Learn Next.jsをやってみている
これね。
App Routerをちゃんと触るのは初めてかな。
疑問点とかを挙げていく。
/app 直下に /ui がある
ファイルシステムルーティングのルートである /app 以下にほぼ全てのコードが配置されていて驚いた。
/app と並列に /components とかを定義していくものだと思っていたから、Vercel様の思想的には /app 内で全て完結させたいのかなという思いを感じ取った。
気になるところとしては、ルーティング責務の部分と見分けが付かなくなるとか全然ありそうだなと思った。ごちゃごちゃしそう。
Next の公式ドキュメントとして、この話題が載っていた。やっぱり認識はしているみたいね。
公式的には /app 以下にルーティング責務と各ページに関わるコンポーネント等の管理を全て任せているけど、別に /app と並列になるように /components を定義する今までのようなやり方でも問題はないよと。
一応これまでの pages router と違って、/app 以下に入れたものが全てルーティングになるということではないので、_hoge のような private folder というものも駆使することで、/app 内に共存していたとしても、幾らか見やすくなるようにはなっているらしい。
それでもルーティングと必ずしもドメインと対応するとは限らないから、そこは柔軟にこれまで通りの方法で /app 以下は「ルーティング責務」として専念させるのがひとまず良いのではという気がする。
/app直下に/uiとかを置くパターン(/ui内はpackage by featureスタイル)。
現状でもだいぶ見辛い気がするなあ()🤔

package by featureスタイルについて調査・考察したいい記事が最近上がっていた。
コンポーネント名をケバブケースにしているの珍しい気がするけど、エディタの検索性とかにはそんなに影響ないのかな?
clsxってそういえばこういう書き方できたのね。
いつもclsx('tailwind-styles', isHoge && : 'is-hoge-style')とか、三項演算子使ってclsx('tailwind-styles', isHoge ? 'is-hoge-style' : '')ってしてた。
今後変えてこ。

この書き方は、特に条件に応じてスタイルが変わるものが多い場合に便利。見やすくなる。
App RouterではデフォルトがRSCなんだっけ。
サーバーコンポーネントって何なんでしょうね。🤷♀️
uhyoさんのこれとかも見てみるかな。
あといろいろ。
Vercelの提供するPostgres。Vercel上からでも本当に必要最低限のデータ確認はできて、SQL実行もできる。
まだ東京リージョンがないのが気になるけど、DBの立ち上げから接続までの体験はさすがVercelだなと感じた(あと久々にVercelデプロイしたけど簡単すぎて(中で何が起きてるのか分からなくて)震えた🤷♀️)。

Client ComponentとServer Componentについて、今一度理解を深めておきたいな。
Next.jsというWebフロントエンドフレームワークの中で、サーバーサイド(Node.js)上で処理を実行できるということの利点を考えたい。
クライアントサイド(ブラウザ)上でJavaScript(React)を実行するのと、サーバーサイドでJavaScriptを実行することの本質的な違い。
言わば、なぜサーバーサイドでセキュアな情報を扱うのは安全で、クライアントサイドでセキュアな情報を扱うのは安全ではないのか、といったような話など(クライアントサイドからSQLを実行できるのがなぜ不安全で、サーバーサイドだと安全なのか)。
--
「クライアント側のスペックに依存せずに処理を実行できる」という点はまずありそう。
Webの各種ブラウザや、iOS上で動くSafari、Android上で動くGoogleなど、クライアントサイドにJavaScriptの処理が寄っていると、それを動かす様々なデバイスのスペックに処理速度が依存してしまう。
Since Server Components execute on the server, you can query the database directly without an additional API layer.
DeepL訳:サーバーコンポーネントはサーバー上で実行されるため、APIレイヤーを追加することなく、データベースに直接問い合わせることができます。
APIを独自に立てる必要なくサーバーサイド処理をNext.js内で行なうことができるのは便利である一方で、意識しないとどこがサーバーサイド処理なのかの判別が付かなくなりそう。/apiというパスもあるみたいだけれど、それはAPI Routesとしての話で、「デフォルトがサーバーサイドで実行されるコンポーネント」ということが意識しないと忘れがちになりそうだなと思った。
実際問題、Next.jsのApp Routerを初めて使ってみているけれど、「あ、これサーバーコンポーネントなのか」ってよくなる。慣れの問題かな。
このタイミングで少し前に話題になっていたこの記事を今更読んだ。
アンサー
要約記事
mainタグってページごとに1つ置くみたいな感じでいいのか。学び。

