はじめに
株式会社Omiaiでテックリードを務める渡邊です。今回は、先日ご紹介したデータベースのリアーキテクトの取り組みに引き続いて、インフラ関連のリアーキテクトで実施したことや技術的負債への向き合い方などについてお話しをしたいと思います。
Omiaiが抱えていたシステムインフラにおける技術的負債とは
2024年以前はインフラ周りの自動化があまり進んでおらず、エンジニアが手作業で進めないといけない状態になっていました。当時は、Amazon EC2でMySQLを利用してサービス運用していました。例えば、レプリケーションするにしても自前で実装をしなければならず、インフラの性能が劣化し続けていました。
また、インフラリソースがどういう仕様なのかを表すドキュメントがない状態で、スケーリングするたびにAPIサーバーの構成のドリフトが発生していました。
さらに、ログインセッション関連も同様の状況です。容量の都合でデータを削除したくてもデフラグ遅延を考慮すると5日間のサービス停止をしなければいけない状態になっており、もう修復が困難な状態にまで陥っていました。
どのような問題が発生していたのか
頻繁に障害が発生していたわけではなかったのですが、単一障害点を抱えていました。最悪の事態が起こらないよう、必死にエンジニアが予防策を講じていました。
例をいくつか挙げると、まず1つがログインセッションのメモリ管理です。当時使用していたAmazon EC2は年に1回ほどメンテナンスを実施していました。インフラリソースが落ちると全ユーザーが強制的にログアウトされてしまうため、毎回エンジニアが手動でMemcachedのサーバーを新しく構築して全データを移行していました。
もう1つがストレージ関連です。ここも自前での実装になっていたため、ストレージの容量を超えそうになったら既存のディスクの状態をスナップショットし、それを新しいディスクにコピーして再構成・復元していました。
これらの問題が累積した結果、インフラ運用・維持にかかるコストが増えていき、プロダクトの成長速度に悪影響を与える結果となってしまっていました。Omiaiは24時間365日のプロダクトです。体制維持のための人件費に加え、多額の待機・オンコール時の追加人件費が発生する状況になっていました。
技術的負債を解消するかどうか「足踏み」した期間でコストや人員が発生し続けていた人員やコストは、もっと新規の機能開発や企画などに投下することもできたと思います。そう考えると、本来得られるはずだった機会損失額も相当大きかったのではないかと感じます。

具体的にどのような改善を行ったか
クラウド環境を前提としてアプリケーションやサービスを設計・開発・運用していく、いわゆるクラウドネイティブな運用に変えていくことを主眼に改善を進めています。
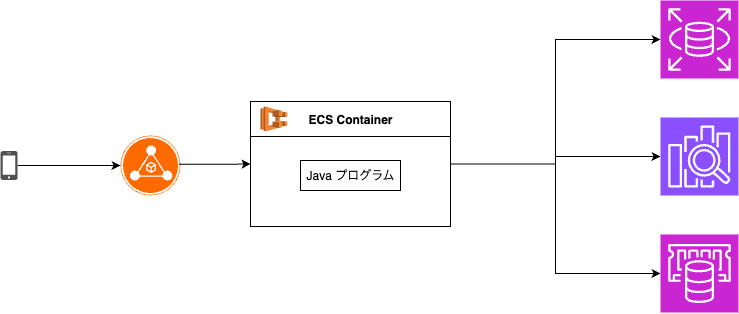
まず、Omiaiの開発で最も大きいボトルネックだったのが、Amazon EC2でMySQLを利用して運用するシステム構成でした。Amazon EC2にはオートスケール機能もあるのですが、基本的にはユーザー自身で設計・設定・管理しなければいけません。そのため、MySQLをAmazon RDSへ、ElasticsearchをOpenSearchとマネージドサービスへ移行中です。これによって、キャパシティに対する計画・構築における負担は大幅に軽減する想定です。
また、コンテナのオートスケールのために、EC2で動かしていたAPIサーバーをECS(Elastic Container Service)に移行しました。EC2では、常にインスタンスの稼働分が課金されますが、ECSではコンテナ稼働に応じてリソースが使われます。
リプレイスをするタイミングはいつがベストか
インフラで最も難しい問いが「リプレイスをするタイミングはいつがベストか」だと思います。というのも、インフラに投資をしてもマイナスをゼロにする効果があるけれど、プラスになる効果が見込めるわけではないからです。
私が考える答えとしては、黒字化したタイミング、つまりPMFを達成したときですね。だから、極端な話、黒字化するまではインフラの技術的負債はそこまで気にせずに突き進んでも良くて。重要なのは、事業戦略として「どこまでの成長曲線を描くのか」という話だと思います。
インフラの改修やリプレイスには非常に多大なコストがかかります。だからこそ、事業戦略と結びつけて考慮しないと、決断の時期は一生訪れません。
Omiaiは、結果として技術的負債が積み重なったタイミングでの実施となってしまいました。当初は1万人規模のプロダクトを想定してインフラを設計していましたが、本来ならば1万人を達成して次の事業戦略を描くタイミングでリプレイスを決断するのが理想的だったと思います。
今後の展望、これから解消していく課題
リアーキテクトはひと段落しましたが、まだ改善すべき点がいくつか残っています。今後、着手したい点は以下の4つです。
自動化
まだまだ手作業で行わないといけない領域があるので、そこを一つずつ改修していって、効率化と生産性向上を目指します。インフラの安定稼働が実現できれば、それはすなわちプロダクトの安定稼働と同義になります。3年後には、99%自動化できると理想ですね。
インフラの構成管理
現状では、ドキュメントやInfrastructure as Code(IaC)などの導入が進んでいません。今のままでは、誤操作や問題発生した際に「どの構成が変更されたか」「どの手順で構築されたか」の確認に時間がかかり、原因追跡やインフラ復旧が遅れてしまいます。また、新規メンバーや他部署への引き継ぎもスムーズに行えません。
ネットワークの管理
現状、網羅的にネットワークを把握できているわけではないので、本当に穴がないかを確認するのと同時に、役割別にネットワークを分割・最適化する、物理・論理構成図を作成・更新するといった施策も行っていきたいです。
インフラコストの低減
リアーキテクト実施前と比べると、インフラコストをおよそ半分にできましたが、まだまだコストを削減できると考えています。ただ、インフラコストは、リソースの過剰プロビジョニングや不要なデータアクセスなど、さまざまな要因が積み重なって増大していくものだと思っています。適切に、ドメイン分割(マルチテナンシー)を行えば、もう少しコストを低減できそうです。
インフラは軽視されがち。常に損失コストを計上しておく
実は水面下で、常に障害(大小問わず)は起こっています。それが可視化されていないのは、エンジニアが問題になる前に先回りをして解消しているからです。しかし、一般的なインフラに対する認識は、“動くことが当たり前”のものとされ、何をしているかよくわからない存在として軽視される傾向にあります。
だからこそ、インフラエンジニアは「経営層はインフラの重要性に気づいていないのではなく、経営判断に必要な情報がシステム側から伝えられないために気づく機会がない」ということを念頭において開発した方が良いです。
ここで大切になるのは、経営層にRDSやECSといったテクニカルな話をするのではなく、障害を未然に防ぐためにかかるコストや人的リソース、万が一インフラが落ちた場合に発生する機会損失のリスクなどを明確に提示することです。そうすれば、自ずとインフラの重要性を理解してもらえるでしょう。

Discussion