宝くじの番号をOCRで一括確認

これは、CANVAの生成AIに描いていただいたものです。
なかなかよいですね。
はじめに
前回の投稿では、OCRとOpenAIを比較して、認識精度の比較をしてみました。
その結果は、下記投稿記事でご確認いただければと思っております。
今回は、宝くじ券の番号をOCRで認識させるプログラムを紹介します。私事で恐縮なのですが、先日「宝くじ記念くじ」を150枚買ったのですが、券を1つ1つ確認すると歳のせいか手がカサカサになり、紙で指が切れて血が出てしまいました。
OCRを使って当選した券を瞬時に見分けられないか、ということで、宝くじ券番号を一括で大量に読み込んで、当選した宝くじ券を判定するプログラムを作成しました。「そんなこと、券売所の機械で店員さんに確認してもらえばいいのに。」と思う方もいるかと思いますが、そこはご愛敬ということで・・・
OCRライブラリ
Windowsでも利用できるtesseractを適用することにします。
これについてのダウンロード方法やインストール方法については、先述した前回の投稿記事を参照ください。
宝くじの画像
宝くじ券の番号の部分だけを画像として作成しました。

こんな感じです。大きな金額が当選している抽選券は一切ありません。
200円の当選が1つあります。(1.jpg)
また、あまりに外ればかりで面白くないので、11.jpgでは、少し加工をしました。下3桁を「124」にしたので、4等(1万円)当選とOCRが認識するかもしれません。
さすがに150枚の撮影はしんどいので、11枚のみをピックアップしてみました。
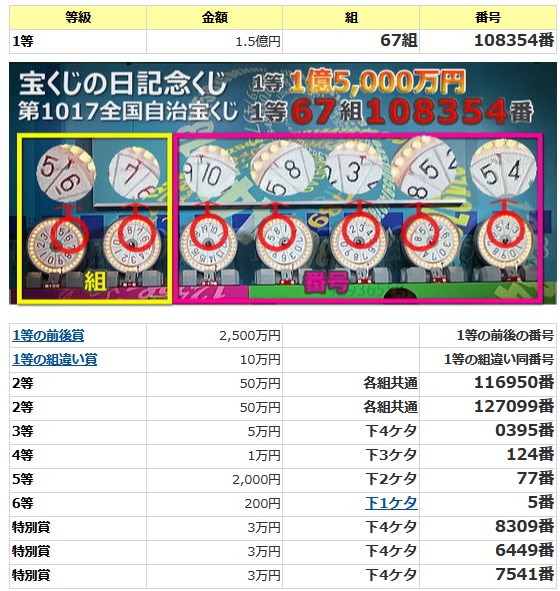
また、先日の抽選結果も併せて記載します。
プログラム
では、Pythonのプログラムを以下に示します。
import sys
import pytesseract
from PIL import Image
import pandas as pd
import re
import os
import glob
kekkas = [
{'number':'108354', 'name':'1等 or 1等組違い賞', 'money': 15000000},
{'number':'108353', 'name':'1等前後賞', 'money': 25000000},
{'number':'108355', 'name':'1等前後賞', 'money': 25000000},
{'number':'116950', 'name':'2等', 'money': 100000},
{'number':'127099', 'name':'2等', 'money': 100000},
{'number':'8309', 'name':'特別賞', 'money': 30000},
{'number':'6449', 'name':'特別賞', 'money': 30000},
{'number':'7541', 'name':'特別賞', 'money': 30000},
{'number':'0395', 'name':'3等', 'money': 50000},
{'number':'124', 'name':'4等', 'money': 10000},
{'number':'77', 'name':'5等', 'money': 2000},
{'number':'5', 'name':'6等', 'money': 200},
]
def image_to_text(image_path):
# 画像を読み込む
img = Image.open(image_path)
# TesseractでOCRを実行
custom_config = r'--oem 1 --psm 6'
text = pytesseract.image_to_string(img, config=custom_config, lang='jpn')
return text
if __name__ == "__main__":
image_path = 'C:/Users/ogiki/Desktop/data'
filepath_list = glob.glob(os.path.join(image_path, "**/*.*"), recursive=True)
amount = 0
for file in filepath_list:
base, ext = os.path.splitext(file)
if ext == '.jpg':
text = image_to_text(file)
rows = text.split('\n') # 念のため複数行の文章だと仮定
text = text.replace('\n','')
print(f"{file} {text}")
for kekka in kekkas:
regex_len= 6-len(kekka['number'])
if regex_len == 0:
regex = kekka['number']
else:
regex = fr"[0-9]{{{regex_len}}}{kekka['number']}"
