LangChainとNeo4jでシステム連携図を自動生成する方法(2)






すみません、文章が今までのトーン違うのは、ChatGPTに「技術者が楽しくなるような文章にして」というオーダーを出したためです。ご了承ください・・・
はじめに
前回の記事では、テキストファイルの内容を「LangChain」で処理し、「Neo4j」のクエリに変換してグラフ描画を行うまでの流れを紹介しました。
今回はさらに一歩進めて、インプットを「テキストファイル」から「画像」に変えて、どこまで精度の高い解析ができるか試してみます!
GPTシリーズの画像認識性能には驚くべきものがあります。実際に検証した記事もあるので、ぜひ参考にしてみてください。
これらの投稿した記事のプログラムソースコードを流用して、試行してみます。
今回の挑戦は、これらの記事で使ったプログラムを少し改良して、画像からどの程度の精度で情報を抽出できるか検証することです。
プログラムの概要
プログラムの流れは基本的に前回と同じです。ただし、今回の入力が「画像ファイル」に変わるため、画像認識がキーになります。そのため、GPTモデルとしてはgpt-4o-miniやgpt-4oを使用します。
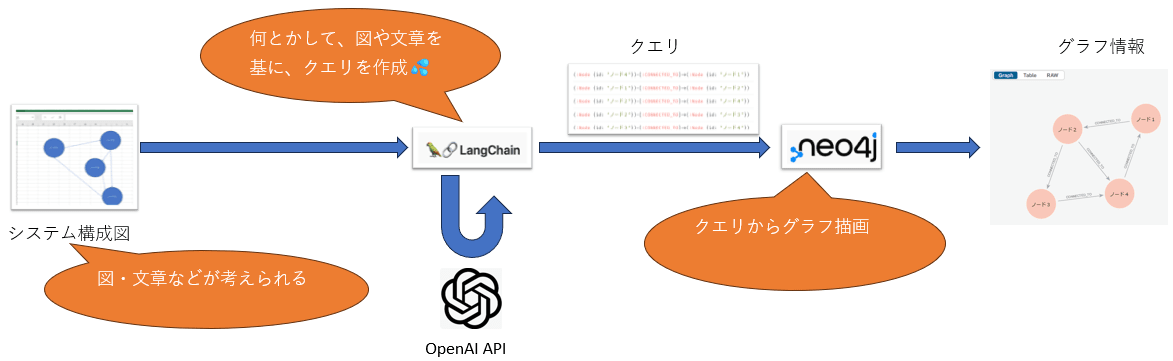
プログラムの詳細
次に、実際に使用したプログラムを示します。ポイントは、画像を読み込んでその内容をテキスト化し、さらにそのテキストを解析してNeo4jでグラフを描画するところです。
from langchain_community.graphs import Neo4jGraph
from langchain.chat_models import ChatOpenAI
from langchain_experimental.graph_transformers import LLMGraphTransformer
from node4j_1 import load_fig, load_pdf, split_text
llm = ChatOpenAI(
model= "gpt-3.5-turbo"
)
import os
os.environ["NEO4J_URI"] = "neo4j+s://********.databases.neo4j.io:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "************************************"
graph = Neo4jGraph()
graph.query("MATCH (n) DETACH DELETE n;")
docs = load_fig()
tgt_chunks = split_text(docs)
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(tgt_chunks)
