GenUを構築してみた(後編)
さて、前回の投稿から大分経ってしまいましたが、Generative AI Use Cases JPを
構築してみたことまとめ後編です。
気が付いたらいつの間にか前編を投稿してから2か月以上も経ってしまいました。
時が経つのは早いですね。催眠術だとか超スピードだとかそんなチャチなもんじゃあないものを
食らった気分です。
前回の構築時からの差分
GenUは日々進化が続いており、前回構築した時よりも新しい機能が追加されています。
そこで今回改めて以下の機能を追加して構築しなおしました。
利用モデルの追加
前回構築した時よりも対応モデルにLlama3.2が追加されています。
また以前からGenUでは対応していましたが前回は設定していなかったClaude系を追加しました。
(Claude系モデルの有効化時に会社名を求められるため個人利用ができないと思い込み、
前回設定していませんでした。)
Llama3.2とClaudeを加え、今回cdk.jsonに設定したモデルは以下のようになります。
"context": {
"modelIds": [
"anthropic.claude-3-5-sonnet-20240620-v1:0",
"anthropic.claude-3-sonnet-20240229-v1:0",
"anthropic.claude-3-haiku-20240307-v1:0",
"amazon.titan-text-premier-v1:0",
"us.meta.llama3-2-90b-instruct-v1:0",
"us.meta.llama3-2-11b-instruct-v1:0",
"us.meta.llama3-2-3b-instruct-v1:0",
"us.meta.llama3-2-1b-instruct-v1:0",
"meta.llama3-1-405b-instruct-v1:0",
"meta.llama3-1-70b-instruct-v1:0",
"meta.llama3-1-8b-instruct-v1:0",
"meta.llama3-70b-instruct-v1:0",
