SQLアンチパターン 要約 第一部
SQLアンチパターンを読んだ際の学習ノートです。本書は4部に分けられており、学習メモ1では第一部「データベース論理設計のアンチパターン」をまとめます。
1章 ジェイウォーク(信号無視)
適切に交差テーブルを利用しないことで発生するアンチパターンです。
交差テーブル(intersection)を無視するため、ジェイウォーク(信号無視)と名付けられたそうです。
目的
productテーブルにお問い合わせ用のアカウントのaccount_idを複数設定できるようにしたいです。
アンチパターン: カンマ区切りフォーマットのリストを格納する
以下のようにaccount_idをカンマ区切りで複数繋ぎ合わせて文字列として格納するのはアンチパターンになります。
CREATE TABLE product (
product_id SERIAL PRIMARY KEY
account_id VARCHAR(100) -- 例:`125,2030,99,3`
)
何がまずいか
-
account_idを使った検索や結合に正規表現などによる工夫が必要になります。 - インデックスを効果的に利用できないのでパフォーマンスが落ちます。
-
account_idに複数のアカウントIDを入れる場合にサイズ上限に引っかかる可能性があります。 - 集約クエリ(SUM、COUNT、AVGなど)が使えなくなります。
- アカウントIDの追加や削除、更新ではアプリ側での文字列操作が必要になります。
- バリデーションがアプリ側で必要で、アカウントIDとは全く関係のない"banana"のような文字列が入る危険性があります。
アンチパターンを用いても良いかもしれない例
アプリケーション側でカンマ区切りフォーマットのデータが必要で、各要素への個別アクセスが不要な時。
解決策
productテーブルにアカウントを入れるのではなく、交差テーブルとしてContactsテーブルを作ってあげるのが良さそうです。
CREATE TABLE Contacts (
product_id BIGINT UNSIGNED NOT NULL,
account_id BIGINT UNSIGNED NOT NULL,
PRIMARY KEY (product_id, account_id),
FOREIGN KEY product_id REFERENCES products(product_id),
FOREIGN KEY account_id REFERENCES accounts(account_id)
)
こちらの方が、
- より柔軟なクエリ発行
- より効果的なインデックス
などのメリットがあります。
2章 ナイーブな木(素朴な木)
誰もが思いつくであろう、各行にparent_idを持たせる方法です。
目的
再帰的な関連をもつデータを管理したいです。例えば、コメントに対するコメントを書く事ができるスレッド形式のコメント欄などです。
他の例としては従業員の上下関係を表す組織図もあげられます。ここではスレッド形式のコメント欄を例として取り上げます。
アンチパターン: 常に親のみに依存する
木構造のデータを管理するため誰しもが最初に思いつくであろう、常に親のみに依存するテーブル設計はアンチパターンとなる可能性があります。
以下の例では各コメントはparent_idに親ノードのコメントのcomment_idを格納しています。
CREATE TABLE comments (
comment_id SERIAL PRIMARY KEY,
parent_id BIGINT UNSIGNED,
comment TEXT NOT NULL,
FOREIGN KEY (parent_id) REFERENCES Comments(comment_id)
)
何がまずいか
