Githubのリポジトリをフォルダツリーにしてみた
チュートリアルにフォルダツリーを表示させるセクションがあったので、Github のリポジトリを適応させてみました。
Svelte Tutorial の構成

チュートリアルの構成は以下のようになっています。
├─Folder.svelte
├─File.svelte
└─App.svelte
root変数にフォルダツリーを作成するためのオブジェクトが格納されています。データとして扱いづらいですがこのままのフォーマットで行きます。
<script>
import Folder from './Folder.svelte';
let root = [
{
name: 'Important work stuff',
files: [
{ name: 'quarterly-results.xlsx' }
]
},
{
name: 'Animal GIFs',
files: [
{
name: 'Dogs',
files: [
{ name: 'treadmill.gif' },
{ name: 'rope-jumping.gif' }
]
},
{
name: 'Goats',
files: [
{ name: 'parkour.gif' },
{ name: 'rampage.gif' }
]
},
{ name: 'cat-roomba.gif' },
{ name: 'duck-shuffle.gif' },
{ name: 'monkey-on-a-pig.gif' }
]
},
{ name: 'TODO.md' }
];
</script>
<Folder name="Home" files={root} expanded/>
チュートリアルではFolder.svelteの<!-- show folder -->となっているところを<svelte:self {...file}>に書き替えます。
以下のコードは書き換え済みです。
<script>
import File from './File.svelte';
export let expanded = false;
export let name;
export let files;
function toggle() {
expanded = !expanded;
}
</script>
<span class:expanded on:click={toggle}>{name}</span>
{#if expanded}
<ul>
{#each files as file}
<li>
{#if file.files}
<svelte:self {...file}/>
{:else}
<File {...file}/>
{/if}
</li>
{/each}
</ul>
{/if}
<style>
span {
padding: 0 0 0 1.5em;
background: url(/tutorial/icons/folder.svg) 0 0.1em no-repeat;
background-size: 1em 1em;
font-weight: bold;
cursor: pointer;
}
.expanded {
background-image: url(/tutorial/icons/folder-open.svg);
}
ul {
padding: 0.2em 0 0 0.5em;
margin: 0 0 0 0.5em;
list-style: none;
border-left: 1px solid #eee;
}
li {
padding: 0.2em 0;
}
</style>
このチュートリアルではファイルとフォルダのアイコンを使用しているみたいです。
<script>
export let name;
$: type = name.slice(name.lastIndexOf('.') + 1);
</script>
<span style="background-image: url(/tutorial/icons/{type}.svg)">{name}</span>
<style>
span {
padding: 0 0 0 1.5em;
background: 0 0.1em no-repeat;
background-size: 1em 1em;
}
</style>
プロジェクトの作成
今回は前回の記事をベースにしています。
構成は以下で、public/iconsにアイコンを拡張子.svgで保存しています。
├─public
│ ├─build
│ └─icons
│ ├─png.svg
│ └─...
└─src
├─components
│ ├─Folder.svelte
│ └─File.svelte
└─App.svelte
インストールします。
$ npx degit sveltejs/template <project-name>
$ cd <project-name>
$ npm install
$ npm install --save felte yup @felte/validator-yup
<script>の中身は前回とほぼ変わりません。
<script>
import { createForm } from 'felte'
import { validator } from '@felte/validator-yup'
import * as yup from 'yup'
import Folder from './components/Folder.svelte';
const schema = yup.object({
username: yup.string().required(),
repositoryName: yup.string().required(),
})
const { form, errors } = createForm({
extend: validator,
validateSchema: schema,
onSubmit: async (values) => {
send(JSON.stringify(values, null, 2))
},
})
let username;
let repositoryName;
let promise;
function send(bodyContent) {
promise = fetch("https://www.google.com/", {
mode: "cors",
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: bodyContent,
}).then((x) => x.json());
};
</script>
<form use:form on:submit|preventDefault autocomplete="off">
<input type="text" name="username" placeholder="username" bind:value="{username}"><br>
<input type="text" name="repositoryName" placeholder="repository" bind:value="{repositoryName}"><br>
<button type="submit">submit</button>
{JSON.stringify($errors)}
</form>
{#await promise}
Loading...
