Python vs Octoparse!初心者向けのYelpスクレイピング方法はどっち?




(転載)
元記事:https://www.octoparse.jp/blog/intro-to-yelp-web-scraping-using-python/
私は大学の時にプログラミングの専攻ではありませんでしたが、2019年以来、私自身の仕事を成功させるために、独学でコーディングを学びました。大変苦労していました。
いま私はIT関連の開発の仕事をしています。学んだ知識や技術はすぐに応用できるために、プログラミングを勉強しました。この前、Webスクレイピングを学んで、夢中になってきました。なぜ私が、スクレイピングがこんなに好きになったのか。その理由は、二つあります。まずスクレイピングっていう技術は非常に実用的で、色々な分野に役立ちます。たとえば、仕事効率化、EC業界の価格監視やネット上での世論調査、マーケティングの意思決定などです。二つ目は将来性がある技術だからです。人工知能や5G技術の発展に伴い、スクレイピングなどのデータを収集する技術は益々重要な役割を果していくだろう。
Webスクレイピングというのは、Webサイトから必要な情報を抽出し、それらを読みやすい形式に転換することができます。データに関心を持っている人は、Webスクレイピングに魅力を感じることができると思います。幸いなことに、今ではコーディングせずにWebデータを自動的に抽出する無料のWebスクレイピングツールがあります。
Webコンテンツの構造は非常に複雑です。複数のWebサイトからデータを抽出することさることながら、仮に一つのWebサイトからデータを抽出ことも大変な作業で、多くの時間と労力を費やさなければならないのです。しかし、誰でも容易に一括的にデータを抽出する方法があります。それは、スクレイピングツールを利用して、Web上のデータを自動的に抽出することです。
スクレイピングツールと似ているPythonもWeb上のデータを自動的に抽出できますが、コードを書くことが必要があります。これから、pythonとWebスクレイピングツール、その二つのことについて説明させていただきます。
では、始めましょう。
1、PythonによるWebスクレイピング
プロジェクト:
Webサイト:Yelp.com
スクレイピング項目:役職、評価、レビュー数、電話番号、価格帯、アドレス
目標サイトのURL: https://github.com/whateversky/yelp
事前準備:
Python 3.7
Pycharm —コーディングエラーをチェックし修正するツール
Bejson —JSON構造形式のクリーニング
2、データを抽出するプロセス
まず、スパイダーを作成して、Yelpからデータを実行および抽出する方法を設定します。つまり、GETリクエストを送信してから、指示に従って、設定することによって、スクレーパーがWebサイトを読み込みます。
次に、Webページのコンテンツをパソコンが解析し、抽出されたデータをデータ集合ベースに戻します。スパイダーにItemオブジェクトまたはRequestedオブジェクトを返すことを指示されます。
最後に、スパイダーから抽出されたデータを変換します。
データを抽出する前に、Web構造を理解しなければなりません。コーディングをする時に、常にdivとclassからWebページをチェックしなければいけません。Webサイトを検査する時に、お気に入りのブラウザに移動して右クリックします。 「検査」を選択し、ネットワークの下にある「XHR」タブがあります。店舗名、電話番号、場所、評価など、対応するリスティング情報が表示されます。 「PaginationInfo」を展開すると、各ページに30のリストがあり、合計で6932のリストがあることがわかります。
①クローラー:
まず、Pycharmを開いて新しいプロジェクトを設定します。次に、Pythonファイルを設定し、「yelp_spider」という名前を付けます。

②ページを開き:
get_pageメソッドを作成します。これにより、すべてのリストWeb URLを含むクエリ引数が渡され、ページJSONが返されます。また、スクレーパーの検出を避けるために、Webサーバーをスプーフィングするユーザーエージェント文字列を追加しました。
.format引数を追加して、URLをフォーマットし、エンドポイントがパターンに従うようにします。この場合は「ニューヨーク市のバー」の全ての検索結果が出てきます。
def get_page(self、start_number):
url =“ https://www.yelp.com/search/snippet?find_desc=bars&find_loc=New York%2C NY%2C United States&start={}&parent_request_id=dfcaae5fb7b44685&request_origin=user” \ .format(start_number)
③詳細の取得:
リストページへのURLの収集を成功しました。これで、get_detailメソッドを使用してスクレーパーにそれぞれの詳細ページにアクセスすることを指示します。
詳細ページのURLは、ドメイン名とビジネスを示すパスで構成されます。