graph.add_graph_documents(graph_documents)
前回の違いは、load_fig()という画像読み込み関数を使っている点です。画像をテキストに変換し、それを元にグラフを生成するフローを維持するために、この部分のみを大幅に変更しました。
import glob
import os
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
from langchain.chat_models import ChatOpenAI
import base64
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.chat import HumanMessagePromptTemplate
system = ("あなたは有能なアシスタントです。ユーザーの問いに回答してください")
question = """
図の中のシステム間の関連を全て列挙してください
"""
# ========== demodata/ *.jpg の読み込み ==========
def load_fig(path: str= "demodata/*.jpg") -> list:
fig_resources = []
for file in glob.glob(path):
print(file)
# ----- 画像ファイルを文章に変換 -----
base, ext = os.path.splitext(file)
with open(base + '.jpg', "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
human_prompt = "{question}"
image_template = {"image_url": {"url": f"data:image/png;base64,{base64_image}"}}
human_message_template = HumanMessagePromptTemplate.from_template([human_prompt, image_template])
prompt = ChatPromptTemplate.from_messages([("system", system), human_message_template])
chain = prompt | chat
result = chain.invoke({"question": question})
# ----- Documentクラスにラッピング(後続処理に影響を与えないため) -----
doc = Document(page_content=result.content, metadata={'source': file})
fig_resources.append(doc)
return fig_resources