サブツリーへのCOUNTやSUMといったクエリを打つのに同じクエリで複数のOUTER JOINを含むことになります。
以下はcomment_idが1のサブツリーのサイズを調べようとしているのですが、以下のようにLEFT JOINが連なっています。
さらに残念なことに深さによってはこれでは正しい値を取得できない可能性があります。
SELECT COUNT(*)
FROM comments AS c1
LEFT JOIN comments AS c2 ON c2.parent_id = c1.comment_id
LEFT JOIN comments AS c3 ON c3.parent_id = c2.comment_id
LEFT JOIN comments AS c4 ON c4.parent_id = c3.comment_id
LEFT JOIN comments AS c5 ON c5.parent_id = c4.comment_id
WHERE c1.comment_id = 1;
また、削除が難しくなるという欠点もあります。
- 非葉ノードの削除では先にこのノードの
parent_idを付け替える必要 - (外部キー制約がある場合)サブツリーの削除では複数回のSELECTクエリののち、子孫のノードから消していく必要
アンチパターンを用いても良いかもしれない例
アンチパターンを用いても良い例もあります。
- ノードの直近の親と子を取得するだけで良い時
- 再帰クエリ構文が利用できる場合(MySQL8.0、PostgreSQL8.4など)
WITH RECURSIVE descendants AS (
SELECT comment_id, parent_id, comment
FROM comments
WHERE parent_id = 1
UNION ALL
SELECT c.comment_id, c.parent_id, c.comment
FROM comments c
INNER JOIN descendants d ON c.parent_id = d.comment_id
)
SELECT *
FROM descendants;
解決策
ナイーブツリーに決定する前に、代替となるツリーモデルを検討すると良さそうです。
ここでは経路列挙モデル、入れ子集合モデル、閉包テーブルモデルの3つを紹介します。
経路列挙モデル
pathカラムに経路を文字列で入れる方法です。pathに入る値は1/や1/2/,1/4/6/7などとなります。
CREATE TABLE Comments (
comment_id SERIAL PRIMARY KEY,
path VARCHAR(1000)
)
コメント7の経路が1/4/6/7の時、その先祖を取得するには以下のようにします。
%は0文字以上の任意マッチのワイルドパターンで、||は文字列結合演算子です。
SELECT *
FROM Comments AS c
WHERE '1/4/6/7' LIKE c.path || '%';
コメント4の経路が1/4の時、子孫を取得するには以下のクエリです。
SELECT *
FROM Comments AS c
WHERE c.path LIKE '1/4/' || '%';
挿入の時は親のpathをコピーして追加する必要があります。
ジェイウォークと同様の弱点があることに注意が必要です。
- 中身の正確性は保証できません
- メンテナンスはアプリケーションコードに依存します
- VARCHARの長さに引っかかる可能性があります
入れ子集合(Nested Set)
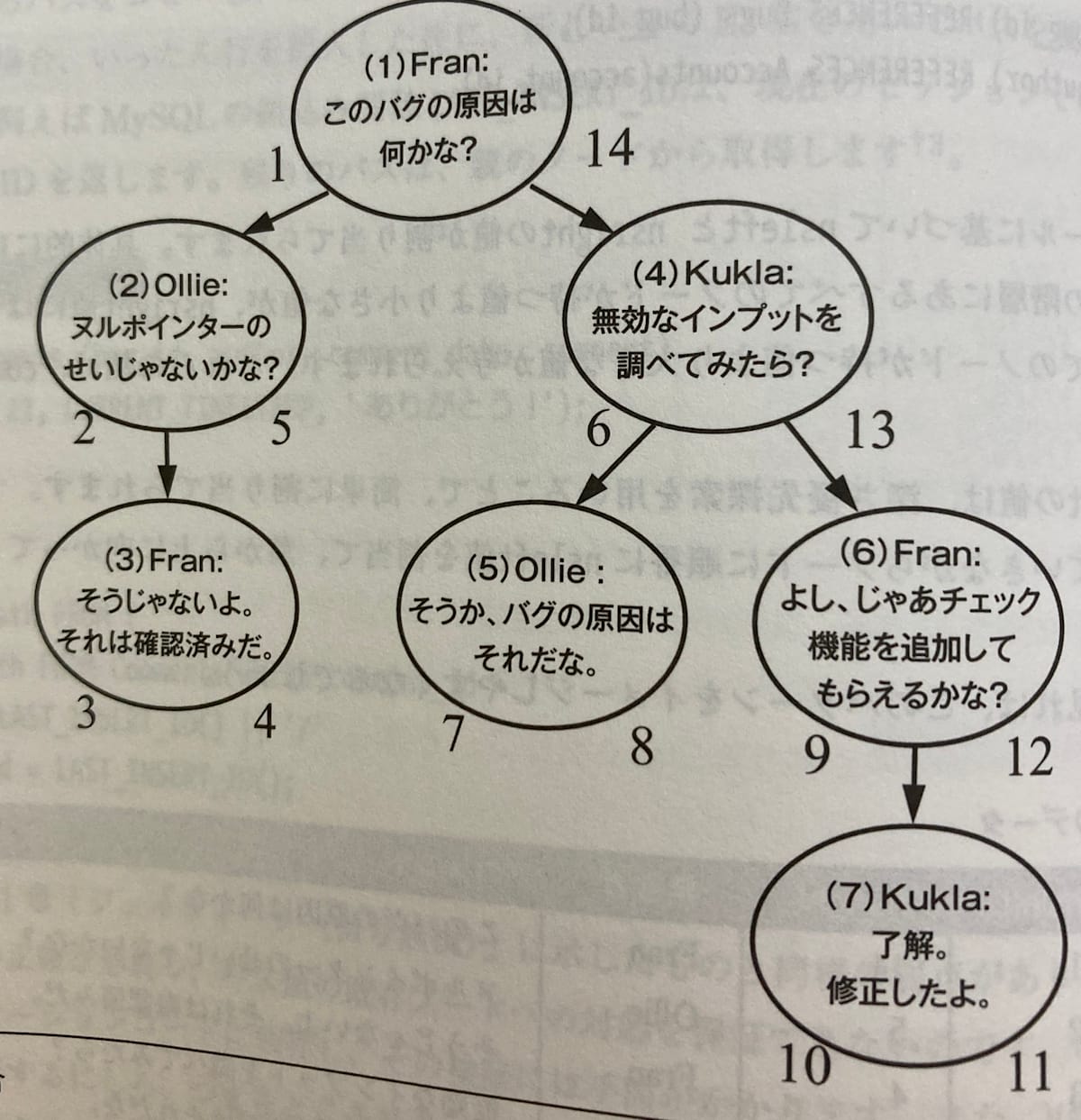

入れ子集合は親ではなく子孫のidの範囲を保持します。この構造はほとんどノードの挿入や変更がない場合には有効となります。
