Streamlitの使い方の細かいところ
この記事は BrainPad Advent Calendar 2021 9日目の記事です。2020年頃より、機械学習エンジニアやデータサイエンティストが Python でお手軽にウェブアプリを構築できる Streamlit が流行っていて、最近では業務で使っている人も多いのではないかと思います。Streamlit は、その設計思想から、シンプルな可視化であればほとんど困ることはありませんが、ちょっと手のこんだことをしようとすると、「あれ、どうしたらいいんだっけ?」と思うことがちょくちょくあります。この記事では、そういった時にどうしたらよいか、というのをいくつか紹介したいと思います。
アップロードしたファイルを保存する
Streamlit には、ファイルのアップロード機能が実装されていて、簡単に手元のデータをサーバーにアップロードできます。アップロードしたファイルはメモリ上に配置され、ディスク上に保存されるわけではないので、ファイルを保存したい場合や、パスが必要な処理を施したい場合は、ファイルを開いて書き込んでやる必要があります。
サンプルコード
import os
import streamlit as st
from PIL import Image
IMG_PATH = 'imgs'
def main():
st.markdown('# 画像を保存するデモ')
file = st.file_uploader('画像をアップロードしてください.', type=['jpg', 'jpeg', 'png'])
if file:
st.markdown(f'{file.name} をアップロードしました.')
img_path = os.path.join(IMG_PATH, file.name)
# 画像を保存する
with open(img_path, 'wb') as f:
f.write(file.read())
# 保存した画像を表示
img = Image.open(img_path)
st.image(img)
if __name__ == '__main__':
main()
ファイルをダウンロードする
以前はダウンロード専用の機能がなく、独自に実装する必要がありましたが、0.88.0 以降では st.download_button を使って、簡単にダウンロードリンクを作ることができるようになりました[1]。
サンプルコード
import os
import streamlit as st
from PIL import Image
IMG_PATH = 'imgs'
def list_imgs():
# IMG_PATH 内の画像ファイルを列挙
return [
filename
for filename in os.listdir(IMG_PATH)
if filename.split('.')[-1] in ['jpg', 'jpeg', 'png']
]
def main():
st.markdown('# 画像を保存するデモ')
file = st.file_uploader('画像をアップロードしてください.', type=['jpg', 'jpeg', 'png'])
if file:
st.markdown(f'{file.name} をアップロードしました.')
img_path = os.path.join(IMG_PATH, file.name)
# 画像を保存する
with open(img_path, 'wb') as f:
f.write(file.read())
# 保存した画像を表示
img = Image.open(img_path)
st.image(img)
# IMG_DIR 以下の画像から選択
filename = st.selectbox('ダウンロードする画像を選択', list_imgs())
# ダウンロード
st.download_button(
'ダウンロード',
open(os.path.join(IMG_PATH, filename), 'br'),
filename
)
if __name__ == '__main__':
main()
複数ページのアプリを作る
Streamlit で作れるアプリは基本的に SPA なので、複数ページを持つようなアプリを作るには少し工夫が必要です。最も簡単なのは、以下のように、selectbox を使って表示内容を切り替える方法です。
サンプルコード
import streamlit as st
import page1
import page2
def main():
with st.sidebar:
page = st.selectbox('', ('page1', 'page2'), )
if page == 'page1':
page1.render()
elif page == 'page2':
page2.render()
if __name__ == '__main__':
main()
以下のように、 page1 および page2 の中で、それぞれ描画したい内容を記述します。
import streamlit as st
def render():
st.write('page1')
クエリパラメーターを利用する
前述の方法で複数ページっぽいアプリは作れますが、各ページに対応する URL があるわけではないため、特定のページをリンクで共有する、といった使い方をすることができません。そこで、クエリパラメーターの利用を考えます。Streamlitでは、クエリパラメーターの取得・設定をする機能が、実験的に提供されています。
以下のコードでは、まず初めに st.experimental_get_query_params を使ってクエリパラメーターを取得して selectbox の初期値として設定しています。続いて、 selectbox の値が変更されり button が押された際に URL に反映されるように、on_change や on_click で st.experimental_set_query_params を使っています。関数名から推察できる通り、今後のリリースで諸々変更される可能性があります。
サンプルコード
import streamlit as st
def first_page():
st.markdown("""
# Welcome to the first Page!
This is the first page.