{:then data}
{#if data}
<Folder name="{repositoryName}" files={data} expanded/>
{:else}
nothing
{/if}
{:catch error}
{error}
{/await}
File.svelteとFolder.svelteのチュートリアルとの変更箇所は、アイコンまでのパスを/tutorial/icons/から/icons/にしたことだけです。
span {
padding: 0 0 0 1.5em;
background: url(/icons/folder.svg) 0 0.1em no-repeat;
font-weight: bold;
cursor: pointer;
}
これで Svelte 側の実装は終わりました。
Github リポジトリ情報を取得する
Github Docs のREST API を使ってみる - GitHub Docsにリポジトリ情報を取得する方法があったのでこれを使います。
ただしリポジトリに含まれるファイルやフォルダの情報は取得できないようで、デフォルトブランチの取得をこのコマンドを実行して行います。ファイルとフォルダの取得はスクレイピングで行います。
今回使うライブラリはrequestsとbs4です。
$ pip3 install requests
$ pip3 install bs4
Lambda 関数を定義します。usernameとrepository_nameは Svelte から送信された値です。requests.get()で実行した結果をresponseに格納すると、実行結果をresponse.json()で取得できます。これはリストになっていて、初めのインデックスにデフォルトブランチが含まれています。
import ast
from urllib.parse import urljoin
import requests
def lambda_handler(event, content):
data = ast.literal_eval(event["body"])
username = data["userName"]
repository_name = data["repositoryName"]
repository_path = f"/{username}/{repository_name}"
response = requests.get(urljoin("https://api.github.com/users/", repository_path))
data = response.json()
default_branch = data[0]["default_branch"]
対象とするリポジトリがプライベートだった場合は403エラーが発生し、存在しない場合は404エラーが発生します。しかしrequests.get()を実行してもエラーが発生しないので、raise_for_status()で200番台以外でエラーを発生させます。
response.raise_for_status()
403と404でエラーメッセージを分けるので、エラーハンドラークラスを作成します。
class LambdaException(Exception):
def __init__(self, status_code: int, error_message: str) -> None:
self.status_code = status_code
self.error_message = error_message
def __str__(self):
return {
"statusCode": self.status_code,
"errorMessage": self.error_message
}
ここまでの Lambda 関数をまとめます。
import ast
import json
from urllib.parse import urljoin
from bs4 import BeautifulSoup
import requests
from requests.exceptions import RequestException, HTTPError
class LambdaException(Exception):
def __init__(self, status_code: int, error_message: str) -> None:
self.status_code = status_code
self.error_message = error_message
def __str__(self):
return {
"statusCode": self.status_code,
"errorMessage": self.error_message
}
def lambda_handler(event, content):
data = ast.literal_eval(event["body"])
username = data["userName"]
repository_name = data["repositoryName"]
repository_path = f"/{username}/{repository_name}"
response = requests.get(urljoin("https://api.github.com/users/", repository_path))
try:
response.raise_for_status()
except HTTPError as e:
raise LambdaException(403, str(e))
except RequestException as e:
raise LambdaException(404, str(e))
else:
data = response.json()
default_branch = data[0]["default_branch"]
body_cotent = GenerateTree(username, repository_name, repository_path, default_branch)
return {
"statusCode": 200,
"headers": {
"Access-Control-Allow-Headers": "Content-Type",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "OPTIONS,POST"
},
"body": json.dumps(body_cotent)
}
フォルダツリーを返すクラスの作成
次にリポジトリ内のフォルダとファイルからフォルダツリーを返すクラスを作成します。
import json
from typing import List, Dict
from urllib.parse import urljoin
from bs4 import BeautifulSoup
import requests
class GenerateTree:
def __init__(self, username: str, repository_name: str, repository_path: str, default_branch: str) -> None:
self.username = username
self.repository_name = repository_name
self.repository_path = repository_path
self.default_branch = default_branch
self.folders = []
files_or_folders = self.get_first_level_files_or_folders()
for file_or_folder in files_or_folders:
self.below_second_level(file_or_folder)
def below_second_level(self, path: str) -> None:
file_or_folder = path \
.replace(f"{self.repository_path}/blob/{self.default_branch}/", "") \
.replace(f"{self.repository_path}/tree/{self.default_branch}/", "") \