CREATE TABLE Comments (
comment_id SERIAL PRIMARY KEY,
nsleft INTEGER NOT NULL,
nsright INTEGER NOT NULL
)
コメント4とその子孫を取得する場合はコメント4のnsleftとnsrightの間に、nsleftを含むノードすべてを検索すれば良いです。
SELECT c2.*
FROM Comments AS c1
INNER JOIN Comments as c2
ON c2.nsleft BETWEEN c1.nsleft AND c1.nsright
WHERE c1.comment_id = 4;
逆にコメント6の先祖を取得するにはコメント6のnsleftを、nsleftとnsrightの間に含むノードを検索します。
SELECT c2.*
FROM Comments AS c1
INNER JOIN Comments as c2
ON c1.nsleft BETWEEN c2.nsleft AND c2.nsright
WHERE c1.comment_id = 6;
メリットとしては、非葉ノードを削除した際に特に処理をすることなく子ノードを親ノードにつけることができることや、深さの計算が容易である事が挙げられます。
一方で、隣接する親や子ノードの検索が複雑になったり、
ノードの挿入時にnsleft, nsrightを書き換えてスペースを開けるといった複雑なことが必要になるというデメリットがあります。
したがって、入れ子集合が適しているのは個々のノードの操作ではなく、サブツリーに対する迅速なクエリ実行が重要な場合と言えるでしょう。
閉包テーブル(Closure Table)
閉包テーブルはCommentsテーブルに加えてTreePathsテーブルを新たに作り、ツリー全体のパスを格納する方法です。
CREATE TABLE TreePaths (
ancester BIGINT UNSIGNED NOT NULL,
descendant BIGINT UNSIGNED NOT NULL,
PRIMARY KEY (ancester, descendant),
FOREINGN KEY (ancester) REFERENCES Comments(comment_id),
FOREIGN KEY (descendant) REFERENCES Comments(comment_id)
);
各行には先祖/子孫関係を共有するノードの組み合わせがすべて格納されます。
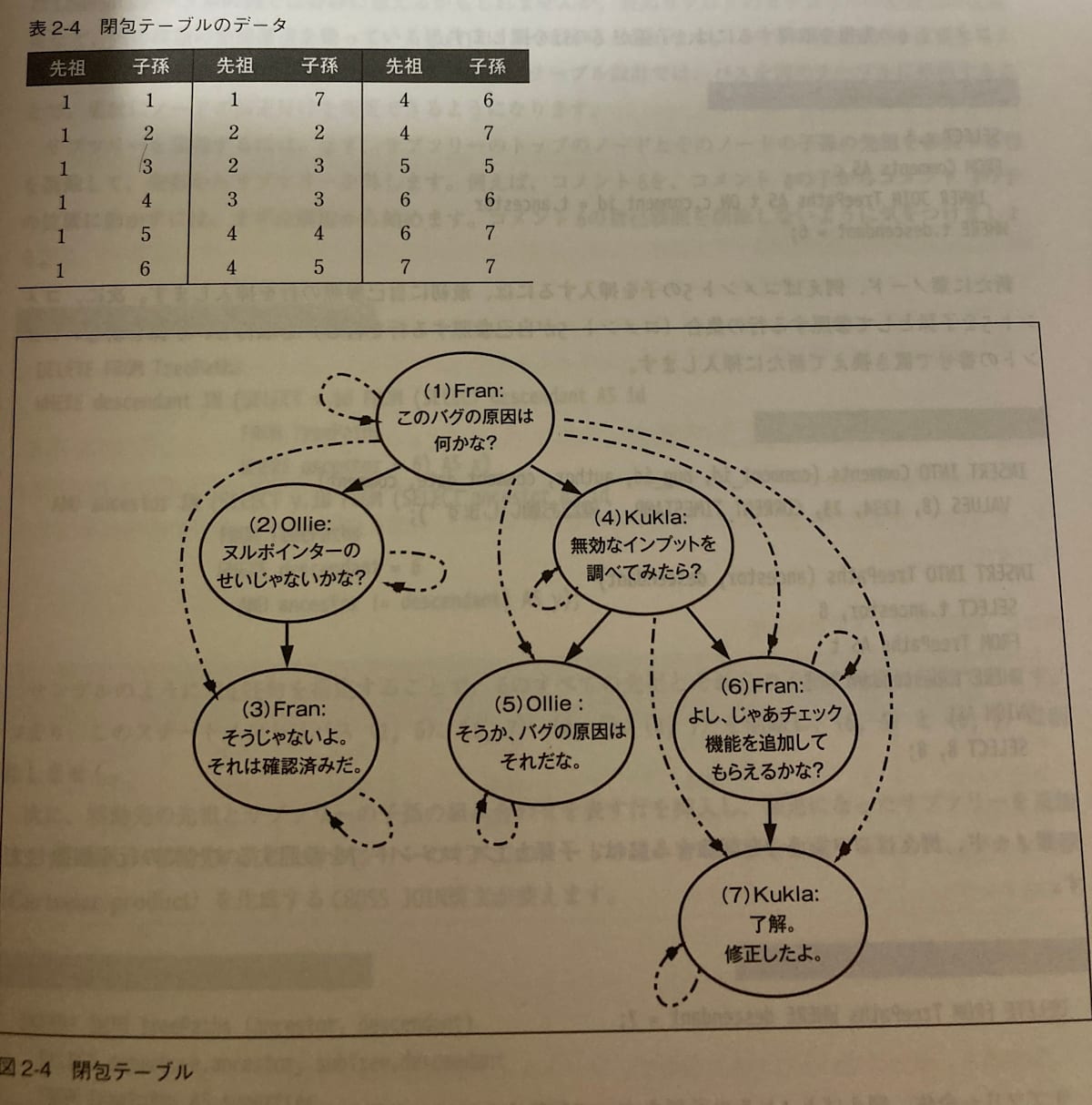
先祖、子孫の列挙はかなり簡単で、例えばコメント4の子孫を探すにはancesterに4が入っているものを探せば良いです。
SELECT c.*
FROM Comments AS c
INNER JOIN TreePaths AS t ON c.comment_id = t.decendant
WHERE t.ancestor = 4;
先祖を探す時も似たクエリでできます。
SELECT c.*
FROM Comments AS c
INNER JOIN TreePaths AS t ON c.comment_id = t.ancestor
WHERE t.decendant = 4;
挿入については親の祖先を列挙して、新たにインサート&自己参照を作ればokです。以下のクエリではコメント5の下に8を入れています。
INSERT INTO TreePaths (ancestor, descendant)
SELECT t.ancestor, 8
FROM TreePaths
WHERE t.descendant = 5
UNION ALL
SELECT 8, 8;
葉ノードの削除には子孫として参照するすべての行を削除します。(ここではコメント7を削除)