"meta.llama3-8b-instruct-v1:0",
"cohere.command-r-plus-v1:0",
"cohere.command-r-v1:0",
"mistral.mistral-large-2407-v1:0",
"mistral.mistral-large-2402-v1:0",
"mistral.mistral-small-2402-v1:0",
"meta.llama2-70b-chat-v1",
"meta.llama2-13b-chat-v1",
"mistral.mixtral-8x7b-instruct-v0:1",
"mistral.mistral-7b-instruct-v0:2"
],
}
Code Interpreter
Code Interpreterはエージェントが回答を生成する際に必要に応じてコードを
生成・実行するというものです。
タスクに応じたコードを生成してくれることから、エンジニアにとっては最も欲しい機能の
1つではないでしょうか?
BedrockでCode Interpreterを有効化したエージェントを作成し、
そのエージェントのagentIdとaliasIdをcdk.jsonに設定することで使用できるようになります。
(詳しい作成方法の説明はGenUのサイトのCode Interpreter Agent の作成ページにあります)
Kendraインデックスの自動作成・削除のスケジュール
前編の補足で述べたKendraインデックスの自動作成・削除のスケジュールの実行を設定してみました。
kendraIndexScheduleEnableをTrueとし、kendraIndexScheduleCreateCronとkendraIndexScheduleDeleteCronのそれぞれにKendraインデックスを作成/削除したい時刻を
Cron形式で指定すると、EventBridgeがStep Functionを呼び出し
Kendraインデックスの作成と同期、および削除を行ってくれます。
私は夜型人間であることからGenUを主に夜に利用するため、日曜から土曜の毎日21時に作成し0時に