文書には hidden 属性が指定されていない <main> 要素を 2 つ以上置くことはできません。
使用上の注意
<main> 要素の内容は、文書で固有のものにしてください。この内容はサイドバー、ナビゲーションリンク、著作権表示、サイトロゴ、検索フォームのような、文書のセットや文書のセクションにまたがって繰り返されるものを除くべきです。(もちろん、主な内容が検索フォームでない限り)
文書=documentごとに1つっぽいから本当に画面に対して1つって感じだ。
Tailwind使っている場合で、動的に計算した高さとかを使用したいとき、style属性(prop)でスタイル指定するの認識一緒だった🐨
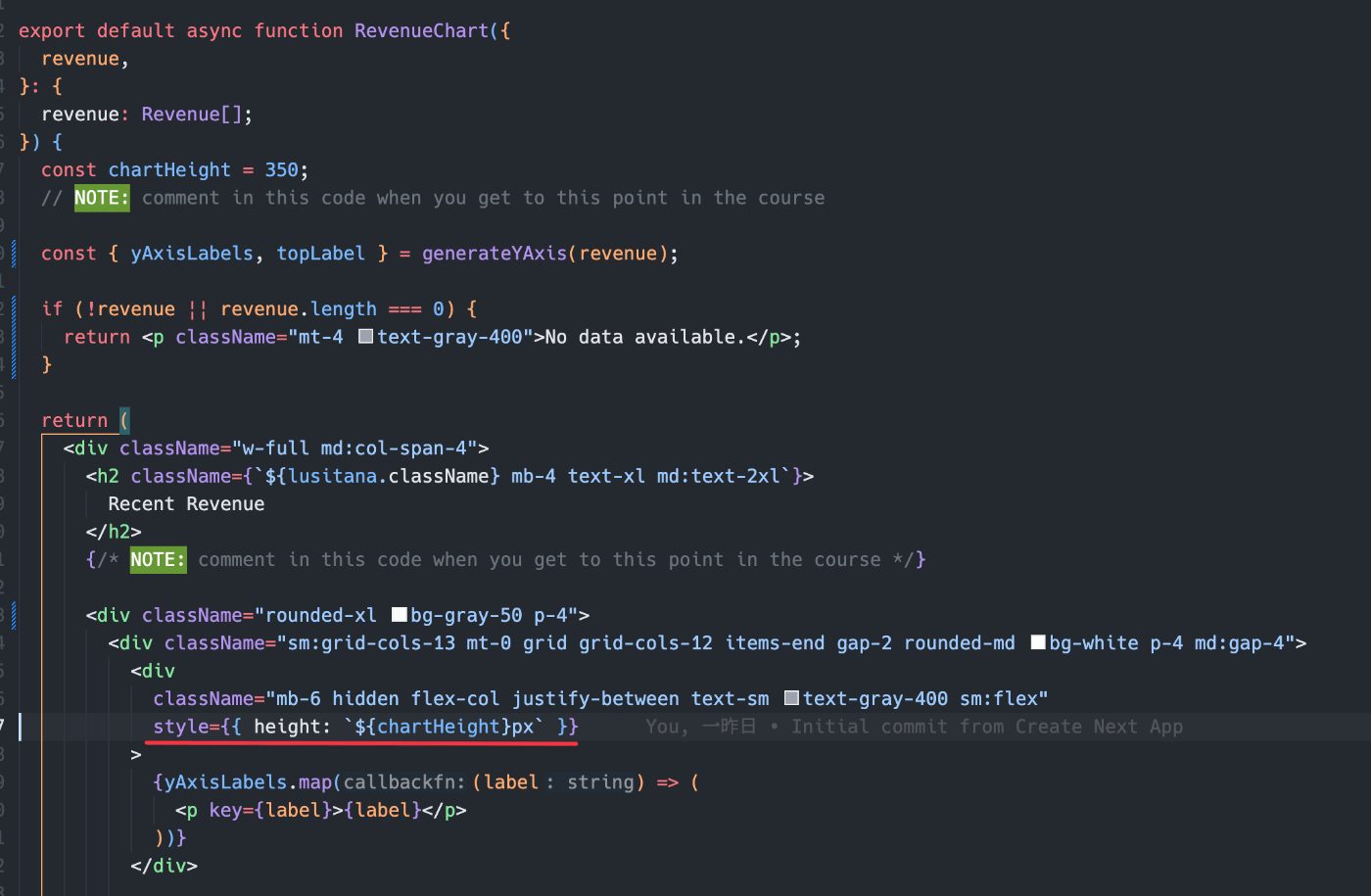
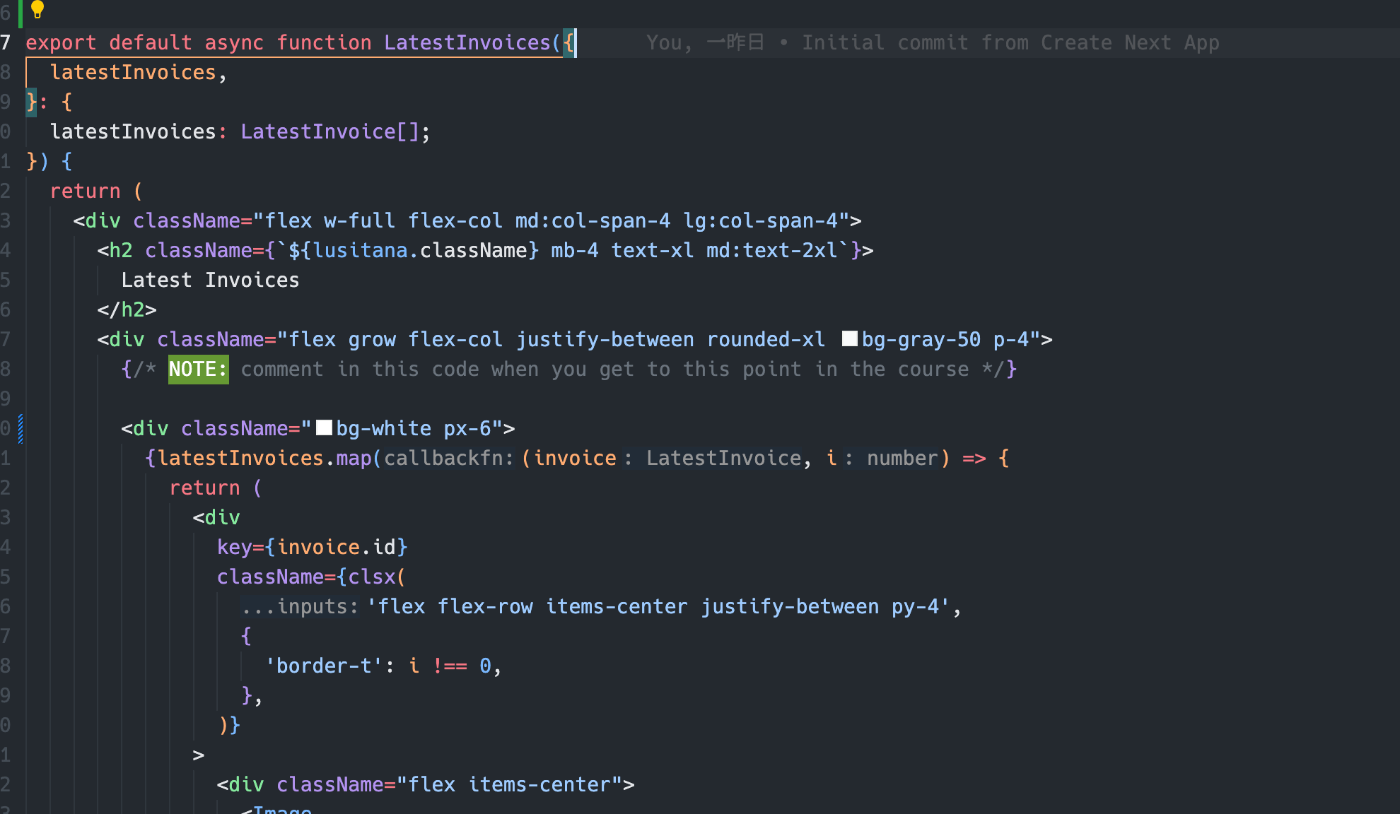
リストで並べるときに、2番目の要素からボーダー入れたいときこう書けるのか。面白い。
className={clsx('flex flex-row items-center justify-between py-4', {
'border-t': i !== 0,
})}
Tailwindのtruncate便利だな。

こういうテキスト...をよしなにやってくれる。

/dashboard画面の、この部分でrequest waterfallが発生している(7章)。
前のデータ取得を前提としたデータ取得が連続する場合はこれで良いが、そうでない場合はparallelにデータを取得する方がパフォーマンス的に良い(Promise.all()など)。