""")
def second_page():
st.markdown("""
# Welcome to the second Page!
This is the second page.

""")
def last_page():
st.markdown("""
# Welcome to the last Page!
This is the last page.

""")
PAGES = [
{'title': 'First', 'contents': first_page},
{'title': 'Second', 'contents': second_page},
{'title': 'Last', 'contents': last_page}
]
def set_page(page_index):
st.experimental_set_query_params(page=str(page_index))
def get_page_index():
query = st.experimental_get_query_params().get('page')
if query is not None and query[0].isdecimal():
return min(int(query[0]), len(PAGES) - 1)
else:
return 0
def main():
page_index = get_page_index()
with st.sidebar:
st.selectbox(
'Select a page',
range(len(PAGES)),
format_func=lambda x: PAGES[x]['title'],
index=page_index,
key='select_page_index',
on_change=lambda: set_page(st.session_state['select_page_index'])
)
# Show the page
PAGES[page_index]['contents']()
# Footer
st.progress((page_index + 1)/len(PAGES))
cols = st.columns(6)
with cols[2]:
st.button(
'Prev',
on_click=lambda: set_page(page_index - 1),
disabled=(page_index == 0) # disable button if on first page.
)
with cols[3]:
st.button(
'Next',
on_click=lambda: set_page(page_index + 1),
disabled=(len(PAGES) - 1 == page_index) # disable button if on last page.
)
if __name__ == '__main__':
main()
過去のコードはこちら
import streamlit as st
import page1
import page2
def get_page_param():
# クエリパラメーターを辞書形式で取得できる
query_params = st.experimental_get_query_params()
if 'page' in query_params:
# 各パラメーターの値はリストに格納されている
return query_params['page'][0]
else:
return None
def main():
pages = {
'page1': page1,
'page2': page2
}
page_names = list(pages.keys())
page_name = get_page_param()
st.write(page_name)
# 現時点では、 session_state を指定しないと挙動がおかしくなる
# くわしくは https://github.com/streamlit/streamlit/issues/3635
if page_name in pages and 'page' not in st.session_state:
st.session_state['page'] = page_name
with st.sidebar:
if page_name is None:
index = 0
else:
index = page_names.index(page_name)
# ローカル環境と Streamlit Cloud で挙動が異なる。ローカル環境では index に 0 を指定する
page = st.selectbox('select page', page_names, index=index, key='page')
st.experimental_set_query_params(page=page)
pages[page].render()
if __name__ == '__main__':
main()
編集可能なテーブルを使う
pd.DataFrame をいい感じに表示するだけであれば、標準の機能で事足りますが、UIからデータをいじりたいという要望には対応できません。そこで サードパーティーのコンポーネント の AgGrid を利用します。インストールは簡単で、 pip で一発です。
pip install streamlit-aggrid
以下のように、GridOptions を介して見た目や編集の可否を指定し、 AgGrid を呼び出す際に updateMode を指定します。
サンプルコード
import streamlit as st