削除するように設定しました。
EventBridgeの仕様に合わせて時刻は世界標準時(UTC)で設定する必要があるため、
cdk.jsonには次のように設定します。
"context": {
"kendraIndexScheduleEnabled": true,
"kendraIndexScheduleCreateCron": { "minute": "0", "hour": "12", "month": "*", "weekDay": "SUN-SAT" },
"kendraIndexScheduleDeleteCron": { "minute": "0", "hour": "15", "month": "*", "weekDay": "SUN-SAT" }
}
Advanced Parsing
OpenSearchコレクションを用いたRAGに対してはGenUの構築時にAdvanced Parsingを
設定することができます。
OpenSearchコレクションを用いたRAGではBedrockのKnowledge Baseにより埋め込みや検索を
行っています。
Advanced Parsingを設定すると、RAGの実行時にKnowledge Baseがモデルを用いて
非構造化データから情報を分析、抽出してくれるようになります。
表やグラフなどから抽出、例えばドキュメント中のフローチャートから文字情報だけでなく
矢印の意味を解釈し、それを基に回答が生成されることでRAGの精度向上を期待できます。
今回の構築では非構造化データを解釈するモデルをClaude3 Sonnetとし、
以下のようにdck.jsonに設定しました。
"context": {
"ragKnowledgeBaseAdvancedParsing": true,
"ragKnowledgeBaseAdvancedParsingModelId": "anthropic.claude-3-sonnet-20240229-v1:0",
}
GenUのユースケース例
ではここから実際にGenUを使った例をご紹介していきたいと思います。
