべきか」を推論。
出力例:
nextSearchTopic:"AWS Savings Plansの最新動向"
shouldContinue:true or false
3-2. EXTRACT NEXTSEARCHTOPIC / EXTRACT SHOULD CONTINUE
役割:LLMの出力から特定の値をJSONパースして抽出。
EXTRACT NEXTSEARCHTOPIC → 次に検索するテーマ文字列を取り出す。
EXTRACT SHOULD CONTINUE → 続行可否(true/false)を取り出す。
※ ENSURE_ASCII が付いているのは、文字化け防止やAPI互換性のため。
3-3. ASSIGN VARIABLES(nextSearchTopic / shouldContinue / topics)
役割:抽出した値をワークフロー変数に代入。
topics は今までの検索テーマの履歴として蓄積されることが多い。
3-4. IF/ELSE 分岐
条件:shouldContinue が true かどうかを判定
true の場合 → Tavily Search を実行
false の場合 → EMPTY ノード(何もせず次のループへ)
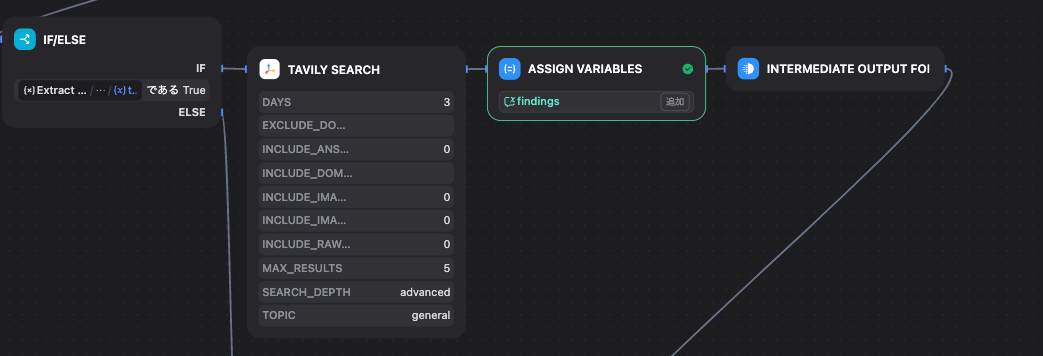
3-5. Tavily Search
役割:指定された nextSearchTopic を使ってWeb検索
設定例:
DAYS = 3(直近3日以内の情報を優先)
MAX_RESULTS = 5
SEARCH_DEPTH = advanced
出力:findings という変数に検索結果を格納。
※Tavilyとは?
Tavilyは、AIアプリケーション向けに最適化されたWeb検索API です。
通常の検索エンジンとは異なり、AIが使いやすい形式で検索結果を返すことに特化しています。
3-6. ASSIGN VARIABLES(findings)
Tavily の検索結果を findings 変数に保存。
次の集約ステップでまとめて使えるようにしておく。
3-7. INTERMEDIATE OUTPUT FOR / VARIABLE AGGREGATOR
INTERMEDIATE OUTPUT FOR:今回のループで得られた findings を中間出力に渡す。
VARIABLE AGGREGATOR:全ループの findings をまとめて最終的なレポート生成に使う。

4. REASONING MODEL
デフォルトモデル:DeepSeek Reasoner(なお廃止予定の記載あり)

役割:
すべてのループで集めた検索結果を総合的に分析。
情報の重複や矛盾を整理し、網羅的なレポートにまとめる。

5. ANSWER ノード
役割:Reasoningモデルの結果をユーザーに返す。
出力内容:検索を繰り返して集めた全データを統合したレポート。
まとめ
START〜CREATE ARRAY
→ ユーザーの検索テーマと深さを設定。
ITERATION
→ ループの中で「次に調べること」と「続けるか」をAIが決定。
Tavily Search
→ 必要なら追加検索し、結果を蓄積。
Reasoningモデル
→ 全結果を分析・要約。
ANSWER
→ ユーザーに最終レポートを返す。
おわりに
最初にテンプレートを出した時にびっくりしたDeepresearchテンプレートでしたが、
ざっくりでも読み解くとDeepresearchについて理解が深まる有意義な体験ができました。
現状のDeepresearchをカスタマイズして、新規のノードの追加や最適化、出力先の変更などに取り組むための第一歩が踏めてよかったです。
では!
Discussion