result = {
"name": file_or_folder,
"files": []
}
blob_or_tree_path = path \
.replace(f"{self.repository_path}/tree", self.repository_path) \
.replace(f"{self.repository_path}/blob", self.repository_path) \
.split("/")
blob_path = blob_or_tree_path.copy()
tree_path = blob_or_tree_path.copy()
blob_path.insert(3, "blob")
tree_path.insert(3, "tree")
blob_path = "/".join(blob_path)
tree_path = "/".join(tree_path)
html = requests.get(urljoin("https://github.com/", path))
soup = BeautifulSoup(html.content, "html.parser")
paths_for_repository = [i.get("href") for i in soup.find_all("a")]
process = [f"url.startswith('{i}')" for i in [blob_path, tree_path]]
process_word = " or ".join(process)
next_paths = []
for url in paths_for_repository:
if eval(process_word):
if not url.startswith(path):
result["files"].append({"name": url.split("/")[-1]})
next_paths.append(url)
elif "/" in url.replace(path, ""):
result["files"].append({"name": url.split("/")[-1]})
next_paths.append(url)
if not result["files"]:
result.pop("files")
else:
self.folders.append(result)
for next_path in next_paths:
self.below_second_level(next_path)
def get_first_level_files_or_folders(self) -> List[str]:
url = urljoin("https://github.com/", self.repository_path)
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
paths_for_repository = [i.get("href") for i in soup.find_all("a")]
process = [f"url.startswith('{self.repository_path}/{i}/{self.default_branch}')" for i in ["blob", "tree"]]
process_word = " or ".join(process)
result = set()
for url in paths_for_repository:
if eval(process_word):
if url.count("/") == 5:
result.add(url)
return result
def __call__(self) -> Dict[str, list]:
for parents in self.folders:
for search_target in self.folders:
if search_target["name"].startswith(f"{parents['name']}/"):
count = 0
child = search_target["name"].split("/")[-1]
for parent in parents["files"]:
if parent["name"] == child:
parents["files"].pop(count)
count += 1
parents["files"].append({
"name": child,
"files": search_target["files"]
})
self.folders = list(filter(lambda x: not "/" in x["name"], self.folders))
return {
self.repository_name: self.folders
}
リポジトリの一番上の階層とそれ以下の階層で URL の構造が異なるので、メソッドを分けています。以下のような流れになっています。
- 第 1 階層のフォルダ・ファイルの取得
- 1 で取得したフォルダ・ファイル名を第 2 階層以降のフォルダ・ファイルを扱うメソッドに渡す
- 第 2 階層以降を扱うメソッドが再帰的にフォルダ・ファイルを取得し、リストに格納する
-
__call__メソッドが呼び出されたタイミングでフォルダツリーを作成し返す
第 1 階層のフォルダ・ファイルの取得し、第 2 階層以降のフォルダ・ファイルを扱うメソッドに渡す
__init__はlambda_handlerからユーザー名、リポジトリ名、リポジトリパス、デフォルトブランチを引数にとります。リポジトリパスは/[username]/[repository_name]/という形になっています。
def __init__(self, username: str, repository_name: str, repository_path: str, default_branch: str) -> None:
self.username = username
self.repository_name = repository_name
self.repository_path = repository_path
self.default_branch = default_branch
self.folders = []
files_or_folders = self.get_first_level_files_or_folders()
for file_or_folder in files_or_folders:
self.below_second_level(file_or_folder)
ファイルはblob、フォルダはtreeが URL に含まれていて、長いのでevalで処理します。<a>タグをfind_all()で取得した場合に得られる URL から第 2 階層のフォルダ・ファイルを判断するには/を使います。
/の含まれる数が 5 個の場合は第 2 階層です。
/[username]/[repository_name]/[blob or tree]/[default_branch]/[second level]
def get_first_level_files_or_folders(self) -> List[str]:
url = urljoin("https://github.com/", self.repository_path)
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
paths_for_repository = [i.get("href") for i in soup.find_all("a")]
process = [f"url.startswith('{self.repository_path}/{i}/{self.default_branch}')" for i in ["blob", "tree"]]
process_word = " or ".join(process)
result = set()
for url in paths_for_repository:
if eval(process_word):
if url.count("/") == 5:
result.add(url)
return result
再帰的にフォルダ・ファイルを取得し、リストに格納する