GenUには以下の箇条書きに示すような機能(ユースケース)があります。
しかし全て紹介すると数が多いですし、GenUのgithubのサイトにも説明されているものも多いため、
本記事では太字にしたユースケースに絞ってご紹介します。
- チャット
- RAGチャット
- Agentチャット
- 検索エージェント
- Code Interpreter
- 文章生成
- 要約
- 校正
- 翻訳
- Webコンテンツ抽出
- 画像生成
- 映像分析
- ブログ記事作成
- 議事録作成
- 音声認識
- Kendra検索
- ファイルアップロード
構築においては大阪リージョンに設置したNAT GatewayのIPアドレスからのアクセスしか
受け付けないWAFの設定をしているため、今回はSessionManagerを用いた
SSHのダイナミックポートフォワーディングにより、大阪リージョンに立てた
Amazon LinuxのEC2インスタンスを経由してローカルのPCのブラウザから
GenUへアクセスしてみました。
(この辺りもいつか記事にできれたらなと思います。)
チャット
生成AIの使い方の代表格であるチャットも当然GenUで試すことができます。
構築時に設定したモデルの中から切り替えて使うことができるため、
ClaudeやTitan、Llamaなどの色々な種類のLLMを使ってみることができます。
それぞれのモデルの特色を比較してみるなんてことをしてみても良いかもしれません。
RAGチャット
RAGはRetrieval-Augmented Generation(検索拡張生成)の略であり、
LLMにドキュメントなどで情報を与えることで、LLMが学習していない事柄についても
回答できるようにするものです。
GenUではKendraインデックスとOpenSearch Serverlessコレクションを用いる
2つのRAGチャットを試すことができます。
今回はGenUでサンプルとして添付されているBedrockのユーザーガイドを登録して
KendraインデックスとOpenSearchコレクションを作成してみました。

(Kendraを用いたRAGチャット)