if re.match(regex, str(rows[0])):
print(f"★当選★ --- 番号:{text} 等賞:{kekka['name']} 金額:{kekka['money']}")
amount = amount + kekka['money']
break
まずはkekkasというディクショナリを作成しました。(結果の複数形でkekkasはダメなネーミングですね)
その中には「番号」と「(等級)名前」それから「(当選)金額」としています。
次にimage_to_textという関数がありますが、画像ファイルのパスをインプットとして、認識した文字をアウトプットするようにしました。
それから「main」と続きますが、特定のフォルダ内のjpeg形式のファイルを繰り返し読み込みます。
当選番号の桁数は等級によって異なりますので、ちょっとややこしいのですが、以下のようなプログラムにしました。そうすることで、例えば「1等は、6桁すべてが合致した場合のみ当選と判断し」、「6等は、下1桁のみが合致した場合で当選と判断する」というようにできます。
for kekka in kekkas:
regex_len= 6-len(kekka['number'])
if regex_len == 0:
regex = kekka['number']
else:
regex = fr"[0-9]{{{regex_len}}}{kekka['number']}"
最後に合致した場合は、「★当選★・・・・・」を標準出力します。
print(f"★当選★ --- 番号:{text} 等賞:{kekka['name']} 金額:{kekka['money']}")
ここまでがプログラムの流れなのですが、OCRの精度を確認するため、OCRが認識した文字を標準出力に出力させることとしました。
print(f"{file} {text}")
プログラム実行
ではプログラムを実行してみます。
C:/Users/ogiki/Desktop/data\1.jpg 012345
★当選★ --- 番号:012345 等賞:6等 金額:200
C:/Users/ogiki/Desktop/data\10.jpg 12027テ7
C:/Users/ogiki/Desktop/data\11.jpg 120194
C:/Users/ogiki/Desktop/data\2.jpg .140570
C:/Users/ogiki/Desktop/data\3.jpg Su9\2う
C:/Users/ogiki/Desktop/data\4.jpg 1&0570)
C:/Users/ogiki/Desktop/data\5.jpg イプ5プラ7
C:/Users/ogiki/Desktop/data\6.jpg 104561
C:/Users/ogiki/Desktop/data\7.jpg 0979エ
C:/Users/ogiki/Desktop/data\8.jpg ュ78プ57
C:/Users/ogiki/Desktop/data\9.jpg 12027テ7
うーん、ほとんど上手に読み込めてませんねぇ。1.jpgと6.jpgだけが正しく認識されていました。11打数2安打、1割8分2厘・・・スタメン落ちですな。
おわりに
今回は、緩い感じで記事を書いてみました。ですので、結果も緩~い感じになっちゃいました。
私の前回の投稿記事でもお伝えさせていただきましたが、gpt-4oを使って画像認識をするとまた違った結果になるかもしれません。
今日はここまでとします。
追記(psmの変更)
あまりに精度が悪かったので、psmの値を1~13まで変更して再度実行しました。
そうすると「8」の時に以下の様になりました。
C:/Users/ogiki/Desktop/data\1.jpg 012345
★当選★ --- 番号:012345 等賞:6等 金額:200
C:/Users/ogiki/Desktop/data\10.jpg 120277
★当選★ --- 番号:120277 等賞:5等 金額:2000
C:/Users/ogiki/Desktop/data\11.jpg 』20194
C:/Users/ogiki/Desktop/data\2.jpg 140570
C:/Users/ogiki/Desktop/data\3.jpg nu9125
C:/Users/ogiki/Desktop/data\4.jpg 1&0570)
C:/Users/ogiki/Desktop/data\5.jpg ゴフ5プラ7
C:/Users/ogiki/Desktop/data\6.jpg 104561
C:/Users/ogiki/Desktop/data\7.jpg 0979エ
C:/Users/ogiki/Desktop/data\8.jpg 78757
C:/Users/ogiki/Desktop/data\9.jpg 120277
★当選★ --- 番号:120277 等賞:5等 金額:2000
5つ正解しました。という事で数字だけを読み取る場合はpsmが「8」に設定することをおすすめします。
Discussion