【和訳まとめ】Anatomy of an Incident - Google - Site Reliability Engineering
本記事は、Anatomy of an Incident - Google - Site Reliability Engineeringを和訳したものです。逐語訳ではなく、訳者による解釈と要約が含まれます。
修正提案はコメントをいただけますと幸いです🙏
第1章 はじめに
"インシデント"という用語を定義し、全員が同じ言葉で話す必要がある。
Googleでは"インシデント"は以下のように定義される。計画的な停止はインシデントではない。
- 1人では手に負えないためエスカレーションされる
- 即時対応が必要
- 組織的な対応が必要
インシデント、障害、メトリクス、アラートは別のものである。
モニタリング
モニタリングは計測の一種であり、システムの健全性を監視する最も一般的な方法である。
SLO, 顧客体験(Customer Experienceのいずれも、顧客中心主義的な(Customer Centric)アプローチをとることが推奨される。つまり、様々な側面から、顧客体験を示すメトリクスを収集することが必要である。
また、インシデントは申告数ベースで測定するのではなく、信頼性やユーザーへの影響の測定に着目すべきである。
"信頼性"と"可用性"
"信頼性"と"可用性"は同じように使われることがあるが、複雑な分散システムにおいてはとくに"信頼性"とは単なる"サービスの可用性"だけではなく、"規模が大きくても一貫したレベルのサービスを提供できる能力"を指す。
サービスによってユーザーの期待値が異なるため、"信頼性"の意味も異なってくる。ユーザーがどの程度ダウンタイムを許容できるかが肝要なので、ユーザー体験をなるべく詳しく測定する必要がある。
アラート
モニタリングにより何らかの期待通りではない動きが見つかった場合に示されるものがアラートである。
アラートには以下の2種類の意味がある。
- 何かが壊れていて、誰かが直す必要がある
- 何かが壊れるかもしれないので、誰かが確認する必要がある
通知方法は以下のように分けられるべきである。
- 人間によるアクションがすぐに必要な場合: Page(オンコール通知)で通知
- 人間によるアクションが数時間以内に必要な場合: アラートで通知
- アクションが必要ない場合: メトリクスまたはログとして残す
アラートの通知方法は組織の好み次第だが、Googleではチケット管理される。
アクション可能なアラート
アラートは、注意すべき問題や、アクション可能なことに対してのみ発令されるべきである。
アラートは、インシデントが進行中であることを通知するために使う指標に過ぎない。アラートがあってもインシデントではない場合もあるし、インシデントなのにアラートがない場合もある。
また、対応においても、管理(レポートライン)においても、アラートとインシデントの扱いは異なる。インシデントは対応により多くのリソースを使い、通常 上層部を対象に報告されるのに対し、アラートは基本的に担当者が確認する。したがって、受け取る対象者を考慮してアラート/インシデントそれぞれのスコープを設定する必要がある。
インシデント管理のライフサイクル
"優れたインシデント管理"とは、インシデントのライフサイクル(リスクに対処するプロセス)全体に注意を払うことを意味する。これには以下の段階がある。
- 準備(Preparedness): 対策や訓練、監視・アラート設定など
- 対処(Response): アラート対応、インシデントであるかどうかの判断、インシデントに関するコミュニケーションなど
- 緩和と復旧(Mitigation and Recovery): 緩和策(暫定対処)、根本対処、ポストモーテムなど
これらの段階は同時に発生することもあるが、いつでも必ずどれかの段階にあり、ライフサイクルは循環する。
第3章~第4章では、各段階についてより詳しく説明する。
第2章 インシデントレスポンスの実践 準備(Preparedness)
障害時のロールプレイングとインシデントレスポンス演習
定期的にインシデント対応テストを行うことには以下のようなメリットがある。
- テストにより問題を発見・修正することでシステムの耐障害性が高まる
- テストの失敗が軽減し、復旧も早まる
- 対応者が冷静に対応できるようになる
ニュアンステスト
(Googleにおいて)テストは、技術的な側面の課題(例: 完全に破損したDBからの復元)から対応プロセスの課題を発見・解決するもの(ニュアンステスト)に徐々に移行しつつある。
技術的な課題は議論や自動化が比較的容易だが、ニュアンステストで問題箇所を見つけるのは難しい。
対応者の準備
インシデント対応演習により、対応者のストレスを減らしたり、悪影響を特定して支援したりすることができる。
どのようにインシデント対応テストを作成するか
最近の(実際の)インシデントを参考にするとよい。
Googleではポストモーテムで必ず以下の質問をしている。
- 何がいけなかったのか?
- 何が良かったのか?
- どこがラッキーだったのか?
