Open1
サーバーレスのワークフローサービス(Google Cloud Workflows)でスロットリングを実現する
概要
- バックエンドアプリケーションからWorkflowsをトリガーし、そのWorkflowsからCloud Run Jobsを実行するとします。(例としてRailsをバックエンドアプリケーションに使用しています。)
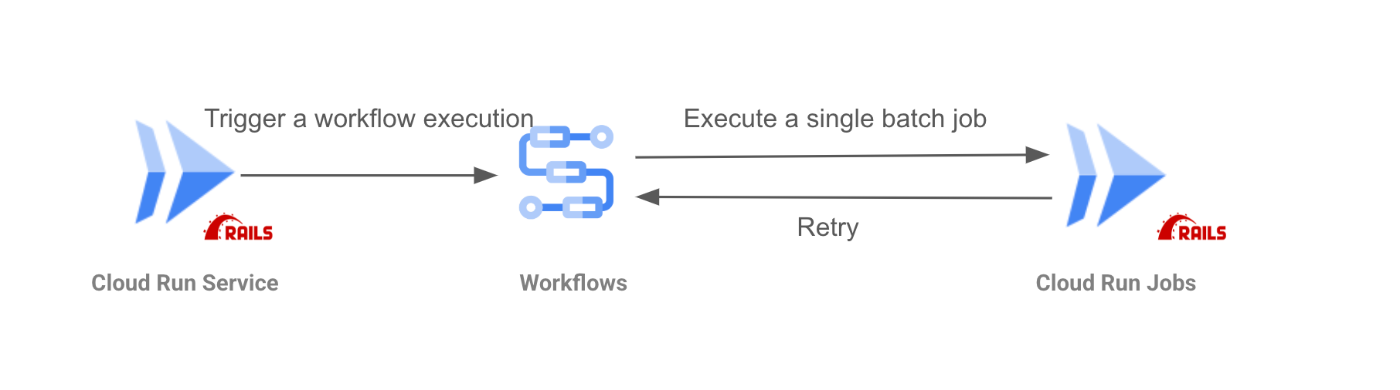
- 上記の状態からスロットリングを導入する場合の実現方法を考えます。
前提
- Google Cloud Workflowsを使うものとする。
- おそらく、AWSだとAWS Step Functions、AzureだとAzure Logic Appsに置き換えて使えると思います。
- DBはMySQLを使うものとします。DBにスロットリングの情報を保存するものとします。また、以下のテーブルを用いるものとします。
- workflows_locksテーブル(各Workflowsの実行単位の情報を保存する)
- ttl
- スロットのTTL
- status
- 該当レコードのスロットが空いている(OFF) or 該当レコードのスロットが空いていない(ON)
- excution_id
- Workflowsの実行ID
- jobs_type
- ジョブの種類(e.g. あるテーブルの一括削除のジョブ)
- workflows_callback_urlsテーブル(
events.create_callback_endpointで作成したURL)- url
- callbackのURL
- workflows_type
- status
- active/inactive
- url
- workflows_locksテーブル(各Workflowsの実行単位の情報を保存する)
- バックエンドアプリケーションからGoogle Cloud Workflowsの実行をトリガーするとします。
- また、バックエンドアプリケーションはモノリスなサービスであるとします。
-
POST /check_concurrencyで同時実行数をバックエンドアプリケーションに問い合わせられます。 -
PUT /locksでは以下の処理を同一トランザクションで行うものとします。- リクエストボディに渡したexcution_idに該当するworkflows_locksのstatusをOFFにUPDATEする。
- 作成日が一番古い
workflows_callback_urlsのレコードを一件取得してきて、workflows_callback_urls.urlにHTTPリクエストする。- この時、競合しないように該当行に対して、DB側で排他ロックをとる。
- 上記
workflows_callback_urlsのレコードのstatusカラムをinactiveにUPDATEする。
比較対象
- ttlまで待つアルゴリズム
- ポーリング