from st_aggrid import AgGrid, GridOptionsBuilder, GridUpdateMode
import pandas as pd
DATA_URL = 'https://raw.githubusercontent.com/fivethirtyeight/data/master/airline-safety/airline-safety.csv'
def main():
df = pd.read_csv(DATA_URL)
gb = GridOptionsBuilder.from_dataframe(df, editable=True)
grid = AgGrid(df, gridOptions=gb.build(), updateMode=GridUpdateMode.VALUE_CHANGED)
# 修正が反映される
st.dataframe(grid['data'])
if __name__ == '__main__':
main()
地図を柔軟に利用する
地図の表示は標準機能だけでもできますが、 MapBox API と pydeck を組み合わせると、より柔軟な操作ができます。以下の例では、住所から2点間の最短ルート(直線ではなく、道路を走った場合の最短ルート)を表示しています。
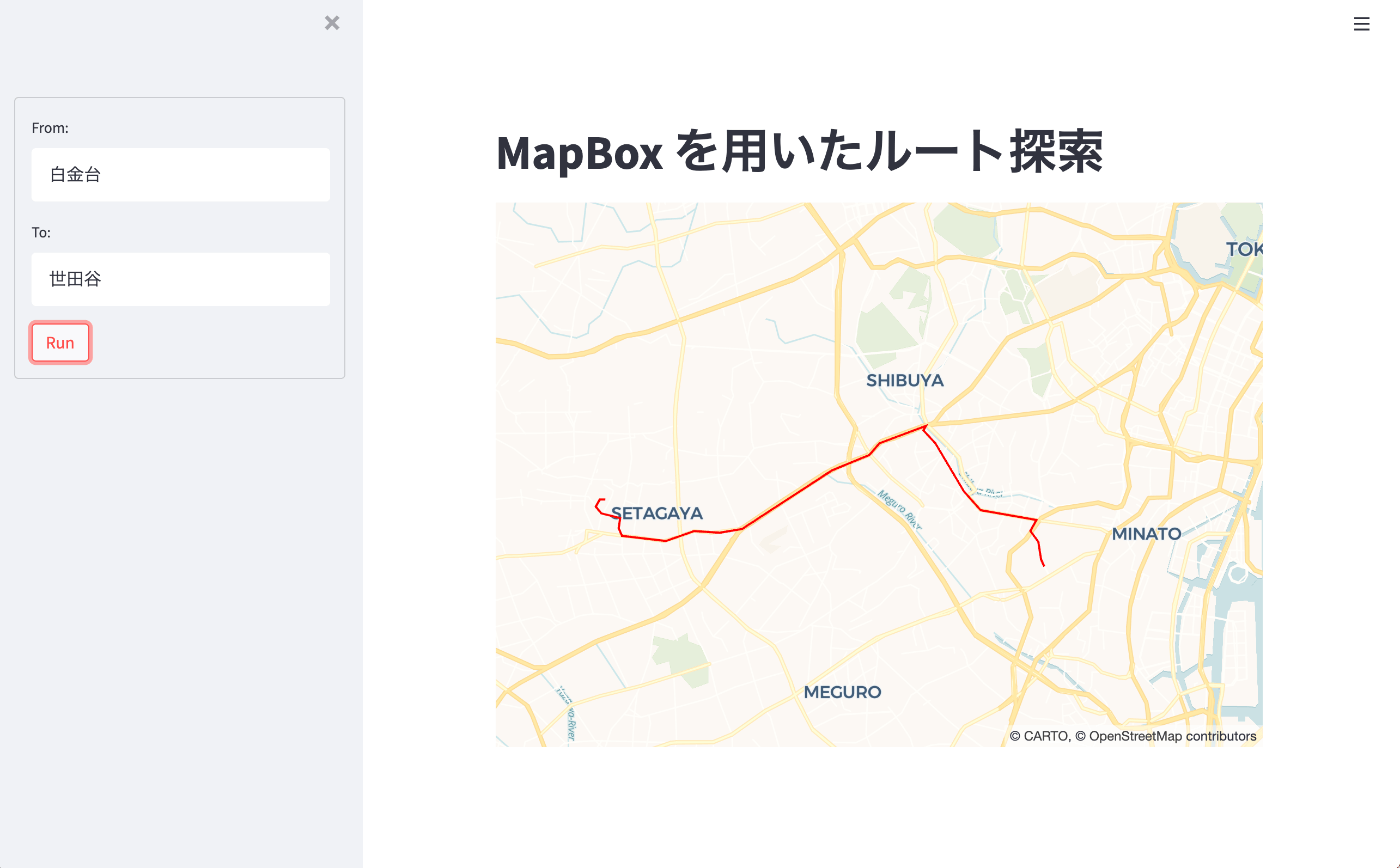
サンプルコード
import pandas as pd
import pydeck as pdk
import streamlit as st
import mapbox
def geocoding(address):
"""
ジオコーディング(住所からの座標検索)を行う
Arguments:
address {str} -- 住所
Returns:
list -- (緯度, 経度)
"""
api = mapbox.Geocoder()
res = api.forward(address)
return res.geojson()['features'][0]['geometry']['coordinates']
def get_path(origin, dest):
"""
MapBox APIを用いてルート探索を行う
Arguments:
origin {list} -- 出発地の緯度経度
dest {list} -- 到着地の緯度経度
Returns:
list -- ルート探索結果
"""
api = mapbox.Directions()
res = api.directions([{
'type': 'Feature',
'geometry': {
'type': 'Point',
'coordinates': origin
}
}, {
'type': 'Feature',
'geometry': {
'type': 'Point',
'coordinates': dest
}
}])
return res.geojson()['features'][0]['geometry']['coordinates']
def main():
with st.sidebar:
with st.form(key='input'):
origin_address = st.text_input('From:', '白金台')
dest_address = st.text_input('To:', '世田谷')
run = st.form_submit_button('Run')
st.markdown('# MapBox を用いたルート探索')
if run:
origin = geocoding(origin_address)
dest = geocoding(dest_address)
coordinates = get_path(origin, dest)
path = pd.DataFrame([{
'coordinates': coordinates
}]
)
view_state = pdk.ViewState(
longitude=origin[0],
latitude=origin[1],
zoom=11
)
path_layer = pdk.Layer(
type='PathLayer',
data=path,
get_color=(255, 0, 0),
width_scale=2,
width_min_pixels=2,
get_width=5,
get_path='coordinates'
)
deck = pdk.Deck(
layers=[path_layer],
initial_view_state=view_state,
map_style='road',
tooltip={'text': '{name}'}
)
st.pydeck_chart(deck)
if __name__ == '__main__':
main()
簡易的な認証・認可の機能をつける
Streamlit 自体には、認証・認可の機能はありません。簡単に認証機能を実現するには、認証が通った場合と通らなかった場合で表示する内容を変えることが考えられます。なお、この実装ではパスワードを平文で送ることになるので、proxy などを通じてHTTPS化する必要がありますし、あくまで簡易的なものである点に注意が必要です。
サンプルコード
import streamlit as st
import hashlib
SALT = 'aiueo:'
# 'password' をハッシュ化したもの
HASHED_PASSWORD = '246380e2b28d0898ff4b214ced62e851fee242112ae9a01a6ab49216194c0d7a'
def get_hash(password):