ただそれでも、Promise.all()を使ったとしても、この複数のpromiseの中で一番処理時間が遅いpromiseがボトルネックとなって処理時間が嵩みパフォーマンスに影響を与える可能性がある。
(今までのNextのSSR(getServerSideProps)なんかはこの傾向あったよね。全てのデータ取得処理が完結した後に、画面が表示されるみたいな。)
With dynamic rendering, your application is only as fast as your slowest data fetch.
[8章] 動的レンダリングでは、アプリケーションの速度は、最も遅いデータ・フェッチと同程度にしかならない。
そこで、各部分(コンポーネント)ごとにストリーミングでデータ取得を行なうみたいな話に繋がっていく。
話の流れが綺麗で好き。
静的レンダリングと動的レンダリング
一概に一対一で対応するものとは言えないかもしれないが、Next v12以前までの知識で例えると、「静的レンダリング」がSG(getStaticProps)に対応して、「動的レンダリング」がSSR(getServerSideProps)のに対応するみたいなイメージの用語なのかな。
With dynamic rendering, content is rendered on the server for each user at request time (when the user visits the page).
DeepL訳:動的レンダリングでは、コンテンツはリクエスト時(ユーザーがページを訪れた時)に各ユーザーごとにサーバー上でレンダリングされる。
動的レンダリングの特徴で気になったところ。
Request Time Information - Dynamic rendering allows you to access information that can only be known at request time, such as cookies or the URL search parameters.
DeepL訳:リクエスト時の情報 - 動的レンダリングでは、クッキーやURL検索パラメータなど、リクエスト時にしかわからない情報にアクセスできます。
これなんでCookieにアクセスできるんだっけ。サーバーサイドからのリクエストってだけで、普通にHTTPリクエストだからか?
ただブラウザからのリクエスト(クライアントサイドのリクエスト)とは異なって、明示的にCookieとかを指定して付けてあげないと、サーバーサイドから認証情報が必要なAPIは叩けなくなる。
静的レンダリングと動的レンダリングの概念って、クライアントサイドでのレンダリング(ブラウザ等でのReact(JavaScript)実行)と、サーバーサイドでのレンダリング(Node.js上でのReact(JavaScript)実行)という、「クライアントとサーバーどちらでレンダリング作業をするか」というのと関連する話だっけ?
With static rendering, data fetching and rendering happens on the server at build time (when you deploy) or during revalidation. The result can then be distributed and cached (stored) in a Content Delivery Network (CDN).
静的レンダリングでは、データのフェッチとレンダリングは、ビルド時(デプロイ時)または再検証時にサーバー上で行われる。その後、結果を配信し、CDN(コンテンツ・デリバリー・ネットワーク)にキャッシュ(保存)することができる。
With dynamic rendering, content is rendered on the server for each user at request time (when the user visits the page).
動的レンダリングでは、コンテンツはリクエスト時(ユーザーがページを訪れた時)に各ユーザーごとにサーバー上でレンダリングされる。
静的レンダリングは書いてあるとおり、サーバーサイドでのレンダリングっぽい。
動的レンダリングも書いてあるまま読めば、SSRなどのサーバーサイドでのレンダリング時の話をしていそうだけど、動的レンダリングに書いてある3つの特徴「Real-Time Data(リアルタイムデータ)」、「User-Specific Content(ユーザー固有のコンテンツ)」、「Request Time Information(リクエスト時の情報)」って、そのままクライアントサイド上での話にも当てはまると思った。
というかわかった、クライアントサイド"レンダリング"の話というよりかは、クライアントサイド"フェッチ"にも当てはまるという話な気がした。
「データフェッチ」がクライアントサイドかサーバーサイドで行われるのと、「レンダリング」がクライアントサイドかサーバーサイドかで行われるので、分けて考える必要があるか。
今回のここで言っている「動的レンダリング」とは、「サーバーサイド上でのフェッチ」と「サーバーサイド上でのレンダリング」の2つをまとめて指しているということかな。
ややこしい。🤔
sumirenさんのこの記事を思い出した。
Streaming is a data transfer technique that allows you to break down a route into smaller "chunks" and progressively stream them from the server to the client as they become ready.
ストリーミングとは、ルートを小さな "チャンク "に分割し、準備ができ次第、サーバーからクライアントに順次ストリーミングするデータ転送技術である。
By streaming, you can prevent slow data requests from blocking your whole page. This allows the user to see and interact with parts of the page without waiting for all the data to load before any UI can be shown to the user.
ストリーミングによって、遅いデータ・リクエストがページ全体をブロックするのを防ぐことができます。これにより、UIがユーザーに表示される前にすべてのデータがロードされるのを待つことなく、ユーザーはページの一部を見て操作することができます。
Streaming works well with React's component model, as each component can be considered a chunk.
各コンポーネントはチャンクとみなすことができるため、ストリーミングは React のコンポーネント モデルとうまく連携します。
ストリーミングの技術と組み合わせて、コンポーネント(サーバーコンポーネント)のレンダリング結果をストリーミングで送ろうと考えたの凄いスマート。😳
There are two ways you implement streaming in Next.js:
- At the page level, with the loading.tsx file.
- For specific components, with <Suspense>.
Next.jsでストリーミングを実装する方法は2つあります:
・ページレベルで、loading.tsxファイルを使用する。
・特定のコンポーネントに<Suspense>を使用する。
loading.tsxを用いたページ全体でのストリーミングは、従来の全て取得し終わったら表示に近いのかな?(従来のSSRみたいな)
と思ったら、App Routerからのnested routing機能によって、layout.tsx部分は事前にレンダリングが済んだ状態として、page.tsxのみストリーミングで取得されるというのを目の当たりにした。まずこの時点で凄い。
[GIF30秒。/dashboard表示から5秒後にデータ取得完了]
/app/dashboard以下の、layout, loading, page各ファイルの関係としては、下みたいな感じかな。
-
layout.tsx(一番外側でレイアウトの規定。childrenとしてloading.tsx > page.tsxを受け取る)-
loading.tsx(内部的にやっていることはSuspense。loading.tsxにはSuspenseのfallbackを書く)-
page.tsx(データフェッチ → 画面の表示)
-
-

