電子化対応を支援する!請求書自動整理ツールのご紹介

最近思うこと
2024年1月に電子帳簿保存法が改定され、領収書や請求書を紙ではなく電子データのまま保存できるようになりました。さらに、同年10月には郵便料金の値上げも予定されています。この変化により、多くの企業では経営層や他部署から「なぜ電子化に対応していないのか?」という声が上がり、情報システム部門が大規模なシステム導入を迫られることが予想されます。こうしたシステムには数百万円から数千万円の投資が必要で、導入の際には費用対効果が重要なポイントとなります。
ただ、電子化によって削減される作業時間を正確に定量化するのは難しく、その効果を見える形にすることは簡単ではありません。削減された業務時間を、よりクリエイティブで価値の高いタスクに活用することが理想ですが、日本全体として、就職後にスキルアップに取り組む意識が低い傾向があり、システム導入により余剰となった時間を効果的に使いこなせないケースが多いのが現実です。これでは、せっかく業務効率化を進めても、その効果が十分に活かされません。これは、「パーキンソンの法則」が示すように、与えられた時間に合わせて仕事が膨張してしまうことが原因です。
そのため、システム導入の成功には、人材のリスキリングやスキルアップも不可欠です。優れた人材がいなければ、どんなにシステムを導入しても真の効果は得られないでしょう。たとえば、「優秀な100名のプロジェクト」を成功させるために、10万匹の猿や30万人の幼稚園児を集めても意味がないように、単純作業だけをこなす社員がどれだけ多くいても、質の高い成果は期待できません。つまり、会社にとって重要なのは、人数ではなく、いかに優秀な人材を確保するかという点です。
背景・目的
さて、ここまでが私の最近思うことなのですが、こうした変化により、経理担当者の業務はむしろ増えているのではないかと感じています。特に、電子ファイルで送信される請求書は、請求元でも保存が必要で、毎月大量のPDFファイルを保管することになります。そのファイル整理に困っているという話をよく耳にします。そこで今回は、請求書の電子ファイルから自動的にファイル名を付けるプログラムをご紹介します。私独自の調査なのですが、OCRを使っても精度の高い処理ができない場合が多いことが分かりました。そこで今回は画像認識ができるgpt-4o-miniのAPIを試してみたいと思います。
さらに、プログラミングに慣れていない方や、コマンドライン操作が苦手な方でも簡単に使えるよう、Excelから実行できる仕組みも用意しました。これにより、より多くの人が効率よく作業を進められるようになることを期待しています。
プログラムの概要
Pythonを使用して、画像データをgpt-4o-miniのAPIに送信するプログラムを実装しました。PDFファイルには、システムで生成されたテキストベースのPDFと、画像データを含むPDFの2種類があります。前者はPDFパーサーで処理できますが、後者はOCRでしか対応できません。しかし前述のとおり、現在のオープンソースのOCRについては認識精度が十分でないため、すべての種類のPDFファイルを一旦画像ファイルに変換し(jpeg形式)、その後gpt-4o-miniのAPIで処理する方法に切り替えました。その結果、非常に精度の高い処理が実現しました。
さらに、この処理をExcelシート上のボタンから実行できるようにし、Pythonで生成されたログをCSVファイルとして保存し、Excel上でそのCSVファイルの内容を表示できる仕組みを構築しました。これにより、PythonとExcelの連携を強化し、作業効率を向上させることが可能になりました。
プログラム
本章では、PDFファイルの名称を変更するPythonのプログラムと、それを簡単なユーザインターフェースで呼び出すExcel VBAのプログラムを紹介します。
PDFファイル名変更(Python)
プログラムはbase64のライブラリを用いたものです。
以前投稿した記事のプログラムを流用しています。
import os
import sys
import glob
import csv
from datetime import datetime
from dotenv import load_dotenv
import base64
import pandas as pd
from pdf2image import convert_from_path
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.chat import HumanMessagePromptTemplate
FOLDER_PATH = sys.argv[1]
system = (
"あなたは有能なアシスタントです。ユーザーの問いに回答してください"
)
question = """
図の中の文字を抜き出して
"""
## =================================================================
def generate_question(text):
return f"""
以下の請求書の内容から、会社名、請求日、請求金額、摘要名を抽出してください。
{text}
結果は以下のフォーマットで返してください:
会社名: [会社名]
請求日: [請求日]
請求金額: [請求金額]
摘要名: [摘要名]
"""
# PDFをJPEGに変換する
def pdf_to_jpeg(pdf_path, jpeg_path):
images = convert_from_path(pdf_path)
images[0].save(jpeg_path, 'JPEG')
return images[0]
#画像ファイルをbase64エンコードする
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
## =================================================================
load_dotenv()
files = glob.glob(os.path.join(FOLDER_PATH, "**/*.*"), recursive=True)
log_file = open(f"{FOLDER_PATH}log.csv", mode="w", newline="", encoding="shift_jis")
for file in files:
base, ext = os.path.splitext(file)
if ext == '.pdf':
image = pdf_to_jpeg(file, base + ".jpg")
base64_image = encode_image(base + ".jpg")
image_template = {"image_url": {"url": f"data:image/png;base64,{base64_image}"}}
chat = ChatOpenAI(temperature=0, model_name="gpt-4o-mini")
#chat = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
#1: 画像から文字列を取得する。
human_prompt = "{question}"
human_message_template = HumanMessagePromptTemplate.from_template([human_prompt, image_template])
prompt = ChatPromptTemplate.from_messages([("system", system), human_message_template])
chain = prompt | chat
result = chain.invoke({"question": question})
#2: 取得した文字列から、請求書の情報を取得する。
human_prompt = "{question}"
human_message_template = HumanMessagePromptTemplate.from_template([human_prompt, image_template])
prompt = ChatPromptTemplate.from_messages([("system", system), human_message_template])
chain = prompt | chat
result = chain.invoke({"question": generate_question(result)})
# ---------- ファイル名を変更 ----------
# 抽出したテキストを行ごとに分割
rows = result.content.split('\n')
# 各行をさらにカンマ区切りで分割し、リストに変換
table_data = [row.split() for row in rows if row.strip()]
# Pandasのデータフレームに変換
df = pd.DataFrame(table_data)
# 会社名
company_name = df[1][0][:15]
