GPTsにもっと知識を! AzureAiSearchを使ってRAGの構築



はじめに
自分で専用のGPTが作れるGPT Builderにメンション機能がついて超使いやすくなりました。
入力欄の最初に"@"を入れるだけで過去使用したGPTsが使用できるので、まさにボタン1つでエージェントを呼び出す感覚です。
しかし、GPTsを作成するときに直接ファイルを渡してRAGを構築してもイマイチ参照精度が良くありません。なので、全文検索&ベクトルのハイブリッド検索 + セマンティックランキングが可能なAzureAiSearch(旧Azure Cognitive Search)を使ってRAGの構築をしてみます。
構築の流れ
- Blobストレージアカウントにファイルをアップロードする
- Azure AI SearchのSearchIndexを作る
- GPTsを作成
- GPTsのAction設定でAzure AI SearchのAPIからの情報取得を設定
- 会話のテスト
①Blobストレージアカウントにファイルをアップロードする
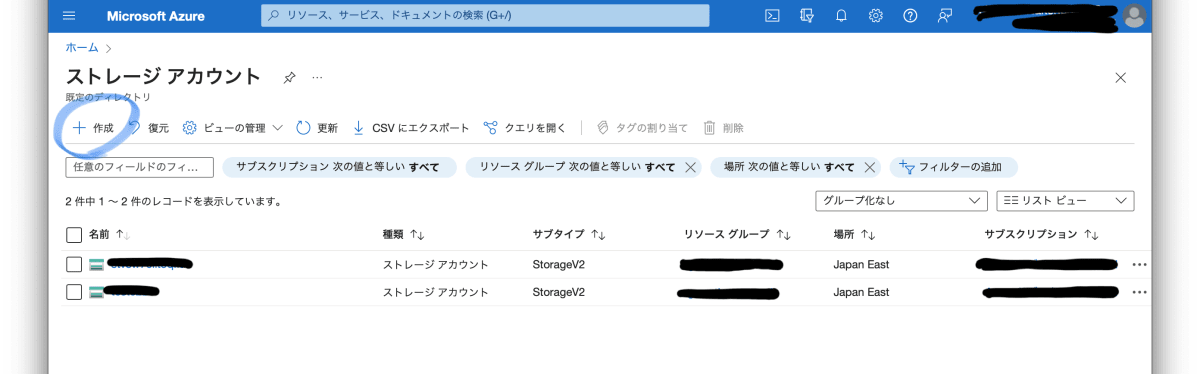
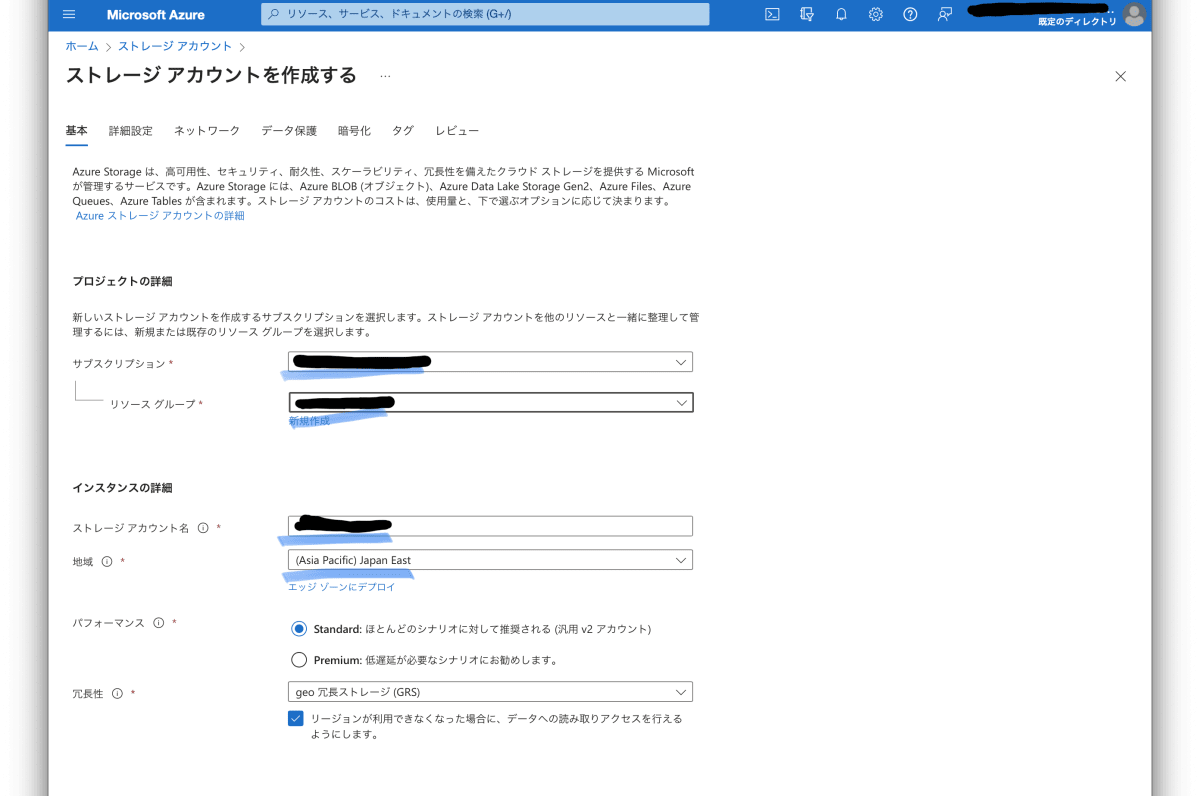
ストレージアカウントのサービスに移動し、「+作成」から新規にストレージアカウントを作ります。

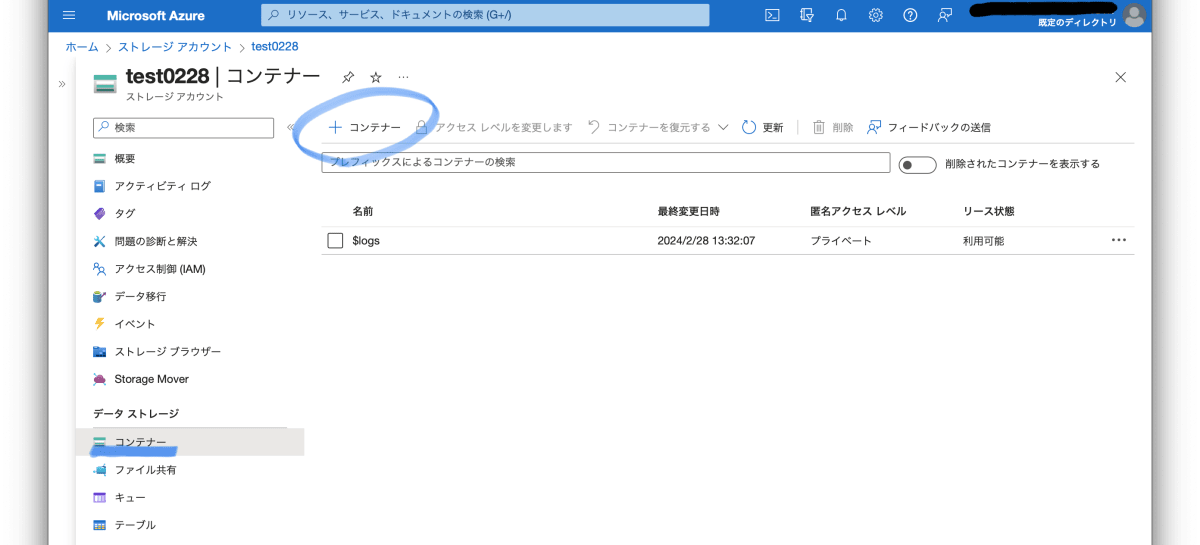
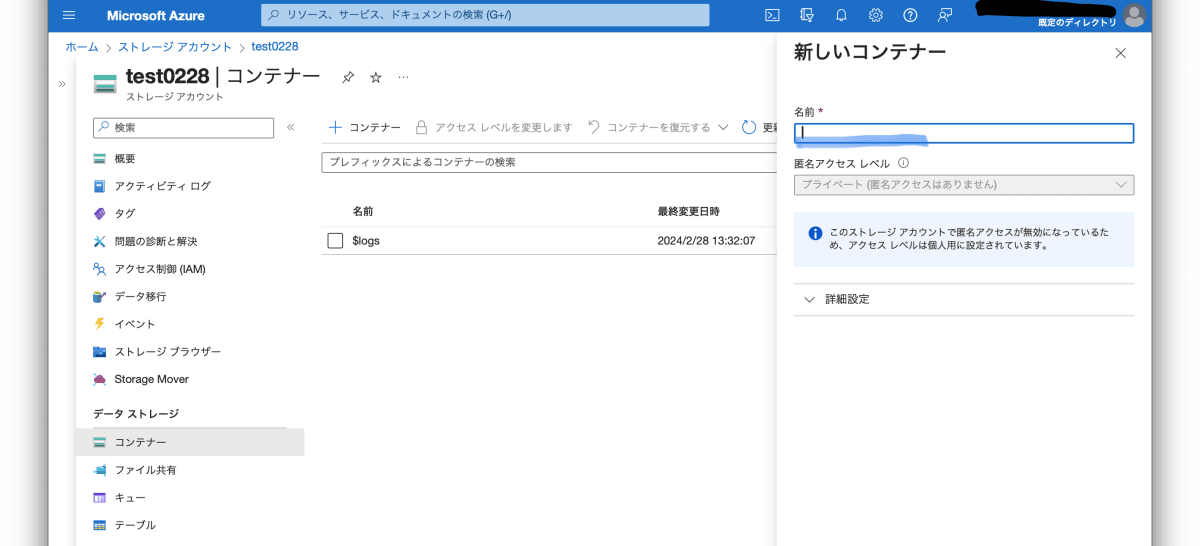
コンテナに移動し、「+コンテナー」から新しいコンテナーを作りファイルをアップロード。

今回は azure の「ai services - document intelligence -」のドキュメントをアップしました。
②Azure AI SearchのSearchIndexを作る
今回 RAG の精度を上げるために、全文検索+ベクトル検索にさらにAzure独自のセマンティック機能を追加した、セマンティックハイブリッド検索でindexを作成します。