これらの質問により問題を特定し、修正した後は、うまくいくか/修正は十分か/他の場所に悪影響が発生していないか等をテストする必要がある。
第3章 インシデント管理のスケーリング (Response)
コンポーネントレスポンダー
Googleでは、Googleの技術インフラ全体における1つのコンポーネント/システムに精通した"コンポーネントレスポンダー"がいる。
技術スタックの範囲が大きくなって一人の人間が理解する能力を超えた場合は、技術スタックを分割し、複数の対応者がそれぞれ1つのコンポーネントをカバーする。
この方法のリスクとしては、複数のコンポーネントにまたがる問題やシステム間の境界の問題、専門のコンポーネント以外の問題への対応に関するサポートが難しくなることである。これを軽減するためにSoSレスポンダーを設定する。
SoS (System of System) レスポンダー
SoSレスポンダーは、複数のコンポーネント/システムにまたがるインシデント等をサポートするために待機している対応者である。SoSレスポンダーはより全体を見通す視点に立ち、政治的・組織的・協調的な対応を手動する。
Googleでは2種類のSoSレスポンダーがいる。
- Product-focused incident response teams (IRTs): 製品に特化したチーム
- Technical incident response team (Tech IRT): 更に広範囲に焦点を当てるチーム[1]
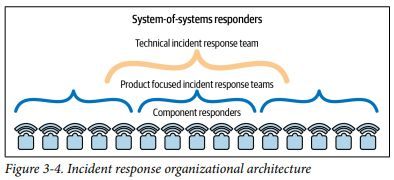
組織体制
インシデント対応を成功させる組織の特徴は以下の4つである。
- 共通のプロトコル: すべての対応者(レスポンダー)が同じインシデント管理プロトコルを使用することで、役割を明確化し、エンゲージメントのルールを共有できる。GoogleではFEMA[2]のインシデント・コマンド・システム[3]を活用して役割を定義し、役割やプロセスを全員が理解している。
- 信頼: 対応者は、すべての行動に対して承認を求めることなく、インシデントを処理する権限を与えられている。
- 尊敬: 心理的安全性をつくり、維持することが全員の責務である。
- 透明性: インシデントは社内でオープンに報告される。
リスク管理
疲弊を防ぐため、インシデントの特定から解決までの時間は3日以内とする。
インシデント管理の機能とリスク
"インシデント管理モード"の時間を最小化するには、インシデント管理の機能とリスクを認識しておく必要がある。Googleでは、インシデントの重要度を具体的に定義している。
インシデント管理は、短期的な影響を軽減し、長期的な判断を下すための時間を稼ぐものである。短期的な影響・長期的な影響の両方が解消されるまでインシデント管理を継続すべきだという意味ではない。
第4章 緩和と復旧(Mitigation and Recovery)
緊急の緩和措置
最優先事項は原因究明ではなく、ユーザーへの影響を軽減(または無くす)ことである。この段階では、"原因"ではなく、障害という"症状"を緩和する。
クイックフィックス・ボタン(即効性のある緩和策[4])の開発に投資することを検討するとよい。
一般的な緩和策を行うために障害を完全に理解する必要はないが、適切に利用できるように、定期的なテストで実践することが重要である。
インシデントの影響を軽減する
次に、長期的にインシデントの影響を軽減する方法を考える必要がある。
ユーザーが気にしているのはインシデントやその数ではなく、信頼性である。
信頼性を測ることは難しいが、サービスがどの程度良好であるかはSLIを設定し測定する。また、ユーザー・ジャーニー、特にクリティカル・ユーザー・ジャーニー(CUJ)によってユーザの幸福度を測定する。
インシデントの影響度を計算する
インシデントの影響度を計算するために重要な指標として以下がある。
- TTD (Time to Detect): 障害が発生してから検出(人間に通知)されるまでの時間
- TTR (Time to Repair): 障害が検出されてから影響を軽減するまでの時間[5]
- TBF (Time Between Failures): 障害が発生してから次の同種の障害が発生するまでの時間

信頼性のなさは以下の式で表すことができる。
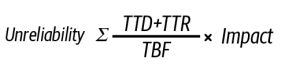
一般的に、自動化と自動修復システムによる対処を行うことで、人間が介在するよりもTTD, TTRを短縮することができる。
TTD (検出までの時間)を短縮する
SLO策定の差異、リスク分析・優先順位付けを行い、SLOの達成を妨げるものを特定する必要がある。また、以下のような取り組みにより、検出までの時間を短縮する。
- SLIをユーザーの期待にできるだけ近づける。
- アラートとSLOを一致させ、定期的に見直す。
- 様々な測定方法を使用して品質を測定する。