[GIF20秒。/dashboard表示から5秒後にデータ取得完了]
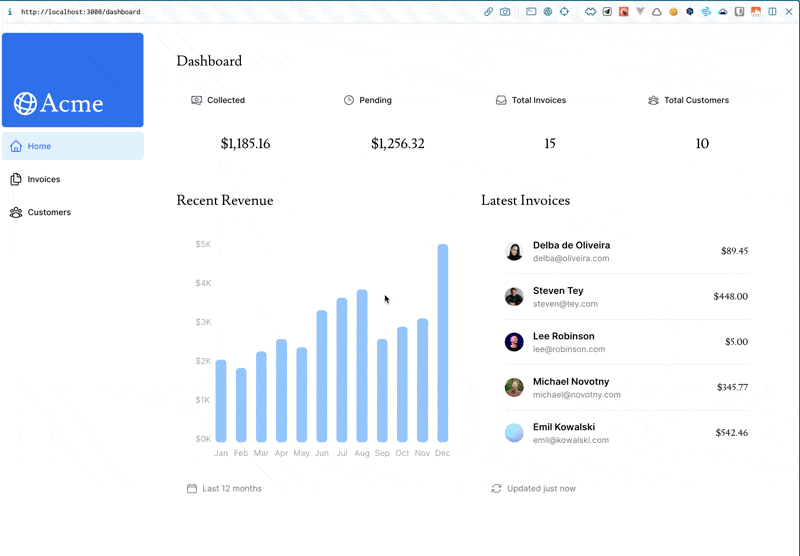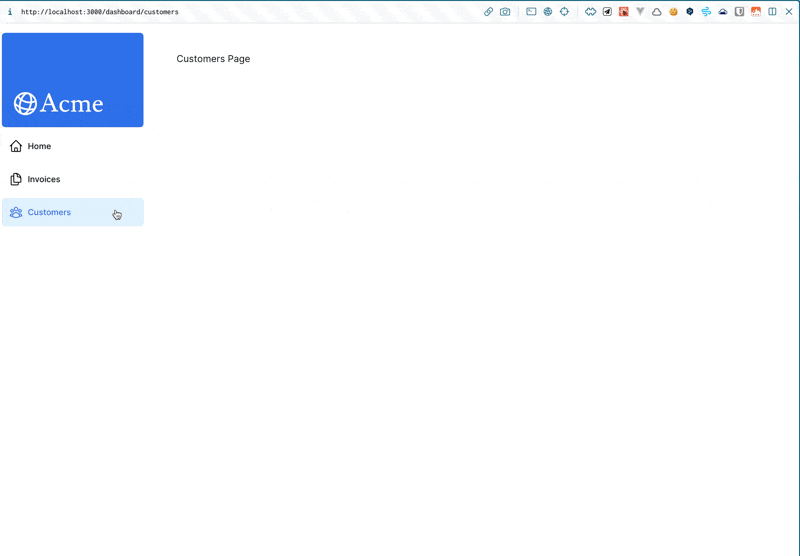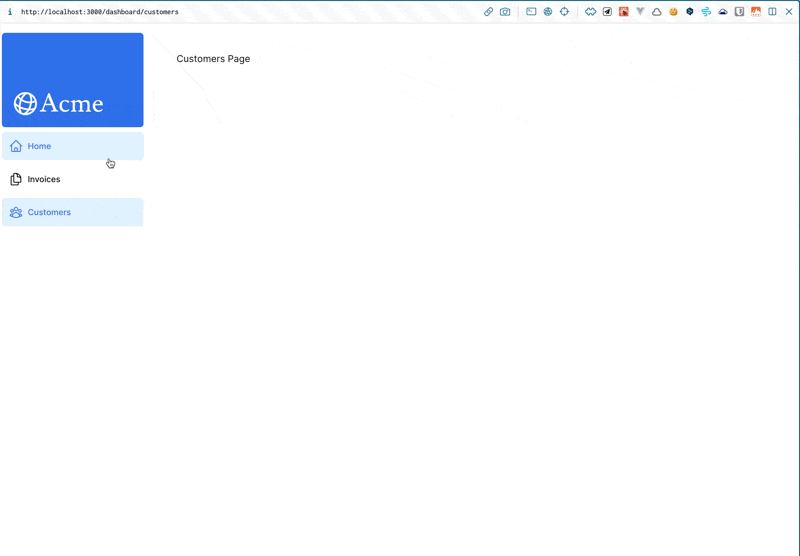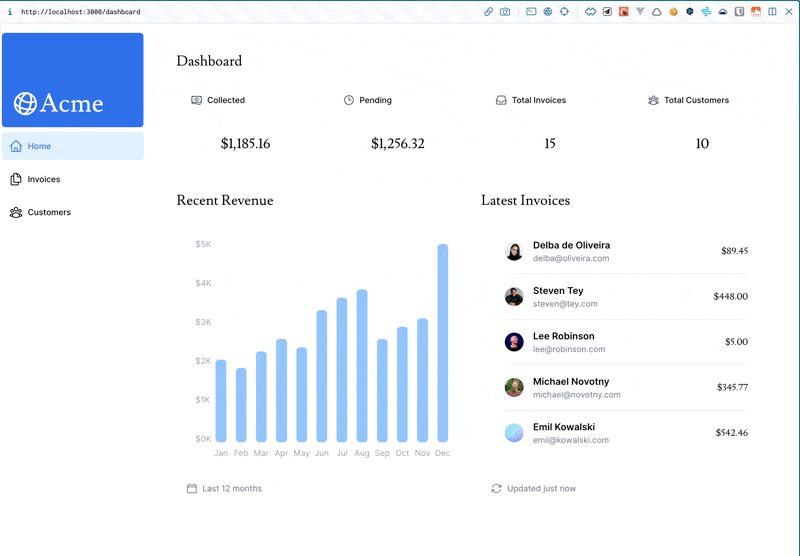
loading.tsxでpage.tsxのデータ取得を待っている間、既にサイドバーのコンポーネントはレンダリングが完了(サーバーサイド上で静的レンダリング)しているため、クリックが可能。
そして、/dashboardを開いた瞬間にデータフェッチ処理はストリーミングで続くため、他の/dashboard/customersとかに切り替えている最中でもデータ取得処理は続き、データ取得が完了したら/dashboardで表示する用のデータが既に取得できている(恐らくキャッシュされている)ため、/dashboard/customersから/dashboardに戻ったときには既にダッシュボード画面が表示可能状態になっていると。
これめっちゃ凄いな。
改めて、上記の動画の流れをまとめた。
-
/dashboardを開く- サーバーサイド上でデータ取得開始(5秒かかる処理)
- ただ、この時点ではデータ取得中なので
loading.tsxにfallbackされる
-
/dashboardでデータ取得中に/dashboard/customersに切り替える- この時点でも、
/dashboardのデータ取得処理は非同期処理として進んでいる- あ!
page.tsxをasyncの関数コンポーネントにしていたのはこのためか!非同期で処理できるようにコンポーネントごと非同期で処理される関数としたのか。
- あ!
- この時点でも、
- 5秒経過後、データ取得完了とともに、サーバーからストリーミングでサーバーサイドレンダリングされたコンポーネント情報のJSONがクライアントに送られる(多分)
- このデータがたぶんキャッシュサーバーとかに保持されているはず
- 再び
/dashboardを開いた際にはデータ取得が再度行われるが、既にキャッシュサーバーにキャッシュがあるため、それを用いてデータ表示(クライアント側のReactがDOMを更新)
かなあ?
ただ、データ取得時に取得したデータのキャッシュを無効にするnoStore()メソッド(参照)の影響か、ちょこちょこ、サイドバーを切り替えるたびにloading.tsxが5秒間表示されちゃうことがあった。noStore()メソッドを全て外したら、思った通り、どんな場合でも上の状況(/dashboardからすぐに別画面に切り替えてもデータ取得が続き、データ取得が完了したらそれ以降はloading.tsxが表示されずに画面表示が行われる)が再現できた。
…あれ?noStoreしない状態でも普通に起きたな。わからなくなった…。
クライアントコンポーネント(CC)もサーバーコンポーネント(SC)も、全ての前処理はNode.js上で行われる?RSCは、サーバー側(Node.js上・ビルド時?)でReact Treeを構成し、そこで処理完了(ハイドレーションの必要がないためクライアント(ブラウザ)へJSを送る必要がなくなる)。恐らくはJSONだけ送る?
クライアントコンポーネントは、ユーザーとのインタラクティブな操作が必要になるコンポーネントであって、その目印はuse client(元々はuse interactiveみたいな案もあったそうな)。
use clientと言いつつも、その実態は、サーバーサイド上でReact Treeを構成し(=レンダリング作業。ブラウザ上で行なうことも可能だと思うが、Nextではデフォルトサーバー上での実行なのかな?)、その後、use clientのコンポーネントはハイドレーション操作を行なうため、イベントハンドラなどの登録を行なうJSバンドルをブラウザへ返し、ハイドレーション作業を行なう必要がある。
サーバーコンポーネントはこのハイドレーション作業の必要がないコンポーネントを、サーバーサイドのみでレンダリング完結させ、ブラウザに余計なJSバンドルを送らない技術ということなのか?
いよいよ名前がややこしい😇 適切な命名を考えたいものだ。
ハイドレーション周りは以下の記事とかで1回試してみるのが良さそうかな。
CCとSCは、「Reactコンポーネントのレンダリング作業」をどこ(クライアント・サーバー)で行なうかという差でしかない?
SCはサーバーでその作業を行なうことによって、副次的にサーバー上での他の恩恵も受けるみたいな?
スケルトンローディングのきらきらってこうやって作れるのかー!
今後使おう👀