※事前に Azure OpenAI サービスでada-002モデルをデプロイしておく必要があります。
2023年の9月に Microsoft から Azure Cognitive Search を用いた RAG システムの定量的評価結果が公表され、セマンティックハイブリッド検索(ハイブリッド+セマンティックランカー)が最も高い品質を示すと報告されています。また、チャンク分割戦略についての参考になるインサイトも提供されています。
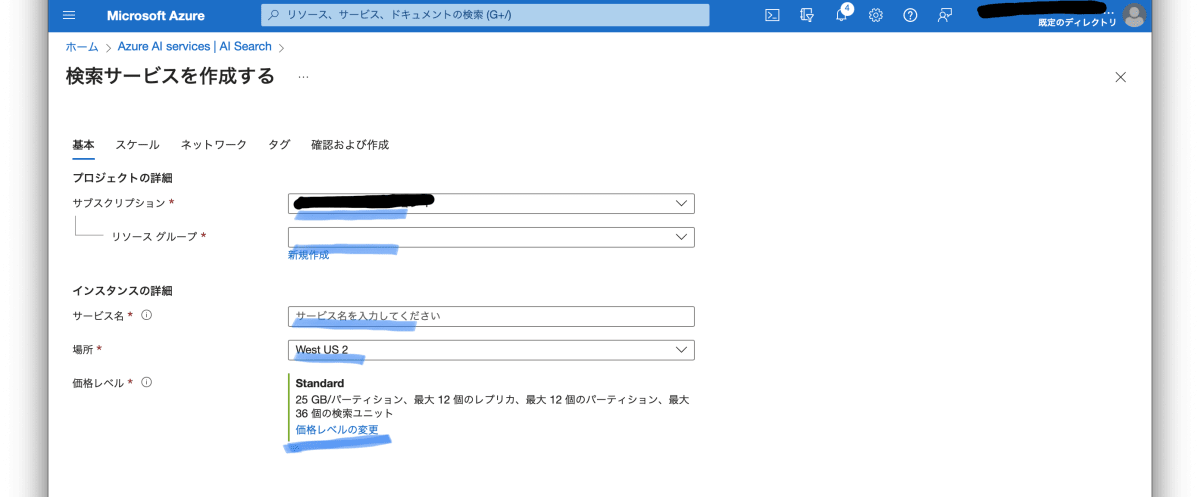
AI services から「+作成」で新しい検索サービスを作ります。

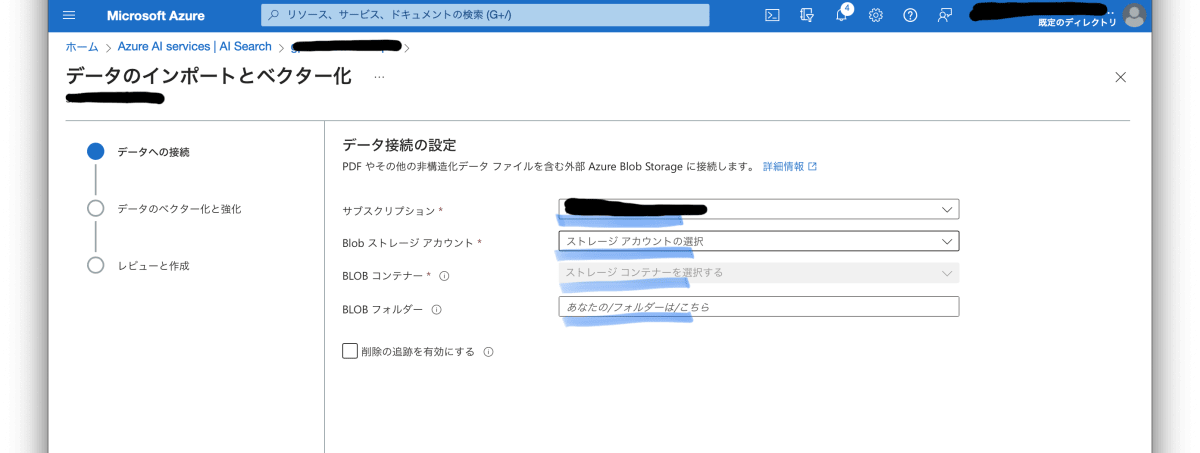
「データのインポートとベクター化」から先ほど作ったBlobのストレージアカウントとコンテナを選択。
Azure OpenAI サービスを選択し、デプロイしたada-002モデルを選ぶ。
セマンティック機能を使用するため 「セマンティックランカーを有効にする」をチェック!
