SpikeGPT で遊んでみる
SpikeGPT という、 RWKV言語モデル に触発されたSNN(Spiking neural networks)系の言語モデルがあるらしい
RWKVがRNNであるのに対してSNNが使われていて、エネルギー効率が良いとのこと 論文
SpikeGPTを動かすために必要なのは、次の通りっぽいが細かなバージョンの指定が必要かもしれない、後述するけど一部修正している
$ python -mvenv spikegpt
$ source spikegpt/bin/activate
$ pip install torch
$ pip install numpy
$ pip install accelerate
$ git clone https://github.com/ridgerchu/SpikeGPT
$ cd SpikeGPT
まずは学習を試してみる
手元に 以前使った日本語wikipedia のデータがあるのでそのまま利用してみた
model_typeは RWKV か RWKV-ffnPre が選べるらしいが、いったん RWKV を選択している
--- a/train.py
+++ b/train.py
@@ -20,16 +20,13 @@ torch.backends.cuda.matmul.allow_tf32 = True
### Step 1: set training data ##########################################################################
-datafile_train = "enwik8"
-datafile_valid = "valid.txt"
-datafile_test = "test.txt"
+datafile_train = "/path/to/ja.txt"
datafile_encoding = 'utf-8'
-# datafile_encoding = 'utf-16le'
@@ -49,8 +46,8 @@ lr_final = 1e-5
# the mini-epoch is very short and of fixed length (ctx_len * epoch_length_fixed tokens)
n_epoch = 1000
# 0 = never, 1 = every mini-epoch, 2 = every two mini-epochs, etc.
-epoch_save_frequency = 10
-epoch_save_path = 'your_path'
+epoch_save_frequency = 1
+epoch_save_path = '/path/to/out'
次に numpy で deprecated と言われてしまう (np.float was a deprecated alias for the builtin floatとなる) ので、若干書き換える
--- a/src/binidx.py
+++ b/src/binidx.py
@@ -27,8 +27,8 @@ dtypes = {
3: np.int16,
4: np.int32,
5: np.int64,
- 6: np.float,
- 7: np.double,
+ 6: np.float16,
+ 7: np.float32,
8: np.uint16,
}
そして、cupyを必要としているのだけど、 pip で入れただけではだめらしいので torch を使うように書き換え
--- a/src/model.py
+++ b/src/model.py
@@ -313,9 +313,9 @@ class Block(nn.Module):
self.ln1 = nn.LayerNorm(config.n_embd)
self.ln2 = nn.LayerNorm(config.n_embd)
- self.lif1 = neuron.MultiStepLIFNode(tau=2., surrogate_function=surrogate.ATan(alpha=2.0), backend='cupy',
+ self.lif1 = neuron.MultiStepLIFNode(tau=2., surrogate_function=surrogate.ATan(alpha=2.0), backend='torch',
v_threshold=1.)
- self.lif2 = neuron.MultiStepLIFNode(tau=2., surrogate_function=surrogate.ATan(alpha=2.0), backend='cupy',
+ self.lif2 = neuron.MultiStepLIFNode(tau=2., surrogate_function=surrogate.ATan(alpha=2.0), backend='torch',
v_threshold=1.)
# self.lif1 = neuron.LIFNode(surrogate_function=surrogate.ATan(),step_mode='m',backend='cupy',detach_reset=True)
# self.lif2 = neuron.LIFNode(surrogate_function=surrogate.ATan(),step_mode='m',backend='cupy',detach_reset=True)
n_layer = 6, batch_size = 10 に下げて train できるようになった
$ python train.py
RWKV_HEAD_QK_DIM 0
Using /home/octu0/.cache/torch_extensions/py38_cu117 as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /home/octu0/.cache/torch_extensions/py38_cu117/wkv/build.ninja...
Building extension module wkv...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
ninja: no work to do.
