Stable Diffusion 2.0 Release日本語参考訳
Stable Diffusion 2.0 Release日本語参考訳
2022年11月24日にStable Diffusion 2.0が Stability.AI社よりリリースされましたので、日本語参考訳を起こしておきました。
まずは原文に忠実に訳したところに続き、最後にまとめと訳注を加えておきました。DeePL訳だと見落としそうな情報が含まれているので、注意して読んでください。

この度、Stable Diffusion Version 2のオープンソースリリースを発表できることを嬉しく思います。
CompVisが開発したオリジナルのStable Diffusion V1は、オープンソースのAIモデルの性質を変え、世界中で何百もの他のモデルやイノベーションを生み出しました。Githubの10,000スターに最も早く到達したソフトウェアの1つであり、また、2ヶ月足らずで33,000スターを獲得しています。

Source: A16z and Github
Björn Ommer教授が率いるLMU MunichのCompVisグループのRobin Rombach (Stability AI) と Patrick Esser (Runway ML) のダイナミックなチームは、オリジナルのStable Diffusion V1リリースをリードしてきました。彼らは、LAIONとEleuther AIから重要なサポートを得て、Latent Diffusion Modelsの研究室の以前の成果をもとに構築しました。Stable Diffusion V1のリリースについては、以前のブログ記事で詳しくご紹介しています。現在、RobinはStability AIのKatherine Crowsonと共に、私たちの幅広いチームと共に次世代のメディアモデルを作成するための努力をリードしています。
Stable Diffusion 2.0では、オリジナルのV1リリースと比較して、多くの大きな改善と機能が提供されていますので、さっそく見てみましょう。

新しい Text-to-Image 拡散モデル
Stable Diffusion 2.0リリースでは、Stability AI社のサポートのもとLAION社が開発した全く新しいテキストエンコーダー「OpenCLIP」を使用して学習させた堅牢なText-to-Imageモデルを搭載し、以前のV1リリースと比較して生成画像の品質を大幅に向上させることに成功しました。このリリースに含まれるテキスト画像生成モデルは、512x512ピクセルと768x768ピクセルの両方のデフォルト解像度の画像を生成することができます。
これらのモデルは、Stability AIのDeepFloydチームが作成したLAION-5Bデータセットの美的サブセットで学習され、さらにLAIONのNSFWフィルターを使用してアダルトコンテンツを除去しています。

Stable Diffusion 2.0を使用して作成した画像の例(画像解像度768x768)
超解像度アップスケーリング拡散モデル
Stable Diffusion 2.0には、画像の解像度を4倍に向上させるアップスケーラー拡散モデルが含まれています。以下は、低解像度の生成画像(128x128)を高解像度画像(512x512)にアップスケーリングしたモデル例です。Stable Diffusion 2.0は、テキストから画像への変換モデルと組み合わせることで、2048x2048またはそれ以上の解像度の画像を生成することができます。

左:128x128の低解像度画像。右:Upscalerによって生成された512x512の解像度の画像
Depth-to-Image (深度から画像へ)の拡散モデル
Depth2imgと呼ばれる新しい深度誘導型安定拡散モデルは、V1からの従来の画像間の機能を拡張し、創造的なアプリケーションのための全く新しい可能性を持っています。Depth2imgは、入力画像の深度を推定し(既存のモデルを使用)、テキストと深度情報の両方を使用して新しい画像を生成します。

