【pythonより簡単!】ノーコードでデータ自動抽出方法


(転載・翻訳)
最近、私はWebサイトからデータを簡単に取得する方法を探しました。ご存じのように、手動でWeb上の情報を収集するのは結構時間のかかる作業です。より効率化の情報収集方法を見つけるために、自動にWeb上の情報収集ツールを調べました。そして、Octoparseというスクレイピングツールが見つかりました。

Octoparseは、コードを書かずに複数のWebサイトから情報(データ)を抽出できるWebスクレイピングツールです。これはノーコードの情報収集ツールで、誰でも簡単に利用できます。プログラミングの知識がなくても、簡単に情報を収集することが可能です。
さらに、より便利なサービスを提供するために、Octoparseは事前にAmazon、ebey、Yahoo、楽天などのよく使うWebサイトのテンプレートを用意しました。これらのテンプレートをチェックして、自分のニーズに合わせて、直接にテンプレートを使用できます。そして、ソフトウェアでスクレイピングタスクを実行し、抽出されたデータをCSV、TXT、Excel、HTML、またはデータベースに保存できます。
Octoparseはどのようにスクレイピングタスクを作成し実行し、そして、抽出したデータをGoogleスプレッドシートドキュメントに保存していくのでしょうか。これから、Octoparseそのものから明らかにしましょう!
1、Octoparseとは?
「Octoparseはコーディングせずにインターネット上にある無限の情報の中から、必要なデータを欲しい形で自動収集(Webクローリング)するWebクローラーです。」—Octoparseの公式ウェブサイト
Octoparseは、インターネットでほとんどあらゆる種類のデータを抽出できるWebサイトクローラーです。より簡単にデータを抽出するために、自動検出、タスクテンプレート、上級モードなど、さまざまな機能を備えています。
これから、その三つの主な機能を簡単に紹介させていただきます。
一つ目は自動検出機能:Octoparseで入力されたURLを開き、そして、自動検出アルゴリズムがどんなデータが欲しいを推測し判断し、データを自動的に抽出します。
二つ目はテンプレートの用意:Octoparseは誰でも簡単にデータを抽出するために、ソフトウェアで数多くのテンプレートを用意しています。ユーザーはこれらのテンプレートを利用して直接にデータを抽出できます。
三つ目は上級モード:これは柔軟かつ強力なモードです。このモードをうまく利用しようとすると、Octoparseの使い方を学ぶ必要があります。上級モードに達したら、ほとんどあらゆるの公開されたWebサイトであらゆるデータを抽出することが可能になります。
Octoparseは、ユーサに分かりやすくデータ抽出プロセスを示すために、左側「ワークフロー」を設置しています。この「ワークフローから」から、データ抽出のプロセンスを示しています。抽出されたデータも簡単にExcelなどの形にエクスポートもできます。
それだけでなく、Octoparseはクラウド抽出機能を提供しています。スケジュールを設定することによって、パソコンに外しても、octoparseは自動的にデータを抽出できます。または、リアルタイムで抽出することも可能です。
または、OctoparseはWebサイトの検出を避けるために、人間の行動をシミュレートしています。または、IPプロキシサーバーも持っているため、 IPを隠し、IPブロッキングを回避します。
要するに、Octoparseはプログラミングの知識がなくても簡単にデータを抽出できる誰でも利用できるスクレイピングツールです。
2、データ抽出タスクを作成
例えば、私たちはリアルタイムで
List_of_countries_and_dependencies_by_populationからデータをスクレイピングしようとするならば、どうすればいいですか?
1)Octoparseをダウンロードする
まず、Octoparseのインストール方法をチェックしましょう。
次に、データを抽出したいWebサイトのURlを用意します。
以上の準備ができたら、Octoparseでデータを抽出してみましょう。
Octoparseのダウンロード手順を以下のようにチェックしましょう。
1.ダウンロードしたインストーラーファイルを解凍します
2.OctoparseSetup.msiファイルを実行します
3.インストール手順に従ってください
4.Octoparseアカウントでログインします。アカウントが持っていない場合はこちらに新規登録を作りましょう。
Octoparseはデータ抽出のニーズに合わせ、いくつかのプランがあります。もうちろん無料のプランもあります。個人としてのデータ収集の場合はほとんど無料プランが満足されますが、より多くのOctoparseの強力な機能を試みたい場合はこちらの上位プランをお薦めです。
2)タスクの作成
データ抽出の方法について、Octoparse公式のwebサイトで初心者ガイドとビデオチュートリアルがありますので、ぜひご利用くださいます。
Octoparseを起動し、ログインし、そしてURLを入力して、「抽出開始」ボタンをクリックします。このような手順をしてから、システムは自動検出機能を使って、データを自動的に抽出します。
たとえば、以下のURLからデータを抽出します。
https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population