- アクションが必要なときのみ、必要な人のみがページ(オンコール)/アラートを受け取るようにする。
TTR (修復までの時間)を短縮する
以下のような取り組みにより、修復までの時間を短縮する。
- 対応者の育成
- 組織的なインシデント対応手順の確立
- インシデント・コマンド・システムに準じて役割を明確化し、チームとして対応する
- 明確なオンコールポリシーとプロセスの確立・文書化
- 有用な手順/プレイブックの作成
- プレイブック作成を重要なものと認識し、ポストモーテムで取り扱い、必要なリソースを割き、貢献として評価する
- 対応者の疲労軽減
- データ収集と可観測性(observability)に投資する
- 極力ユーザー体験に近いデータを取得する
- SLI/SLOを定期的に見直す
- 目的に合ったダッシュボードを利用する(例:インシデントのトラブルシューティングに使うダッシュボードと、管理者がSLOを確認するダッシュボードは異なっているべき。)
TBF (障害の間隔)を長くする
アーキテクチャをリファクタリングし、リスク分析/プロセス改善で特定した障害発生ポイントを修正する。また、以下のような取り組みにより、障害が発生する間隔を長くする。
- アンチパターンの回避
- リスク分散
- 冗長性を確保し、単一障害点を避け、責任を分離し、グローバルな変更を避ける
- 段階的なロールアウトや失敗時の自動ロールバック、自動テストを採用する
- Dev Practice (開発の文化)の採用
- 信頼性を考慮した設計
- Graceful Degradation (サービス停止を避けて縮退稼働させる)の実装
- Defense-in-depth (多層防御)
- 障害に耐えるシステムを構築する[6]
- N+2個のリソースを確保
- 失敗から学ぶ(ポストモーテム)
第5章 ポストモーテムとその後
注力すべき箇所を知るには、データ駆動型のアプローチを採るとよい。社内でポストモーテムを広く共有し、パターンを分析することが推奨される。
心理的安全性
適切な対応のためには、「変化の速度を考えるとインシデントや停止は避けられない」ことを理解し、支援と権限を与える文化が必要。インシデントから学ばないことは、改善の機会を逃していることになる。
インシデントの原因は人間ではなくシステムやプロセスにある。
インシデント管理や対応を実践する際に心理的安全性を担保するには、以下のような文化が必要である。
- できごとを学習の機会として捉える
- 多様なアイデアを奨励し、意見や質問を歓迎する
- 責任を負わせない
- 失敗から学ぶ
チームメイト間、パートナーチーム間、マネージャー、組織など様々なレベル/関係性において、心理的安全性を考慮する必要がある。[7]
インシデントの対応者は、何でも自分でやろうとする傾向があることを強く意識し、かわりに早く頻繁にエスカレーションを行うべきである。
ポストモーテムを作成する
ポストモーテムは、サービスに対するエンジニアリングを実践し改善を推進するための中核となる。
全てのポストモーテムは、以下を含む必要がある。インシデント中には記録を取り(keeping a “live document”)、後々ポストモーテムで利用することが望ましい。
- 明確なアクションアイテム、そのオーナー、期限など
- これは責任を負わせるためではなく、曖昧さをなくして確実にフォローアップするためのものであることに注意。
- インシデントの明確なタイムライン
- エスカレーションが発生した場合、その理由と方法
- "インシデント"と"停止(outage)"、インシデント"開始"と"検出"の用語を区別する。
ポストモーテムでは心理的安全性を実践する。また、透明性をもって共有されるべきである。
組織改善のためのシステム分析
インシデント後に分析を深めることで、根本的な問題の理解に近づくことができる。
以下は、エンジニアリング作業とシステム分析の相互作用を示すベン図である。
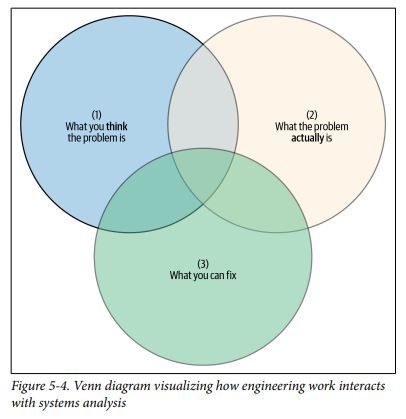
取り組むべきなのは (1)問題だと思うこと、(2)実際の問題、(3)アクション可能なこと、の3つが重なる部分となる。システム分析により(1)と他の2つの円とのギャップを減らし、本当に効果的な対処にリソースを割く必要がある。
分析において重要な事柄として以下を挙げる。
- 根本原因 vs トリガー
- 根本原因は、システムがどのように脆弱であったかを指す。
- トリガーは、根本原因がインシデントに転じることを可能にした状況のことを示す。
- トリガーは「ある/ない」の二律背反的なものではなく、動的なものである。
- 例:
- 根本原因: メモリリークを発生させるような設定ファイルの変更
- トリガー: 大量のリクエスト
- インシデント: Out Of Memory
- 独立した技術スタックと全体的なスタックの比較