return hashlib.sha256((SALT + password).encode('utf-8')).hexdigest()
def check_password(password, hashed_password):
return get_hash(password) == hashed_password
def login():
placeholder = st.empty()
with placeholder.form('login'):
password = st.text_input('パスワード', type='password')
st.form_submit_button('ログイン')
if check_password(password, HASHED_PASSWORD):
placeholder.empty()
return True
else:
if password:
st.write('パスワードが違います')
return False
def main():
loggedin = login()
if loggedin:
st.write('Authenticated!')
if __name__ == '__main__':
main()
実際には、上記の簡易的な方法では不十分なことが多いと思います。アクセスの制限だけをすれば良く、ユーザー情報等が不要な場合は、 OAuth2 Proxy や IAP (Identity-Aware Proxy) を間に挟んでおまかせしてしまうのがお手軽で、かつ役割を分離できるのでおすすめです。アプリを実装する機械学習エンジニアやデータサイエンティストがセキュリティ周りも独自に実装するのは、多くの場合リスクでしかありません。なお、Streamlit は WebSocket を使っているので、 Proxy を使う場合には注意しましょう。
リクエストヘッダを取得する
上記のようにアクセス制御等を考え出すと、どうしてもリクエストヘッダにアクセスした句なることがあります。正式な機能としてはリリースされておらず、関連チケット もオープンのままですが、以下のようなコードで取得できます。
サンプルコード
import pandas as pd
import streamlit as st
from streamlit.server.server import Server
def main():
session_infos = Server.get_current()._session_info_by_id.values()
headers = [info.ws.request.headers for info in session_infos]
st.write(pd.DataFrame(headers).transpose())
if __name__ == '__main__':
main()
非同期処理を行う
機械学習関連のアプリを作成していると、長時間の演算が必要になることがあります。例えばユーザーの指定したパラメーターを使ってモデルを訓練するような状況です。Streamlit で普通に実装すると、演算中は右上に Running... と表示されて操作できない状態となります。そういった状況を避けるため、制御はいったん返し、バックグラウンドで演算を行いたいような状況があります。
Python で非同期処理を行う場合は、threading や multiprocessing を使って、スクリプト内で別スレッド/プロセスを立ち上げるのが普通ですが、Streamlitでは、その仕組み上そういったことができません。(2022/03/09 追記: できました) そこで、アプリとは独立のプロセスでワーカーを立ち上げておいて、プロセス間通信をおこないます。
$ python worker.py &
$ streamlit run app.py
こちらの記事(StreamlitとFastAPIで非同期推論MLアプリを作る) のように、HTTP経由としても良いでしょう。Streamlit のスクリプト内でプロセスを分離するのではなく、2つのプロセスを立てておくのがポイントです。
以下のコードはすこし長いですが、簡易的なジョブキューを構築して非同期処理を実現しています。もちろん、非同期にするだけであれば、ジョブキューにする必要はありません。ちなみに Python に標準で含まれている multiprocessing.managers.BaseManager を使うと別ホストのプロセスとも簡単に通信できます。
サンプルコード
import datetime
from multiprocessing import Queue
from multiprocessing.managers import BaseManager
import pathlib
import pickle
ARTIFACT_PATH = pathlib.Path('./artifacts')
QUEUE_HOST = '' # localhost
QUEUE_PORT = 6666
AUTH_KEY = b'1234'
class QueueManager(BaseManager):
pass
def _get_queue():
return queue
queue = Queue()
QueueManager.register(
'get_queue',
callable=_get_queue
)
def get_job_id():
return datetime.datetime.now().strftime('%Y-%m-%d_%H%M%S')
def get_jobs():
if not ARTIFACT_PATH.exists():
