Vertex AI Gemini API のチャットをCloud Runで動かす
はじめに
この記事では Vertex AI Gemini API をバックエンドとしたチャットインターフェースをGradioを用い作成する流れを紹介します。
ローカル環境でコードを作成し動作確認をして、最後は Cloud Run にデプロイしたいと思います。
こちらはQiitaに掲載した記事のリバイス版になります。
Vertex AI Gemini API
Google Cloud を利用していれば Vertex AI からも Gemini API を利用できます。2024年9月24日、Google社は生成AIの最新バージョンGemini 1.5シリーズの更新版であるGemini-1.5-Pro-002とGemini-1.5-Flash-002をリリースしたことを発表しました。
Gemini 1.5 Proでは200万トークンのコンテキストウィンドウを持ち、大規模な入力に対応しています。合わせて利用料の値下げ、レイテンシやレート制限の改良も発表されました。
大きなコンテキストウィンドウと低価格を活かして、入力にクローズドな情報を載せるプロンプトエンジニアリングにより、独自の情報源に基づいたレスポンス作成といった活用方法も期待できます。
Gradio とは
Pythonで機械学習やAIアプリ向けのインターフェイスを簡単に作れるOSSです。今回はChatInterface を利用して入力応答画面を作成します。
チャットアプリケーションの作成
画面からTemperatureなどのgeneration_configを変更できるようなインターフェイスを備え、またモデルをGemini-1.5-Pro-002とGemini-1.5-Flash-002から選択できるようにしたチャット画面を作成します。また、応答のストリーミング表示にも対応したものとします。
環境に必要なライブラリをインストール
Google Cloud の Cloud shell には開発ツールがインストールされており、開発と動作確認まで行うことができます。ローカルのPython開発環境を用いても大丈夫です。
Cloud shellを使う場合は右上のTerminalアイコンをクリックしてCloud shellを起動してください。

以下のコマンドを実行してライブラリをインストールします。
pip3 install gradio
pip3 install -u google-cloud-aiplatform
Vertex AIの初期化
関連ライブラリのインポートとVertex AIの初期化を行います。
import os
import gradio as gr
import vertexai
from vertexai.generative_models import GenerativeModel, Content, Part
# 環境変数の設定
PROJECT_ID = os.environ.get('PROJECT_ID')