サーバーコンポーネントが主流になることによって、データフェッチをサーバーコンポーネント内(=サーバー上)で行なうことが主流になる可能性が高い。
このとき、今までクライアントフェッチとしてブラウザ上でAPIリクエストを送っていたもの(useSWRなど)が、全てサーバー上でNextが提供するラッパーfetchAPIなどを用いて実行することが主流になり、クライアントフェッチ用のライブラリであった useSWR や Tanstack Query などは今後使われなくなっていく気がした。
これまで、ReactのSuspenseAPIを使用するコードで、以下のようなコードが多く、親側がSuspenseを使用するとき、「使われる子側が内部的にuseSWRなどをsuspense: trueで使用していること」を知っていることを前提としていて、「なぜ親側(使う側)が子(使われる側)がどのようにデータフェッチ処理をしているかに依存しているのだろう?」と思っていた。
// 親(使う側)
const ParentComponent = () => {
return (
<Suspense fallback={<div>Loading...</div>}>
<ChildComponent />
</Suspense>
)
}
// 子(使われる側)
const ChildComponent = () => {
const { data } = useSWR(..., { suspense: true })
return /* data を用いてなにか */
}
サーバーコンポーネントの登場によって、「サーバー上でのデータの取得及びコンポーネントのレンダリング」をSuspenseで待つというメンタルモデルになったことによって、幾分か受け入れやすくなった気はする。
というか、ここにも書いてあった通り、Suspenseとは「何らかの条件が満たされるまで何かを待つ」というのが本質的な部分なのだろう。
Suspense allows you to defer rendering parts of your application until some condition is met (e.g. data is loaded).
サスペンスでは、何らかの条件が満たされるまで(例えばデータが読み込まれるまで)、アプリケーションの一部のレンダリングを延期することができます。
以下の<RevenueChart />はサーバーコンポーネント。

親側(使う側)の責務として、「子(使われる側)をどのように配置するか」また「子の準備ができていない場合はどうするか」を決めるのは自然な責務であるかと思うので、SuspenseAPIを親側が使用して、まだ準備中の子コンポーネントの部分にどのような表示をさせるかを指定するというのはメンタルモデルとしても直感的に思う。
これからはこういう感覚かな。
// 親(レイアウト等の配置の規定や、準備できていないコンポーネントへの対応などを担う)
const ParentComponent = () => {
return (
<>
<ChildComponentA />
{/* ChildComponentBは、データ取得に時間がかかりそうなのでSuspenseで囲っておく */}
<Suspense fallback={<div>Loading...</div>}>
{/* 正味この ChildComponentB が RCC か RSC かは問わない */}
<ChildComponentB />
</Suspense>
<div className="flex">
<ChildComponentC />
<ChildComponentD />
</div>
</>
);
};
// 子(データフェッチして情報を表示する。親のことには関心がない。自分のUI表示責務を果たす)
// ※サーバーコンポーネント想定
const ChildComponentB = () => {
const data = fetch() // Nextの拡張fetch
return /* data を用いてなにか */
}
Suspenseの境界をどこに引くか
大体似たようなことを考えていた。
Where you place your suspense boundaries will vary depending on your application. In general, it's good practice to move your data fetches down to the components that need it, and then wrap those components in Suspense. But there is nothing wrong with streaming the sections or the whole page if that's what your application needs.
サスペンスの境界をどこに置くかは、アプリケーションによって異なります。一般的には、データの取得を必要なコンポーネントに移し、そのコンポーネントをサスペンスでラップするのが良い方法です。しかし、アプリケーションに必要であれば、セクションやページ全体をストリーミングしても問題はありません。
7, 8, 9章での学びがとんでもなかったな。🐶
今後ここを参照しに来ることは多そう。
部分プリレンダリング、面白いけど、そこまでする必要があるのか?という気がしないでもない。
Twitterで言ったら、タイムラインに表示されているツイート本体は 一度表示された後は静的(static) だけど、そのツイートへの「いいね」は 増えたり減ったりして動的(dynamic) だよね、ってことよね。

引用
It's worth noting that wrapping a component in Suspense doesn't make the component itself dynamic (remember you used unstable_noStore to achieve this behavior), but rather Suspense is used as a boundary between the static and dynamic parts of your route.
Susppenseでコンポーネントをラップしても、コンポーネント自体が動的になるわけではなく(この動作を実現するためにunstable_noStoreを使用したことを覚えておいてください)、むしろSusppenseはルートの静的な部分と動的な部分の境界として使用されることに注意してください。
「Susppenseはルートの静的な部分と動的な部分の境界として使用される」、これ重要な認識かもしれない。
RSCの利点がちらっとまとめてあった。
Fetched data on the server with React Server Components. This allows you to keep expensive data fetches and logic on the server, reduces the client-side JavaScript bundle, and prevents your database secrets from being exposed to the client.
React Server Componentsでサーバー上のデータをフェッチします。これにより、高価なデータフェッチとロジックをサーバー上に保持し、クライアント側のJavaScriptバンドルを削減し、データベースの秘密がクライアントに公開されるのを防ぐことができます。
[編集予定]
App Routerに対する所感。
フロントエンドから入る人が最近多くなっている中で、サーバーが果たす役割を理解できていない状態でNextを扱うのは中々難しいのではないかと思った。
サーバーサイドについて学ぶ重要性が上がっている気がする。
検索機能や検索画面を組む際に、URL search param(クエリパラメータ)を用いる利点が書いてある
There are a couple of benefits of implementing search with URL params:
- Bookmarkable and Shareable URLs: Since the search parameters are in the URL, users can bookmark the current state of the application, including their search queries and filters, for future reference or sharing.
- Server-Side Rendering and Initial Load: URL parameters can be directly consumed on the server to render the initial state, making it easier to handle server rendering.
- Analytics and Tracking: Having search queries and filters directly in the URL makes it easier to track user behavior without requiring additional client-side logic.
URLパラメータを使って検索を実装することには、いくつかの利点がある:
- ブックマーク可能なURLと共有可能なURLです:検索パラメータはURL内にあるので、ユーザーは検索クエリとフィルタを含むアプリケーションの現在の状態をブックマークして、将来の参照や共有に利用できる。
- サーバーサイドレンダリングと初期ロード:初期状態をレンダリングするために、URLパラメータをサーバー上で直接消費することができるため、サーバーレンダリングの処理が容易になります。
- アナリティクスとトラッキング: 検索クエリとフィルタを直接URL内に持つことで、クライアントサイドのロジックを追加することなく、ユーザーの行動をトラッキングしやすくなります。
検索実装において、クエリパラメータを使う利点。
1つ目はよく分かるのに対して、2つ目と3つ目はあまりピンとこないな。
2つ目はサーバーコンポーネントと相性が良いってことを言っているのかな。
最近意識しだしたけれど、クエリパラメータはNext.js内ではRouterContext内にあるので、実質useRouter等を介してグローバルステートのように扱えるのがめちゃくちゃ便利なんだよなあ。
useRouterラップして特定のクエリパラメータをいじるカスタムフックにすれば、色々なクエリパラメータをセットしたり外したりといったことが簡単にできるようになる。可能性無限大マン。
[11章] "use client" - This is a Client Component, which means you can use event listeners and hooks.
"use client" - これはクライアントコンポーネントであり、イベントリスナーとフックを使用できることを意味します。
use clientディレクティブのメンタルモデルとしては、フックの使用やイベントリスナの登録などを通して、ユーザーとインタラクティブな操作を媒介することにあるっぽいね。
Tailwindにpeerなんてものあったのか。
兄弟要素にフォーカスが当たったときとかを検知してスタイル当てられるらしい。面白い。
画像のコードは、inputにフォーカスしたらアイコンの色が赤色に変わる例。

参考
この検索コンポーネントにおいて、検索内容の入力状態は「クエリパラメータ」として表され、その入力状態の更新はrouter.push()やrouter.replace()によって実現される。
Nextの内部実装的には、useRouterフック内でRouterContextをuseContext(RouterContext)で呼び出している。
言いたいこととしては、Next.js内において、URL(及びクエリパラメータ) はNext.jsアプリケーション内で管理される 状態(ステート) であり、状態更新関数(pushやreplace) を用いてURLというステートを更新することによって、再レンダリングをトリガーできる というのが重要な理解。