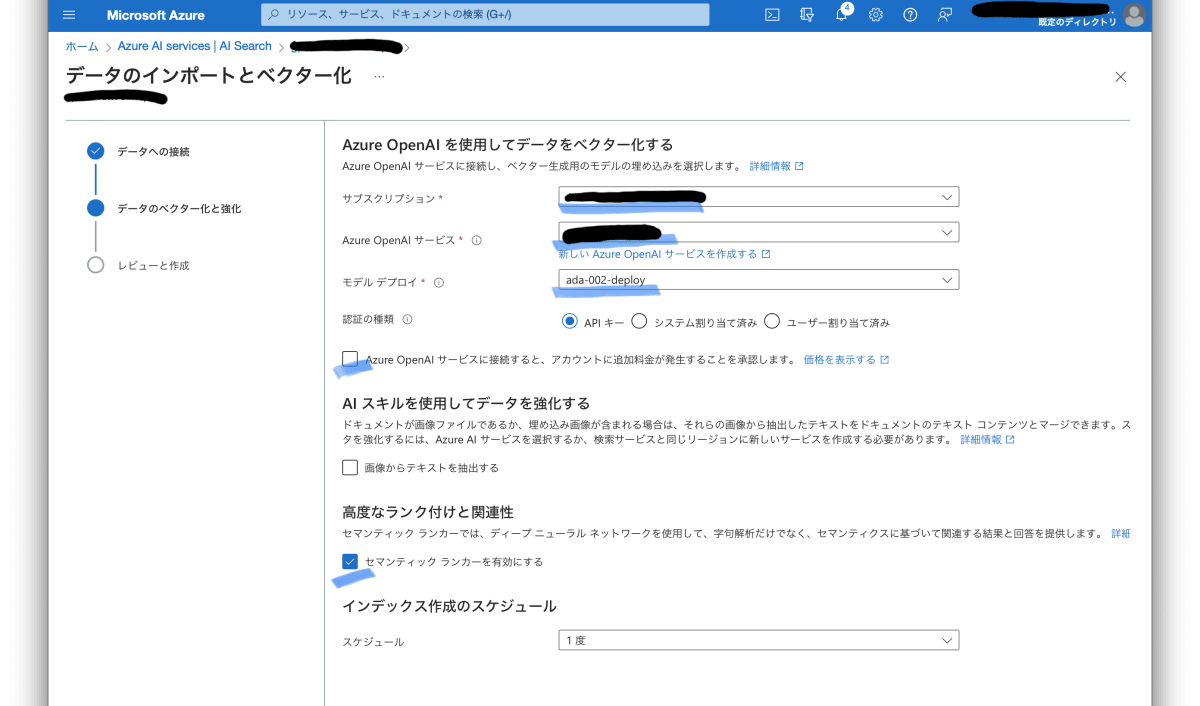
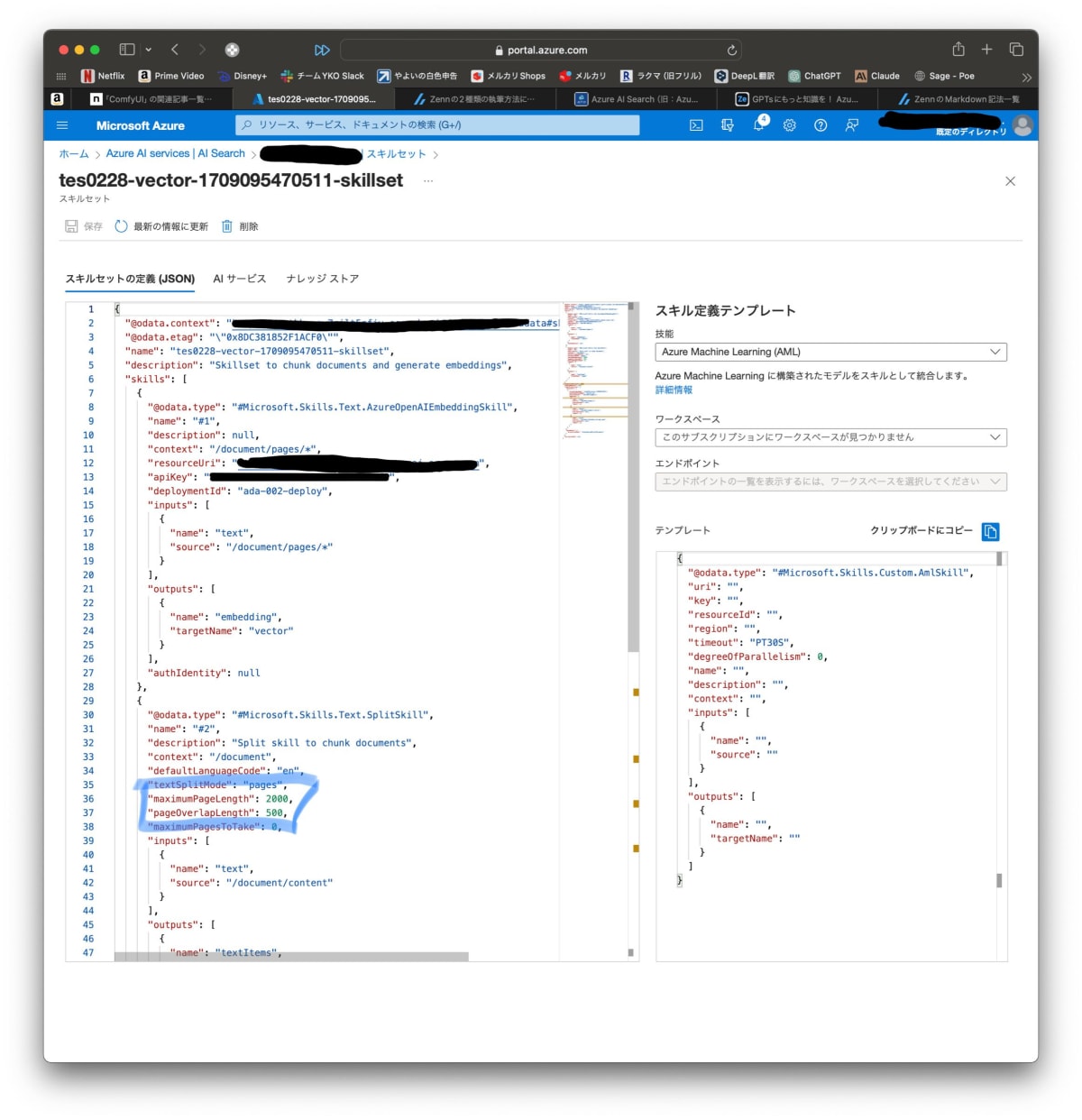
スキルセットに移動し、"maximumPageLength"と"pageOverlapLength"の値をベストプラクティスとされる512、128に変更する。
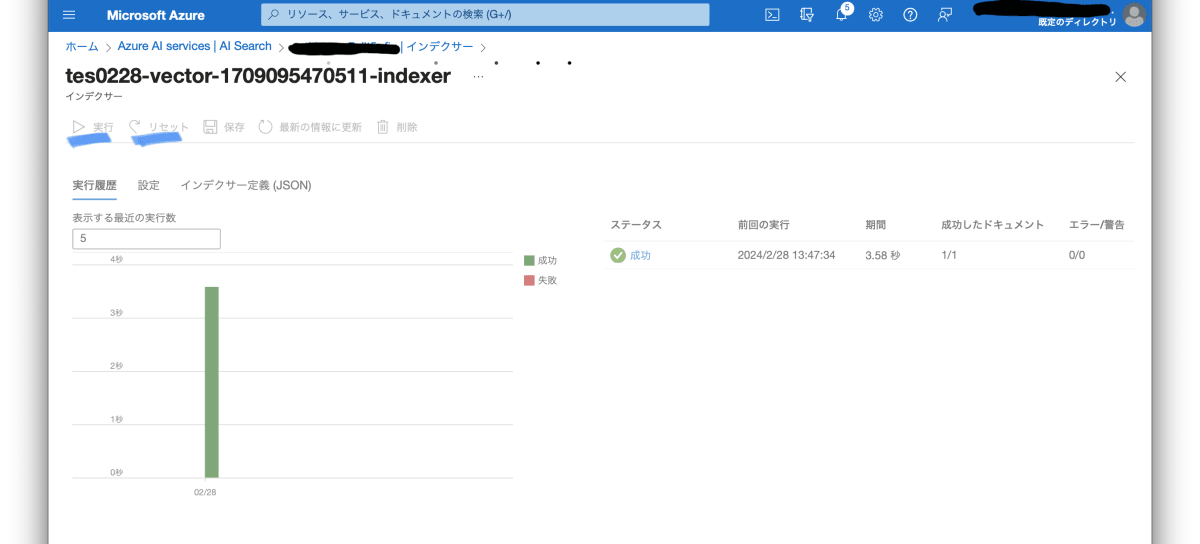
インデクサーで一度リセットしてから、実行ボタンを押して処理の終了を待ちます。
この工程では言語アナライザーがデフォルト(英語)になってしまうので、フルテキスト検索の精度が悪くなってしまいます。言語アナライザーを日本語にする方法については @tmiyata25 さんの記事が参考になります。
③GPTsを作成
左のサイドバーにある「GPTを探査する」から「+GPTを作成する」で Builder の画面に入ります。
GPTsの作り方についてはChatGPT研究所さんのnoteを参考にしてください。
④GPTsのAction設定でAzure AI SearchのAPIからの情報取得を設定
ここからがこの記事のメインです!