LOCATION = os.environ.get('LOCATION', 'asia-northeast1')
# Vertex AI API の初期化
vertexai.init(project=PROJECT_ID, location=LOCATION)
Gemini モデルとのチャットを行う
Gemini モデルとのチャットを行う関数とGradioから呼び出されチャットの応答をストリーミングする関数を用意します。
Gradio側からは message, history と追加で定義した additional_inputs が関数に渡されます。
会話履歴を含めてチャットを行うことでLLMが過去の会話内容に沿った回答を行えるようになります。
# Gemini モデルとのチャットを行う関数
def get_chat_response(model, message, history):
# 会話履歴リストを初期化
chat_history = []
# 会話履歴のフォーマットを整形
for row in history:
input_from_user = row[0]
output_from_model = row[1]
chat_history.append(Content(role="user", parts=[Part.from_text(input_from_user)]))
chat_history.append(Content(role="model", parts=[Part.from_text(output_from_model)]))
# Gemini モデルに会話履歴をインプット
chat = model.start_chat(history=chat_history)
# Gemini モデルにプロンプトリクエストを送信
try:
responses = chat.send_message(message ,stream=True)
for response in responses:
yield response.text
except Exception as e:
print(f"Error: {e}")
yield ""
# チャットの応答をストリーミングする関数
def stream_response(message, history, temperature, top_p, top_k, max_output_token, model_name):
# Note: デバッグ用に設定値を確認
print([temperature, top_p, top_k, max_output_token, model_name])
if message is not None:
# Gemini モデルの初期化
generation_config = {
"temperature": temperature, # 生成するテキストのランダム性を制御
"top_p": top_p, # 生成に使用するトークンの累積確率を制御
"top_k": top_k, # 生成に使用するトップkトークンを制御
