【超簡単!】映像情報を一括抽出方法!NHKを例とし


映画やドキュメンタリーに関する学術研究の場合は一般的に映像のテーマ、制作された年月、俳優のキャストなどの情報を収集する必要があります。その場合はどうしますか?手動で映画やドキュメンタリーの情報を収集します?あるいはソフトウェアツールを利用して、データの収集作業をパソコンに任せますか?多くの人にとってやはりパソコンが自動的にデータを収集する欲しいと思うんですが、今日は、この記事でWeb上の映画やドキュメンタリーの情報を自動的に収集する方法を紹介させていただきます。
1.アーカイブの活用
近年、アーカイブの推進に伴って、映画やドキュメンタリーなどの情報の収集は図書館、博物館などの特別な場所に行かなくても、キーワードを入力するだけでインターネットで簡単に情報を探し出すことができました。アーカイブって一体どういうものでしょうか。
アーカイブとは英語「archive]に由来する言葉であり、「保存」「記録」の意味を持ちます。平成24年から、デジタル技術の発展に伴い、総務者は知のデジタルアーカイブと社会の知識インフラの拡充を積極的に組み込んでいます。具体的に言うと、この動きは「図書・出版物、美術品・博物品・歴史資料などの公共的な知的財産をデジタル化し公開することによって、誰でもどこでも見られる目的として行っています。特に学術研究の場合はデジタルアーカイブの活用することで、より簡単的に情報を入手できるようになりました。
デジタルアーカイブの保存、公開ないし活用について代表的な例はNHKアーカイブです。NHKは日本の公共放送としてよく「みんなのNHK」と呼ばれています。2007年12月に国会の改正放送法が成立し、放送した番組をインタネットで配信できるようになりました。その後、新作番組を放送後後一週間ほど見ることができるキャッチアップ(見逃し)サービスと過去に放送したアーカイブ番組を提供するサービスが実施された。NHKアーカイブでは、学術研究向けのサービスがあります。ここでNHKが制作・放送してきた370万のニュース項目、約60万本の番組の映像を保存しています。インターネットでNHK総合データベースにアクセスし、番組のタイトルや放送日時、番組基本情報、台本、構成表、主演者、著作権などの色々情報を検索することができます。NHKの映像や番組やドキュメンタリーを研究する学者にぜひおすすめます。
NHk学術利用トライアル:https://www.nhk.or.jp/archives/academic/
これはNHK学術利用トライアルのホームページです。

このページの一番下のところに「データベースで探す」があります。下図のように

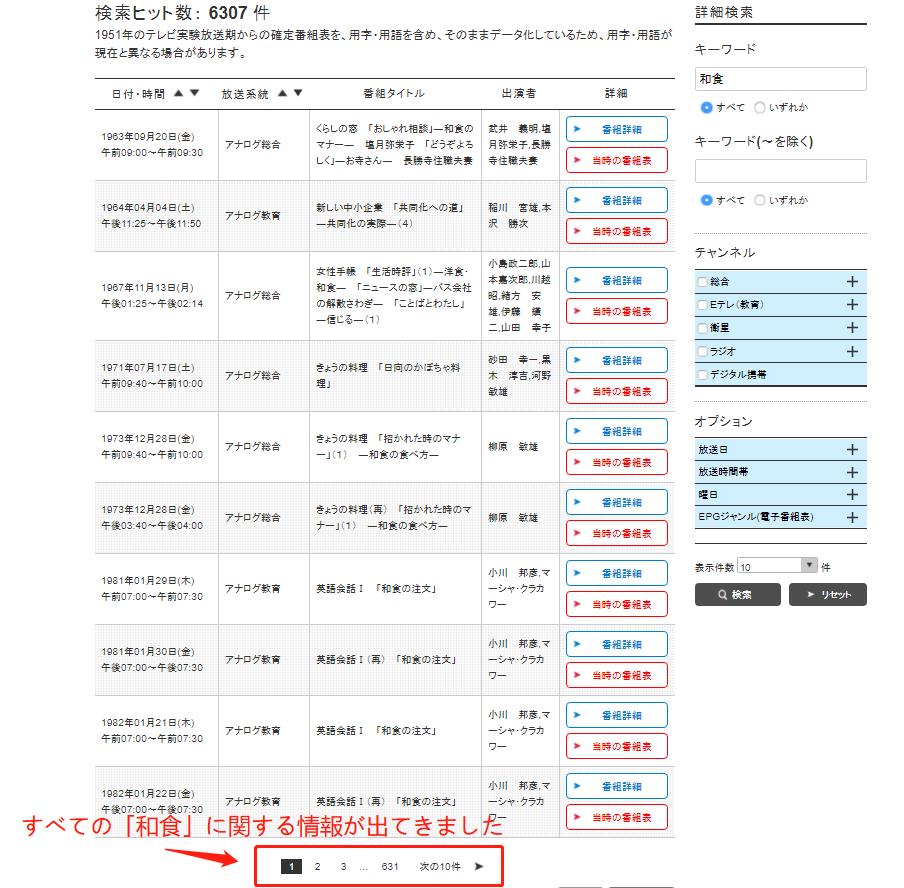
ここにクリックしてから、検索欄が出てきます。その検索欄にキーワードを入力するだけで、NHKが制作や放送したこのキーワードに関する全ての映像アーカイブ情報が出てきます。ここに「和食」を例としてやってみます。

2.データの抽出
たとえば、以下の図のように、「和食」に関するすべての映像の制作された時期、放送系統、番組タイトル、主演者などの情報を提出して、それをExcelにエクスポートする場合はどうしますか?

