言語モデルはどのようにして知識を蓄えているのか? 関連文献の紹介
この記事は Ubie Engineering Advent Calendar 2023 15日目の記事です。私は現在、 新しいプロダクトのプロダクトオーナー (PO) として働きつつ、機械学習エンジニアとして大規模言語モデル(LLM)を活用する業務にも携わっています。Ubie は LLM にかなり力を入れており、社員の生産性向上 やプロダクトへの機能追加 など、色々なところで LLM が活用されています。
また、私が所属するチームでは、既存の大規模言語モデル(LLM)の活用に加えて、LLM 自体に関する理解を深め、知見を蓄積する取り組みも行っています。その中で特に「言語モデルはどのようにして知識を蓄えているのだろうか?」という問いは、非常に興味深いと感じました。そこで、この記事では、言語モデルと知識獲得に関する文献をいくつか紹介したいと思います。
知識ベースとしての言語モデル
そもそも「言語モデルはどのようにして知識を蓄えているのだろうか?」という文脈における「知識」とは何でしょうか。例えば
- オバマはハワイで生まれた
というのは一つの「知識」と言えるでしょう。この場合、 ①「オバマ大統領」と ②「ハワイ」という概念があり、その二つの関係が ③「出身地(生まれた)」である、というように、3つくらいの情報が、この1文に入っていそうです。
こういった「知識」は昔から知識ベースの一種である知識グラフという形で表現されることが多いようです。
知識グラフでは、(subject(主体), predicate(述語), object(対象)) という形式の3つ組(トリプレット)を用いて知識を表現します。例えば前述の「オバマはハワイで生まれた」という知識は、 (オバマ, 生まれた, ハワイ) というトリプレットで表現できます。トリプレットで保存しておけば、例えば、「オバマはどこで生まれたか?」という質問に対しては、 (オバマ, 生まれた, ・) で検索して「ハワイ」を得ることができます。また、 (・, 生まれた, ハワイ) で検索すれば、オバマを含むハワイ出身者を列挙できます。
では、言語モデルを使って「オバマはどこで生まれたか?」に回答するにはどうしたら良いでしょうか?答えは簡単で、例えば「オバマが生まれたのは <MASK> 」という形式のクエリを入力し、 <MASK> の部分に当てはまる単語やフレーズを予測させればよさそうです。
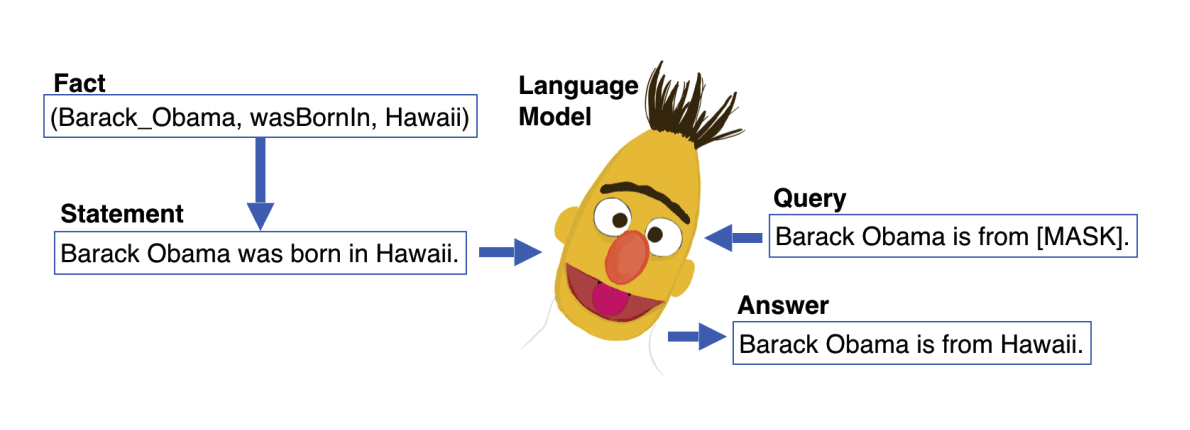