左側の入力画像から、複数の新しい画像(右側)を生成することができる。この新しいモデルは、構造を保存した画像間合成や形状条件付き画像合成に用いることができる
Depth-to-Imageは、オリジナルとは全く異なる印象を与えながらも、その画像の一貫性と深みを維持した変換を実現することで、様々な新しいクリエイティブなアプリケーションを提供することができます。
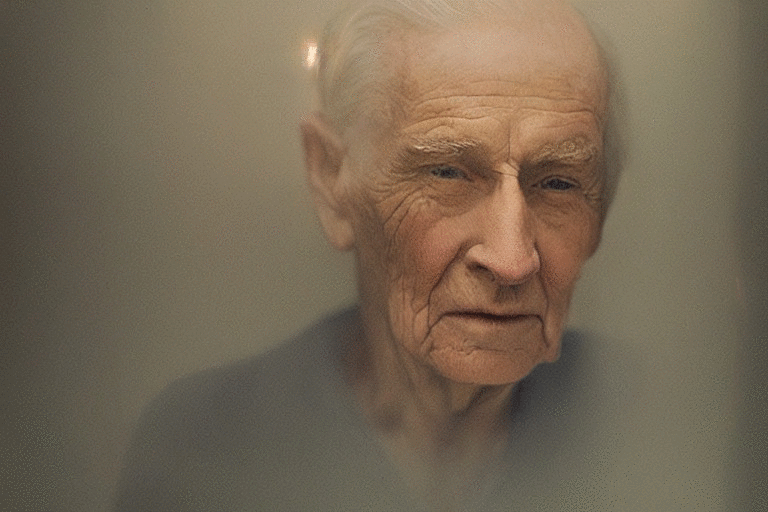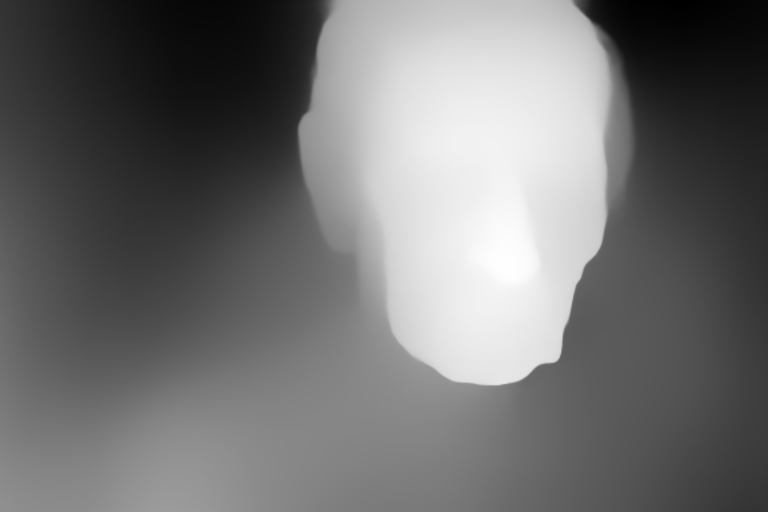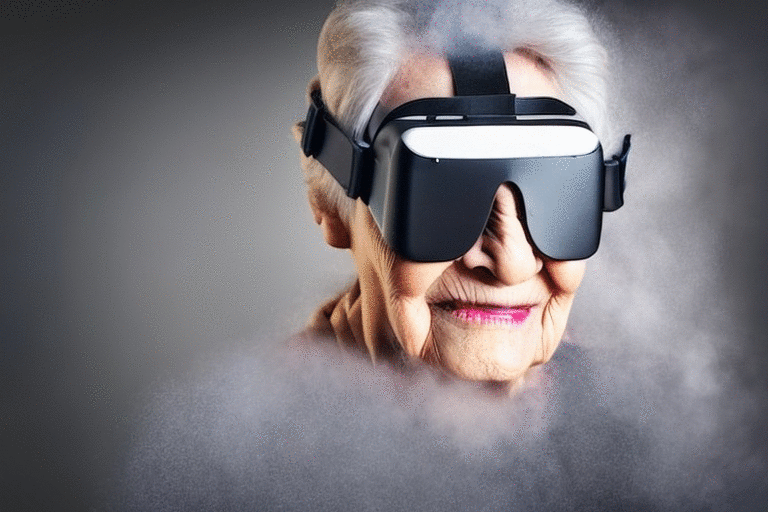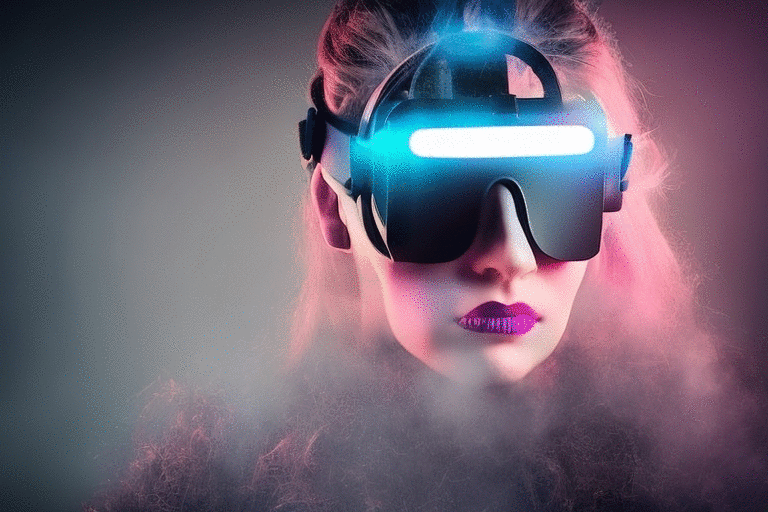
Depth-to-Imageは、コヒーレンスを維持します
訳注:コヒーレンス(coherence)とは物理用語で「可干渉性」、互いに干渉する波の性質のこと。波の場合は波形(位相)が揃っていると干渉しやすい。Stable Diffusion内部で波動を扱っているとはいいがたいので、おそらく「画像の位相(phase)が揃っている」、という意味で理解してよいのでは。
更新されたインペイントの拡散モデル
また、新しい安定した拡散2.0ベースのテキストから画像に微調整された新しいテキストガイドインペイントモデルが含まれており、画像の一部をインテリジェントかつ迅速に切り替えることが非常に簡単にできます。