この場合は、Octoparseというスクレイピングツールをすすめます。
・Octoparseとは
Octoparseとはpythonの知識が不要で、どんなWebサイトで、誰でも簡単にデータを抽出し収集する無料のツールです。ただし、Octoparseの使い方を慣れるまで、使い方の学びや練習が必要です。使い方もそれほど難しいではありませんので、ご安心ください。
では、これからNHKアーカイブのWebサイトで「和食」のキーワードを例として、映像情報をの抽出、収集ないしExcelにエクスポートする方法を紹介していきます。
まず、コンピューターにOctoparseの最新バージョン8.2.2Betaをダウンロードしてください。ソフトウェアのダウンロードとインストールの方法をOctoparseの公式サイトで「Octoparse 8.2.2 Beta がリリース!」にて、ご参照ください。
・映像情報を抽出しましょう!
ステップ1:OctoparseのソフトウェアでNHKアーカイブのULRを開きます。

Octoparseの内蔵ブラウザーでNHKアーカイブのWebサイトが開きました。

ステップ2:欲しいデータのところにクリックして、そして、オレンジ色の「操作ピント」の「すべてを選択」を選択してから、「データ抽出」をクリックしてください。
一般的にOctoparseが内蔵ブラウザーで収集したいデータを自動的に識別出来るが、でもこのWebサイトのようにデータの自動識別はできなくなった場合もあります。そうしたら、一応手動で自分で欲しい情報を選択してください。
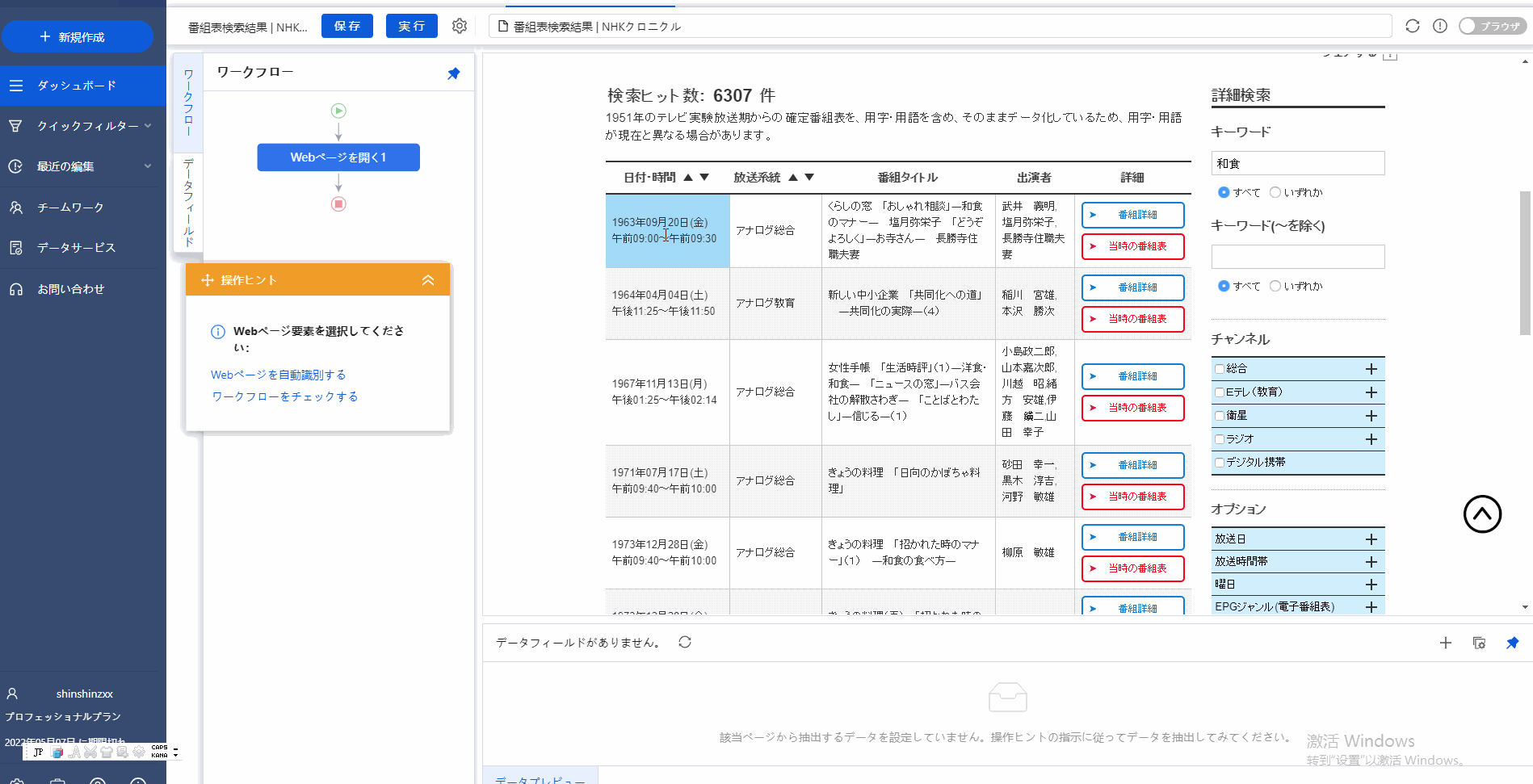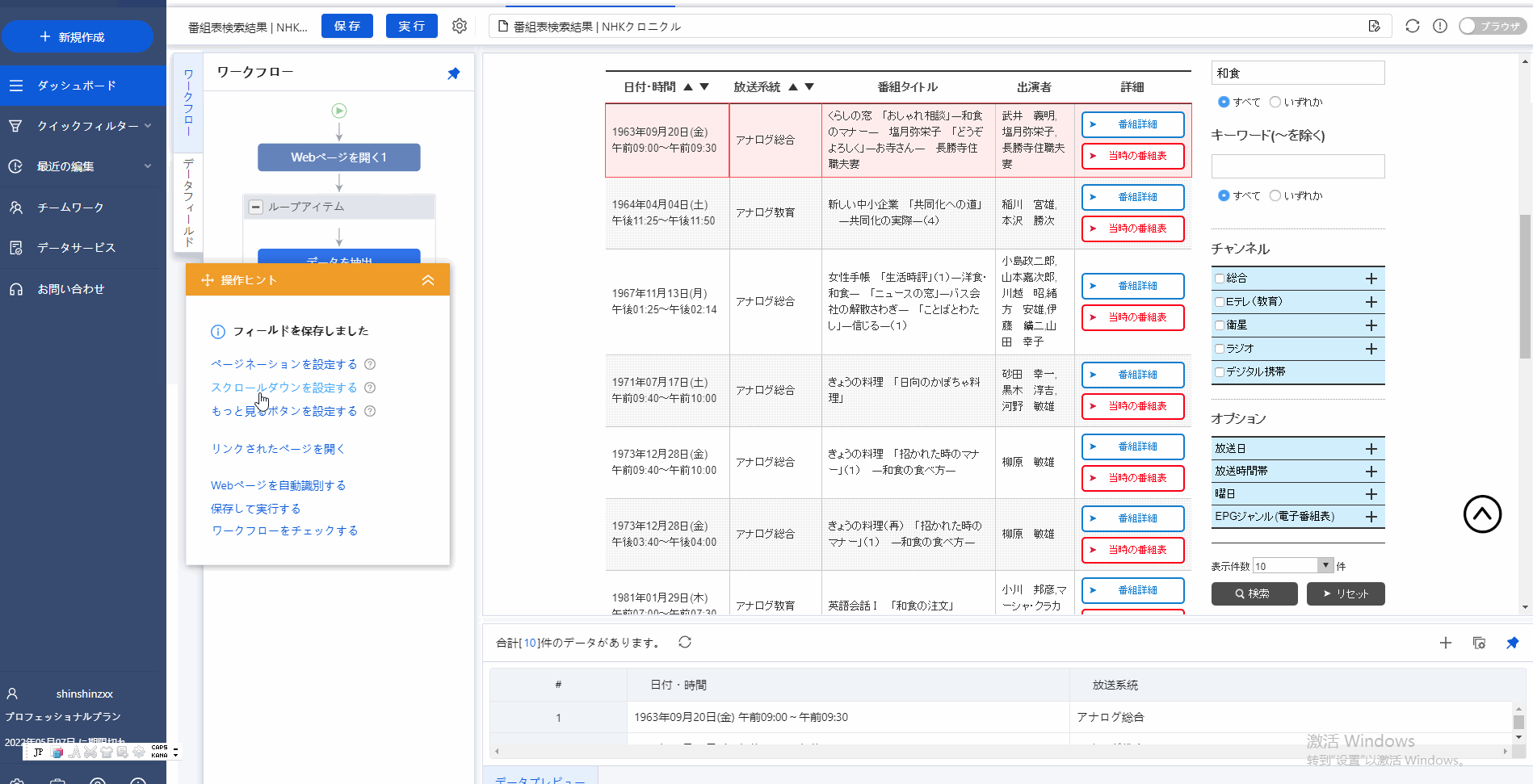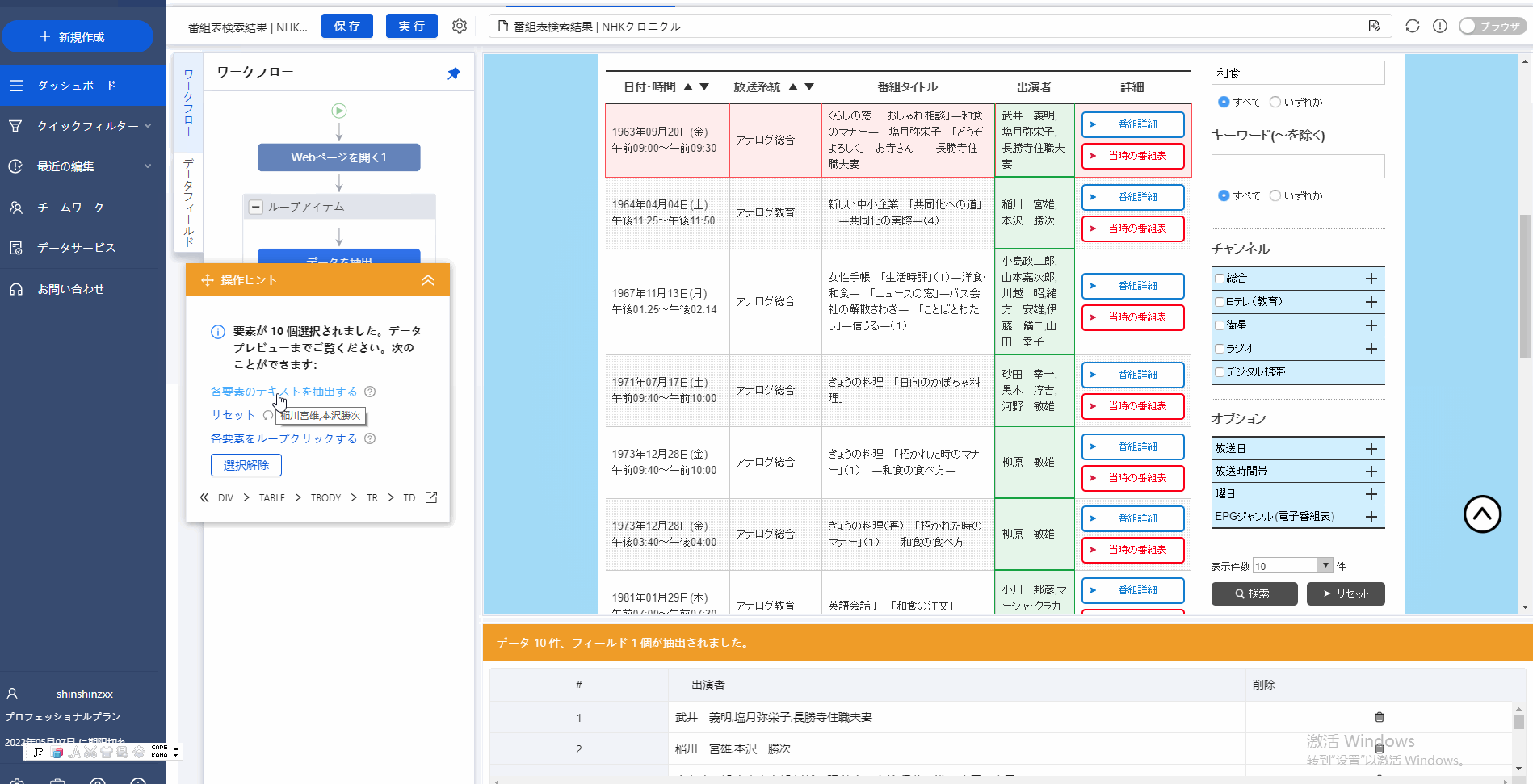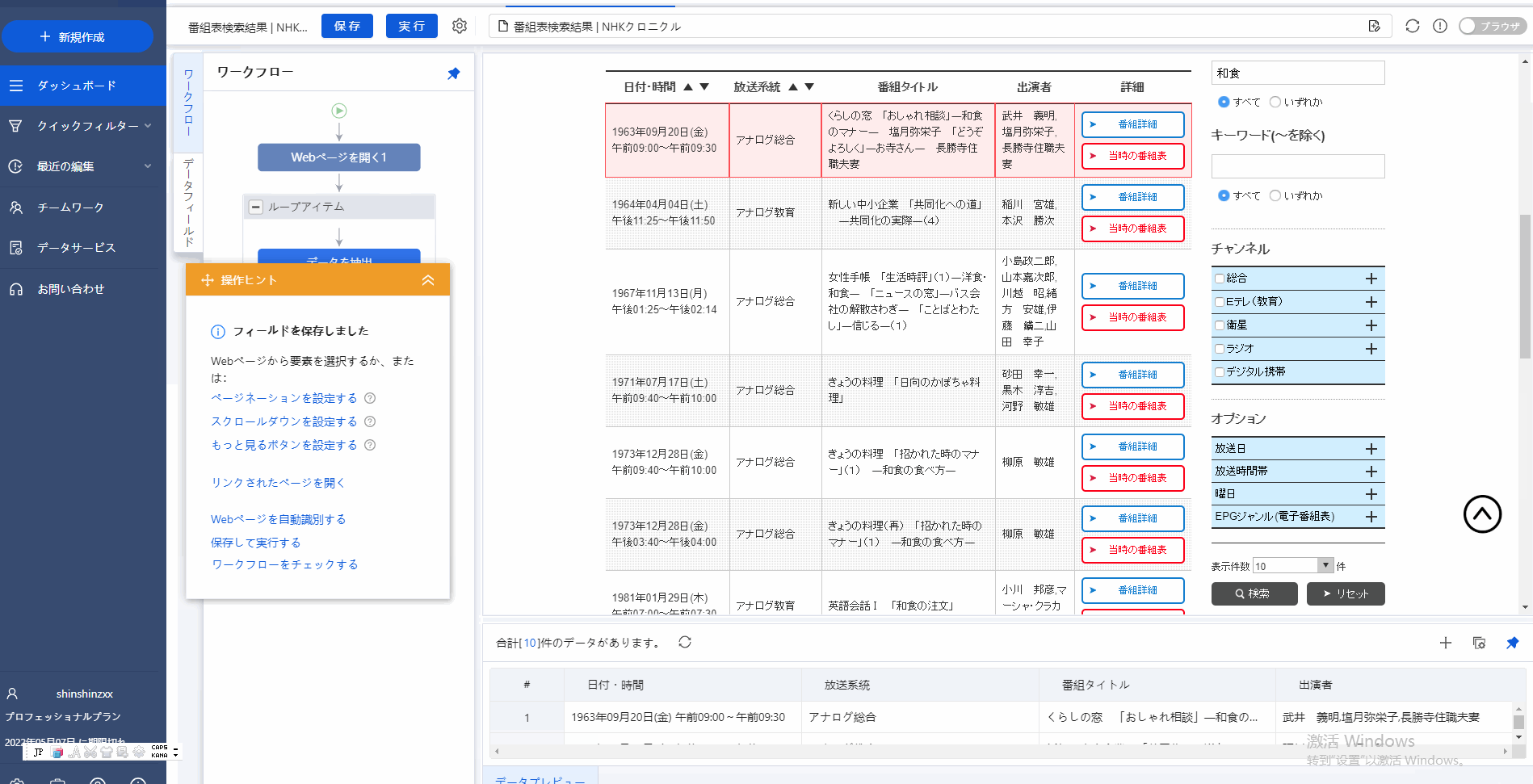