"max_output_tokens": max_output_token, # 最大出力トークン数を指定
}
model = GenerativeModel(
model_name=model_name,
generation_config=generation_config
)
partial_message = ""
for response in get_chat_response(model, message, history):
partial_message += response
yield partial_message
yieldを用いているのはレスポンスを順次出力するストリーミング対応のためです。
Gradioを起動
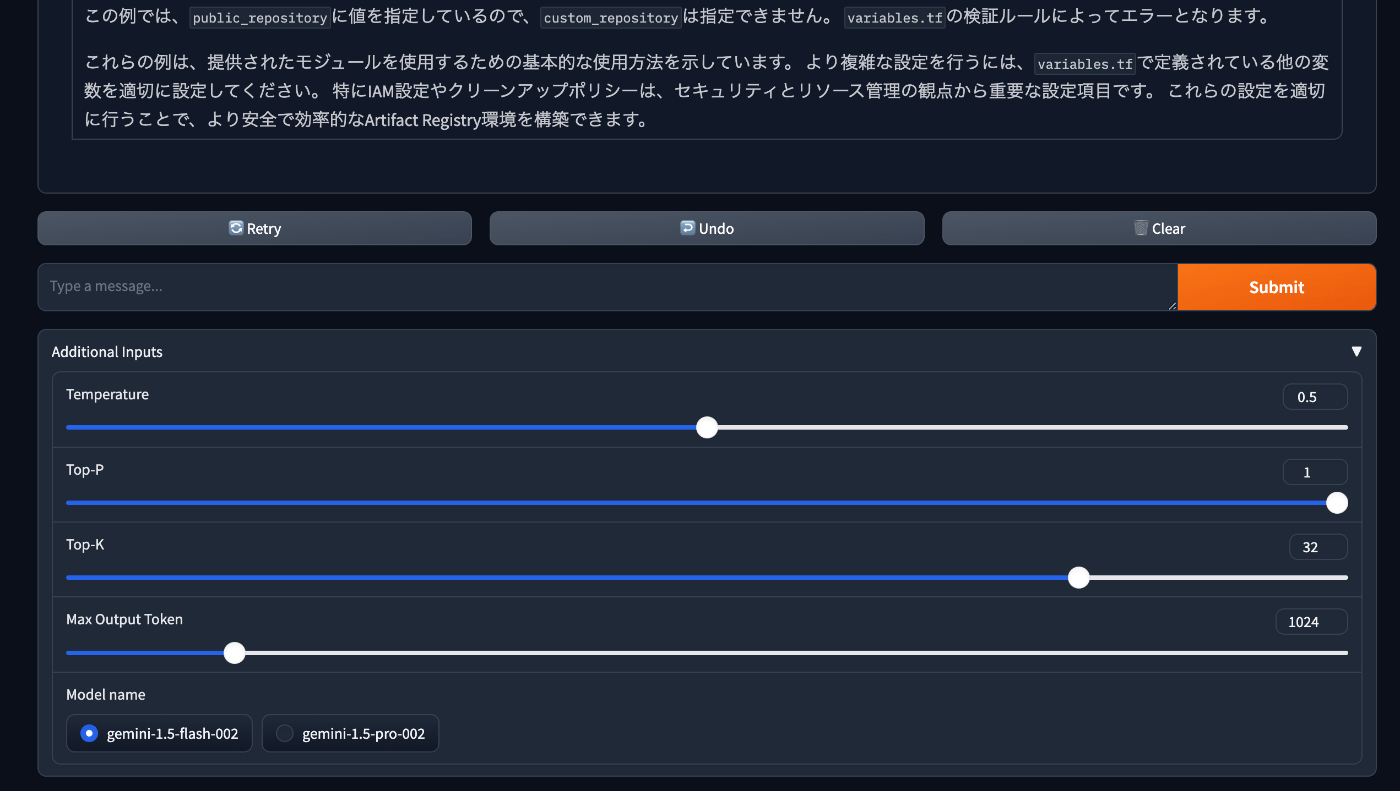
additional_inputs として Gradio のUIパーツを定義しています。UI上にスライダーやラジオボタンを追加してGeneration Configを調整することができます。
Gemini-1.5-Pro-002とGemini-1.5-Flash-002がリリースされたので、モデルはこの2つから選べるようにしました。
if __name__ == "__main__":
# UI に Generation Config を調整するためのリスト
additional_inputs = [
gr.Slider(label="Temperature", minimum=0, maximum=1, step=0.1, value=0.5, interactive=True),
gr.Slider(label="Top-P", minimum=0.1, maximum=1, step=0.1, value=1, interactive=True),
gr.Slider(label="Top-K", minimum=1, maximum=40, step=1, value=32, interactive=True),
gr.Slider(label="Max Output Token", minimum=1, maximum=8192, step=1, value=1024, interactive=True),
gr.Radio(["gemini-1.5-flash-002", "gemini-1.5-pro-002"], value="gemini-1.5-flash-002" ,label="Model name")
]
css = """
.contain { display: flex; flex-direction: column; }
#component-0 { height: 100%; }
#chatbot { flex-grow: 1; }
"""
# チャットインターフェースを作成
with gr.Blocks(css=css) as app:
chatbot = gr.Chatbot(elem_id="chatbot")
gr.ChatInterface(
