はじめに
こんにちは、
株式会社オークンでデータサイエンティストをやっています、nobuです。
cuDFはpandasと同じ感覚で使えてGPUをつかって高速計算ができるライブラリです。
私も普段から使っている、非常に優れたライブラリです。
しかし、cuDFでは、GPU1枚に乗るまでのデータ容量しか計算できません。
私はEC2(g4dn.xlarge)を使っていたので、GPU1枚のメモリの上限は16GBです。
つまり、今回のケースではcuDFでは16GBまでのデータまでしか計算ができないのです。
私のプロジェクトの機械学習の前処理では、300個ほどの特徴量を計算したりして、データ量は最終的に30GBを超えてしまいました。
cuDFで計算できずに困っていたのですが、Dask-cuDFを使ったマルチGPUでの計算を導入したところ、大容量データの計算が可能になりました!
Dask-cuDFは実装に少し癖があり、導入にかなり苦労したのですが、
今回はこれだけ押さえればよい、Dask-cuDFの実装方法をまとめましたので、ご紹介できればと思います!
かなりざっくり、Dask-cuDFとは
Dask-cuDFとは、データを複数GPUに分散させながら、計算できる技術です。
Dask-cuDFを使うことで、1枚のGPUに乗り切らない大容量のデータでも、計算させることが可能になります。
例えば、EC2インスタンス"G4dfn.12xlarge"で、Dask-cuDFを使うと、メモリ16GBのGPUが4枚搭載されているので、64GBまでのデータが計算できるようになります。
さっそく、実装
まずは、事前準備として、以下のコードを書いておきます。これにより、利用可能なすべてのGPUを利用して計算できるようになります。
from dask_cuda import LocalCUDACluster
cluster = LocalCUDACluster()
client = Client(cluster)
データの読み込み
csvからも、parquetからも、データの読み込みが可能です。
できれば、parquetの方が読み込みが速いのでおすすめします。
import dask_cudf
ddf = dask_cudf.read_csv(filepath)
ddf = dask_cudf.read_parquet(filepath)
cuDFからDask-cuDFに変換することも可能です。
cudf = cudf.read_csv(filepath)
ddf = ddf.from_cudf(cudf, npartitions=n)
※ cuDFからの変換だと、複数GPUにデータが分散されず、1つのGPUを集中して使ってしまうので、大容量のdfを変換する場合は注意が必要です。
Daskの仕様
上記でDask-cuDFへの変換を行いましたが、
実は、この時点では計算スケジュールが設定されただけで、読み込みは完了していません。