その流れは:データをクリックし→「操作ピント」で「すべて選択」をクリックし→(繰り返し操作して)→「操作ピント」で「データを抽出する」をクリックします。
そのような流れが終わった後に、Octopaseの下のところ(抽出するデータ表示欄)にこのページに手に入れたいすべてのデータをグラフの形で表示されています。
次のページのデータを続けて抽出する場合はどうしますか。
これはステップ3から説明していきます。
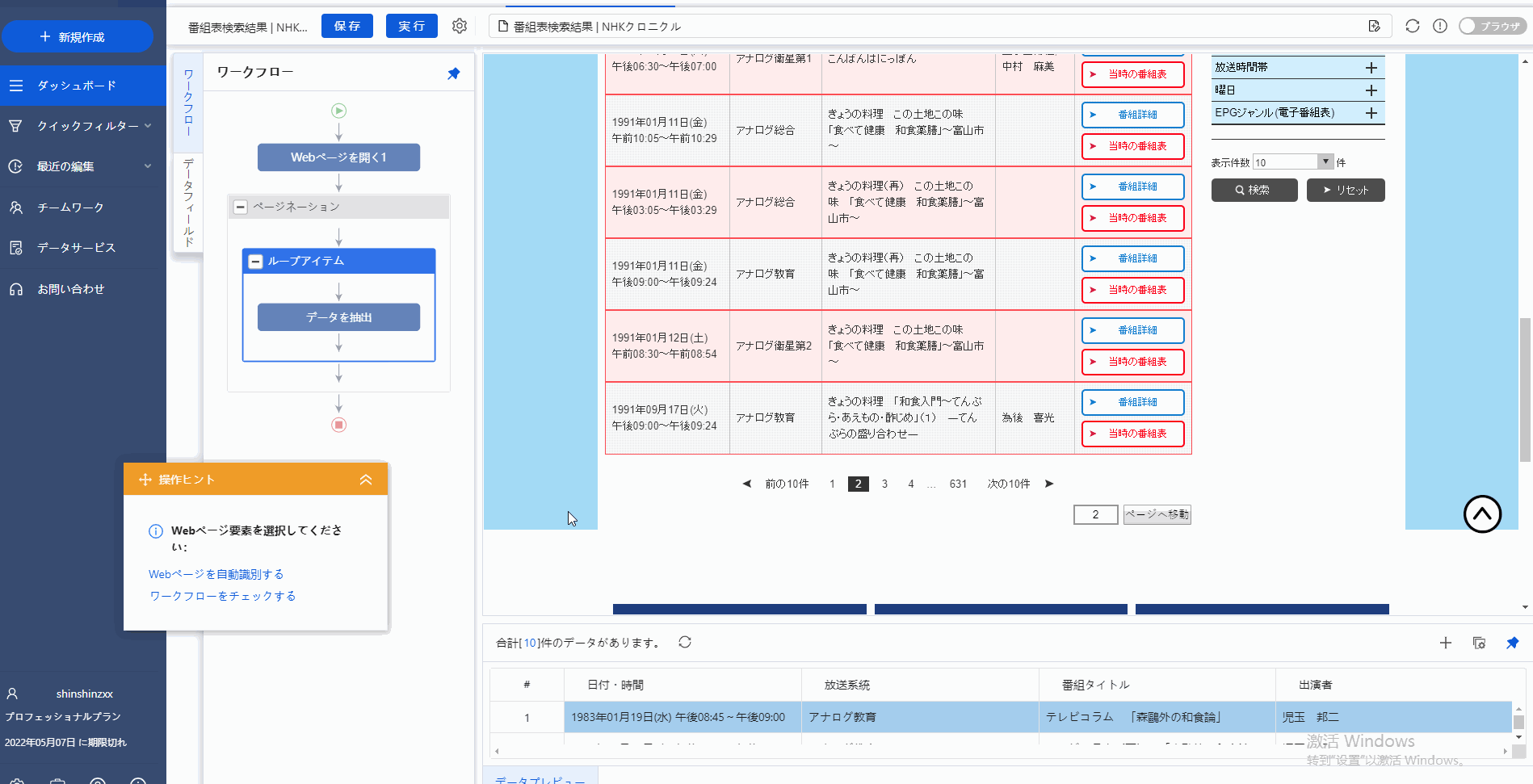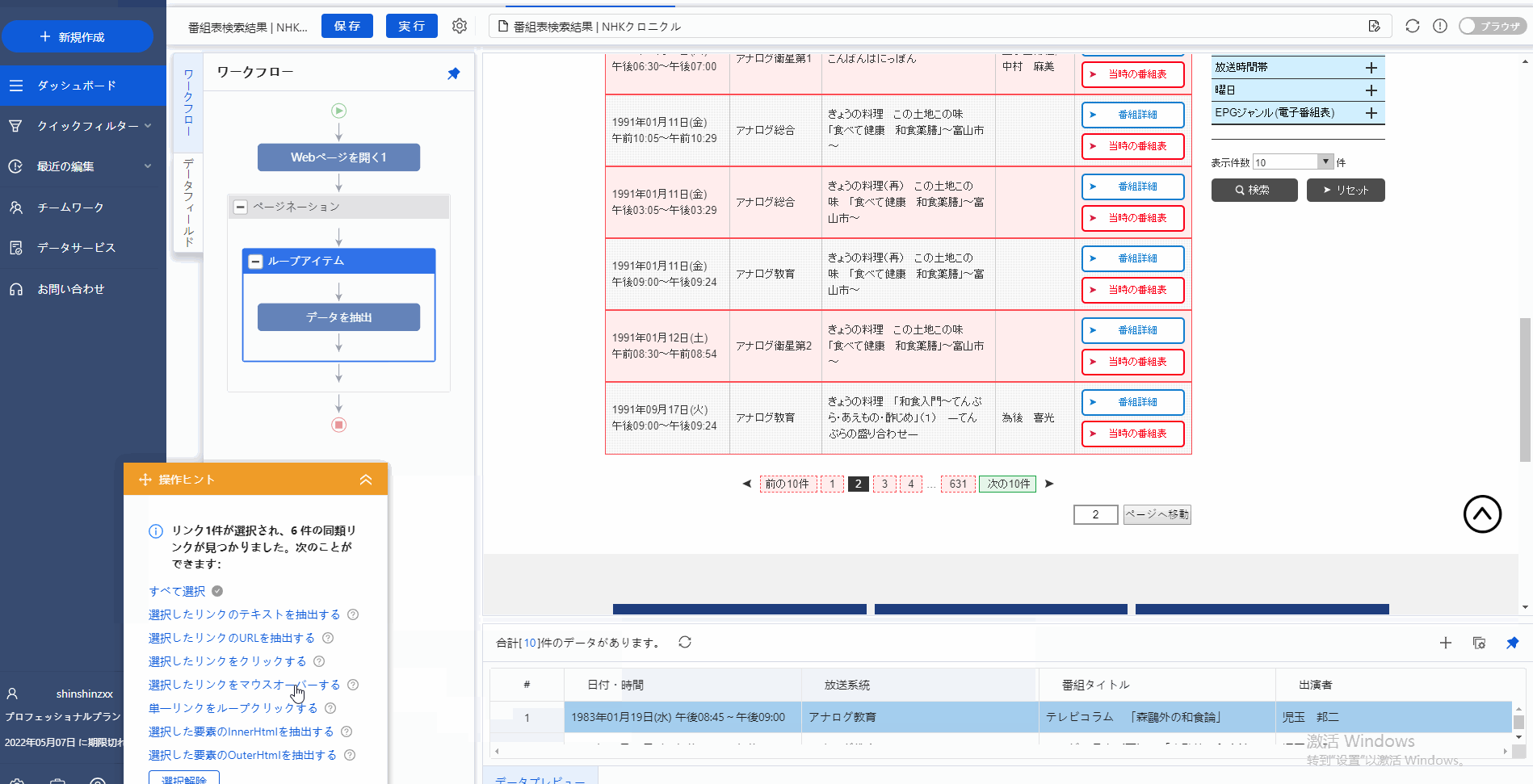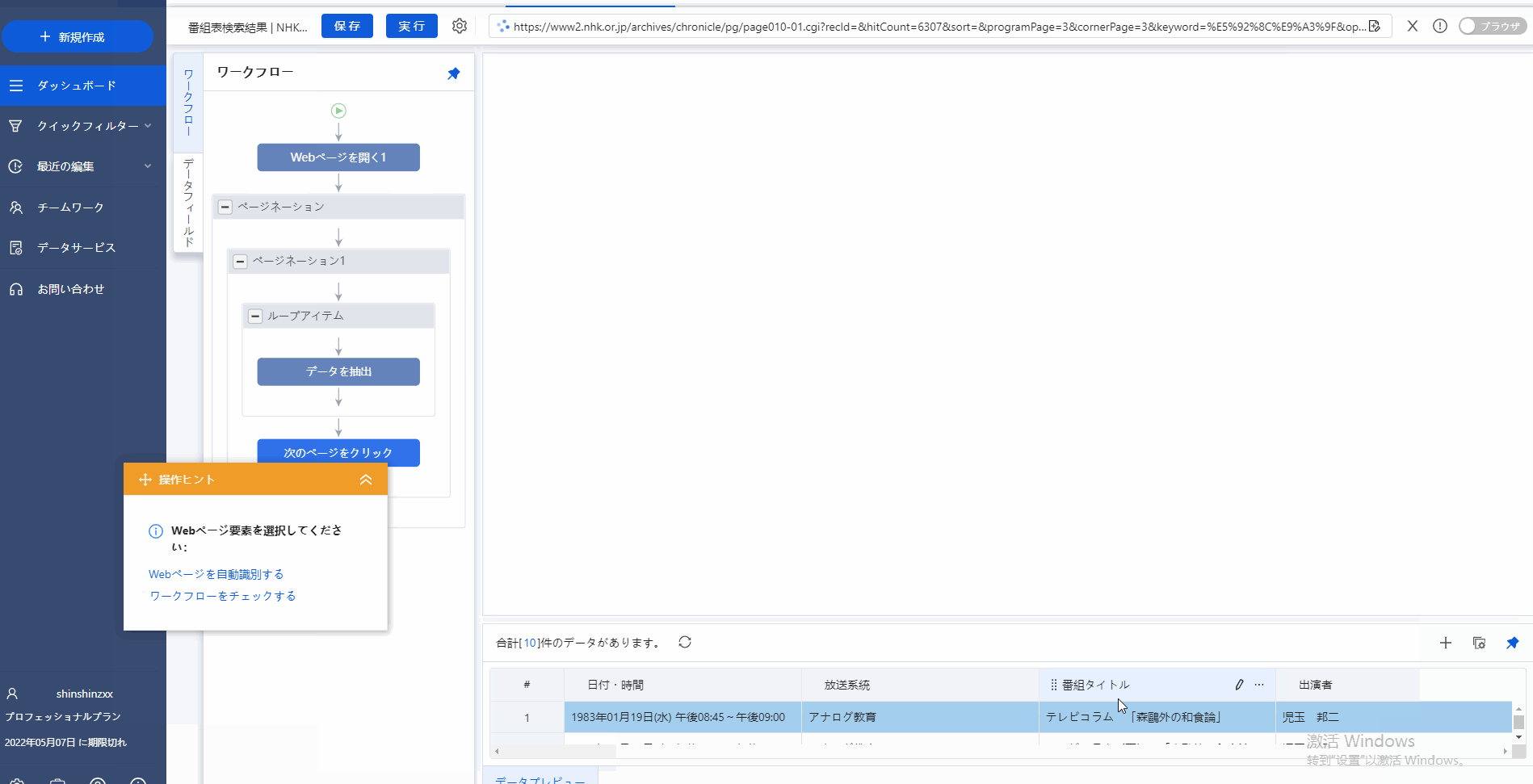