DELETE FROM TreePaths WHERE descendant = 7;
サブツリーの削除は子孫を列挙してそのコメントと子孫をdescendantに含む行をすべて消します。(ここではコメント4のサブツリー)
DELETE FROM TreePaths
WHERE descendant IN (
SELECT x.id FROM (
SELECT descendant AS id
FROM TreePaths
WHERE ancenster = 4
) AS x
);
メリットとしては、
- 設計がシンプルになります
- 先祖、祖先の列挙が迅速かつ容易
- 挿入や削除もでき、サブツリーの移動なども可能です
- 少し拡張して
path_lengthをつけると直近の親や孫などを簡単に検索できるようになります
一方で、デメリットとしては以下のようなものが挙げられます - 別個のテーブルが必要となります
- 階層が多くなると多くの行数が必要となりスペースが消費されます
閉包テーブルは最も用途が広いと言えます。

とりあえずID(ID Required)
とりあえず全てのテーブルにidを生やすのはアンチパターンです。
目的
すべてのテーブルに主キーを設定したいと考えています。しかし、どの列を主キーにするかは難しい問題です。メールアドレスでさえ、厳密には一意であるとは限りません。
アンチパターン: すべてのテーブルに「id」列を用いる
主キーを列名idですべてのテーブルに作るのはアンチパターンです。例えば、こういうの
CREATE TABLE Bugs (
id SERIAL PRIMARY KEY,
description VARCHAR(1000),
...
何がまずいか
- すでに主キーとして使えそうなキー(例えば
bug_id)がある場合は冗長なキーになります。 - id列を主キーとしてしまうとその他のキーで重複を許さないようにした場合は明示的にUNIQUEを指定する必要があります。
-
idという名前は極めて一般的なので、何のidなのかがわかりにくくなる可能性があります。 - 二つのテーブルをJOINしたSELECT文の時、PHPなどの言語では連想配列で結果が返されるので
b.id AS bug_idみたいにする必要があります -
idという名前が被ってしまうとUSING(例:SELECT * FROM Bugs INNER JOIN BugsProducts USING (bug_id))は利用できなくなります
アンチパターンを使用しても良い例
- ORMの規約によっては列名
idで、整数の擬似キーを必要となる場合があります。こういう時は設定より規約に従いましょう。 - 自然キーがあまりにも長い場合は良い選択肢になるかもしれません。
解決策
- bugテーブルなら
bug_idのように主キーに分かりやすい命名をするのがベターです。 - ORMの規約を上書きできるか調べてみましょう。Railsはできるらしいです。
- ユニークな自然キーがあればそれを主キーとすると良いです。仮に仕様変更で重複するようになった場合は擬似キーを導入すれば良いだけです。
4章 キーレスエントリ(外部キー嫌い)
外部キー制約を使わないのはアンチパターンです。
目的
できるだけシンプルなアーキテクチャで参照整合性を持たせたいです。
アンチパターン: 外部キー制約を使用しない
外部キーを省略するとデータベースがシンプルになり、柔軟性が高まり、実行速度が早くなると考えるエンジニアもいますが、
代償があることに注意を払う必要があります。
なぜダメなのか
- 完璧なコードを前提にしているので、外部キー制約を利用しない場合はアプリ側で完璧なコードを書いて整合性を維持する必要が出てきます。
- 破損を探すスクリプトの作成が必要になる可能性があります
