Sakana AI 秋葉氏が解き明かす、「本番で戦えるAIエージェントの作り方」W&B Fully Connected公演
はじめに
AIエージェントという言葉が一般的になって久しいですが、その実用性について満足している人はどれほどいるでしょうか。LLMにツールを連携させれば、簡単な自動化は実現できます。しかし、それが本当に「使える」レベルに達しているかというと、疑問が残ります。なぜなら、私たちが自動化したいタスクの多くは、これまで専門家が担ってきた高度な業務だからです。
2025年10月31日、Sakana AIのリサーチャーである秋葉さんが登壇し、専門家に匹敵するほど強力で実用的なAIエージェントを開発するための「決め手」について講演しました。本記事では、提供された音声とスライド資料を基に、その講演の要点をZennの記事形式でまとめます。
Sakana AIが開発した専門家レベルのAIエージェント
講演ではまず、Sakana AIがこれまでに発表してきた、専門家レベルの実力を持つAIエージェントの事例が3つ紹介されました。
1. The AI Scientist
100%全自動でAIが科学研究を行い、その成果を論文として執筆までしてしまうという驚異的なエージェントです。実際に、このエージェントが執筆した論文が、機械学習分野の国際的なワークショップで専門家による査読を通過し、人間が書いた論文と遜色ない評価を獲得した実績があります。これは、AIが専門家の領域で通用するレベルの成果物を生み出せることを証明した画期的な事例と言えるでしょう。
2. AE-Agent (アルゴリズムエンジニアリングエージェント)
物流の配送計画のような、複雑な組合せ最適化問題のアルゴリズムを自動で設計するエージェントです。このエージェントも、専門家が参加するプログラミングコンテストにおいて、人間と同じルールで競い合い、優れた成績を収めています。専門家並みのアルゴリズム設計能力を持つことを実証しました。
3. ShinkaEvolve
エージェント自身が自己進化することで、より強力なエージェントを自動で作り出すという野心的なプロジェクトです。ソフトウェアエンジニアリングのベンチマークであるSWE-Benchを用いた実験では、人間が何ヶ月もかけて開発する既存のエージェントに匹敵する性能を持つエージェントを、シンプルな初期状態から自動で生成することに成功しました。さらに、国際的なプログラミングコンテスト「ICFP-PC 2025」では、このShinkaEvolveが優勝チームに貢献したことも明かされました。

国際プログラミングコンテストでの実績を示すスライド
強力なエージェントを作るための2つの鍵
これらの成功事例の裏側には、どのような技術的なブレークスルーがあったのでしょうか。秋葉氏は、その鍵となる2つの重要な概念、「推論時スケーリング」と「ドメイン知識の活用」について詳しく解説しました。