(OpenSearchを用いたRAGチャット)
上の画像のように、RAGを用いた場合はBedrockについて質問するとユーザーガイドを
基にした回答を生成してくれます。
一方でRAGを行わずBedrockの情報を持たないモデルで同じ質問をすると、
ハルシネーションが発生します。

(RAG無しで行った場合の結果)
検索エージェント
Bedrockのエージェントは入力文から行うべきタスクを解釈し、APIやLambda関数を実行するなどして人間の代わりにタスクを実行することができます。
GenUではエージェントの例として検索エージェントを使うことができます。
検索エージェントでは回答の生成に必要な情報を検索エンジンAPIを実行して調査し、
回答してくれます。
GenUではデフォルトでBrave Search APIが用いられています。

(検索エージェントのチャット例)
上の画像のように、Bedrockについて質問すると検索エンジンAPIから調査した回答を
作ってくれますね。
Code Interpreter
記事冒頭のCode Interpreterで紹介したように、エージェントが必要に応じてコードを生成・実行し
回答を生成する、Code Interpreterエージェントを使うことができます。
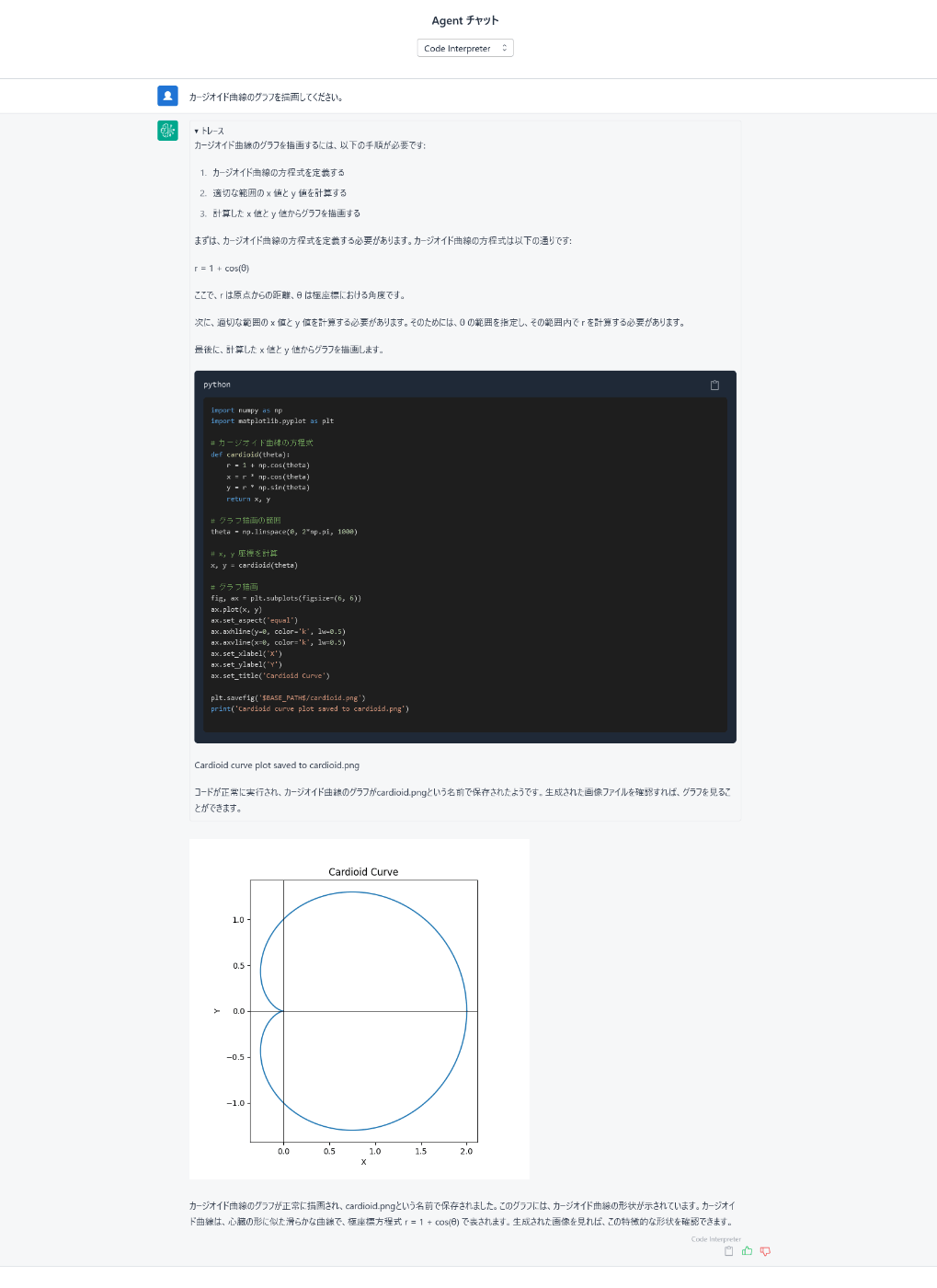
カージオイド曲線の方程式などもはやとうの昔に忘れてしまいましたが、
Code Interpreterエージェントに聞くとこの通り方程式やグラフ描画コードを
作ってもらうことができ、カージオイド曲線のグラフ画像を得ることができます。
ブログ記事作成
GenUでは基本的なユースケースを複数組み合わせた「ユースケース連携」も
試すことができます。
その1つが「ブログ記事作成」であり、「Webコンテンツの抽出」「文章生成」「要約」
「画像生成」を組み合わせたブログ記事を作成できます。
このユースケースを東京都議会の委員会速記録を用いて試してみました。
Webコンテンツの抽出
ではまずは議事内容を抽出してみましょう。
委員会速記録のURLを指定し、議題と議論の内容を抽出するような指示で実行します。