(例えば、statusに無効な値が入っているレコードを探すには以下のようなクエリが必要です。外部キー制約を利用すればそもそも無効な値が入らないようにすることができます)
SELECT b.bug_id, b.status
FROM bugs b LEFT OUTER JOIN BugStatus s
ON b.status = s.status
WHERE s.status IS NULL;
アンチパターンを用いても良い場合
- MySQLのMyISAMや、SQLiteの3.6.19以下のバージョンではそもそも外部キーがサポートされていません
- 極端に柔軟なデータベース設計を扱わなければならない場合
解決策
外部キー制約を利用しましょう。
- 外部キー制約を使って参照整合性を維持することで「ポカヨケ」になります。(つまり、アプリケーション側での保証が不要になってポカが発生しない)
- カスケード更新を活用すれば、更新する親の行の更新、削除も一緒にできます
- 大したオーバーヘッドにはなりません
- 複数テーブルの変更を防ぐためにロックを取る必要はありません。
- チェックのためにSELECTをする必要もありません。
個人的補足
個人的には外部キー制約の利用は本当に参照整合性がないと大変なことになるという場合にのみ利用するべきと考えています。
例えば、コメントとかであれば、ユーザが削除された場合に投稿者の名前を「退会済みのユーザ」などと表示すれば良いだけです。
きちんと理解しておかないとDBの変更や削除などで手間がかかったり、カスケード更新で意図しない変更が起きたりすると思うので、
なんでもかんでも外部キー制約をつけるというのはやめた方が良いと思います。
また、カスケード更新まわりは以下がわかりやすくまとまっています。
5章 EAV(エンティティ・アトリビュート・バリュー)
柔軟性のためにあらゆるキーバリューを入れることのできるテーブルはアンチパターンです。
目的: 可変属性をサポートする
同じ基底型を拡張した複数のオブジェクトがある場合のテーブル設計を行いたいです。
例えば、Issueというクラスを継承するBugとFeatureRequestがあるとします。
Issueにあるカラムは共通ですが、BugとFeatureRequestで異なる独自の属性が存在しています。
アンチパターン: 汎用的な属性テーブルを使用する
以下のように、どんな属性でも入れることができるIssueAttributeテーブルを新たに作るのはアンチパターンです。
CREATE TABLE IssueAttribute (
issue_id BIGINT UNSIGNED NOT NULL,
attr_name VARCHAR(100) NOT NULL,
attr_value VARCHAR(100) NOT NULL,
PRIMARY KEY (issue_id, attr_name),
FOREIGN KEY (issue_id) REFERENCES Issues(issue_id)
このようなテーブルを作ってしまうのは以下のようなメリットが存在するからです。
- 両方のテーブルの列数を減らせる
- 新たな属性をサポートするのに列を増やす必要がない
- 属性が存在しないエンティティの該当列にNULLが入っている、NULLだらけのテーブルになることを防げる
なぜダメなのか
- ある属性を読みたい場合に、
WHERE attr_name = 'hoge'をつける必要があるため、少し冗長になります - 同じ属性でもアプリ側のコードで間違えて、異なる属性として登録してしまうことがあります(
date_reported,reported_dateなど、名前にばらつきがでてしまう可能性) - SQLのデータ型を使えないので、間違った値が入っても気付けないです(数値型を期待しているのに"banana"が入ってしまうなど)