# 請求日
date_obj = datetime.strptime(df[1][1].replace("年", "/").replace("月", "/").replace("日", ""), "%Y/%m/%d")
claim_date = date_obj.strftime("%Y%m%d")
# 請求金額
claim_money = df[1][2]
# 摘要名
abstract = df[1][3].replace(",", "_")[:20]
# 指定のフォーマットで日時を文字列として取得
now = datetime.now()
formatted_time = now.strftime("%Y%m%d%H%M%S")
os.rename(file, f"{FOLDER_PATH}{company_name}_{claim_date}_{abstract}_{formatted_time}.pdf")
os.remove(base + ".jpg")
# ログファイル出力(Excel用にShift-JISに変換)
writer = csv.writer(log_file)
pdf_file_name = f"{FOLDER_PATH}{company_name}_{claim_date}_{abstract}_{formatted_time}.pdf"
writer.writerow([pdf_file_name])
このプログラムで注意したところ、苦労したところについて説明します。
プロンプト
請求書の画像データから「会社名」「請求日」「請求金額」「摘要名」を抜き出して、それらをPDFのファイル名に付与することを考えました。
ただ、ChatGPTに対してどういうプロンプトにして良いかわかりませんでした。そういう場合は、本人に聞いてみよう~という事で、ChatGPTにどのようなプロンプトにして良いかを質問しちゃいました。その結果が以下のプロンプトになります。{text}は、請求書画像を基にChatGPTから返却された文章です。このプロンプトでは、その文章をインプットにして再度ChatGPTにその文章の中から「会社名」や「請求日」を拾い出してもらうという流れです。
f"""
以下の請求書の内容から、会社名、請求日、請求金額、摘要名を抽出してください。
{text}
結果は以下のフォーマットで返してください:
会社名: [会社名]
請求日: [請求日]
請求金額: [請求金額]
摘要名: [摘要名]
"""
画像変換
このプログラム自体は流用したものなのですが、PDFファイルを画像に変換して、それをgpt-4o-miniに認識させるという考え方は今までにはない方法なのではないかと思っています。
image = pdf_to_jpeg(file, base + ".jpg")
base64_image = encode_image(base + ".jpg")
image_template = {"image_url": {"url": f"data:image/png;base64,{base64_image}"}}
画像認識結果から取得した配列
配列をdfとして定義して画像認識結果の情報を取得しています。dfがリストになっていることは分かっていたのでforで回したかったのですが、なぜかエラーが出てしまったので、とりあえず「会社名」はdf[1][0]、請求日はdf[1][1]、請求金額はdf[1][2]として情報を取得することにしました。VSCodeにてデバッグモードにして、ブレークポイントを付けて、処理を中断させながら「ウォッチ式」を確認することで、配列の中に何が入っているかを知ることができました。
# 会社名
company_name = df[1][0][:15]
# 請求日
date_obj = datetime.strptime(df[1][1].replace("年", "/").replace("月", "/").replace("日", ""), "%Y/%m/%d")
claim_date = date_obj.strftime("%Y%m%d")
# 請求金額
claim_money = df[1][2]
# 摘要名
abstract = df[1][3].replace(",", "_")[:20]
また、ファイル名に日付(例えば20240915)を付与したかったのですが、「/」をファイル名に適用できないことや、コンマ(,)もファイル名に含めることができないなど、後からいろいろエラーが検出されたので、そのような対処のための処理も追記しました。ただ、未だいろいろ課題はあるだろうなぁと思っています。エラー処理としては粗削りです。
それから最後の最後に発覚したのですが、Pythonから出力したファイルをExcel VBAで読み込ませようとしたのですが、ExcelがUTF-8に対応していない為、文字化けしてExcelのセルに表示されてしまいました。Excel VBAにエンコード処理を入れようかと思ったのですが、めちゃめちゃ大変そうでした・・・しかしながら、ChatGPTに質問をすると、あっさり回答が返ってきました。そう、Python側でエンコードを`shift-jis'に設定しておけばよいという事でした。なるほど、そうですよね・・・でも気づきませんでした。ChatGPTさんありがとー。
log_file = open(f"{FOLDER_PATH}log.csv", mode="w", newline="", encoding="shift_jis")
インターフェース(Excel VAB)
まずはExcelシートに追加したプログラムです。
シート状にcmdExecというボタンを作成して、そこに処理を埋め込みました。
実際の処理プログラムはmdlExec.RunOCRScriptの中にあります。
Option Explicit
Private Sub cmdExec_Click()
Dim path As String
path = ExecSheet.txtFolderPath
If path <> "" Then
Call mdlExec.RunOCRScript(path)
End If
End Sub
次に、実行処理のあるプログラムを記載します。
Option Explicit
Const START_ROW_NO = 3
Const LAST_ROW_NO = 50
Const COL_NO = 2
Public Sub RunOCRScript(folderPath As String)
Dim shellObj As Object
Dim ret As Integer
Dim csvFilePath As String
Dim fileNumber As Integer
Dim lineData As String
Dim iRow As Long
Set shellObj = VBA.CreateObject("WScript.Shell")
ret = MsgBox("請求書PDFファイルの名称を変更します。", vbOKCancel)
If ret = 1 Then
csvFilePath = folderPath & "log.csv"
' クリア処理
Call Clear
' Pythonスクリプトを実行
shellObj.Run "python C:\Users\ogiki\ocr\gpt_script.py " & folderPath, 0, True
' CSVファイルを開く
csvFilePath = Replace(csvFilePath, "\\", "\")
fileNumber = FreeFile
Open csvFilePath For Input As fileNumber
' CSVファイルのデータをExcelに書き込む
iRow = START_ROW_NO
Do While Not EOF(fileNumber)
Line Input #fileNumber, lineData
ExecSheet.Cells(iRow, COL_NO).Value = lineData
iRow = iRow + 1
Loop
' ファイルを閉じる
Close fileNumber
Call MsgBox("処理が完了しました。", vbOKOnly)
End If
End Sub
Public Sub Clear()
Dim iRow As Long
For iRow = START_ROW_NO To LAST_ROW_NO
ExecSheet.Cells(iRow, COL_NO) = ""
Next iRow
End Sub
ついでに、Clear関数も末尾に追記しています。ボタンを押下する度にコールされ、一覧がクリアされます。
このプログラムで注意したところ、苦労したところについて説明します。
フォルダパスのバックスラッシュ
これには苦労しました。pythonでは「\\」で表記するのに対して、Excel VBAでは「\」なんですよね。頭の中がこんがらがってしまいました。最終的に以下のプログラムを追加して、なんとか収めることができました。本当だったらエクセルの中のテキストボックスは「\」の記入方式にすればよかったかなぁ。(今回は「\\」の記入方式)
' CSVファイルを開く
csvFilePath = Replace(csvFilePath, "\\", "\")
サンプルとして利用したpdf請求書
ネット上にあったサンプルを利用しました。そのうちの1つをお見せします。