画面一番下にある「新しいアクションを作成」をクリックし、Add actionsの設定を行います。
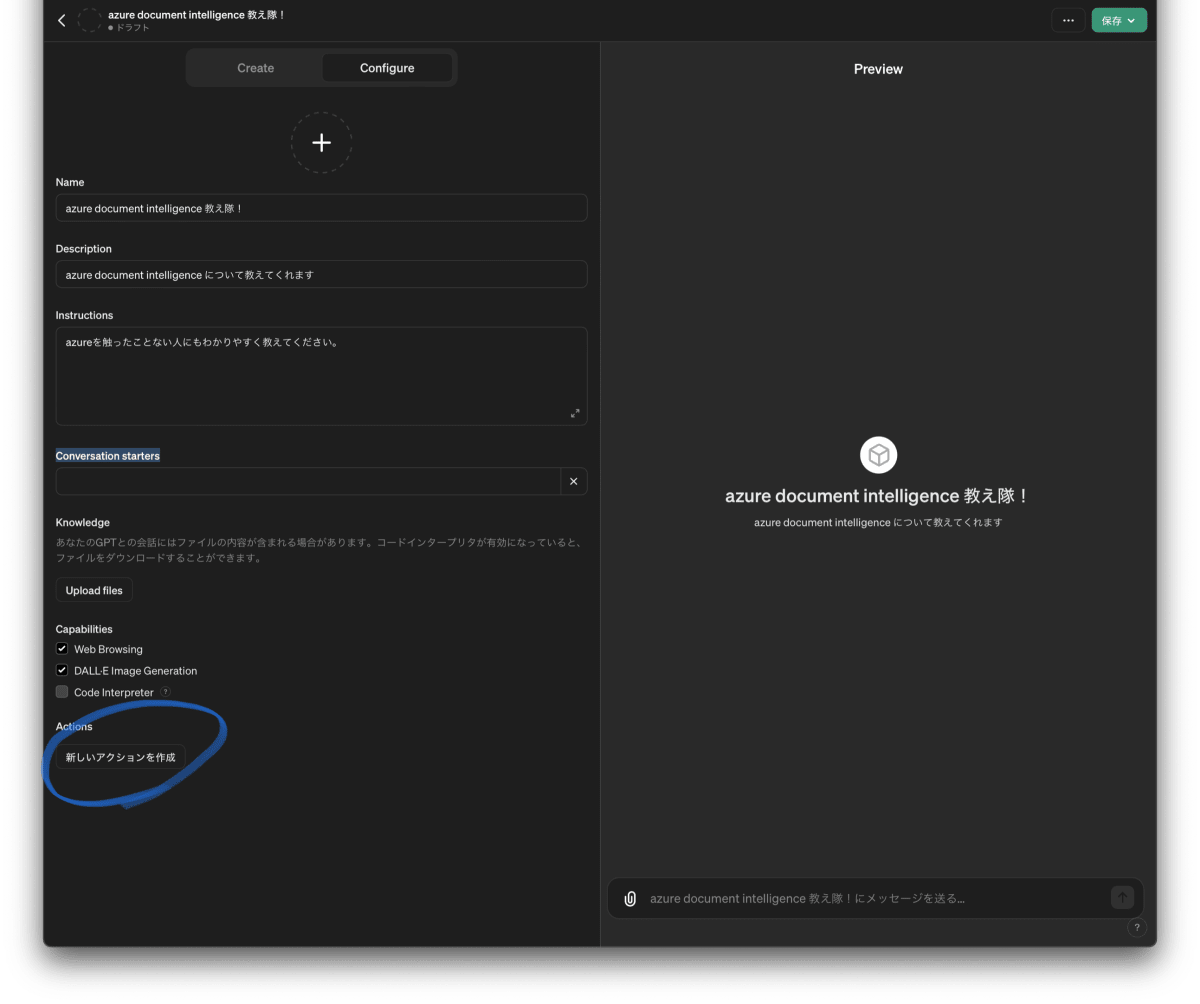
Schemaを設定する必要があるのですが、OpenAIが " Actions の設定(Schema)を作る専用の GPTs "を公開してくれています。
ActionsGPTでSchemaの作成を依頼したところ、以下の返答が・・・。
GPTs(OpenAIのカスタムAIモデル)から外部のAPI、例えばAzure AI Serviceのようなサービスに直接接続することは、一般的にはサポートされていません。これは、安全性、プライバシー、および技術的な制限によるものです。GPTsは主に事前に学習された情報をもとに応答を生成することを目的としており、リアルタイムで外部のAPIにアクセスする機能は標準では提供されていません。
直接接続の代替案:Azure Web Appsを使用してGPTsとAzure AI Serviceを連携させるための中間層の作成
直接Cognitive SearchのAPIとやりとりするのではなく、ワンクッション挟む方法をGPTさんに考えてもらいました。いろいろ案をいただいた結果、Azure Web Apps を使用して、GPTsとAzure AI Serviceを連携させるための中間層を作成することとなりました。
セキュリティ、認証、データ処理のロジックを中間層で管理し、GPTsからのリクエストを安全にAzure AI Serviceへ転送することができます。
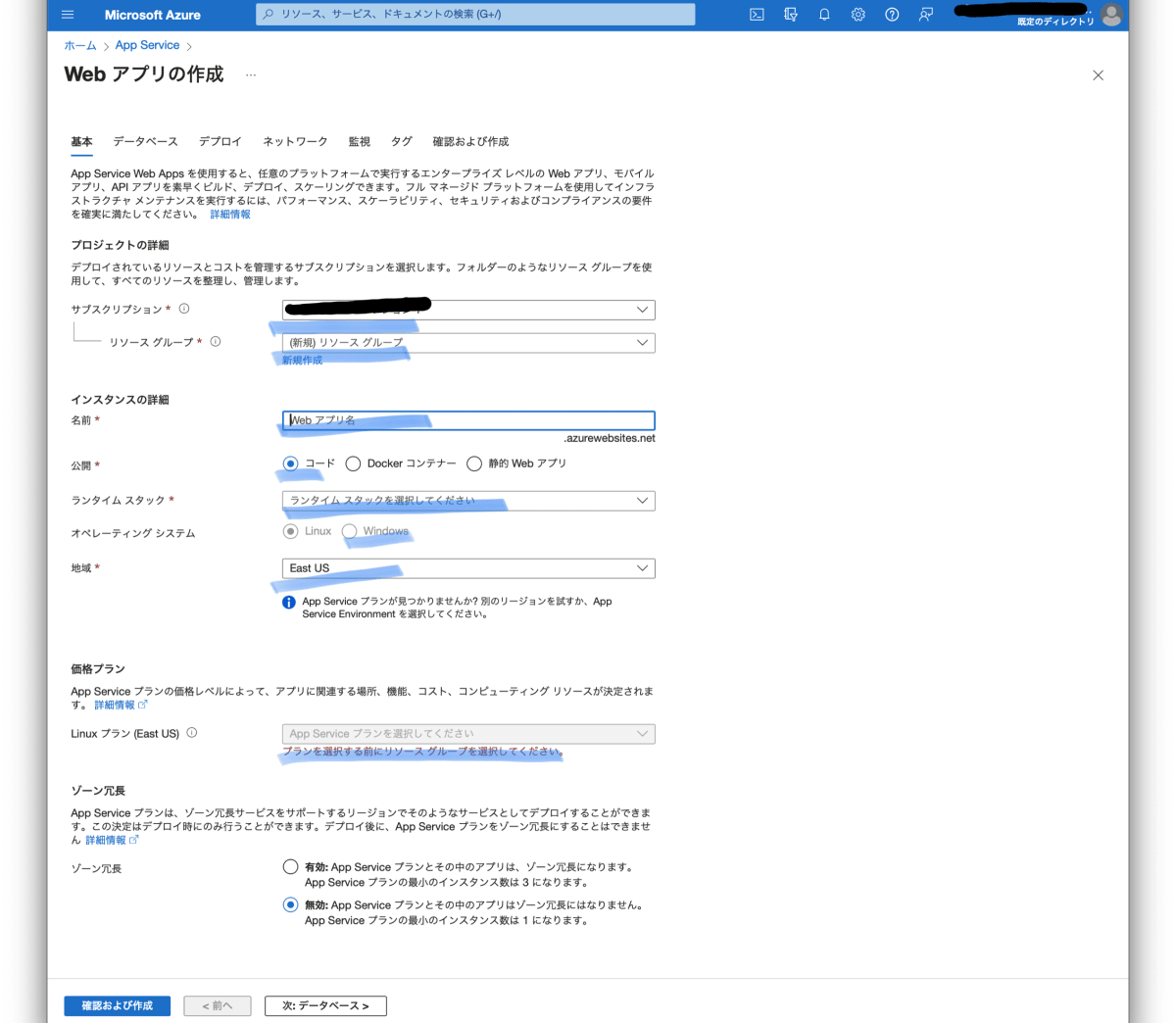
Azure App Service の作成
アプリのデプロイ自体はVS-codeから行いますので、事前にアプリをデプロイする場所を作っておきます。「+作成」から"Webアプリ"を選びます。

ランタイムスタックは今回 .NET 8(LTS)を選んでいます。
VS-code でプロジェクトの作成
-
プロジェクトのセットアップ
- VS Codeで新しいフォルダを作成し、ターミナルを開きます。
- .NET Core Web APIプロジェクトを作成するために以下のコマンドを実行します。
`dotnet new webapi -n [プロジェクト名]`
-
必要なNuGetパッケージのインストール:
Azure.Search.Documents:Microsoft.Azure.Searchの後継であり、Azure Cognitive Searchの最新のSDKです。このライブラリを使用すると、Azure Cognitive Searchサービスとのやりとりを簡単に行えます。
Microsoft.Extensions.Configuration: アプリケーションの設定(例:APIキーやエンドポイントのURL)を管理するためのライブラリです。これにより、環境変数やappsettings.jsonファイルから設定を読み込むことができます。
Microsoft.Extensions.Configuration.Json: JSONファイル形式で設定をアプリケーションに読み込むためのライブラリです。appsettings.jsonを介して設定を管理する際に必要です。
Microsoft.Extensions.DependencyInjection: 依存関係注入(DI)パターンをサポートするためのライブラリです。これは、Azure Cognitive Searchクライアントなどのサービスをコントローラーに注入する際に便利です。
これらのパッケージをプロジェクトに追加するために、Visual Studio Codeのターミナルから以下のコマンドを実行します(プロジェクト名を適切なものに置き換えてください)。
cd [プロジェクト名]
dotnet add package Azure.Search.Documents
dotnet add package Microsoft.Extensions.Configuration
dotnet add package Microsoft.Extensions.Configuration.Json
dotnet add package Microsoft.Extensions.DependencyInjection