return []
jobs = [
path.stem
for path in ARTIFACT_PATH.iterdir()
if path.is_dir()
]
jobs.sort()
jobs.reverse()
return jobs
def put_job(*args):
manager = QueueManager(address=(QUEUE_HOST, QUEUE_PORT), authkey=b'1234')
manager.connect()
queue = manager.get_queue()
job_id = get_job_id()
queue.put((job_id, args))
return job_id
def get_job():
manager = QueueManager(address=(QUEUE_HOST, QUEUE_PORT), authkey=b'1234')
manager.connect()
queue = manager.get_queue()
return queue.get()
def save_artifact(name, data, job_id):
artifact_dir = ARTIFACT_PATH.joinpath(job_id)
if not artifact_dir.exists():
artifact_dir.mkdir(parents=True)
filepath = artifact_dir.joinpath(f'{name}.pkl')
with open(filepath, 'wb') as o_:
pickle.dump(data, o_)
def load_artifact(name, job_id):
artifact_dir = ARTIFACT_PATH.joinpath(job_id)
if not artifact_dir.exists():
raise ValueError(f'Artifact directory {artifact_dir} does not exist')
filepath = artifact_dir.joinpath(f'{name}.pkl')
with open(filepath,'rb') as i_:
return pickle.load(i_)
def serve():
manager = QueueManager(address=(QUEUE_HOST, QUEUE_PORT), authkey=AUTH_KEY)
server = manager.get_server()
server.serve_forever()
if __name__ == '__main__':
serve()
import time
import job_queue
def run():
while True:
job_id, args = job_queue.get_job()
# Long process
time.sleep(10)
# Do something
result = sum(args)
# save result
job_queue.save_artifact(
job_id=job_id,
name='result',
data={
'a': args[0],
'b': args[1],
'sum': result
}
)
def main():
run()
if __name__ == '__main__':
main()
import streamlit as st
import job_queue
def show_result(job_id):
job_result = job_queue.load_artifact(
job_id=job_id,
name='result'
)
st.write(job_result)
st.markdown(f'## {job_id}')
st.markdown(f'a: {job_result["a"]}')
st.markdown(f'b: {job_result["b"]}')
st.markdown(f'a + b: {job_result["sum"]}')
def main():
st.set_page_config(
page_title='job',
page_icon='.logo.png',
layout='wide',
initial_sidebar_state='auto'
)
with st.sidebar:
task_type = st.radio('', ('show results', 'put a new job'))
if task_type == 'show results':
job_id = st.selectbox('job', job_queue.get_jobs())
elif task_type == 'put a new job':
with st.form(key='job_form'):
st.markdown('和を計算します')
a = st.number_input('a', -1., 1., 0.1)
b = st.number_input('b', -1., 1., 0.9)
submit = st.form_submit_button('submit')
if task_type == 'show results':
if not job_id:
return
show_result(job_id)
elif task_type == 'put a new job':
if submit:
job_id = job_queue.put_job(a, b)
st.info(f'job {job_id} submitted.')