実際に読み込みを完了させるには、persistを使います。
ddf = ddf.persist()
persistを実行して初めて、各GPUにデータが分散されます。
ターミナル上で、watch nvidia-smiを実行して、GPUの使用具合を確認します。
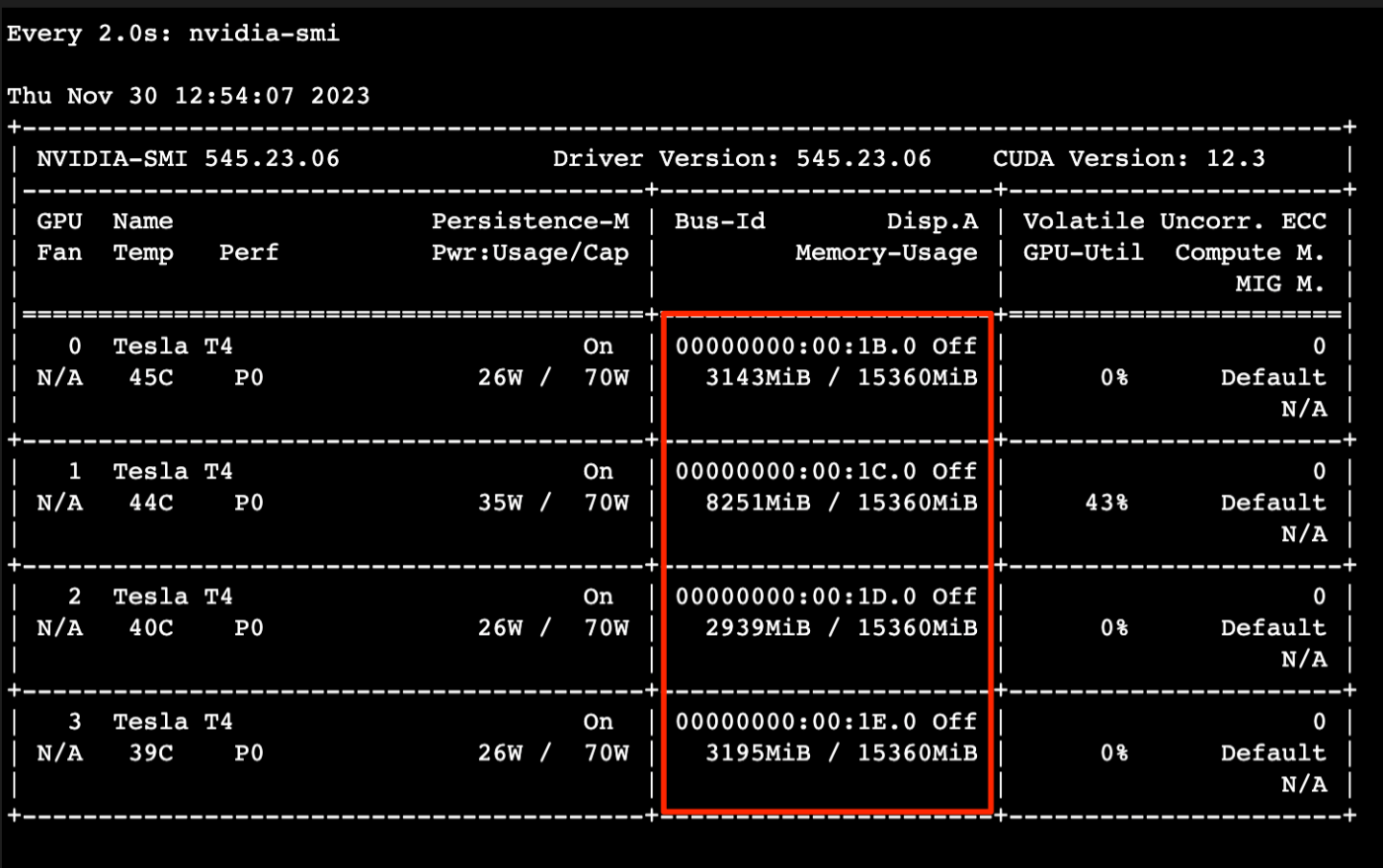
今回はGPUが4枚搭載されたインスタンスを使ったのですが、
たしかに4枚のGPUにそれぞれデータが分散されていることが確認できます。
これは各種計算処理でも同様で、実際に計算させるにはpersistを使う必要があります。
persistは複数GPU上で演算させる処理ですが、
最終的な計算結果を取得する場合は、computeを実行する必要があります。
cudf = ddf.compute() # dask_cudfからcudfに変換されます
df = ddf.compute().to_pandas() # pandasに変換する場合
max_id = ddf['id'].max().compute() # 数値の計算結果を取得する場合も同様
map_partitionについて
基本的にはpandasやcuDFと同じように計算できますが、Dask-cuDFではサポートされていない計算が結構あります。
その場合は、map_partitionsを使うことで計算可能です。
import numpy as np
def myadd(df, n)
return np.log(df['a']) * n
ddf["log_n"] = ddf.map_partitions(10) # n=10として渡される
RAPIDSコミュニティ
cuDF、Dask-cuDFを含むライブラリ群であるNVIDIA RAPIDSにはなんと、Slackコミュニティがあるようです!!
(RAPIDSのトップページの下部にありました)

このSlackでは、RAPIDSの技術質問も受け付けている?ようで、私もDask-cuDFの質問をいくつかさせていただき、助けて頂きました。
このコミュニティなしには、Dask-cuDFを導入できなかったと思います。ありがとうございました!
RAPIDSを使われている方は是非活用されることをお勧めいたします。
まとめ
無事、Dask-cuDFを導入することができ、メモリ不足に悩まされることがなく、大容量データでの計算が可能になりました!
大容量データを高速に計算したい場合はぜひご検討ください!
さいごに
最後までご覧いただき、ありがとうございました!
株式会社オークンでは、ヘッジファンド向けのトレードシステムを先日リリースいたしました。
現在、さらなる事業拡大に向け、エンジニアを積極的に採用しています。
本プロジェクトにご興味をお持ちいただけましたら、こちらの記事もぜひご覧ください!

Discussion