fn=stream_response,
chatbot=chatbot,
additional_inputs=additional_inputs,
)
app.queue()
app.launch()
チャットアプリケーションの動作確認
環境変数を指定してチャットアプリケーションを起動します。
CloudShell の Web Preview 機能を利用するため、GRADIO_SERVER_PORT を指定して8080番ポートで起動するようにします。PROJECT_ID は自信のプロジェクトIDを指定して下さい。LOCATION は記事執筆時点では gemini-1.5-flash-002 が 東京リージョンでは利用出来なかったので us-central1 を指定しておきます。
GRADIO_SERVER_PORT=8080 PROJECT_ID=<your-project-id> LOCATION=us-central1 python3 chatbot.py
ローカルの場合は 127.0.0.1:8080 を、CloudShell を利用している場合は右上の Web Preview → Preview on port 8080 をクリックして下さい。

チャットの入力画面が出たら好きな内容を入力して Submit すると Gemini モデルからの応答が確認できます。
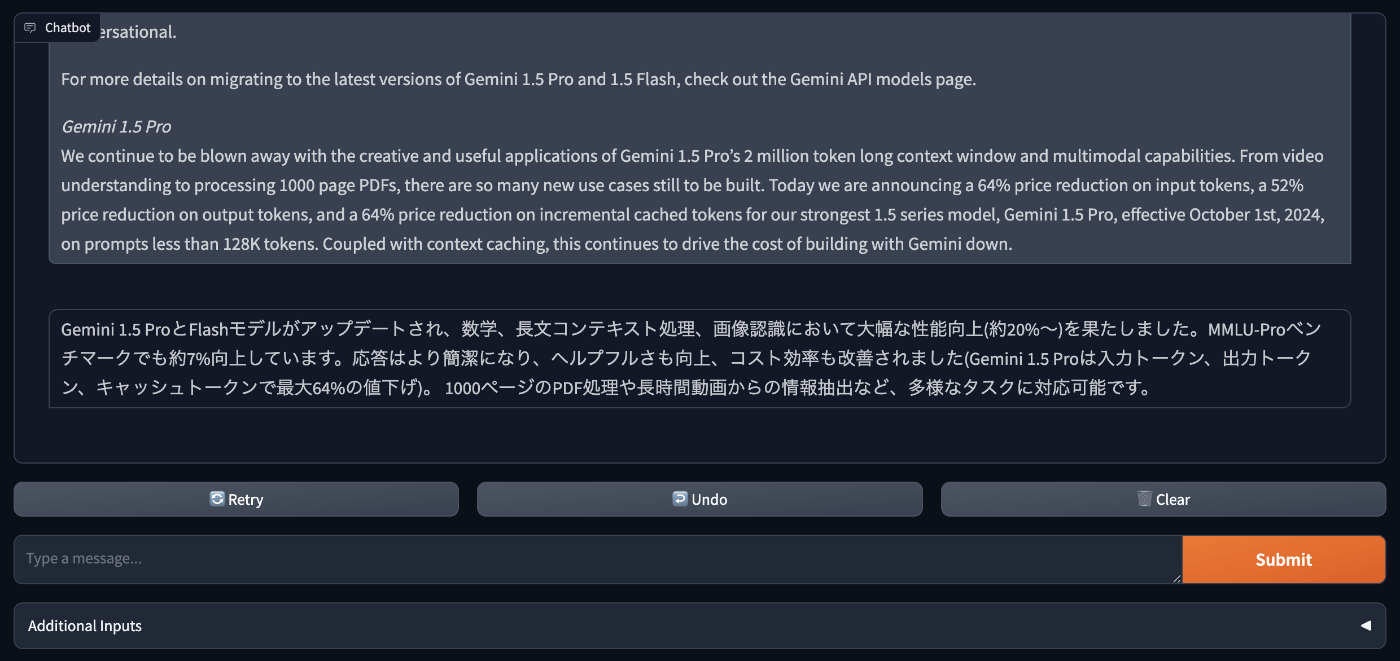
gemini-1.5-flash-002 は体感でも以前より応答速度が向上しており、かなり早く応答が返ってきました。
Additional Inputs の部分を展開すると、TemperatureやModelを変更してチャットを試すことができます。
アプリケーションを止めるには Ctrl+c を送信してください。
アプリを Cloud Run にデプロイしてみる
作ったアプリを好きな時に利用できるように Cloud Run にデプロイしてみます。
コンテナイメージ作成
Dockerfile と requirements.txt を chatbot.py と同じディレクトリに作成します。
FROM python:3.12-slim
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
COPY chatbot.py chatbot.py
ENV GRADIO_SERVER_NAME=0.0.0.0 \
GRADIO_SERVER_PORT=8080
CMD [ "python3", "chatbot.py"]
gradio==4.44.0
google-cloud-aiplatform
資材があるディレクトリでイメージを作成します。
docker build -t chatbot .
作成したイメージの動作確認をします。
CloudShell 上であれば以下でコンテナを起動して、先ほどと同様に Web Preview で確認できます。ローカル環境の場合は Google Cloud の Application Default Credentials をコンテナに渡すための追加引数が必要になります。
