Open7
Ribbon: もうちょっとreadを最適化する
さすがに起動に2分掛かるのはちょっと。。まぁランタイムライブラリを全部S式から読んでバイトコードコンパイルするコストが掛かっているとは言え。。
real 1m56.997s
user 1m56.703s
sys 0m0.234s
文字クラスの取得を表引きにする
従来は cond で
のように分けていた。ribbonではこれは長い if 〜 then 〜 else になるので、O(N)になる。これを vector から拾うようにすれば O(1) になる。
real 1m48.052s
user 1m47.812s
sys 0m0.218s
期待した程早くは無いな。。
readerのループの呼出しをなるべく纏めて行うようにする
まぁバッチできるように作ったんだからバッチすべきだよね。。
real 1m43.413s
user 1m43.140s
sys 0m0.265s
ループの中でクロージャを作らないようにする
これはSchemeインタプリタ上で動くコードの最適化手法としてはよくある奴。 define の中で手続きを define するとクロージャが作られるので、実行のたびにメモリ確保が入ってしまう。
real 1m32.697s
user 1m32.577s
sys 0m0.108s
これはかなり効果あるな。。
この手の最適化はJavaScript界隈でも見られる。
文字ステートを開いたら逆に遅くなった
read中のストリームには以下のようなステートがある:
;; 初期状態 = 0
(define CHARLIT 1)
(define OBJ0 2)
(define OBJ0/SHARP 3)
(define OBJ0/DOT 4)
(define OBJ1 5)
(define OBJ1/SHARP 6)
(define OBJ2 7)
(define STRING0 8)
(define STRING1 9)
(define LINECOMMENT0 10)
(define LINECOMMENT1 11)
(define BLOCKCOMMENT0 12)
(define BLOCKCOMMENT1 13)
この case を1文字づつ実行することになっているので、これを開いて vector 参照一発にしてみた:
real 1m39.809s
user 1m39.531s
sys 0m0.280s
... これはダメだな。。case の各分岐を vector に入れるためにはクロージャにする必要があるのと、GCされるオブジェクトが大きくなるぶんで相殺されてしまっていると見られる。没。
バッチサイズを増やしても逆に遅くなる
diff --git a/lib/yuni/miniread/reader.sls b/lib/yuni/miniread/reader.sls
index 4a8760f..7f76e84 100644
--- a/lib/yuni/miniread/reader.sls
+++ b/lib/yuni/miniread/reader.sls
@@ -290,7 +290,7 @@
(values b bv c))))))
(define (utf8-read bv) ;; => eof-object if comment-only
- (define tkn (make-tkn 128))
+ (define tkn (make-tkn 1024))
(define cb (%utf8-in bv))
(define mr (make-miniread))
(define (capture tkn idx)
@@ -299,7 +299,7 @@
(type (tkn-type tkn idx)))
(vector type start-index end-index)))
(define (itr cur)
- (let ((r (miniread-main mr tkn 0 128 cb)))
+ (let ((r (miniread-main mr tkn 0 1024 cb)))
(cond
((eq? r #f)
(%realize bv (reverse cur)))
クロージャの生成コストは相対的に減るけど、まぁGC負荷が増えるぶんで相殺できないんだろうね。。
real 1m57.722s
user 1m57.483s
sys 0m0.202s
GC頻度が高すぎるのでは
VisualStudioのプロファイラで処理時間を確認してみた。
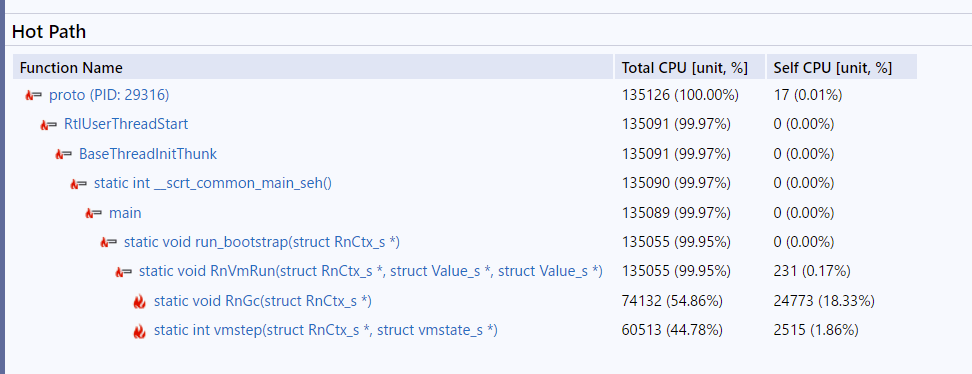
試しにGC頻度を1/100にすると、
real 0m56.238s
user 0m56.000s
sys 0m0.202s
うーむ。。もっと真面目にヒープを実装すべきか。。?