処理としては、第 1 階層の時とほぼ同じです。フォルダツリーを作成するためにresultをself.foldersに格納していきます。foldersの要素数がない辞書は、ファイルがフォルダとして扱われてしまうのでfilesを削除します。
def below_second_level(self, path: str) -> None:
file_or_folder = path \
.replace(f"{self.repository_path}/blob/{self.default_branch}/", "") \
.replace(f"{self.repository_path}/tree/{self.default_branch}/", "") \
result = {
"name": file_or_folder,
"files": []
}
blob_or_tree_path = path \
.replace(f"{self.repository_path}/tree", self.repository_path) \
.replace(f"{self.repository_path}/blob", self.repository_path) \
.split("/")
blob_path = blob_or_tree_path.copy()
tree_path = blob_or_tree_path.copy()
blob_path.insert(3, "blob")
tree_path.insert(3, "tree")
blob_path = "/".join(blob_path)
tree_path = "/".join(tree_path)
html = requests.get(urljoin("https://github.com/", path))
soup = BeautifulSoup(html.content, "html.parser")
paths_for_repository = [i.get("href") for i in soup.find_all("a")]
process = [f"url.startswith('{i}')" for i in [blob_path, tree_path]]
process_word = " or ".join(process)
next_paths = []
for url in paths_for_repository:
if eval(process_word):
if not url.startswith(path):
result["files"].append({"name": url.split("/")[-1]})
next_paths.append(url)
elif "/" in url.replace(path, ""):
result["files"].append({"name": url.split("/")[-1]})
next_paths.append(url)
if not result["files"]:
result.pop("files")
else:
self.folders.append(result)
for next_path in next_paths:
self.below_second_level(next_path)
フォルダツリーを作成する
self.foldersを展開してnameに/を含むものを親のfiles内に格納していきます。filterを使ってnameに/を含むものを削除しています。
def __call__(self) -> Dict[str, list]:
for parents in self.folders:
for search_target in self.folders:
if search_target["name"].startswith(f"{parents['name']}/"):
count = 0
child = search_target["name"].split("/")[-1]
for parent in parents["files"]:
if parent["name"] == child:
parents["files"].pop(count)
count += 1
parents["files"].append({
"name": child,
"files": search_target["files"]
})
self.folders = list(filter(lambda x: not "/" in x["name"], self.folders))
return {
self.repository_name: self.folders
}
lambda_function.py
import ast
import json
from typing import List, Dict
from urllib.parse import urljoin
from bs4 import BeautifulSoup
import requests
from requests.exceptions import RequestException, HTTPError
class LambdaException(Exception):
def __init__(self, status_code: int, error_message: str) -> None:
self.status_code = status_code
self.error_message = error_message
def __str__(self):
return {
"statusCode": self.status_code,
"errorMessage": self.error_message
}
class GenerateTree:
def __init__(self, username: str, repository_name: str, repository_path: str, default_branch: str) -> None:
self.username = username
self.repository_name = repository_name
self.repository_path = repository_path
self.default_branch = default_branch
self.folders = []
files_or_folders = self.get_first_level_files_or_folders()
for file_or_folder in files_or_folders:
self.below_second_level(file_or_folder)
def below_second_level(self, path: str) -> None:
file_or_folder = path \
.replace(f"{self.repository_path}/blob/{self.default_branch}/", "") \
.replace(f"{self.repository_path}/tree/{self.default_branch}/", "") \
result = {
"name": file_or_folder,
"files": []
}
blob_or_tree_path = path \
.replace(f"{self.repository_path}/tree", self.repository_path) \
.replace(f"{self.repository_path}/blob", self.repository_path) \
.split("/")
blob_path = blob_or_tree_path.copy()
tree_path = blob_or_tree_path.copy()
blob_path.insert(3, "blob")
tree_path.insert(3, "tree")
blob_path = "/".join(blob_path)
tree_path = "/".join(tree_path)
html = requests.get(urljoin("https://github.com/", path))
soup = BeautifulSoup(html.content, "html.parser")