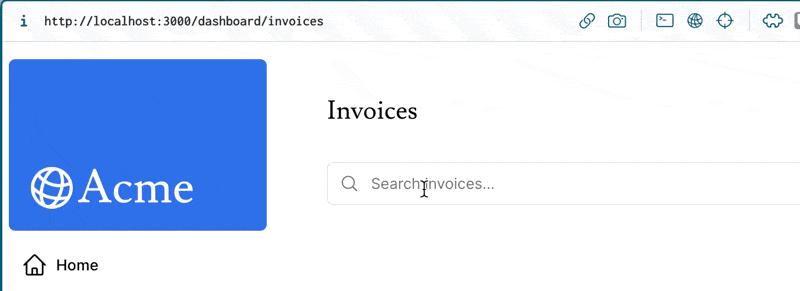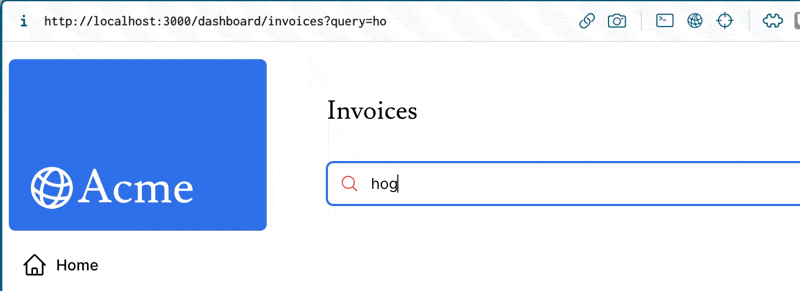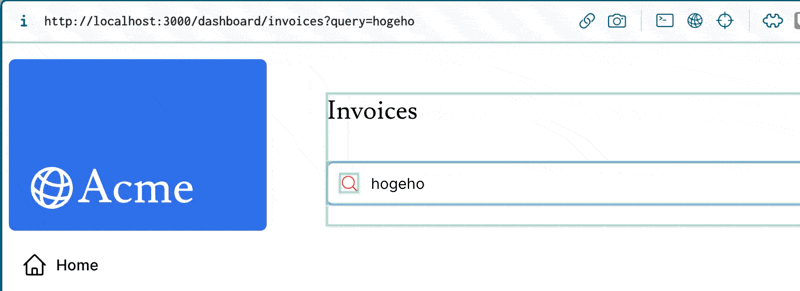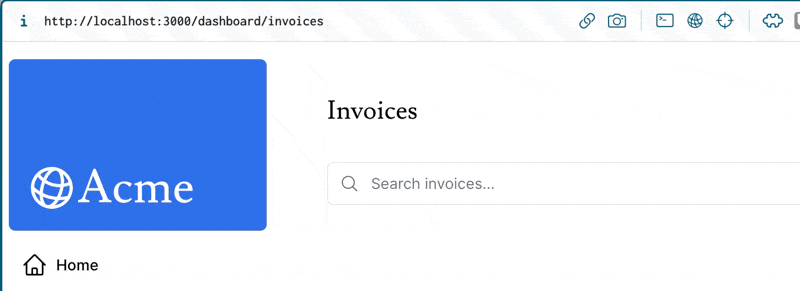
Next.jsのuseSearchParamsっていうフック、ジェネリック型指定して、クエリパラメータを型安全に取り扱えるようにできないかな?🤔

そういえば最近Zodでクエリパラメータ安全に扱うみたいな記事見たな。
あった。
[11章] defaultValue vs. value / Controlled vs. Uncontrolled
If you're using state to manage the value of an input, you'd use the value attribute to make it a controlled component. This means React would manage the input's state.
However, since you're not using state, you can use defaultValue. This means the native input will manage its own state. This is okay since you're saving the search query to the URL instead of state.defaultValue vs. value / コントロールされる(制御) vs. コントロールされない(非制御)
入力の値を管理するために状態(state)を使用する場合、value属性を使用して制御されたコンポーネントにします。これは、Reactが入力の状態を管理することを意味します。
しかし、状態(state)を使用していないので、defaultValueを使用できます。これは、ネイティブのinput要素が自身の状態を管理することを意味します。検索クエリを状態ではなく URL に保存しているため、これは問題ありません。
なるほどなあ。defaultValueとvalueの使い分けってあまり意識したことはなかったけれど、こういう違いだったのか。確かに今回はinput要素に対応させるローカルステートを定義していないから、React制御下に置かない非制御なコンポーネントとして扱えているわけね。
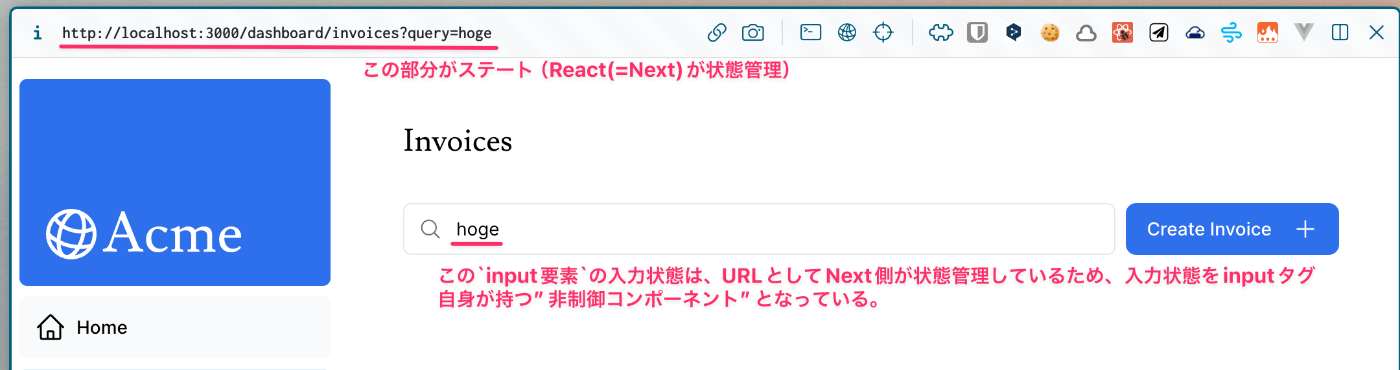
今回の場合は、この方がinput要素自身で入力状態を管理できるから、パフォーマンス的にも都合がいいだろうね。
Pageコンポーネント用の独自のpropsができたの、これは普通に良いな!
これまで、Pageコンポーネント内でuseRouterフックを呼んで、そこからundefinedかもしれないクエリパラメータを検証して〜みたいなことをやっていたのが、これで軽減できそう(?)。
何もない場合は空オブジェクトになるみたいだから、結局クエリパラメータ取り出すときにはundefinedである可能性はあるのか。

あとクエリパラメータを型安全に扱えないのは少し気になるな。
まあ、Pageコンポーネント側で、クエリパラメータとしてはこの値を取りうるというのを先に型定義しておけたらより良いかな。それこそpathpidaなんかはそれができるから、いずれNextの今は実験的機能であるtypes routeに組み込まれる可能性はありそう。
クエリパラメータまで型安全に扱えるようになったらめっちゃいいなあ。
実験的機能のtyped routesの機能の影響だろうけど、一応PageProps型が動的に生成されてるんだな。
このPageProps型を使うときに、ジェネリック型で受け取れるクエリパラメータを指定できるように今後なっていく気がするなあ。