docker run -it --rm -p 8080:8080 -e PROJECT_ID=<your-project-id> -e LOCATION=us-central1 chatbot
Artifact Registry 作成
コンテナイメージを格納する Artifact Registry を作成します。
以下は repo という名前のリポジトリを作成する例です。
gcloud artifacts repositories create repo \
--repository-format=docker \
--location=asia-northeast1 \
--project=<your-project-id>
Console で Artifact Registry のページを開き、作成したレポジトリを開くとイメージレジストリのパスを確認できます。
作成したイメージにtagを付与します。
docker tag chatbot asia-northeast1-docker.pkg.dev/<your-project-id>/repo/chatbot
作ったイメージを Artifact Registry に Push します。
docker push asia-northeast1-docker.pkg.dev/<your-project-id>/repo/chatbot
Cloud Run のサービス作成
Console で Cloud Runを開き、サービスをデプロイします。

以下を設定して「作成」をクリックします。
- コンテナイメージのURL: Artifact RegistryにPushしたイメージを選択
- サービス名: 好きな名称を入力
- 認証: 未認証の呼び出しを許可 を選択 (インターネット上に公開された状態になるのでご注意ください)
- 環境変数: PROHECT_ID と LOCATION を指定

- インスタンスの最大数: 初期値が大きいので適宜小さい値に変更(動作確認であれば1で十分)
Cloud Runが作成されたら上部の URL からアプリケーションにアクセスできます。
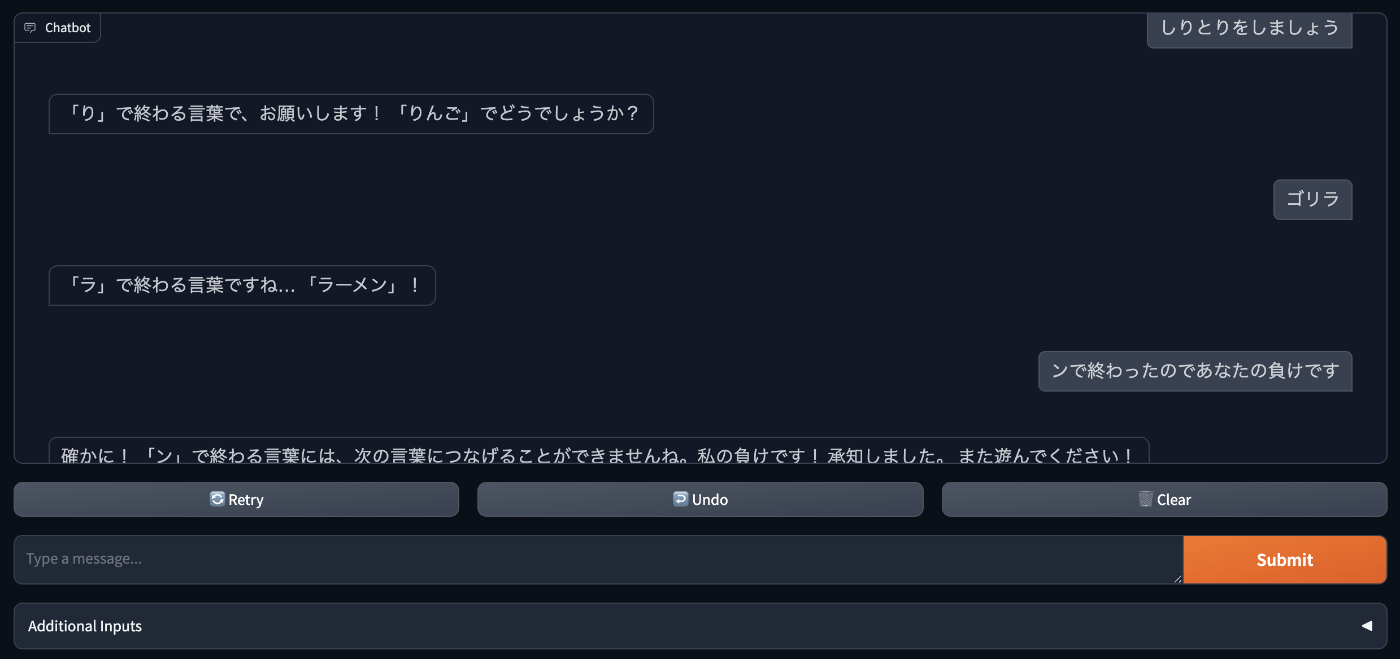
(過去文脈を理解しているかの確認のためにしりとりをしてみたのですが、激弱でした)
まとめ
最後までご覧いただきありがとうございます。
今回はGemini 1.5シリーズの更新版をモデルにした生成AIのチャットインターフェースを作成しました。Gradio を用いることで短いコードでインターフェイスが実現できました。
Function Calling や RAG(retrieval-augmented generation) などを組み合わせれば、より幅広いタスクに対応できるようになります。Function Callingについては別の記事を記載したので、よろしければこちらもご覧ください。
Discussion