# テキストのチャンク分割
def split_text(docs: list) -> list:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=700,
chunk_overlap=100,
)
chunked_resources = text_splitter.split_documents(docs)
return chunked_resources
プロンプト
gpt APIに投げるプロンプトを以下のようにしました。
もっといいプロンプトがあるかもしれません・・・
system = ("あなたは有能なアシスタントです。ユーザーの問いに回答してください")
question = """
図の中のシステム間の関連を全て列挙してください
"""
ソースコード中の「画像ファイルを文章に変換」のコメント以下は、以前の記事で説明していますので、お時間があればご連絡ださい。
# ----- 画像ファイルを文章に変換 -----
base, ext = os.path.splitext(file)
with open(base + '.jpg', "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
human_prompt = "{question}"
image_template = {"image_url": {"url": f"data:image/png;base64,{base64_image}"}}
human_message_template = HumanMessagePromptTemplate.from_template([human_prompt, image_template])
prompt = ChatPromptTemplate.from_messages([("system", system), human_message_template])
chain = prompt | chat
result = chain.invoke({"question": question})
ここからが一番大変でした。最初は、テキストのリストをそのまま返そうとしたのですが、後続処理でエラーが発生しました。具体的には、Neo4jにデータを渡す際に、期待していた形式と異なるため、うまく処理されなかったのです。
そこで、テキストデータを一旦DocumentクラスのPageContentプロパティに格納し、そのリストを返すように変更しました。このDocumentクラスは、LangChainの後続処理と互換性が高いため、この方法を採用することで、エラーを回避できました。
# ----- Documentクラスにラッピング(後続処理に影響を与えないため) -----
doc = Document(page_content=result.content, metadata={'source': file})