この手の議事録は長いので全部読むのは中々に骨が折れますが、このように要約してもらえると内容を把握しやすいですね。
文章生成
続いて抽出したWebコンテンツの内容からブログ用の文章を作成します。
分かりやすくなるよう中学生向けの文章を生成してもらうようにします。
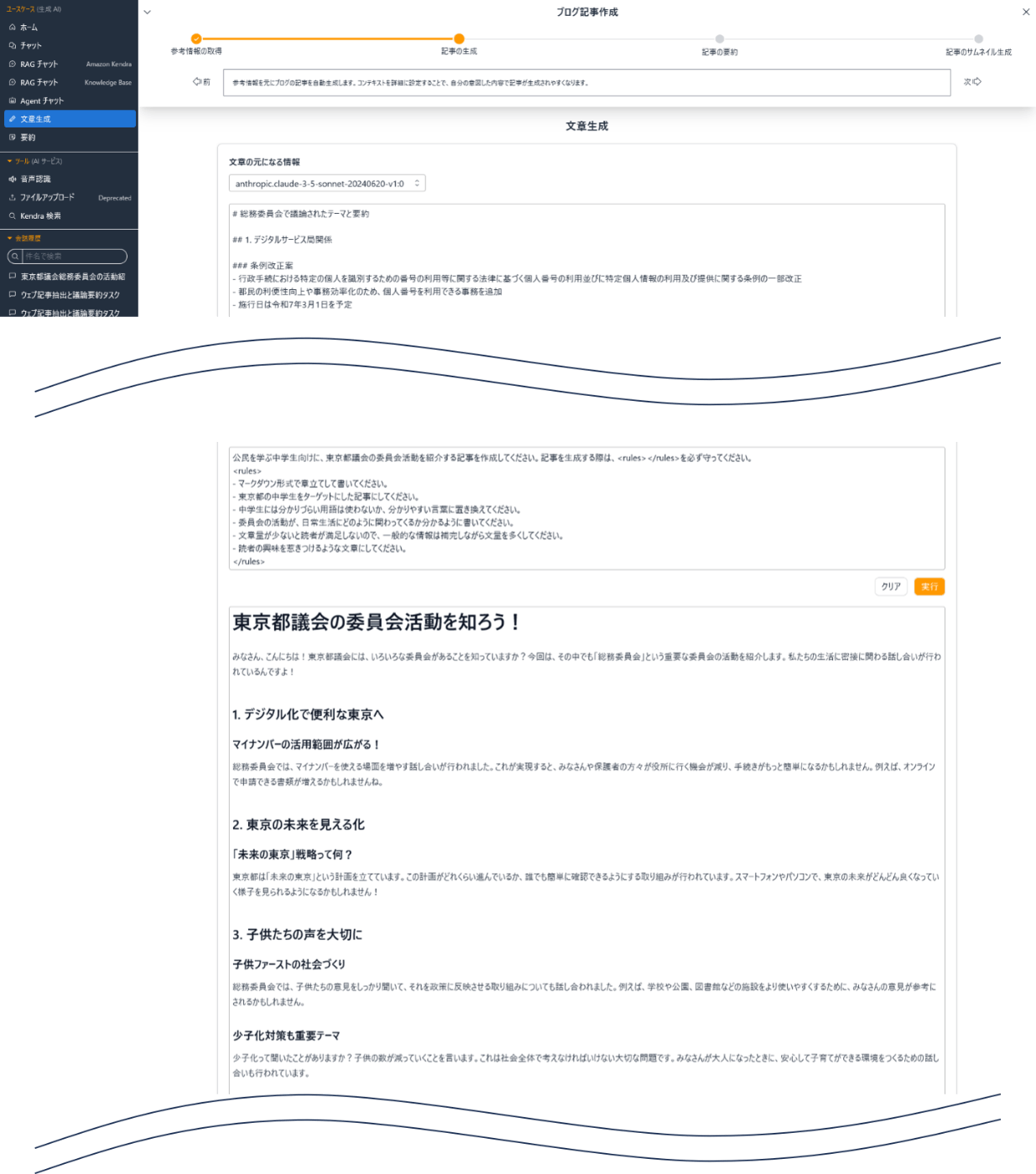
長くなるので一部カットしていますが、何か普通に勉強になりますね。
要約
先ほど作成した文章の記事のプレビュー用にということで、要約を生成します。
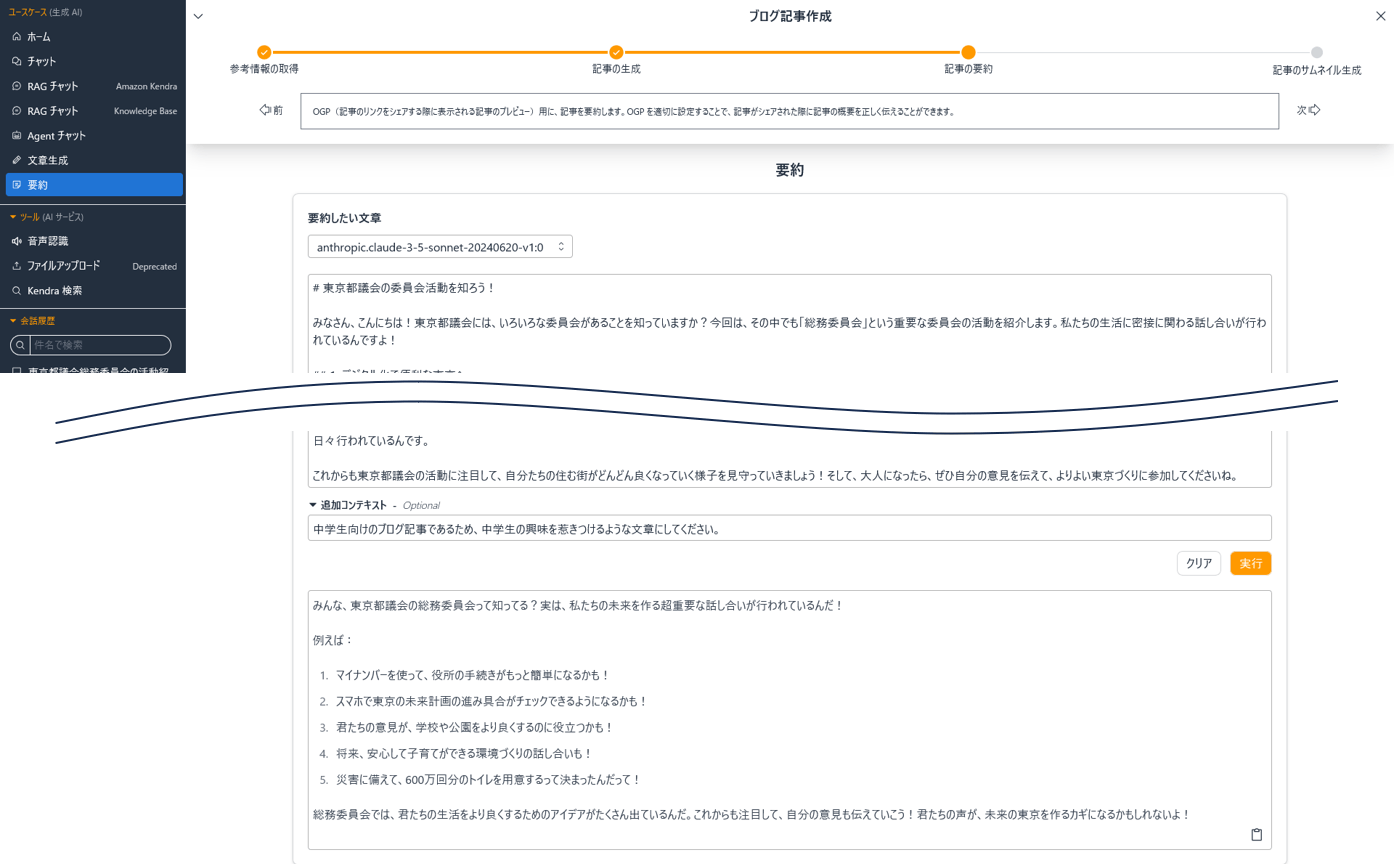
狙い通り中学生向け学習サイトにありそうな文言ができました。
画像作成
最後にブログのサムネイルとなる画像を生成します。


東京都庁っぽい建物の前を歩く若者達の画像ができました。
都議会議事堂ではなく都庁っぽい建物となりましたが、東京の政庁をイメージさせるならこちらの方が分かりやすいですね。
以上が「ブログ記事作成」のユースケースです。
このように普段読まないような文章を基に普段書かないような文章を生成してみましたが、
あっという間に指定したテーマ、文体で生成することができました。
議事録作成
続いてのユースケース連携は「議事録作成」です。
「議事録作成」は「音声認識」「校正」「要約」を組み合わせたユースケースとなっています。
こちらの題材としては国会中継を使用してみました。
音声認識
会議の音声データをアップロードすると、Amazon Transcribeを用いて文字起こしが行われます。

2時間以上の委員会議事となるとかなり内容が多いですね。
これを読んで内容を把握するのは大変そうです。
校正
続いて書き起した議事内容を、校正機能により文字起こしの誤認識の修正や省略された接続詞の補完、言い淀みの除去を行い整形します。

大分読みやすくなりました。
要約
最後に成型された文章を「要約」機能により、よくある議事録のフォーマットである
議論の内容、決定事項、宿題事項にまとめます。
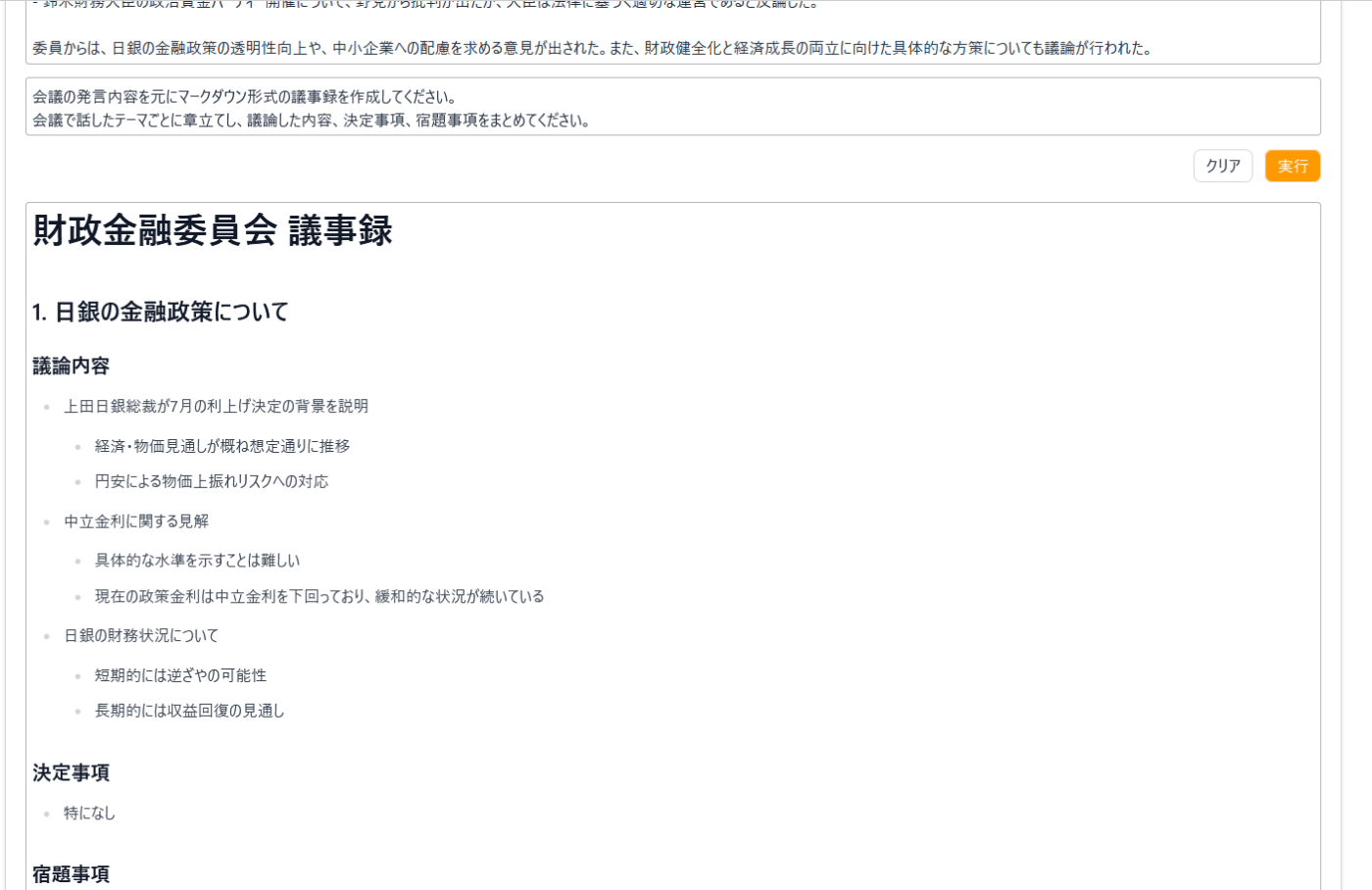