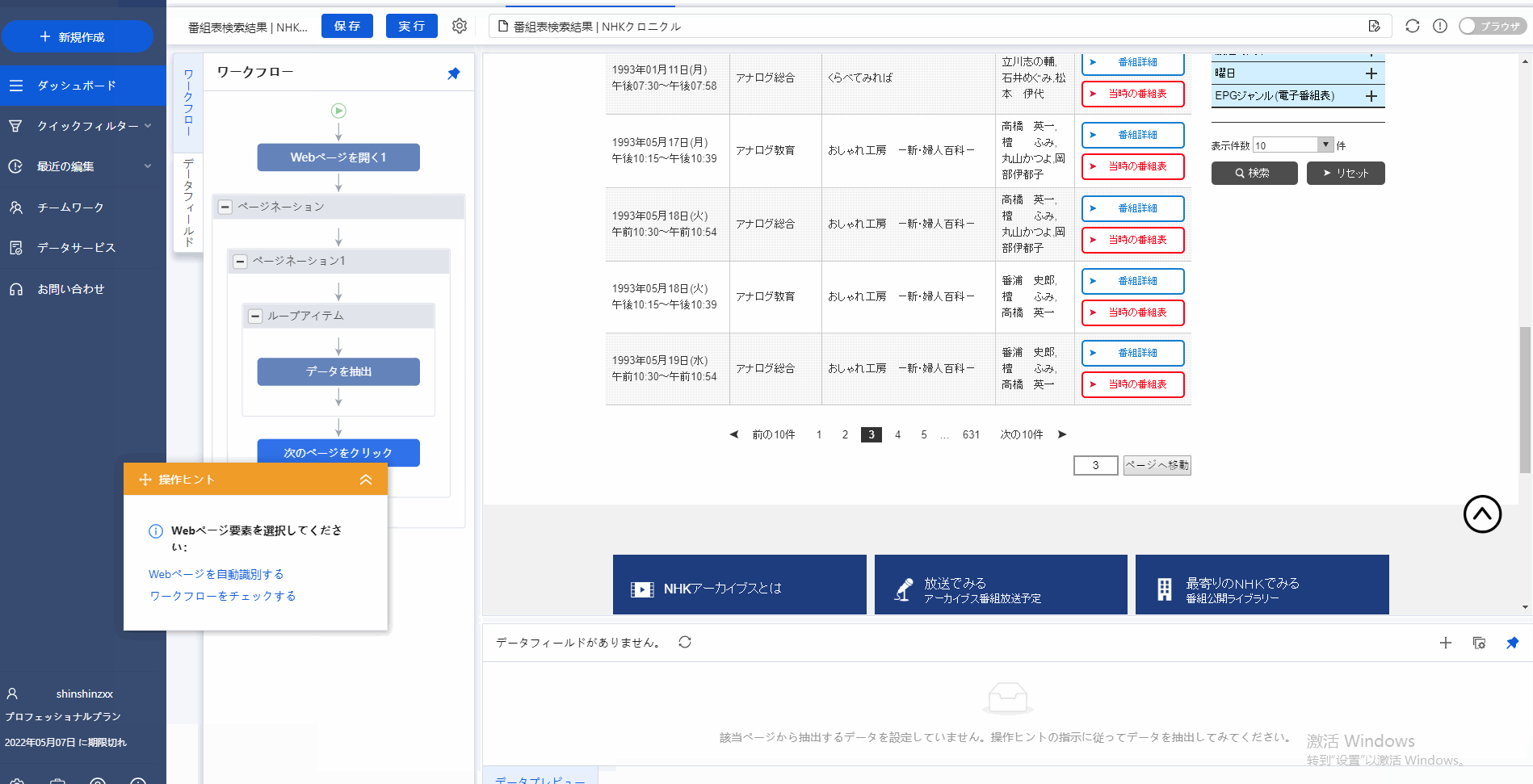
図のように、ページのところに「次の10件」をクリックし、そして、「操作ピント」で「単一リンクをループクリックする」をクリックし、次のページへの動作を設定しました。つまり、すべてのページでのデータを第一ページのようにデータを抽出する動作を自動に行います。
ステップ4:
ステップ3のようにデータの自動抽出を設定完了してから、左上のところに、青い「保存」ボダンをクリックし、そして「実行」をします。

全てのデータを抽出するまで、しばらくお待ちください。


3分40秒を経ってから、全てのデータを抽出しました。「和食」に関する映像のデータは500件があることを分かりました。
そして、右下のところに「データをエクスポート」をクリックし、「Excel」を選択し確認し、octoparseで抽出されたデータを自動的にExcelにエクスポートします。
3.まとめ:
NHKアーカイブWebサイトで映像情報を収集しようとする場合は、一般的にこういう流れがあります。
OctopaseでULRを開き→欲しいデータをクリック→「操作ピント」で「すべて選択」をクリック→「操作ピント」で「データ抽出」→ページのところに「次の10件」をクリック→「操作ピント」で「単一リンクをループクリックする」→左上の青いボタン「保存」と「実行」をクリック→データをエクスポート→Excle+「はい」
このような流れに従って、データを抽出しました。
この方法は操作の流れはNHKだけ使えるのではなく、たくさんのWebサイトでも使えます。もし興味があれば、他のWebサイトのULRをOctopaseで入力し、データの抽出をやってみましょう!
関連記事:
画像を一括ダウンロードするのに超便利なツール5選
すぐ出来る!データ収集をTwitterから学ぼう
【2021年最新版】学術研究にオススメのツールとリソース30選
Discussion