Stable Diffusion 2.0のテキストから画像への変換モデルをベースに微調整された、最新のインペイントモデル
Stable Diffusionの最初のイテレーションと同様、私たちはこのモデルをシングルGPUで動作するように最適化することに尽力しました。私たちはすでに、何百万人もの人々がこれらのモデルを手にすることで、本当に素晴らしいものが生み出されることを目の当たりにしています。これこそオープンソースの力です。最先端のモデルを訓練するためのリソースはなくても、そのモデルを使って何か素晴らしいことをする能力を持つ、何百万人もの才能ある人々の膨大な潜在能力を利用することができるのです。
この新しいリリースは、depth2imgや高解像度アップスケーリング機能などの強力な新機能とともに、無数のアプリケーションの基礎として機能し、新しい創造の可能性を爆発的に増やすでしょう。

モデルへのアクセスの詳細については、私たちのGitHubにあるリリースノートをご覧ください: https://github.com/Stability-AI/StableDiffusion
私たちは、オープンソースAIへの直接的な貢献として、このリポジトリに積極的なサポートを提供し、みなさんがこのリポジトリで構築する素晴らしいものを楽しみにしています。
我々は、数日以内にこれらのモデルをStability AI API Platform (https://platform.stability.ai/)とDreamStudioにリリースする予定です。これについては、価格の更新を含む、開発者やパートナー向けの情報を発信する予定です。皆様、ぜひこれらのアップデートをお楽しみください。
私たちは、次世代のオープンソースGenerative AIモデルの開発に携わることに興奮する研究者やエンジニアを募集しています! Stability AIへの入社に興味がある方は、履歴書と自己紹介文を添えて、careers@stability.ai までご連絡ください。
訳者まとめ・補足
- LAION社が開発した全く新しいテキストエンコーダー(OpenCLIP)を使用して学習させた
- OpenCLIPを使ったロバストなText-to-Imageモデルで、V1に比べて生成画像の品質が向上
- デフォルト解像度が向上:768x768ピクセル
- 超解像度で2048x2048やそれ以上も可能に
- Depth-to-Image Diffusion Model:奥行き構造を使った画像間合成や形状条件付き画像合成が可能
- In-Paintingの改善:パーツ切り替え
The Stable Diffusion 2.0 release includes robust text-to-image models trained using a brand new text encoder (OpenCLIP), developed by LAION with support from Stability AI, which greatly improves the quality of the generated images compared to earlier V1 releases.
原文に沿って「LAION社が開発した全く新しいテキストエンコーダーOpenCLIP」って翻訳してしまったけど、OpenCLIPはオープンなプロジェクトなのでLAION社やStabilityAI社だけで作ったものではないですね、そして
These models are trained on an aesthetic subset of the LAION-5B dataset created by the DeepFloyd team at Stability AI, which is then further filtered to remove adult content using LAION’s NSFW filter.
これらのモデルは、Stability AI社のDeepFloydチームが作成したLAION-5Bデータセットの美的サブセットで学習され、さらにLAIONのNSFWフィルターを使ってアダルトコンテンツを除去しています。
"新しい"って公式リリース書いているけどLAION-5Bは変わらないな、でもLAION-5Bの貢献は相変わらず大きい…。
リンクしている先
もLAION-5Bに関するものです。
50億の画像-テキストのペアによるデータセット(23.2億の英文テキスト、22.6億の他言語によるテキスト、12.7億の明確に判断できないテキスト)、最近傍(nearest-neighbor)インデックス、データを使用した意味検索(semantic search)、このデータでトレーニングされたCLIPの複製を同梱して、これを広く利用可能にする最新バージョンをリリースすることによって、公開データセットの規模の新標準を狙いながら、世界中の研究者がGLIDEやTuring Bletchleyのような最先端の視覚言語モデルをトレーシングできるようになった。
LAION-5Bについての翻訳解説
公式が引用しているリンク先には特に新しいNSFWフィルターは含まれていないようなので、やっぱりaesthetic環境は変わっていないっぽいな
LARGE SCALE OPENCLIP: L/14, H/14 AND G/14 TRAINED ON LAION-2B
(大規模OPENCLIP: L/14,H/14,G/14がLAION-2Bでトレーニングされました)
投稿者: Romain Beaumont 2022年11月11日
なるほど OpenCLIP でさらにOpenAIのデータセットと同規模のLAION-400Mと、より大規模なLAION-2Bスーパーセットで再現実験を行っているのか
- 画像生成AI「Stable Diffusion」のバージョン2.0が登場、出力画像の解像度が拡大&デジタル透かしを入れられる機能も (Gigazine 2022年11月24日 12時20分)
- GitHubリポジトリのREADMEも翻訳したい
- Stable Diffusion 2 - a Hugging Face Space by stabilityai
npakaさんが翻訳してくれている!
- HuggingFace Diffusers v0.9.0の新機能(npaka)
冒頭で引用しているa16zのレポートも面白かった
ビットコインとイーサリアムが2500日(約7年)かかった開発者のトレンドを数日で達成してしまっている
"アートは死なない、機械で作られるだけ"
読まなきゃいけないものがどんどん増えていく流れでした。
Discussion