- 属性に外部キー制約は使えません
- 各属性が異なる行に格納されるので、一つの行として出力するにはJOINが必要になります
アンチパターンを使用しても良い場合
特にありません。非リレーショナルなデータ管理が必要な場合は非リレーショナルな技術を使うのが良いです(MongoDB, Redisなど)。
解決策: サブタイプのモデリングを行う
以下の4つの解決策があります。サブタイプの数が限定的で、開発者がその属性もわかっている場合にこれらの解決策はうまく機能します。
シングルテーブル継承
一つのテーブルにタイプの識別用カラムとすべてのタイプの属性を入れてしまう方法が最もシンプルです。
CREATE TABLE ISSUES (
... 略
issue_type VARCHAR(10), -- 'BUG'または'FEATURE'が格納される
severity VARCHAR(20), -- 'BUG'のみで使う属性
sponser VARCHAR(50), -- 'FEATURE'のみで使う属性
)
対応する属性のないオブジェクトを格納する場合はそれらの属性をNULLにします。
以下のようなデメリットがあることに注意が必要です。
- 新しいオブジェクトタイプを追加する場合にはテーブルの変更が必要になる可能性があります
- どの属性がどのサブタイプに所属するかを定義するメタデータはありません
シングルテーブル継承が適切なのはサブタイプと固有の属性が限られていて、アクティブレコードのような単一のテーブルに対するデータベースアクセスパターンを使う必要がある場合です。
アクティブレコードについてはこちらで紹介されているとのこと。
具象テーブル継承
具象テーブル継承は各サブタイプごとにテーブルを作成する方法です。
シングルテーブルと比較した際のメリットとしては
- サブタイプに存在しない属性を入れる必要がない
- サブタイプを表す列(
issue_typeなど)が不要
といったメリットがありますが、 - 基底型のデータをいじりたい場合にすべてのサブタイプのテーブルを変更する必要がある
- 基底型とサブタイプのどちらなのかを示すメタデータはない
- すべてのオブジェクトをサブタイプに関わらず取得する際のクエリが複雑になる(UNIONを使えば少し簡単になる)
というデメリットもあります。
この解決策が適切なのはすべてのサブタイプを跨いだ検索を実行する頻度が低い場合です。
クラステーブル継承
基底型を独立したテーブルとして作成し、各サブタイプのテーブルにはその基底型への参照を保持するようにする方法です。
具体的には、共通する属性をもつIssuesテーブルと、issue_idを主キーとし、サブタイプの属性をもつBugsテーブルとFeatureRequestsテーブルの3つを作ります。
この方法はすべてのサブタイプにまたがる検索を効率よく行うことができます。
(個人的にはこれが柔軟性が高く、わかりやすさもあるので良さそうです。)
半構造化データ
基底型にサブタイプを表すカラムと、JSON(あるいはXML)の形式でサブタイプの固有のデータを格納するカラム(LOB列と言われる)を追加する方法です。
この設計は拡張性が極めて高いものの、行のソートや絞り込みのためにLOB列の中の個別の属性にアクセスするといったことは難しいです。
この設計は、サブタイプの数を制限できない場合や、新しい属性を随時定義するための高い柔軟性が必要な場合に適しています。
6章 ポリモーフィック関連
異なるテーブル間で共通のフィールドを使って汎用的に関連付けを行うのはポリモーフィック関連と呼ばれるアンチパターンです。
目的: 複数の親テーブルを参照する
BugsとFeatureRequestsという2つのテーブルがあります。それらにコメントをつける機能を付け加えたい時、どのようなテーブル設計にするのが良いでしょうか