検索ボックスに検索テキストを入力したときに、何が起こるか。
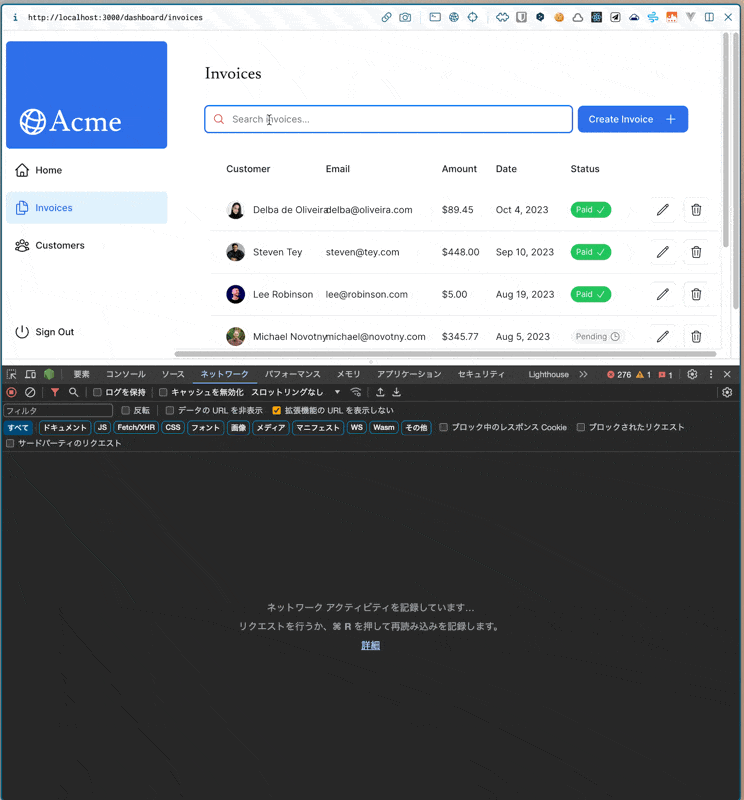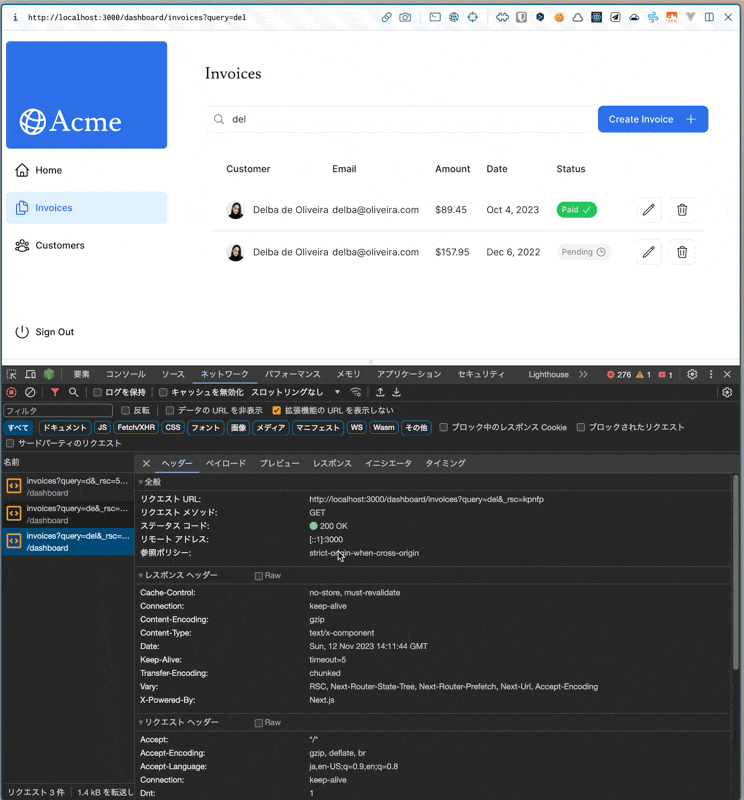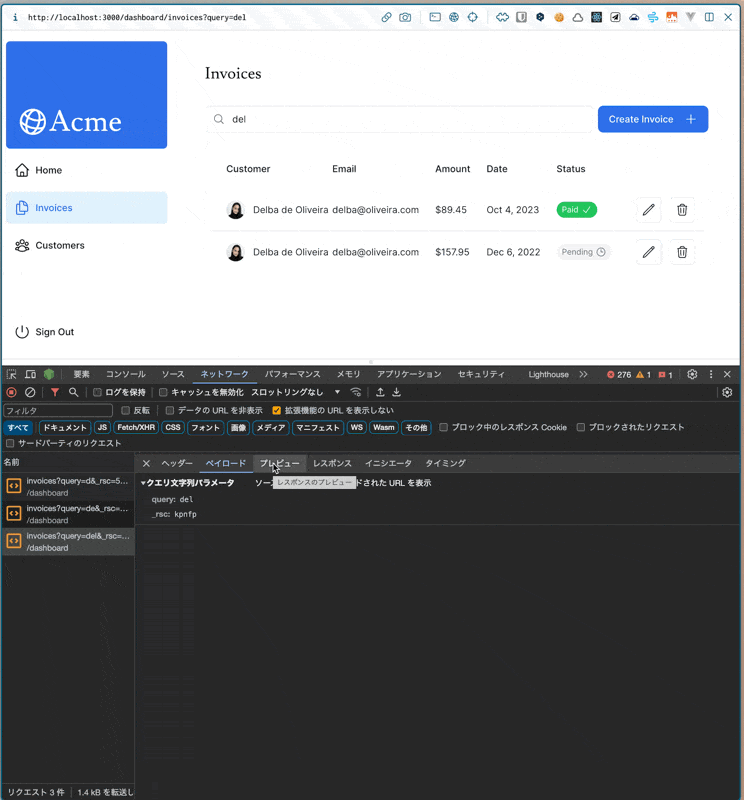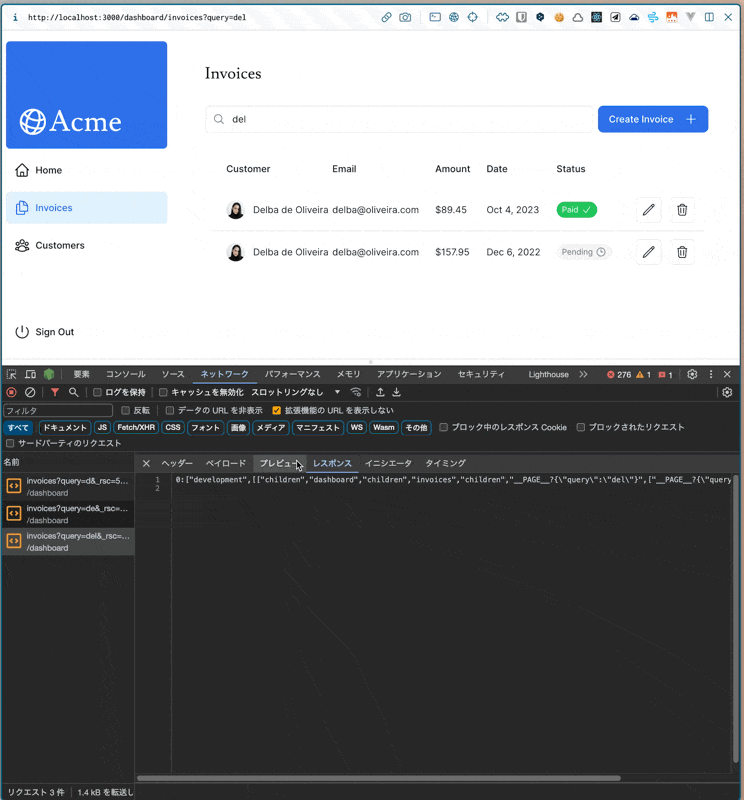
- 検索ボックスに値を入力する(replaceメソッドが動いてURLを更新する)
- URL(実質ステート)が変わるのを受けて、再レンダリングがトリガーされる
- 請求書ページのPageコンポーネント(SC)から順に再レンダリングがかかる
- [SC: Page]
Page({ params, searchParams }) {}から、searchParams.queryを取得して、そのキーワードを下の<InvoicesTable />に渡す(※サーバー/Node.js上での実行) - [SC: InvoicesTable] 請求書テーブルコンポーネント内で、propsの
queryを元に、fetchFilteredInvoices()関数が実行される。中で@vercel/postgresのsql関数が実行される(内部的にはfetchの実行かな。ネットワークタブで見えているのは多分これ→いや違うか?サーバー側で実行されるsql関数がブラウザ側のネットワークで見えるのはおかしい)。(※サーバー/Node.js上での実行) - 5.の請求書データ取得中は、外側のSuspenseでフォールバックコンポーネントが表示されている(なんでサーバー側で関数実行するとレンダリングがサスペンドするんだっけ?また調べたい)
- データの取得が完了し次第、そのデータを用いて
<InvoicesTable />が表示される
[11章] When to use the useSearchParams() hook vs. the searchParams prop?
You might have noticed you used two different ways to extract search params. Whether you use one or the other depends on whether you're working on the client or the server.
<Search> is a Client Component, so you used the useSearchParams() hook to access the params from the client.
<Table> is a Server Component that fetches its own data, so you can pass the searchParams prop from the page to the component.
As a general rule, if you want to read the params from the client, use the useSearchParams() hook as this avoids having to go back to the server.useSearchParams()フックとsearchParamsプロップの使い分けは?
検索パラメータを抽出するために2つの異なる方法を使用していることに気づいたかもしれません。どちらを使うかは、クライアントで作業しているかサーバで作業しているかによります。
<Search>はクライアントコンポーネントなので、クライアントからパラメータにアクセスするためにuseSearchParams()フックを使いました。
<Table>はそれ自身のデータを取得するServer Componentなので、ページからコンポーネントにsearchParams propを渡すことができます。
一般的なルールとして、クライアントからパラメータを読み込みたい場合、useSearchParams()フックを使用します。
なるほど。
一応Pageコンポーネントでもuse clientすればsearchParams取れるみたい。


