🥷
【Google Colabで学ぶpandas入門】データ分析の応用
この記事は、前回の「基本編」に続く「応用編」です。基本編では、データの準備や確認、クリーニング、基本的な可視化方法について紹介しました。今回は、より高度なデータ分析テクニックに焦点を当て、実践的なスキルを身につけることを目指します。データのグループ化、結合、並べ替え、フィルタリング、さらに高度な可視化まで幅広く紹介します。
🔎 応用編:データ分析の応用
1️⃣ グループ化と集計
データをカテゴリごとにグループ化して、統計量を計算できます。
🔹 平均値の計算
import pandas as pd
data = {
'名前': ['太郎', '花子', '次郎', '三郎', '太郎', '次郎'],
'科目': ['数学', '英語', '数学', '英語', '英語', '数学'],
'得点': [88, 92, 76, 81, 79, 95]
}
df = pd.DataFrame(data)
# 科目ごとの得点平均
print(df.groupby('科目')['得点'].mean())
🖥️ 実行結果
科目
数学 86.33
英語 84.00
Name: 得点, dtype: float64
🔹 最大値・最小値の計算
# 最大値と最小値
print(df.groupby('科目')['得点'].max())
print(df.groupby('科目')['得点'].min())
🖥️ 実行結果
科目
数学 95
英語 92
Name: 得点, dtype: int64
科目
数学 76
英語 79
Name: 得点, dtype: int64
🔹 複数の統計量をまとめて計算
print(df.groupby('科目')['得点'].agg(['mean', 'max', 'min']))
🖥️実行結果
mean max min
科目
数学 86.333333 95 76
英語 84.000000 92 79
2️⃣ データの結合と結合処理
merge() を使用すると、2つのデータフレームを結合できます。
🔹 内部結合
df1 = pd.DataFrame({'ID': [1, 2, 3], '名前': ['太郎', '花子', '次郎']})
df2 = pd.DataFrame({'ID': [1, 2, 4], '得点': [88, 92, 76]})
merged_df = pd.merge(df1, df2, on='ID', how='inner')
print(merged_df)
🖥️ 実行結果
ID 名前 得点
0 1 太郎 88
1 2 花子 92
🔹 外部結合 (すべてのデータを残す)
merged_df = pd.merge(df1, df2, on='ID', how='outer')
print(merged_df)
🖥️ 実行結果
ID 名前 得点
0 1 太郎 88.0
1 2 花子 92.0
2 3 次郎 NaN
3 4 NaN 76.0
3️⃣ データの並べ替え
sort_values() を使用して、データを特定の列の値に基づいて並べ替えできます。
🔹 昇順ソート
sorted_df = df.sort_values(by='得点', ascending=True)
print(sorted_df)
🖥️ 実行結果
名前 科目 得点
2 次郎 数学 76
4 太郎 英語 79
3 三郎 英語 81
0 太郎 数学 88
1 花子 英語 92
5 次郎 数学 95
🔹 複数列でのソート
sorted_df = df.sort_values(by=['科目', '得点'], ascending=[True, False])
print(sorted_df)
🖥️ 実行結果
名前 科目 得点
5 次郎 数学 95
0 太郎 数学 88
2 次郎 数学 76
1 花子 英語 92
3 三郎 英語 81
4 太郎 英語 79
4️⃣ データのフィルタリング
query() を使用すると、より直感的な方法でデータをフィルタリングできます。
🔹 条件でのフィルタリング
filtered_df = df.query('得点 >= 80')
print(filtered_df)
🖥️ 実行結果
名前 科目 得点
0 太郎 数学 88
1 花子 英語 92
3 三郎 英語 81
5 次郎 数学 95
🔹 複数条件でのフィルタリング
filtered_df = df.query('得点 >= 80 & 科目 == "数学"')
print(filtered_df)
🖥️ 実行結果
名前 科目 得点
0 太郎 数学 88
5 次郎 数学 95
5️⃣ 高度な可視化テクニック
seaborn を使用すると、より見やすく美しいグラフが作成できます。
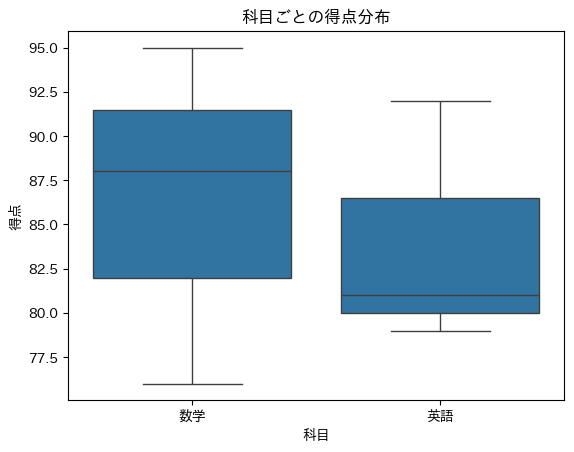
🔹 箱ひげ図
!pip install japanize_matplotlib
import seaborn as sns
import matplotlib.pyplot as plt
sns.boxplot(x='科目', y='得点', data=df)
plt.title('科目ごとの得点分布')
plt.show()
🖥️ 実行結果
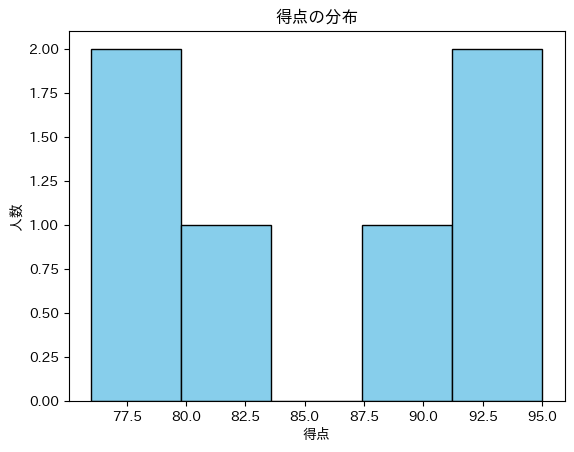
🔹 ヒストグラム
plt.hist(df['得点'], bins=5, color='skyblue', edgecolor='black')
plt.title('得点の分布')
plt.xlabel('得点')
plt.ylabel('人数')
plt.show()
🖥️ 実行結果
🎯 まとめ
pandasは、基本的なデータ処理だけでなく、次のような高度なテクニックも強力にサポートします。
✅ グループ化と集計
✅ データの結合
✅ データの並べ替え
✅ query() による直感的なデータ抽出
✅ seaborn を用いた可視化
これらのテクニックを活用することで、より高度なデータ分析が可能になります。
株式会社ONE WEDGE
【Serverlessで世の中をもっと楽しく】 ONE WEDGEはServerlessシステム開発を中核技術としてWeb系システム開発、AWS/GCPを利用した業務システム・サービス開発、PWAを用いたモバイル開発、Alexaスキル開発など、元気と技術力を武器にお客様に真摯に向き合う価値創造企業です。
Discussion