アンチパターン:二重目的の外部キーを使用する
目的を果たすため、Commentsテーブルを一つ作り、issue_typeカラムに"Bugs"あるいは"FeatureRequests"を文字列で格納し、
issue_idに親テーブルのidを入れる...というのはポリモーフィック関連というアンチパターンです。
以下のようなデメリットがあります
-
issue_idに外部キー制約をつけることはできなくなる(テーブルを一つに指定できないので) -
issue_typeの値に対応するテーブルが存在するかわからない
アンチパターンを用いても良い場合
なるべく避けた方が良いが、Hibernateなど、ORMフレームワークによっては使わざるを得ない場合がある
解決策:関連(リレーションシップ)を単純化する
交差テーブルを作る
一つ目の解決策は、Commentsテーブルを作った上で、issue_idとcomment_idを交差するBugsCommentsテーブルおよびFeaturesCommentsテーブルを作ります。
このような設計ならissue_typeをCommentsテーブルに入れる必要はありません。
同じコメントを参照するレコードがBugsCommentsとFeaturesCommentsの両方に入ってしまうことを防ぐためにはアプリケーション側で防ぐ必要があります。
共通の親テーブル
二つ目の解決策はEAVのクラステーブル継承のような設計で、
BugsとFeatureRequestsテーブルの親として、Issuesテーブルを作り、CommentsテーブルはIssuesテーブルを参照するようにします。
こちらもCommentsにissue_typeは不要です。
7章 マルチカラムアトリビュート(複数列属性)
同じ意味の列を一つのテーブルに複数含めるのはマルチカラムアトリビュートというアンチパターンです。
目的
Bugに"crash"や"performance"といったタグをつけたくなってきました。
アンチパターン:複数の列を定義する
Bugsテーブルにtag1, tag2, tag3といった具体にtagを記録するカラムを定義するのはアンチパターンです。
以下のようなデメリットがあります
- 値の検索がしんどくなります。"crash"をタグにもつバグの検索には
WHERE tag1 = "crash" OR tag2 = "crash" OR tag3 = "crash"のようなクエリを書く必要があります。 - 値を追加する時、tag1~3のどれに入れれば良いのか判定が面倒くさくなります
- 同じレコードに同じタグが複数入ることを防ぐのは難しいです
- タグの数を増やしたくなった場合にテーブル変更が必要です。また、値の検索のクエリも修正が必要です
アンチパターンを用いても良い例
同じような列を複数入れるにしても、明確に役割や意味合いが異なる場合は不適切であるとは言い切れません。
例えば、アカウントID3つを同じテーブルの列に入れるとしても
バグ報告者のアカウントID, 修理を割り当てられたプログラマのアカウントID, 修正を確認する品質管理エンジニアのアカウントID
といったように各カラムに異なる意味を持たせられるなら大丈夫でしょう。
解決策:従属テーブルを作成する
従属テーブルを作成するのが最善の解決策となります。
CREATE TABLE Tags (
bug_id BIGINT UNSIGNED NOT NULL,
tag VARCHAR(20),
PRIMARY KEY (bug_id, tag),
FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id)
);