fig_resources.append(doc)
return fig_resources
この方法を使うことで、後続の処理がスムーズに動作するようになり、全体のフローがうまく回ることが確認できました。特に、LangChainが期待するデータ構造に合わせることが重要だと改めて感じました。
ここで注意することは、画像認識をさせ文章を作る時はgpt-4o(これは環境変数で設定しているためソースコードに現れません)、文章からNeo4jのクエリを作るのをgpt-3.5-turboにして、少しでもコストを減らそうとしました。
サンプル画像ファイル
今回は実際にネット上で見つけた画像を使って、システムの精度を検証してみることにしました。対象にしたのは「カシミール3D」のシステム構成図です。この画像を使って、どのように関係性を読み取ってグラフを生成できるか試してみます。
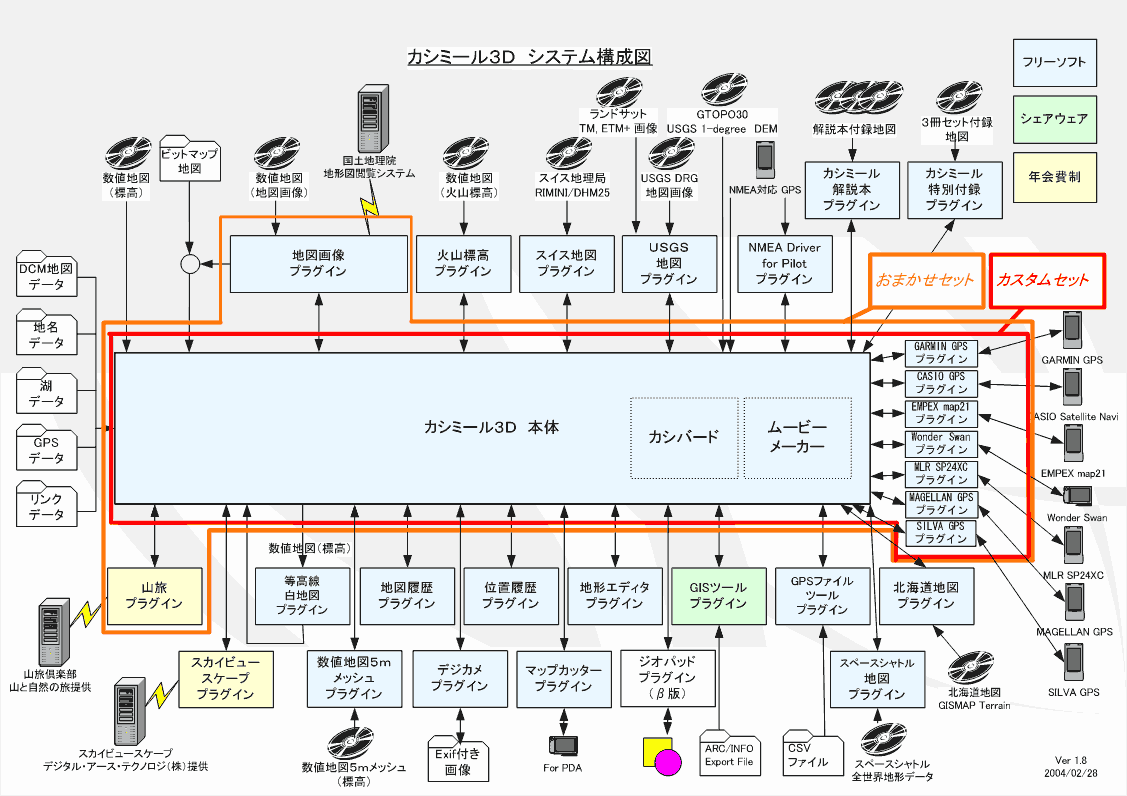
プログラム実行
さて、いよいよプログラムを実行します。gpt-4oは非常に高精度ですが、利用コストも高めです。とはいえ、エラーで途中停止するのは避けたいので、少し緊張しつつ実行ボタンを押しました。
次に、Neo4jのインスタンスを開いて結果を確認します。さて、どうなっているでしょうか…!
では、Neo4jのインスタンスを開いてみます。
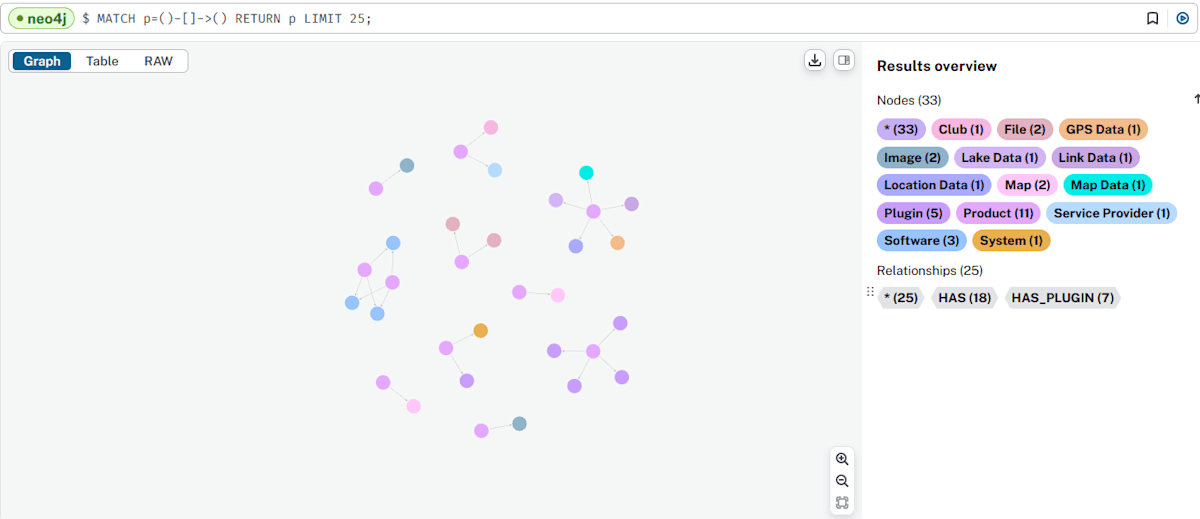
なんかできてそうです。
もう少し拡大をします。
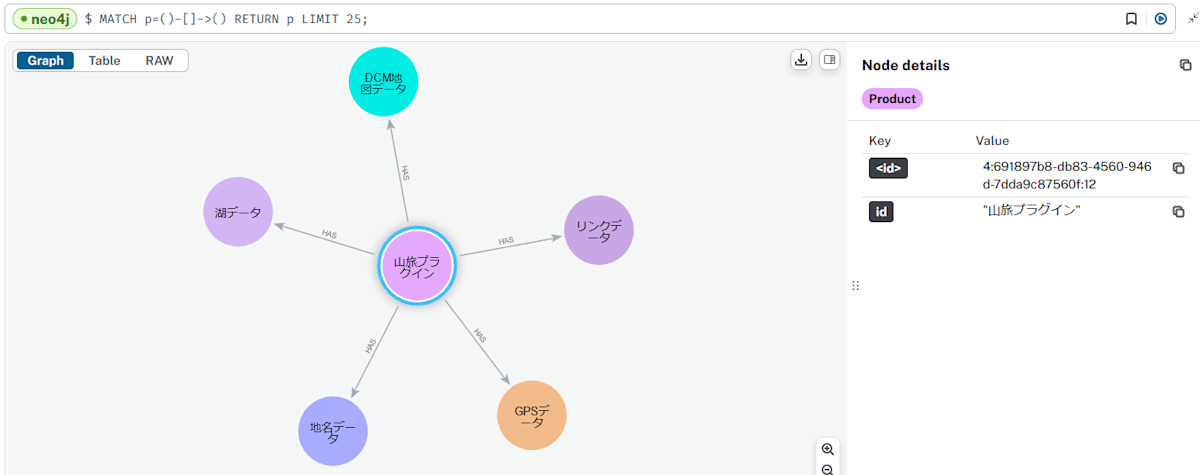
あちゃ、「山旅プラグイン」は「カシミール3D本体」と繋がっているのが正解ですが、グラフはちょっと間違っているようです。
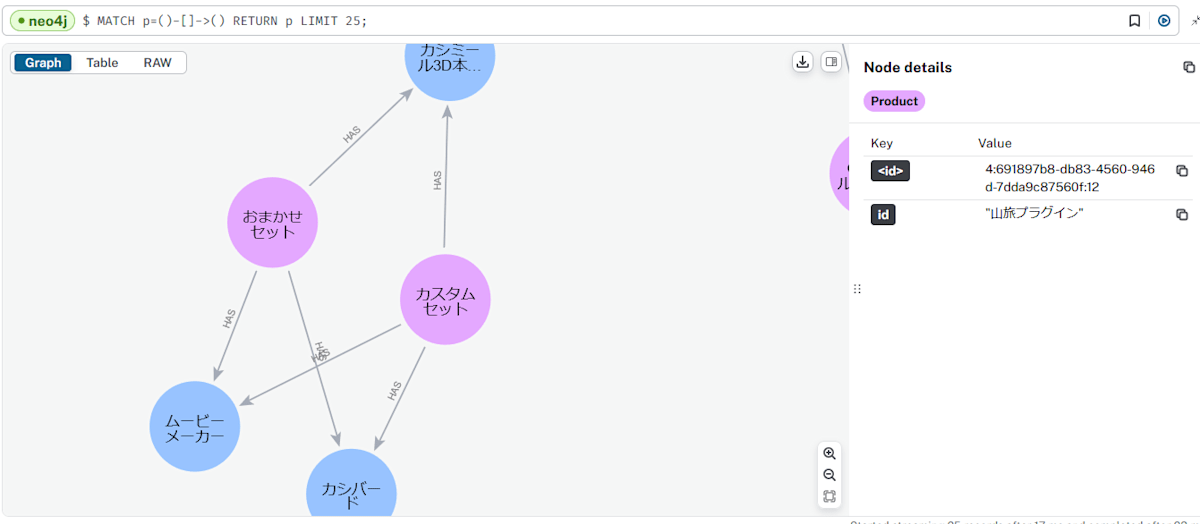
次は「おまかせセット」と「カスタムセット」です。言いたいことは分かるのですが・・・ちょっと違いますね。💦
パラメータやモデルを色々試すことで、精度を上げることができるかもしれません。
おわりに
今回の実験では、LangChainで画像を解析し、それをNeo4jにグラフとして描画する方法を試してみました。しかし、現時点の精度ではまだ商用利用には遠いかなという印象です。うーん、もう少し改善が必要ですね…。
次回は、さらに一歩進めて、Excelシート内のオブジェクト(円や線など)を抽出し、それをNeo4jにグラフとして描画することに挑戦してみます。具体的には、Pythonを使ってVBAコードを自動生成し、シート内のオブジェクトを抽出する方法を紹介します。そして、抽出したデータを基にクエリを作成するプロセスもカバーする予定です。
今から次の実験が楽しみです!こういったプロジェクトは、試行錯誤の中で大きな発見があり、とてもワクワクしますね。最後まで読んでいただき、ありがとうございました!
Discussion