dotnet add package Microsoft.AspNetCore.Mvc.NewtonsoftJson
-
コントローラーの作成:
- プロジェクトのルートディレクトリに「Controllers」フォルダを作成します。「Controllers」フォルダ内に新しいファイルを作成し、「CognitiveSearchController.cs」という名前を付けます。
コントローラークラスのコードを記述: - 「CognitiveSearchController.cs」ファイルを開き、以下のコードをコピー&ペーストします。
- プロジェクトのルートディレクトリに「Controllers」フォルダを作成します。「Controllers」フォルダ内に新しいファイルを作成し、「CognitiveSearchController.cs」という名前を付けます。
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Configuration;
using Azure.Search.Documents;
using Azure.Search.Documents.Models;
using Newtonsoft.Json;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
namespace YourProjectName.Controllers
{
[ApiController]
[Route("[controller]")]
public class CognitiveSearchController : ControllerBase
{
private readonly IConfiguration _configuration;
private readonly SearchClient _searchClient;
public CognitiveSearchController(IConfiguration configuration)
{
_configuration = configuration;
string serviceName = _configuration["AzureSearch:ServiceName"];
string indexName = _configuration["AzureSearch:IndexName"];
string apiKey = _configuration["AzureSearch:ApiKey"];
_searchClient = new SearchClient(new Uri($"https://{serviceName}.search.windows.net/"), indexName, new Azure.AzureKeyCredential(apiKey));
}
[HttpGet]
public async Task<IActionResult> Get(string searchText)
{
var options = new SearchOptions()
{
// ここで検索オプションを定義します。例えば、結果のサイズ制限やフィルタリング条件などです。
Size = 10, // 結果の最大数を10に制限します。
Filter = "", // 必要に応じてフィルタ条件を追加します。
Select = { "chunk" } // 必要なフィールドのみを選択します。
};
// 検索を実行します。
var results = await _searchClient.SearchAsync<SearchDocument>(searchText, options);
// 検索結果から必要な情報を抽出し、カスタムオブジェクトにマッピングします。
var response = results.Value.GetResults()
.Select(r => r.Document)
.Select(doc => new
{
Chunk = doc["chunk"]
})
.ToList();
// 特殊文字を安全に処理するためにJSONシリアル化オプションを定義します。
var settings = new JsonSerializerSettings
{
Formatting = Formatting.Indented,