Loading extension module wkv...
loading data... /path/to/ja.txt
building token list... data has 964555944 tokens, 18273 unique.
model RWKV epoch 1000 batchsz 10 betas (0.9, 0.99) eps 4e-09 ctx 1024 layer 6 embd 768
mini-epoch 1 prog 0.10% iter 999: ppl 40.43 loss 3.6995 lr 5.999985e-04: 100%|██████████| 1000/1000 [2:56:21<00:00, 10.58s/it]
mini-epoch 2 prog 0.20% iter 999: ppl 20.69 loss 3.0295 lr 5.999942e-04: 100%|██████████| 1000/1000 [2:53:18<00:00, 10.40s/it]
mini-epoch 3 prog 0.30% iter 999: ppl 17.56 loss 2.8659 lr 5.999869e-04: 100%|██████████| 1000/1000 [2:56:51<00:00, 10.61s/it]
mini-epoch 4 prog 0.40% iter 999: ppl 16.17 loss 2.7830 lr 5.999767e-04: 100%|██████████| 1000/1000 [2:58:07<00:00, 10.69s/it]
mini-epoch 5 prog 0.50% iter 999: ppl 15.20 loss 2.7214 lr 5.999636e-04: 100%|██████████| 1000/1000 [2:56:38<00:00, 10.60s/it]
学習時の VRAM の消費は 13GB 程度
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 511.69 CUDA Version: 11.6 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA RTX A5000 Laptop GPU On | 00000000:01:00.0 Off | N/A |
| N/A 62C P0 26W / N/A| 12791MiB / 16384MiB | 25% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 22511 C /python3.8 N/A |
+---------------------------------------------------------------------------------------+
文字列を生成させてみる run.py は書いてある通りで、出力されたモデルのパスに指定し直している、のと
コメントアウトされてる生成時間の箇所を戻して時間を出すようにしている
--- a/run.py
+++ b/run.py
@@ -33,13 +33,13 @@ setup_io()
TOKEN_MODE = 'char' # char / bpe / pile
#For book Corpus Pre-trained model
-n_layer = 18
+n_layer = 6
n_embd = 768
ctx_len = 1024
if TOKEN_MODE == 'char':
- MODEL_NAME = 'BookCorpus-SpikeGPT' # your trained model
- WORD_NAME = 'vocab_book' # the .json vocab (generated by train.py)
+ MODEL_NAME = './out5'
+ WORD_NAME = 'vocab'
@@ -105,7 +106,7 @@ print('\nYour prompt has ' + str(src_len) + ' tokens.')
print('\n--> Currently the first run takes a while if your prompt is long, as we are using RNN to process the prompt. Use GPT to build the hidden state for better speed. <--\n')
for TRIAL in range(1 if DEBUG_DEBUG else NUM_TRIALS):
- #t_begin = time.time_ns()
+ t_begin = time.time_ns()
print(('-' * 30) + context, end='')
ctx = src_ctx.copy()
model.clear()
@@ -145,5 +146,6 @@ for TRIAL in range(1 if DEBUG_DEBUG else NUM_TRIALS):
print(tokenizer.tokenizer.decode(int(char)), end='', flush=True)
ctx += [char]
- #t_end = time.time_ns()
- #print("\n----------", round((t_end - t_begin) / (10 ** 9), 2), end='s ')
+ t_end = time.time_ns()
+ print("\n----------", round((t_end - t_begin) / (10 ** 9), 2), end='s ')
+print("\n")
context = "吾輩は猫である、名前はまだない、" として、約12時間学習させたもので実行した
$ python run.py
Loading ./out5...
RWKV_HEAD_QK_DIM 0
Using /home/octu0/.cache/torch_extensions/py38_cu117 as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /home/octu0/.cache/torch_extensions/py38_cu117/wkv/build.ninja...
Building extension module wkv...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
ninja: no work to do.
Loading extension module wkv...