B. Heinzerling and K. Inui, Language Models as Knowledge Bases:
On Entity Representations, Storage Capacity, and Paraphrased Queries
以下の論文では、言語モデルを知識ベースとみなせるか、色々な角度から検証されています。
蓄えられる知識の容量
この論文では、隠れ層(もしくはパラメーター数)のサイズを変化させたときに、記憶できる知識の量を調べています。
下図は、<MASK> を予測するタスクにおいて、訓練時に入力する知識量を変化させ、80%以上の精度を保てる知識量をプロットしたものです[1]。隠れ層のサイズが大きいほど、多くの知識を蓄えられることがわかります。

柔軟な入力に対する対応
言語モデルを知識ベースとみなす場合、本当に知識を学習しているのかに注意して評価する必要があります。本論文では、言語モデルにおける記憶を以下の3種類に分け、事実の記憶を評価できるような問題設定にしています。
- 暗記
- 訓練データをそのまま記憶しているだけの状態。クエリを少し変更するだけで、正しい結果が得られなくなる
- 一般的な関連付け
- (object, predicate, subject) のうち、object と subject だけを記憶してしまっている状態。例えば (オバマ, 生まれた, ハワイ) というデータで訓練したにも関わらず、クエリに「オバマ」が含まれれば常にハワイを返してしまう
- 事実の記憶
- (object, predicate, subject) を(抽象化して)記憶しており、クエリの表現が訓練データとは異なる場合でも正解できる
以下の図は、「S was born in O」という表現のデータを作って訓練したモデルに対して、「S, who is from <MASK>」 のように、訓練時とは違う表現のクエリで評価した場合の精度をまとめています。また、事前訓練を行った場合(左)と、事前訓練なしで、ゼロから訓練した場合(右)も比較しています。柔軟な入力に対応するには、事前訓練が有用であることがわかります。
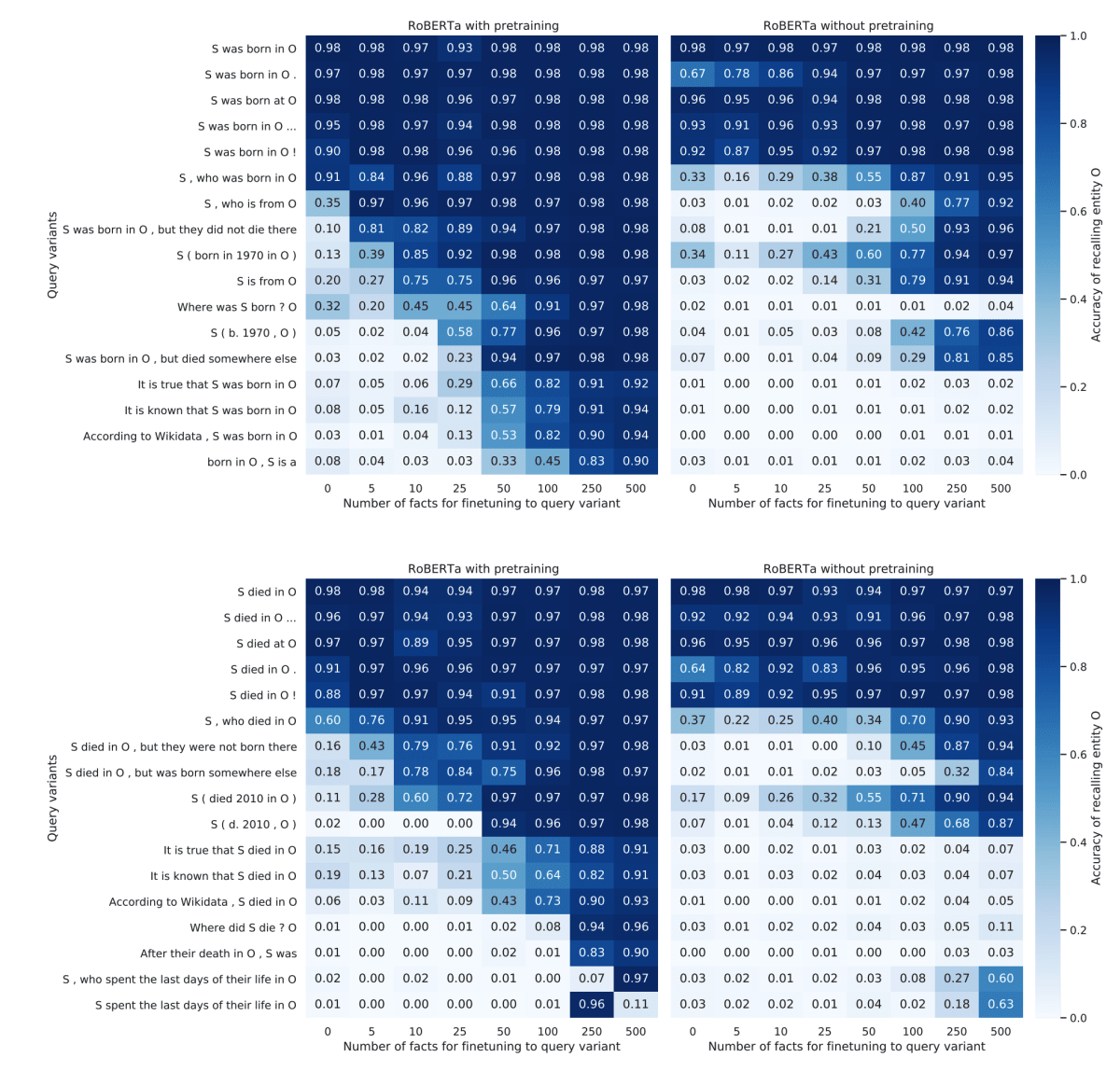
言語モデルにおいて知識はどのように蓄えられているか
さて、上記の論文で、言語モデルを知識ベースとみなせそうであることがわかりました。では、知識は言語モデルの中でどのように蓄えられているのでしょうか?