paths_for_repository = [i.get("href") for i in soup.find_all("a")]
process = [f"url.startswith('{i}')" for i in [blob_path, tree_path]]
process_word = " or ".join(process)
next_paths = []
for url in paths_for_repository:
if eval(process_word):
if not url.startswith(path):
result["files"].append({"name": url.split("/")[-1]})
next_paths.append(url)
elif "/" in url.replace(path, ""):
result["files"].append({"name": url.split("/")[-1]})
next_paths.append(url)
if not result["files"]:
result.pop("files")
else:
self.folders.append(result)
for next_path in next_paths:
self.below_second_level(next_path)
def get_first_level_files_or_folders(self) -> List[str]:
repository_path = f"/{self.username}/{self.repository_name}"
url = urljoin("https://github.com/", self.repository_path)
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
paths_for_repository = [i.get("href") for i in soup.find_all("a")]
process = [f"url.startswith('{self.repository_path}/{i}/{self.default_branch}')" for i in ["blob", "tree"]]
process_word = " or ".join(process)
result = set()
for url in paths_for_repository:
if eval(process_word):
if url.count("/") == 5:
result.add(url)
return result
def __call__(self) -> Dict[str, list]:
for parents in self.folders:
for search_target in self.folders:
if search_target["name"].startswith(f"{parents['name']}/"):
count = 0
child = search_target["name"].split("/")[-1]
for parent in parents["files"]:
if parent["name"] == child:
parents["files"].pop(count)
count += 1
parents["files"].append({
"name": child,
"files": search_target["files"]
})
self.folders = list(filter(lambda x: not "/" in x["name"], self.folders))
return {
self.repository_name: self.folders
}
def lambda_handler(event, content):
data = ast.literal_eval(event["body"])
username = data["userName"]
repository_name = data["repositoryName"]
repository_path = f"/{username}/{repository_name}"
response = requests.get(urljoin("https://api.github.com/users/", repository_path))
try:
response.raise_for_status()
except HTTPError as e:
raise LambdaException(403, str(e))
except RequestException as e:
raise LambdaException(404, str(e))
else:
data = response.json()
default_branch = data[0]["default_branch"]
body_cotent = GenerateTree(username, repository_name, repository_path, default_branch)
return {
"statusCode": 200,
"headers": {
"Access-Control-Allow-Headers": "Content-Type",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "OPTIONS,POST"
},
"body": json.dumps(body_cotent)
}
実行
ローカルからですが実行してみます。
if __name__ == "__main__":
import pprint
result = GenerateTree("ogty", "requirements.txt-generator", "/ogty/requirements.txt-generator", "master")
pprint.pprint(result())
実行すると以下の結果が得られました。
{'requirements.txt-generator': [{'files': [{'name': 'config.json'},
{'files': [{'name': 'main.css'},
{'name': 'style.min.css'}],
'name': 'css'},
{'files': [{'name': '32px.png'},
{'name': 'demo.gif'},
{'name': 'download_for_linux.png'},
{'name': 'download_for_mac.png'},
{'name': 'download_for_windows.png'},
{'name': 'file_type_pip.png'},
{'name': 'launch_in_browser.png'},
{'name': 'throbber.gif'}],
'name': 'images'},
{'files': [{'name': 'jstree.min.js'},
{'name': 'main.js'}],
'name': 'js'}],
'name': 'static'},
{'name': 'requirements.txt'},
{'name': 'settings.py'},
{'name': 'app.py'},
{'name': 'LICENSE'},
{'name': '.gitignore'},
{'files': [{'name': 'base.py'},
{'name': 'routes.py'}],
'name': 'src'},
{'files': [{'name': 'main.py'},
{'name': 'test_install.py'}],
'name': 'test'},
{'name': 'README.md'},
{'name': 'main.py'},
{'files': [{'name': 'main.html'}],
'name': 'templates'}]}
ちなみにかかった時間は16.72573733329773秒でした...
結果
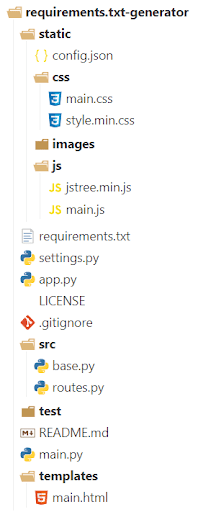
icon には vscode-icons を使っています。
Discussion