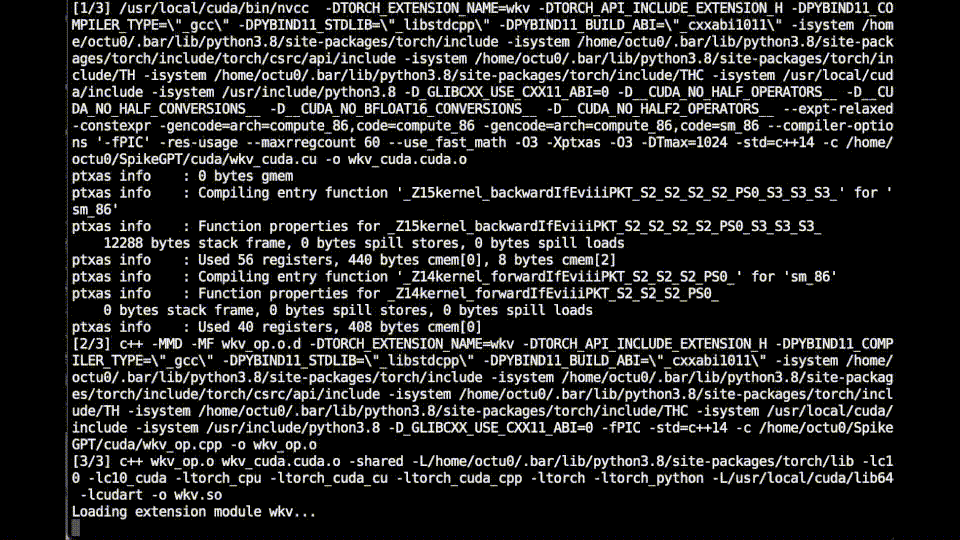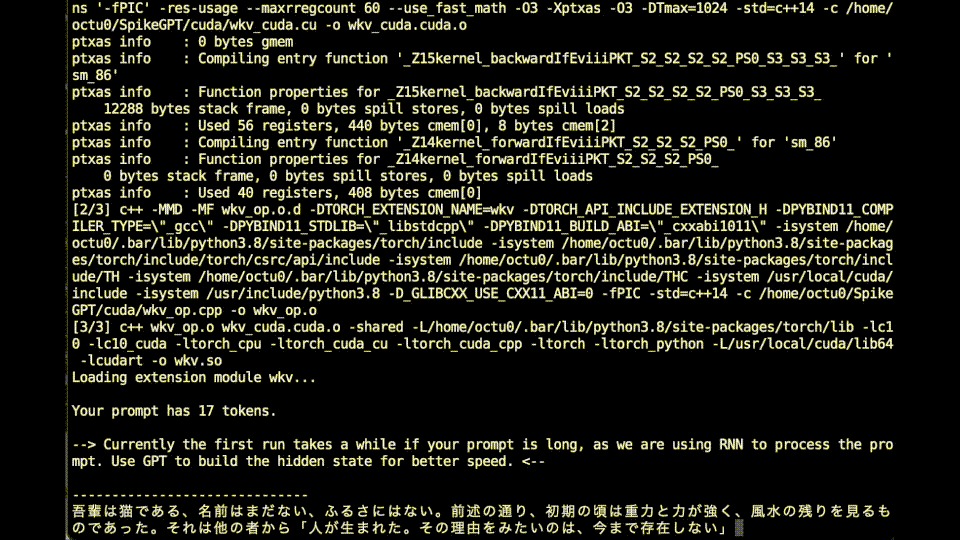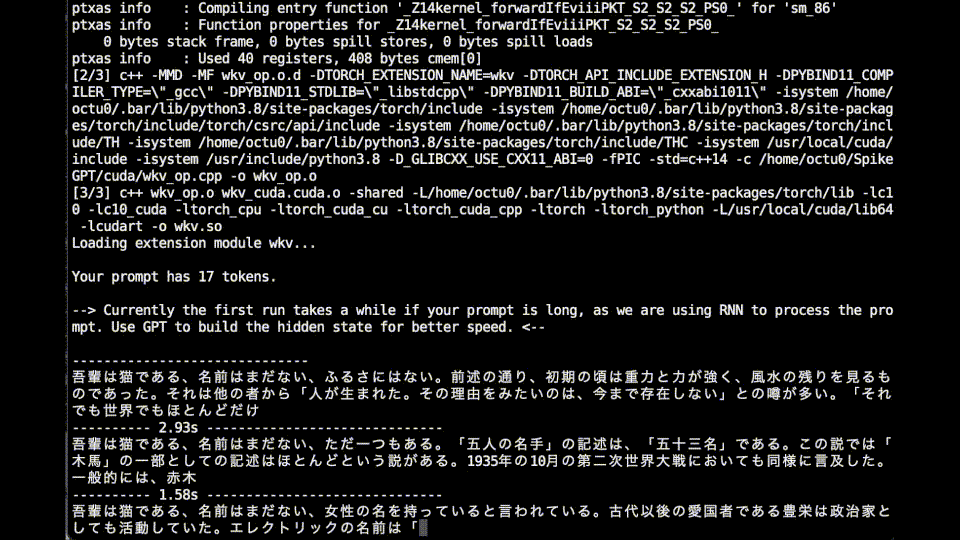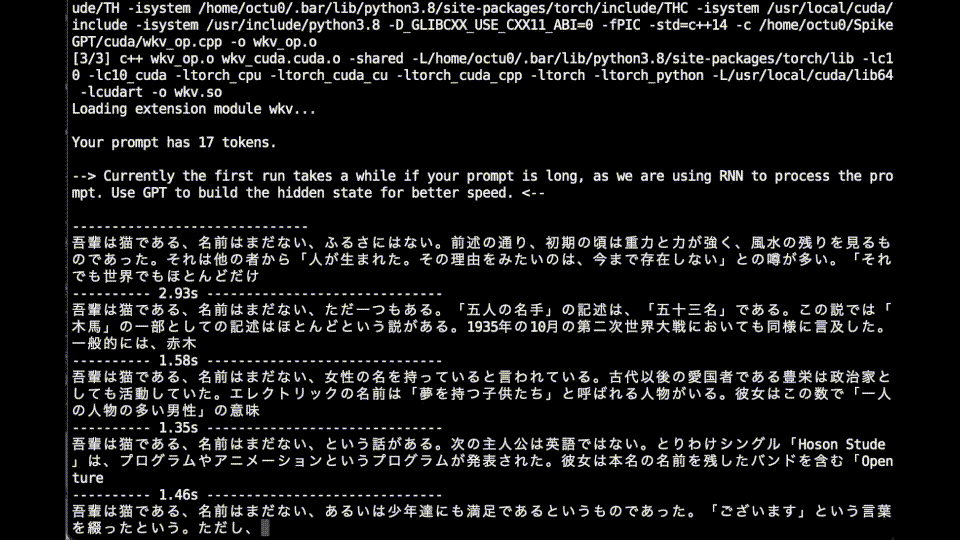
Your prompt has 17 tokens.
--> Currently the first run takes a while if your prompt is long, as we are using RNN to process the prompt. Use GPT to build the hidden state for better speed. <--
------------------------------
吾輩は猫である、名前はまだない、しばしば、ミシガンとして名前がある。ただし、薬物の薬草の食事により、その他にもタバコの中からフィリップを食べる事もある。また、おまけにはまず、ハンガリーのギャンガンがハーバード・ヘンリーの作品である。
---------- 3.08s ------------------------------
吾輩は猫である、名前はまだない、『聖闘士』の本格的な大作となっている。この『"Inetain"』の中で、本作では初めての「太郎」としては一切のことである。『第 三世界』では20世紀末に原作となった「聖」を好んだものである。
一般に、サ
---------- 1.75s ------------------------------
吾輩は猫である、名前はまだない、それ以上の部隊が残ることになったのである。当時の人物は、「東亜」と呼ばれる大きな古い名前であった。東京都出身。東京大学文学部卒業後、父親のメンバーになる。
はっきりしていた。彼は、親友として育ち、東京
---------- 1.66s ------------------------------
びっくりするくらい軽い
RWKVと同じくらいの速度で出力される
この時のVRAMは 1.3GB 程度だった
同じようなデータを使った RWKV では 5GB 程度使用していたので確かに省エネ
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 511.69 CUDA Version: 11.6 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA RTX A5000 Laptop GPU On | 00000000:01:00.0 Off | N/A |
| N/A 54C P3 24W / N/A| 1351MiB / 16384MiB | 33% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 24221 C /python3.8 N/A |
+---------------------------------------------------------------------------------------+
これはもしかしたら小さなデバイスでも動かせれるやつかもしれない