1. 推論時スケーリング
これは、LLMの性能を最大限に引き出すためのアプローチです。単純ですが非常に強力な手法として「Repeated Sampling」が紹介されました。
Repeated Sampling: 数で質を凌駕する
この手法は、同じプロンプトでLLMを何度も(例えば250回)実行させ、生成された大量の解答の中から最も優れたものを選択するというものです。非常にシンプルながらその効果は絶大で、あるベンチマークでは、正解率が16%から56%へと劇的に向上したことが示されました。まさに「量質転化」を地で行くアプローチです。
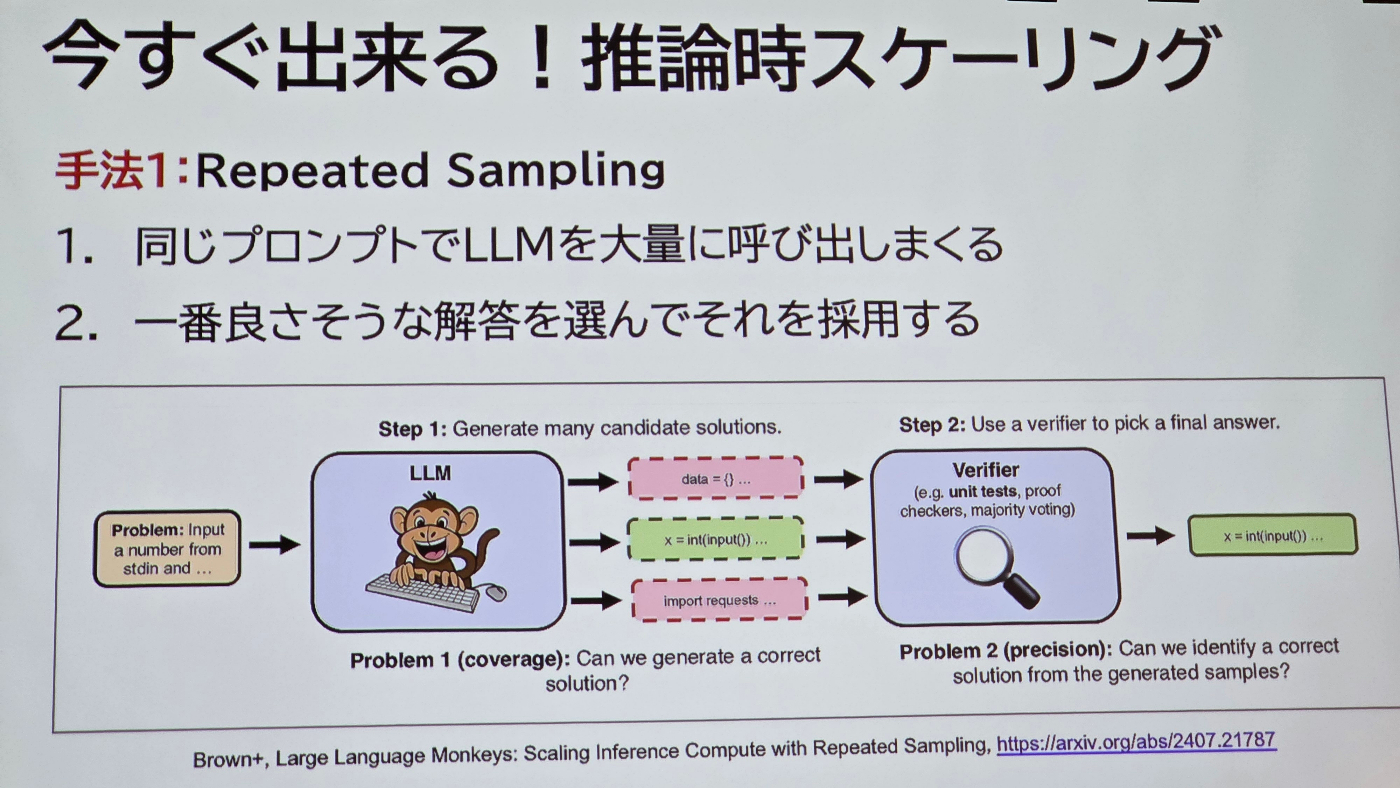
Repeated Samplingの考え方。大量の候補を生成し、検証器で最適な解を選ぶ
AB-MCTS: 幅と深さの適応的探索
しかし、単に数をこなすだけでは限界があります。そこでSakana AIが開発したのが「AB-MCTS (Adaptive Branching Monte Carlo Tree Search)」です。これは、多様な解を広く探索する「go wide」(Repeated Samplingに相当)と、有望な解を深く掘り下げて改良していく「go deep」(Sequential Refinement)の2つの戦略を、状況に応じて適応的に切り替えるアルゴリズムです。これにより、LLMの出力の多様性と、フィードバックによる改善という両方の利点を最大限に活用できます。さらに、複数の異なるLLM(例: Gemini 2.5 Pro, o4-mini)を動的に組み合わせることで、単体のLLMを凌駕する性能を達成できることも示されました。
![AB-MCTSの概念図]
AB-MCTSは、広く探索するか深く掘り下げるかを適応的に判断する
2. ドメイン知識の活用
もう一つの鍵は、対象分野の専門的な知識、すなわち「ドメイン知識」をいかにしてAIエージェントに組み込むかです。これは、かつての機械学習における「特徴量エンジニアリング」に相当する重要なプロセスだと秋葉氏は指摘します。
プロンプト: 知識を注入する
最も直接的な方法は、ドメイン知識をプロンプトに含めることです。タスクを解くための有用な知識や方法論を具体的に指示することで、エージェントの性能は大きく向上します。特に専門性の高いニッチなタスクにおいて、その効果は顕著です。重要なのは、表面的な言葉遣いではなく、問題解決に不可欠な情報をいかに的確にインプットするかです。

専門的なプロンプトの追加と推論時スケーリングにより、性能が劇的に向上
ワークフロー: 正しい手順をコード化する