if __name__ == '__main__':
main()
Celery を使って本格的なジョブキューを作る
前述のように、ジョブキューを独自で実装することもできますが、諸々のことを考えると、実績のある Cerely を使うのが良いでしょう。Cerely を使う場合はブローカーとして ZeroMQ や Redis を準備する必要があります。例えば Redis を使う場合、開発時には Redis の Docker Image を使えば、Redis自体のインストールが不要となるのでお手軽です。
サンプルコード
version: "3"
services:
redis:
image: redis
ports:
- 6379:6379
import os
import pathlib
import pickle
import time
import datetime
import celery
ARTIFACT_PATH = pathlib.Path('data/artifacts')
if not ARTIFACT_PATH.exists():
ARTIFACT_PATH.mkdir(parents=True)
app = celery.Celery('celery')
if 'REDIS_URL' in os.environ:
app.conf.update(
broker_url=os.environ['REDIS_URL'],
result_backend=os.environ['REDIS_URL']
)
@app.task(name='add', bind=True)
def add(self: celery.Task, x, y):
start = datetime.datetime.now()
result = x + y
time.sleep(10)
end = datetime.datetime.now()
if self.request.id is not None:
filepath = ARTIFACT_PATH.joinpath(f'{self.request.id}.pkl')
with open(filepath, 'wb') as o_:
pickle.dump({
'id': self.request.id,
'task': self.name,
'start': start,
'end': end,
'result': result
},
o_
)
return result
import pickle
import pandas as pd
import streamlit as st
import worker
def get_results():
results = []
for file in worker.ARTIFACT_PATH.iterdir():
if file.name.startswith('.'): # 隠しファイルの除く
continue
with open(file, 'rb') as i_:
results.append(pickle.load(i_))
return results
def main():
st.write('Hello, Celery!')
with st.sidebar:
x = st.number_input('x')
y = st.number_input('y')
submit = st.button('submit')
if submit:
task_id = worker.add.delay(x, y)
st.write(f'task submitted: {task_id}')
results = get_results()
if results:
df = pd.DataFrame.from_records(results)
st.write(df)
# 何もしないボタンをつけておくと、画面更新に使えます
st.button('reload')
if __name__ == '__main__':
main()
Streamlit アプリを公開する
2021/11/2 に公開された Streamlit Cloud の機能を使うと、アプリを簡単に公開することができます。
アプリの公開機能は、もともと Streamlit Sharing と呼ばれて提供されていましたが、 使い勝手が大幅に改善され利用内容に応じた料金プランも設定されました。
使い方はとても簡単で、コードを GitHub にあげ、リポジトリとブランチ、ファイルを指定するだけです。コードを修正した場合も、GitHub に push するだけで自動的に更新されます。また、無料のコミュニティプランであっても、メールアドレスによるアクセス制御をしてくれるプライベートアプリを1つ作れます。

社内向けにお手軽にデプロイできる環境を作る
Streamlit Cloud は素晴らしいですが、データ連携のことを考えると、自前のサーバー上で動かしたくなることが多いかと思います。Dokku を使うとお手軽にデプロイできる環境を構築できます。Dokku は Heroku のような PaaS を構築できる OSS で、 Streamlit Cloud のように 「git push したらデプロイ」を簡単に実現できます。社内向けであれば、機械学習エンジニアやデータサイエンティストが Streamlit を使ってお手軽にアプリを作成し、 Dokku を使ってお手軽にデプロイするというプロセスは気持ちの良いものだと思います。
まとめ
Streamlit を使う上で、あれ?と思った時に書き溜めていたサンプルコードをもとに記事にしてみました。ベストプラクティスでないものもあると思いますが、参考にしてもらえればと思います。
最後に、 Streamlit はあくまでダッシュボードやプロトタイピングのためのツールで、ほどほどの柔軟性と素晴らしい開発体験が得られる一方、認証周りを含め本格的なアプリには向いていない側面もあります。どんなツールでもそうですが、適切な用法・用量を守ってお使いください。
Discussion
記事化ありがとうございます。
以下の部分は要らないみたいです。あるとselectboxのリロードが1回空振ってしまいました。