この論文では、特定の知識を担当する知識ニューロンという概念を導入しています。
Transformerベースの言語モデルは、大まかに「Self-Attention層」と「全結合層」で構成され、「Self-Attention層」ではトークン間の関係を計算し、「全結合層」では各トークン内での演算処理が行われます。
この論文では、事実知識(factual knowledge)は全結合層に蓄積されて知識ニューロンによって表現されるという仮説を立て、知識ニューロンを特定する方法を提案しています。
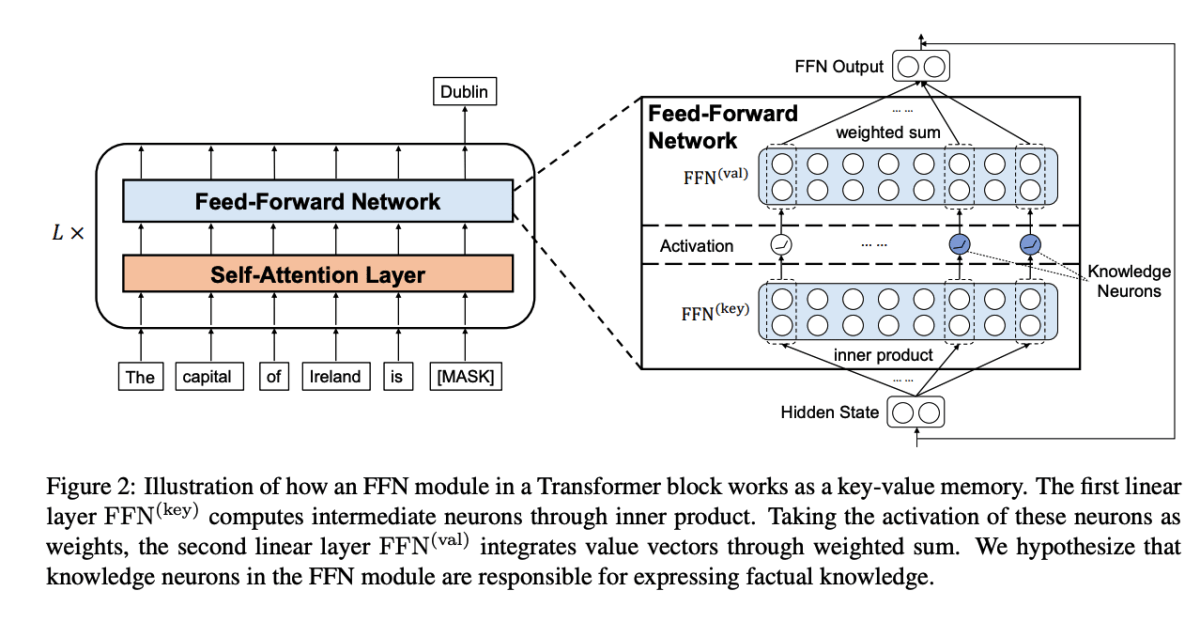
面白いのは、この論文の方法で特定された知識ニューロンをいじることで、言語モデルの出力を調整できることです。例えば
- 知識ニューロンの活性値を2倍にすると、該当する知識に関する正答率が大きく上がる
- 逆に知識ニューロンの活性値を小さくすると、該当する知識に関する正答率が大きく下がる
- 知識ニューロンに対応する重みベクトルを入れ替えると、知識も入れ替わる
- 知識ニューロンに対応する重みベクトルを
0
というように、ファインチューンイングなどの重い計算なしに、言語モデルを自由に調整できるそうです。
Symbol Tuning
最後に、少し毛色が違いますが Symbol Tuning と呼ばれる少し変わったファインチューンイング手法を紹介します。
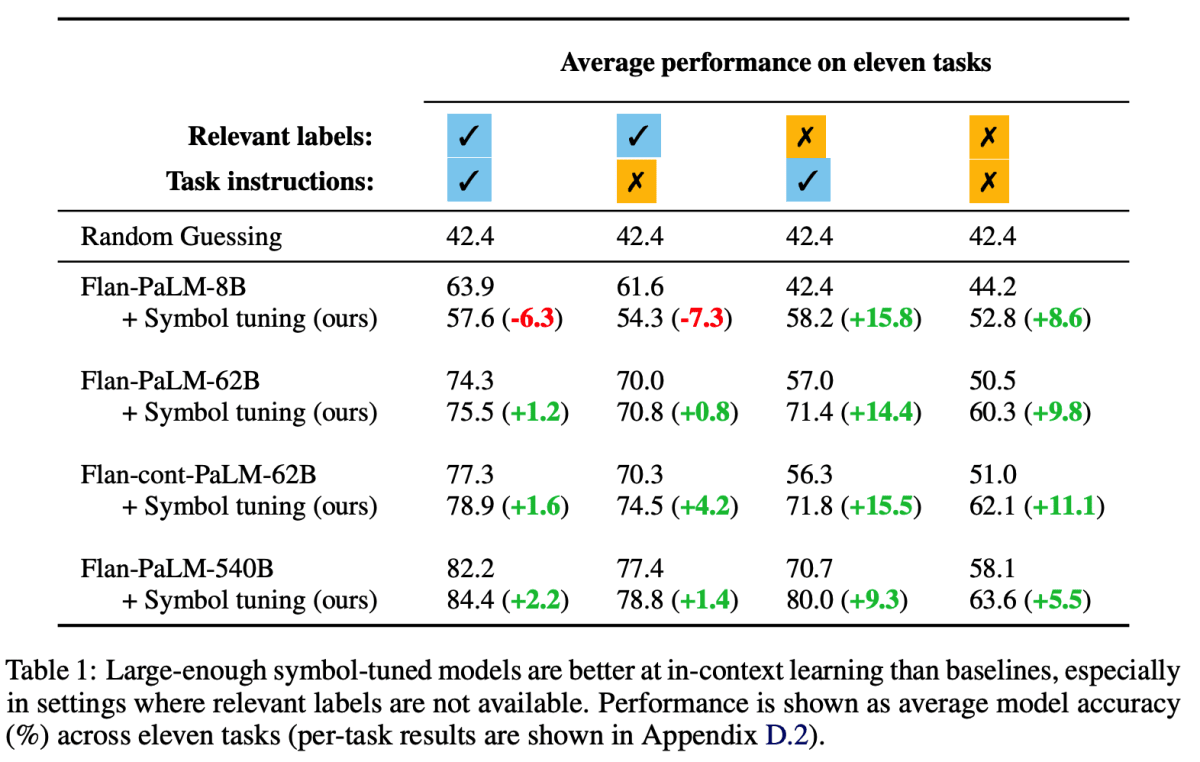
この論文では、few-shotの指示チューニングにおいて、指示をなくし、回答ラベルを全く関係ない単語に置き換えるだけで精度が上がるという主張がされています。

few-shotの指示チューニングでは、上図・左のように、複数の例(指示と入力、回答)に続いて指示と入力が与えられ、正しい回答ラベルを出力するように訓練します。Synmol Tuning では、指示をなく回答ラベルを全く関係ない単語に置き換えます(上図・右)。