このテーブルではbug_idとtagを主キーとして設定しているため、同じバグに同じタグが複数つけられることを防ぐことができます。
検索は以下のようにシンプルなクエリになります
SELECT * FROM Bugs INNER JOIN Tags USING(bug_id)
WHERE tag = 'performances';
8章 メタデータトリブル(メタデータ大増殖)
目的
クエリの実行速度を劣化させずに、データが増加し続けるテーブルに対応できるよう、データベースの構造を設計したいです
アンチパターン:テーブルや列をコピーする
Bugsテーブルをdate_reported列を使って年毎に分割する方法が思い付きます
CREATE TABLE Bugs_2008 (...);
CREATE TABLE Bugs_2009 (...);
CREATE TABLE Bugs_2010 (...);
この方法は以下のような注意点があります
-
date_reportedを見て正しい挿入先テーブルを選択する必要がある- アプリケーションがわの実装にミスがあると正しくないテーブルにデータが混入することがある(CHECK制約を宣言することはできる)
- 修正は単純なUPDATEではなく、DELETEとINSERTが必要
- 年の終わりに、Bugs_2011テーブルの作成を忘れているとエラーが発生するようになる
- 分割されたすべてのテーブル間で主キーが一意であることを保証する必要がある
- テーブルを跨いだクエリ実行(過去の全ての未完了のバグの合計を算出するなど)はUNIONでたくさん繋ぐ必要がある
- 従属テーブルは外部キーを定義できない
アンチパターンを用いても良い場合
過去データを最新データから分離するようなアーカイブが目的の場合は問題ないです
解決策:パーティショニングと正規化
水平パーティショニング
水平パーティショニングはシャーディングとも呼ばれる機能で、行を分離するいくつかのルールを定めて論理テーブルを作ればあとはデータベースが必要な作業を行ってくれます。
CREATE TABLE Bugs (
bug_id SERIAL PRIMARY KEY,
... 略
date_reported DATE
) PARTITION BY HASH ( YEAR(date_reported) )
PARTITION 4;
この例ではテーブル数は4になっていて、データベースが4年を超える場合はどれか一つのパーティションに2年以上のデータが入ることになります。
垂直パーティショニング
水平パーティショニングが行で分割する一方で、垂直パーティショニングは列で分割を行います。
一部の列のサイズが大きい場合やほとんど利用されない場合に有効です。
例えば、サイズの大きなインストーラが格納されている場合には安易にそのテーブルに*を使ったSELECTをすると結果が大きくなってしまうため、
別のテーブルに切り出しておくのが良さそうです。
従属テーブルの導入
以下のように従属テーブルを宣言することも解決方法になります。
CREATE TABLE ProjectHistory (
project_id BIGINT,
year SMALLINT,
bug_fixed INT,
PRIMARY KEY (project_id, year)
FOREIGN KEY (project_id) REFERENCES Projects(project_id)
);
感想
テーブル設計時のトレードオフについてよくまとまっていて、参考にできる点が非常に多く、今後新たにスキーマを考える際に引き出しが多くなってそうです。
本書は外部キー制約に対して肯定的な意見が多いものの、強い整合性が本当に必要かは状況によって考える必要がありそうです。
より丁寧かつ詳しい解説を求める方はぜひこちらから購入してみてはいかがでしょうか。
Discussion