Octoparseはページを読み込んだ後に、データが検出されるまでに待ちます。自動検出が完了したら、オレンジ色の[操作ピント]で表示された指示に従い、データ抽出の各ステップを確認します。最後に、データフィールドの名前を変更し、不要なデータフィールドを削除します。

「操作ピント」欄に「ワークフローの作成」ボタンをクリックします。そして、左上の [保存] ボタンをクリックします。次に、ダッシュボードビューにチェックすると、先ほど作成したタスクは下図のように表示されます。

そして、タスクの名前を変更したり、ローカルまたはクラウドで実行したりできます。ここまで、データ抽出作業が完了します。
APIを介してこのタスクを実行する場合は、[その他]> [クラウドの実行]メニューから[API]をクリックします。
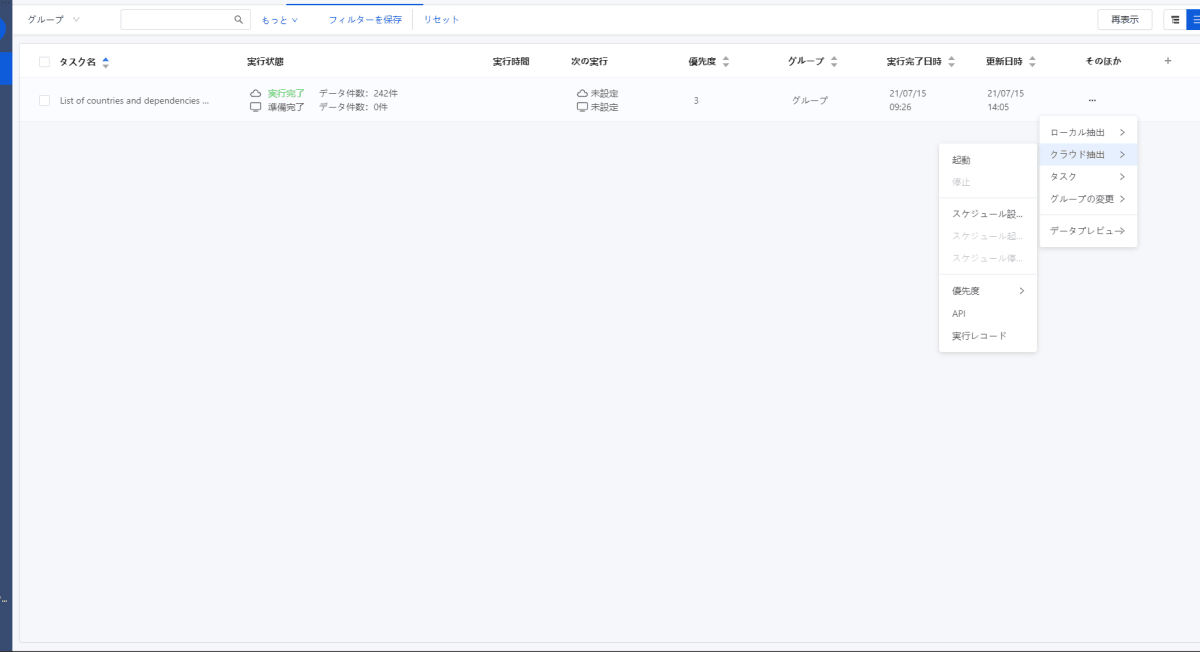
次に、タスクIDを示す別のウィンドウが表示されます。後で使いますので、安全な場所に保管することを忘れないでください。