通常の指示チューニングではせっかく複数の例が与えられているのに、それを活用しないで指示だけを見たり、回答ラベルについての知識を使って問題を解くことができるため、例と回答ラベルの関係をきちんと学習できないことがある、というのが理由のようです。指示の有無や回答ラベルの置き換えの有無によってチューニング結果を比較すると以下の図のようになり、特に回答ラベルの置き換えをすることで大幅な精度向上が見込めるようです。

知識ベースとしての言語モデルにおいて、単なる暗記ではなくて知識の記憶が必要であり、それを適切に評価する工夫がなされているという話をしました。ファインチューニングにおいても同様に、何をもって学習したと言えるのか、という点から手法を検討するのが大事だなと感じました。
まとめ
少しマニアックな記事になりましたが、「言語モデルはどのようにして知識を蓄えているのか」という観点で最近読んだ文献を紹介しました。LLMをいかに活用するか、事業にどのようにして組み込むか、というのも面白いテーマですし、言語モデル自体を深掘りしていくというのも、また面白いものです。
Ubieでは、LLMのプロダクト活用と生産性向上をより加速させるために、LLMアプリケーションエンジニアを募集しています。このポジションでは、LLMのプロダクト活用や社内生産性向上の観点で、顧客や社員にニーズをヒアリングして、プロトタイプを作成し、改善していくというプロセスを高速に回していきます。新技術に対する興味関心が高く、それらを素早く実装して顧客に届けたい方からのご応募を待っています。詳細は、下記のリンクよりご覧ください。
また、その他の職種でも一緒に働きたいメンバーをまだまだ募集しています(とくにデータ人材来てほしい...)。
カジュアル面談もできますので、お気軽にご登録ください
-
このグラフは Continuous Representation と呼ばれる表現方法を用いて実験したものです。埋め込み表現を見にいくなどしており、 <MASK> の単純な予測ではありませんが、記事ではわかりやすさのため「<MASK> を予測するタスク」としています。詳細は原論文を参照してください。 ↩︎
Discussion