- システムのコンテキスト(システムの機能に関連するシステム環境の部分)を考慮する
- 個々のインシデントと長期的な変化[8]
- "変化の軌跡"としてはどうなっているか、という観点で見直す
第6章 マヤの黙示録: 実例
Googleでは、"マヤの黙示録"とはマヤ文明の人類滅亡説のことではない。
これは2019年6月2日、Mayaというネットワーク自動化ツールでの話である。
その日、計画的なメンテナンスでのミスフラグがジョブスケジューリングロジックと衝突し、トラフィック方向に関するジョブが一斉にスケジュール解除されるという障害が"発見"された。トラフィック方向がまだ機能している残りのネットワーク容量へスケジュール解除されたジョブを収めようとしたが、上手くいかなかった。
ネットワークが輻輳し、システムはトラフィックの過負荷に正しく対処した、より小さく遅延の影響を受けやすいトラフィックフローを維持するために、より大きく遅延の影響を受けにくいトラフィックを自動的に削減した。その結果アラートが発生し、対応者(コンポーネントレスポンダー)は状況の評価を始めた。
一方で、ネットワークの輻輳はネットワーク、コンピューティングのインフラ全体に連鎖的な障害を引き起こした。Googleのネットワークは社内トラフィックよりもユーザを優先しているため、社内ツールが停止し、アラートが錯綜して多くのオンコールが鳴り響いた。
ネットワークコンポーネントの担当者は輻輳の原因を特定したが、障害により正しい設定を復元することもまた難しくなっていた。
ほとんどの人は、システム全体で何が使用不能になったのか、全体像を把握していなかった。なぜなら、輻輳が発生したネットワークを利用しないパスで提供されるサービスは機能していたからである。
障害開始から1時間後、あるコンポーネントレスポンダーはSystem of Systemの問題(システム間の問題)が大きすぎて協調的なコミュニケーションが混乱していると指摘した。多くの人が何とかしようとした結果、混乱が生じていたのである。そこでTech IRTへのエスカレーションが行われた。
インシデントコマンダー(指揮官)として対応したTech IRTメンバーは、技術的対応を行い、内部トラフィックに少々余裕が出たところでネットワークコンポーネントの担当者に指示を出して事態を収束させた。
そして、混乱していたコミュニケーションと「参加しよう」としていた人々に対して構造化と整理を行った。それにより全員が一丸となって前進することができ、影響緩和のために適切な対応を取ることができた。
緩和の目途が立つと、Tech IRTメンバーはインシデントの終結に注力した。インシデント終結の基準を設定し、復旧した他のシステムが対応から手を引けるようにしたのである。
インシデント終了後、分析と綿密な事後調査が行われた。ネットワークチームはMayaを再構築し、今回"発見"された障害を防止する取り組みに着手した。
最後に、関係者の貢献を称え、褒賞が与えられた。
第7章 まとめと今後
このレポートでは、インシデント管理のライフサイクルである 準備・対応・軽減と復旧 について述べた。次に考えるべきことは何だろうか?
インシデント対応という行為は、優先順位を決定するための時間を稼ぐために発生中の問題に対して緩和策を講じることを目的としている。つまり、インシデント対応中には長期的/定期的な計画や改善が優先されない可能性がある。また、インシデント対応は対応者にストレスを与える業務でもある。そのため、企業にとってはインシデント管理をできるだけ上手く行い、できるだけ少なくすることが不可欠となる。
そこで次のアクションアイテムは、チーム全体がインシデント管理ライフサイクルの全ての部分を改善するために積極的に取り組むということである。ヒロイズム的でない地道な改善、そして心理的に安全な職場をはぐくむことで、社員が生き生きと働き素晴らしい製品を作れるようになる。
一般的に、全ての問題に対してインシデント管理を用いるべきではない。インシデント管理が終わったら、より長期的な問題やリスクを解決するために必要なエンジニアリングに取りかかろう。
以上
-
経験豊富なレスポンダーが24/365シフトで対応し、年2回・2週間の製品トレーニング、四半期ごとの対応テストで入念に準備している ↩︎
-
アメリカ合衆国連邦緊急事態管理庁 ↩︎
-
原文ではこれを、雨漏りの影響を止めるバケツに例えている。 ↩︎
-
根本対処が完了するまでにかかった時間ではない。例としては、トラフィックを別リージョンに移すなどの対処でユーザーへの影響を軽減するために、対応者が要した時間など。 ↩︎
-
ここではセキュリティではなく、障害に耐えるシステムアーキテクチャについて"Defense-in-depth"と表現している模様 ↩︎
-
レポート原文には具体例が記載されている。 ↩︎
-
かなり意訳した。原文はPoint-in-Time versus Trajectory。 ↩︎
Discussion