3、Pythonで実行する
これからも、どのようにOctoparse APIを使用して、その前に作成したタスクが抽出されたデータをGoogleスプレッドシートドキュメントに保存方法について詳しく説明します。
ここにPythonスクリプトを使用してこれを実現して行きたいと思います。
import sys
import requests
import os
import gspread
import pandas as pd
def login(base_url, email, password):
"""login and get a access token
Arguments:
base_url {string} -- authrization base url(currently same with api)
email {[type]} -- your email
password {[type]} -- your password
Returns:
json -- token entity include expiration and refresh token info like:
{
"access_token": "ABCD1234", # Access permission
"token_type": "bearer", # Token type
"expires_in": 86399, # Access Token Expiration time (in seconds)
"refresh_token": "refresh_token" # To refresh Access Token
}
"""
content = 'username={0}&password={1}&grant_type=password'.format(email, password)
token_entity = requests.post(base_url + 'token', data=content).json() token_entity = requests.post(base_url + 'token', data=content).json()
if 'access_token' in token_entity:
return token_entityr
else:
os._exit(-2)
def get_data_by_offset(base_url, token, task_id, offset=0, size=10):
"""offset, size and task ID are all required in the request.
Offset should default to 0, and size∈[1,1000] for making the initial request.
The offset returned (could be any value greater than 0) should be used for making the next request.
Arguments:
base_url {string} -- base url of the api
token {string} -- token string from a valid token entity
task_id {string} -- task id of a task from our platform
Keyword Arguments:
offset {int} -- an offset from last data request, should remains 0 if is the first request (default: {0})
size {int} -- data row size for the request (default: {10})
Returns:
json -- task dataList and relevant information:
{
"data": {
"offset": 4,
"total": 100000,
"restTotal": 99996,
"dataList": [
{
"state": "Texas",
"city": "Plano"
},
{
"state": "Texas",
"city": "Houston"
},
...
]
},
"error": "success",
"error_Description": "Action Success"
}
"""
url = 'api/allData/getDataOfTaskByOffset?taskId=%s&offset=%s&size=%s' % (task_id, offset, size)
task_data_result = requests.get(base_url + url, headers={'Authorization': 'bearer ' + token}).json()
return task_data_result
def run_countries_task(base_url, token_entity):
"""Running the countries task
Arguments:
base_url {string} -- API base url
token_entity {json} -- token entity after logged in
"""
# retrieving an access token after the login
token = token_entity['access_token']
# your task id
task_id = "ded69c74-f6d5-b64e-4d2e-c8036a8ec3a8"
# running the task and retrieving data
data = get_data_by_offset(base_url, token, task_id, offset=0, size=1000)
# retrieving the extracted data in JSON format
json_extracted_data = data['data']['dataList']
# converting the JSON string to CSV
df = pd.DataFrame(json_extracted_data)
csv_extracted_data = df.to_csv(header=True).encode('utf-8')
# check how to get "credentials":
# https://gspread.readthedocs.io/en/latest/oauth2.html#for-bots-using-service-account
# credentials = ... your credentials
gc = gspread.service_account_from_dict(credentials)
# spreadsheet_id = ... -> your spreadsheet_id
# importing CSV data into your Google Sheet document identified
# by spreadsheet_id
gc.import_csv(spreadsheet_id, csv_extracted_data)
if __name__ == '__main__':
# the email you used to subscribe to Octoparse
email = "test@email.com"
# your password
password = "password"
octoparse_base_url = 'http://advancedapi.octoparse.com/'
token_entity = login(octoparse_base_url, email, password)
run_countries_task(octoparse_base_url, token_entity)
最初にログインをします。次にGet Data By Offset APIを使ってタスクを起動します。そして、JSON形式でデータを抽出します。最後にこれらのデータをCSV形式に変換され、gspreadライブラリを使用してGoogleスプレッドシートドキュメントにインポートします。
スクリプトを実行すると、選択したGoogleスプレッドシートドキュメントに保存されているOctoparseタスクによって抽出されたデータを次のように確認できます。
出来た!APIを利用してデータを抽出しました。
4、終わりに
この記事では、どのように強力なデータ抽出ツールであるOctoparseを利用して、データを抽出する方法を紹介してきました。または、このタスクがどのようにPythonスクリプトに統合され、そしてプログラミングの方法で抽出したデータをGoogleスプレッドシートドキュメントに保存する方法についても紹介していきました。このような機能があるこそ、Octoparseはほぼあらゆるサイトからデータを抽出することが可能になりました。
ここまで読んでくれて本当にありがとうございました!この記事がご参考になれば幸いと思います。何かご質問、ご意見、ご提案がございましたら、お気軽にご連絡ください。
お問合せ:https://helpcenter.octoparse.jp/hc/ja
関連記事:
Python vs Octoparse!初心者向けのYelpスクレイピング方法はどっち?
Discussion