合計4つのpdf請求書をサンプルに用いました。

実行結果
では実行してみます。
■ 実行前

■ 実行後
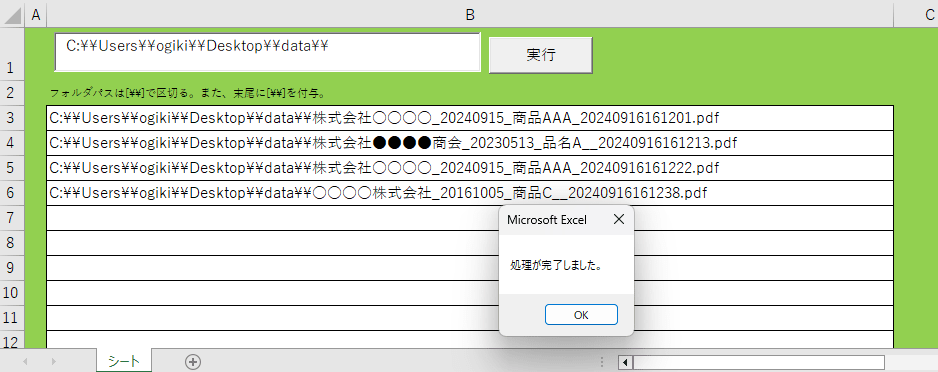
pdfファイル群のあるフォルダは、こんな感じになりました。

ちゃんとできているようですね。
これで、特定のフォルダにpdfファイルを沢山入れて実行すると、自動的にpdfファイル名を付与してくれるプログラムの完成です。
実行する方は、Excelファイルだけを起動して、ボタンをポチっとすると出来上がります。
おわりに
最近、電子帳簿保存法の改定やインボイス制度の施行により、経理担当者の業務負荷が増加しているという話を耳にしています。そうした方々が少しでも業務を楽にできるよう、サポートできればと考えています。しかし、負荷が軽減された分、単に時間を浪費するのではなく、その時間を活用して、よりクリエイティブで価値のある業務に取り組むためのスキルを身につけていくことが、今後の人生や生きがいにとって肝要です。
Discussion