その分野における「正しい問題解決の進め方」自体が、重要なドメイン知識です。例えば「The AI Scientist」では、科学者が研究を進める一般的なプロセス(アイデア創出→実験→論文執筆)をワークフローとしてエージェントのコードに組み込んでいます。これにより、エージェントは闇雲に試行錯誤するのではなく、体系的かつ効率的にタスクを遂行できます。
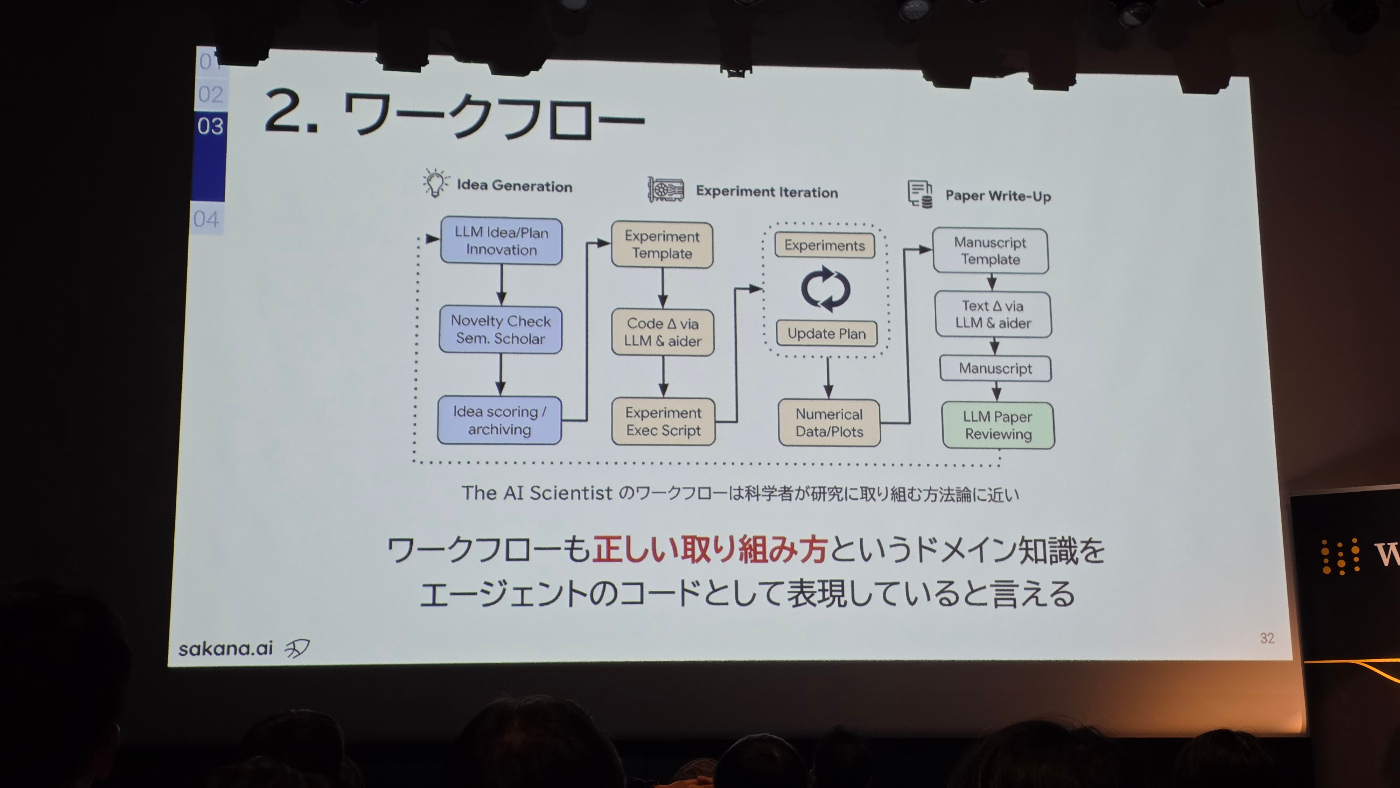
科学的な研究プロセスをワークフローとして実装
ルーブリック: 専門家の評価基準を定義する
実務上の多くのタスクでは、生成された結果の良し悪しを自動で評価することが困難です。そこで重要になるのが「ルーブリック」、すなわち詳細な評価基準です。専門家が持つ暗黙的な評価基準を明文化し、ルーブリックとしてLLMに与えることで、「LLM-as-a-Judge」の評価精度を専門家レベルに近づけることができます。
安定した評価軸が確立できれば、前述の「推論時スケーリング」がさらに効果を発揮します。大量の生成物の中から、質の高いものを自動で選別できるようになるからです。
OpenAIが発表した「PaperBench」というベンチマークは、このアプローチの好例です。わずか20本の論文を対象としながらも、論文の著者を含む専門家が作成した8,000以上の詳細なルーブリックが含まれており、データセットの本質がルーブリックにあることを示唆しています。今後は、専門家がコードを書くのではなく、ルーブリックを書くことに時間を費やす時代が来るかもしれません。

PaperBenchでは、少数の論文に対し膨大な数のルーブリックが用意されている
まとめ
本講演では、AIエージェントが単なる「自動化ツール」から、専門家と肩を並べる「実用的なパートナー」へと進化するための具体的な道筋が示されました。
| 重要な概念 | 内容 | なぜ重要か |
|---|---|---|
| 推論時スケーリング | LLMを何度も呼び出したり、探索戦略を工夫したりして、生成物の質を高めるアプローチ。 | LLMの潜在能力を最大限に引き出し、単一の試行では到達できない高品質な解を得るため。 |
| ドメイン知識の活用 | プロンプト、ワークフロー、ルーブリックなどを通じて、対象分野の専門知識をエージェントに組み込むこと。 | エージェントに正しい問題解決の方法論を与え、専門家のように振る舞わせるため。 |
「推論時スケーリング」によってLLMの能力を極限まで引き出し、「ドメイン知識の活用」によってその能力を正しい方向に向ける。この2つのアプローチを両輪とすることで、専門家にも匹敵する強力なAIエージェントの開発が現実のものとなります。Sakana AIの先進的な取り組みは、AIエージェントの未来が非常に明るいものであることを予感させてくれました。

Discussion