すでにURLのリストを収集したので、https://www.yelp.com に追加されたパスを含むURLパターンを簡単に定義できます。このようにして、詳細ページのURLのリストに返されます。
def get_detail(self、url_suffix):url =“ https://www.yelp.com/”+パス
次に、スクレーパーをより人間味あるものにするために、ヘッダーを追加する必要があります。
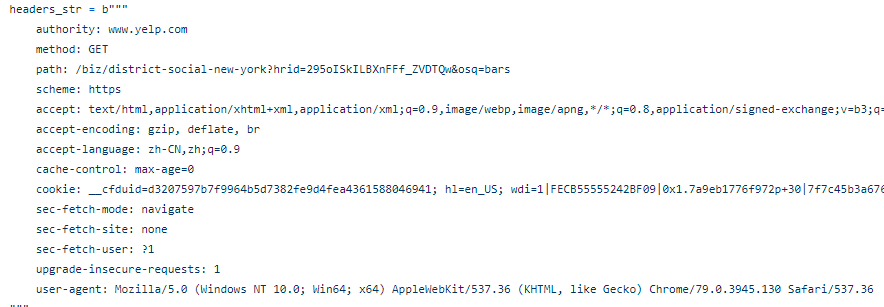
④ヘッダーを追加する
次に、タグを見つけるために、IFステートメントとFORループの組み合わせを作成しました。タグは主に、会社名、評価、レビュー、電話などを含めています。

⑤ループを作成する
JSONに返すリストページと異なり、詳細ページは通常HTMLで答えます。したがって、解析にきれいに見えるように、句読点と余分なスペースを取り除きました。
⑥解析:
これらのページに1つずつアクセスするときに、スパイダーを指示することによって、ページを解析して詳細情報を取得できます。
まず、同じフォルダの下に「yelp_parse.py」という2番目のファイルを作成します。そして、インポートを開始し、YelpSpiderを実行します。
複数のページに30のリストがあるため、ここでページネーションループを追加します。 この場合は「start_number」というオフセット値は「0」にしてください。クロールが完了すると、数が30に増えます。
Get first 30 listings
Paginate
Get 31-60 listings
Paginate
Get 61-90 listings….

最後に、キーと値を、会社名、評価、電話番号、価格帯、住所などのそれぞれのデータ属性とペアにする辞書を作成します。
3、Webスクレイピング:
Pythonを使用すると、Webサーバー、ポータル、およびソースコードと直接対話できます。この方法は効果的ですが、プログラミング知識が不可欠です。Webサイトは非常に用途が広いので、スクレーパーを絶えず編集し、変更に適応する必要があります。 SeleniumとPuppeteerも同様です。でも、Pythonに比べると、大規模なデータの抽出には制限はあります。
Pythonに対して、もう一つのデータ抽出方法があります。それはWebスクレイピングツールです。ここにOctoparseを取り上げましょう。
Octoparseの最新バージョンOP8.1は、Webページが読み込まれたときにデータ属性を検出するアルゴリズムを備えています。Octoparseは自動的にWebページを巡回し、会社名、連絡先情報、レビューなどのさまざまなデータを読み込めます。

yelpを例として取り上げましょう。 Webページが読み込まれると、Web要素が自動的に解析され、データ属性が自動的に読めます。検出プロセスが完了してから、プレビューのところにOctoparseが抽出したすべてのデータが表示されます。そして、ワークフローが自動的に作成されます。ワークフローはスクレイピングロードマップのようなものであり、スクレイパーはこの指示に従ってデータを抽出します。
Pythonでもデータの抽出が出来ますが、Octoparseのような見えるプロセンスのワークフロー機能がありません。プログラミングはより抽象的なものであり、この分野の専門知識がなければ、データ抽出の作業ができません。
しかし、Octoparseはそれだけではありません。詳細ページから情報を取得しようと思ったら、橙色の「操作ヒント」のガイドに従って操作してください。

次に、詳細ページに移動できるtitle_urlを選択します。

コマンドを確認すると、新しいステップがワークフローに自動的に追加されます。次に、ブラウザに詳細ページが表示され、ページ内の抽出したいデータをクリックするだけでデータを抽出できます。たとえば、タイトル「ARDYN」をクリックすると、「操作ヒント」ガイドに一連のアクションが表示され、そこから選択できます。 「選択した要素のテキストを抽出する」をクリックして、ワークフローにアクションが追加されます。同様に、上記の手順を繰り返して、「評価」、「レビュー数」、「電話番号」、「価格帯」、「住所」などのデータを抽出できます。

(yelpのビジネス情報をこすります)
ガイドに従い、アクションを設定します
すべての設定が完了したら、スクレイピングを実行します。

4、終わりに:
PythonとWebスクレイピングツールはどちらでもデータを抽出できます。ただ、pythonの方がデータを抽出する前に必要なプログラミング専門知識は欠かせません。でも、スクレイピングツールの方が、誰でも簡単に使えることができます。プログラミング知識のない方にも、入手したいデータがあったら、Octoparseでクリックするだけで簡単にデータを抽出することができます。ぜひ、お勧めます!
関連記事:
Webサイトから画像を一括ダウンロードする方法
注目のWebスクレイピングツール5選を徹底比較!
PythonによるWebスクレイピングを解説
Twitterからツイートをスクレイピングする
Discussion