あっという間に議事録の完成です。
以上が「議事録作成」のユースケースです。
Kendra検索
RAGチャット用に作成しているKendraインデックスにおいては、
登録している資料に対して検索することができます。
"Bedrock"で検索してみると、インデックスに登録しているBedrockユーザーガイドの
内容が出てきますね。

ファイルアップロード
「ファイルアップロード」機能ではWordファイルやMarkdownファイルなどから
テキストを抽出することができます。
試しに先ほどの議事録作成で用いた財政金融委員会の会議録をアップロードしてみます。

会議録のテキストを抽出できました。
抽出したテキストはチャットや要約、翻訳などのユースケースで入力文として使うことができます。
特に意味はないですが抽出したテキストを翻訳にかけてみます。

会議録が英語に翻訳されました。英語にするだけで何故かかっこよく見えますね。
以上、GenUのユースケース紹介でした。
(「ファイルアップロード機能」は2024年9月末で廃止されるとありますが、
2024年10月7日時点ではまだ廃止されていないようです。
ただ、おそらく今後廃止になると思われます。)
GenUの解体
さて、作ったからには片付けをしていきたいと思います。
CDKが用いられているためGenUの解体は簡単でnpm run cdk:destroyコマンドを実行するだけです。
ただしオプション設定を追加していると複数のスタックが作られるため、削除するスタックを指定する必要があります。
ここでアスタリスク"*"でワイルドカード指定することですべてのスタックを削除することができます。
(最初に解体を試みた際はこれが分からず、AWSコンソールからCloudFormationスタックを
選択して削除していました。)
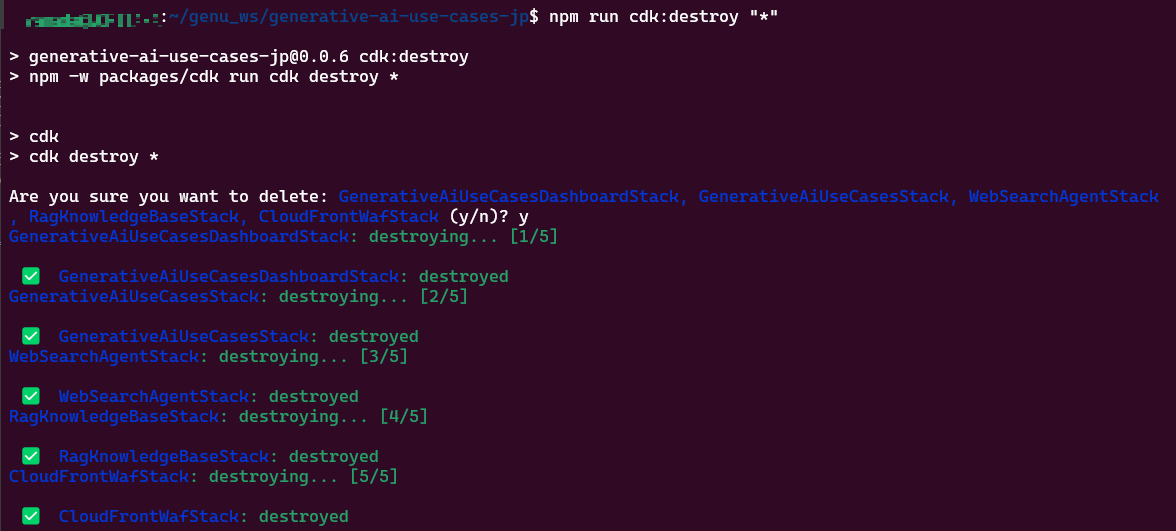
これによって解体は完了です。
以上、GenUの構築解体およびユースケースの紹介でした。
GenUは生成AIを用いたアプリを試すのにとても便利なツールだと思います。
試してみるのはいかがでしょうか?
Discussion