ただそれをするメリットは殆どないかな。サーバーコンポーネント時代では、基本的にはサーバーコンポーネントにしてバンドルサイズ等を減らしていく戦略を取るのが普通だろうから、一番ルートのPageをクライアントコンポーネントにするなんて、するメリットが殆どないはず。
基本的には、上から順にサーバーコンポーネントで降ろして行って、末端部分でクライアントコンポーネントにするのが理想形なんだろうね。こう考えると、サーバーコンポーネント時代のReactって、Astroとかがやってるアイランドアーキテクチャの形に近い感じに見えるな。インタラクティブな部分のみが島のように浮いているイメージ。
デバウンス処理の解説もあるの、いいね。
テキスト入力に伴う検索処理系は、デバウンス処理かけるの負荷軽減としてもほぼ必須に思えるから、こういうプラクティス紹介してくれるのありがたい。
Pagination関係のコンポーネント、全体的に凄く良くできていて参考になる。
clsxっていつもclassNameの部分に直接書いていたけど、たしかに一度変数に格納するみたいな使い方もできるのか。JSX部分が簡潔になっていいね。
というかこれ、上手く使えば、CSS Modulesやstyled-component的な、スタイル部分の分離ができるのでは?const articleTitle = clsx(/* ... */)みたいな。

ポストしておいた。
[12章] Good to know: In HTML, you'd pass a URL to the action attribute. This URL would be the destination where your form data should be submitted (usually an API endpoint).
However, in React, the action attribute is considered a special prop - meaning React builds on top of it to allow actions to be invoked. Rather than calling an API explicitly, you can pass a function to action.
Behind the scenes, Server Actions create a POST API endpoint. This is why you don't need to create API endpoints manually when using Server Actions.知っておいて損はない:HTMLでは、action属性にURLを渡します。このURLはフォームデータの送信先(通常はAPIエンドポイント)になります。
しかしReactでは、action属性は特別なpropとみなされます。つまり、Reactはアクションを呼び出すことができるように、action属性の上に構築します。APIを明示的に呼び出すのではなく、actionに関数を渡すことができます。
舞台裏では、Server ActionsはPOST APIエンドポイントを作成します。これが、Server Actionsを使用する際にAPIエンドポイントを手動で作成する必要がない理由です。
form要素のaction属性に関数を渡せるのってReact特有のことだったのか。HTMLの標準かと思っていた。
あとServer Actionsって内部的にはやっぱりAPIエンドポイントを勝手に作ってくれてるのね。因みに、use serverディレクティブのことをServer Actionsって言うの?
たぶんだけど、use serverディレクティブで定義された関数のことをService Actionと呼ぶのだろう。

The amount field is specifically set to coerce (change) from a string to a number while also validating its type.
金額フィールドは、文字列から数値に強制(変更)されるように特別に設定されており、同時にその型も検証される。
Zodってcoerceなんていう便利変換メソッドあったのか。
Server Action雑まとめをする。
動作原理(たぶん)
-
use serverディレクティブを用いて関数を定義する(まずこれがServer Actionと呼ばれるもの) - Next.jsが上記の関数を呼び出すようなPOST APIを自動で生やす(APIエンドポイントの指定等諸々不要)
- formのaction属性にそのServer Actionを渡す(この時点でNextが自動生成したPOST APIを叩くfetchに変換されているのかな?)。
type=submitなボタンで実行する - Next.jsのNode.jsサーバー上で、自動生成されたPOST APIの先で、元々定義していたServer Action関数が実行される
こんな感じ?
Server Actionの利点についてまとめてある良き記事。
React / Next.js周りのキャッシュ周りについて理解を深めたいな。
仕事仕事で、だいぶ空いてしまった。🙃
こういうことがあるから、こういう系は一気にやり終えてしまいたいのだけどなあ。
[12章] UUIDs vs. Auto-incrementing Keys
We use UUIDs instead of incrementing keys (e.g., 1, 2, 3, etc.). This makes the URL longer; however, UUIDs eliminate the risk of ID collision, are globally unique, and reduce the risk of enumeration attacks - making them ideal for large databases.
However, if you prefer cleaner URLs, you might prefer to use auto-incrementing keys.UUIDとオートインクリメントキーの比較
私たちは、キーのインクリメント(1、2、3など)の代わりにUUIDを使用しています。そのためURLは長くなりますが、UUIDはIDの衝突のリスクを排除し、グローバルに一意であり、列挙攻撃のリスクを軽減します。
しかし、よりすっきりとしたURLを好むのであれば、自動インクリメントのキーを使う方がよいでしょう。
UUIDとオートインクリメントのどちらがいいのか、最近考えようと思っていた話題だ。
オートインクリメントだと、何の工夫もしないとユーザー数が何人いるとか、投稿数がいくつとかすぐ分かっちゃうよね。