StringEscapeHandling = StringEscapeHandling.EscapeHtml
};
// オブジェクトのリストをJSONにシリアル化します。
string jsonResponse = JsonConvert.SerializeObject(response, settings);
// シリアル化されたJSON文字列を応答として返します。
return Ok(jsonResponse);
}
}
}
※ インデックスのフィールドと合わせるために " Chunk = doc["chunk"] " の部分を修正してください。(chunkがフィールド名)
-
設定ファイルの編集 1:
アプリケーションの構成設定を管理するappsettings.jsonファイルを編集します。Azure AI Searchのデプロイ名、インデックス名、およびAPIキーを含める必要があります。以下の手順に従ってください。
・Azure AI Searchの設定を追加:
appsettings.jsonファイルにAzure AI Searchに関する構成設定を追加します。これには、Azure AI Searchのデプロイ名、インデックス名、およびAPIキーが含まれます。ファイルの内容は次のようになります。
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning"
}
},
"AllowedHosts": "*",
"AzureSearch": {
"ServiceName": "Azure AI Searchのデプロイ名",
"IndexName": "Azure AI Searchのインデックス名",
"ApiKey": "Azure AI SearchのAPIキー(プライマリ管理者キー)"
}
}
-
設定ファイルの編集 2:
Program.csに対しても修正が必要です。
現状、CognitiveSearchControllerがこのファイル内で明示的に言及されておらず、コントローラーのエンドポイントをアプリケーションにマップする必要があります。コントローラーを有効にするために以下の日本語でコメントがついている箇所を追加してください。
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
// コントローラーのサービスを追加します。
builder.Services.AddControllers();
var app = builder.Build();
if (app.Environment.IsDevelopment())
{
app.UseSwagger();
app.UseSwaggerUI();
}
app.UseHttpsRedirection();
// コントローラーのルートをマップします。
app.MapControllers();
var summaries = new[]
{
"Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching"
};
app.MapGet("/weatherforecast", () =>
{
var forecast = Enumerable.Range(1, 5).Select(index =>
new WeatherForecast
(
DateOnly.FromDateTime(DateTime.Now.AddDays(index)),
Random.Shared.Next(-20, 55),
summaries[Random.Shared.Next(summaries.Length)]
))
.ToArray();
return forecast;
})
.WithName("GetWeatherForecast")
.WithOpenApi();
app.Run();
record WeatherForecast(DateOnly Date, int TemperatureC, string? Summary)
{
public int TemperatureF => 32 + (int)(TemperatureC / 0.5556);
}
-
ローカルでのテスト:
プロジェクトのビルドと実行:- VS Codeのターミナルを開き、プロジェクトのルートディレクトリに移動します。
- プロジェクトをビルドするには、ターミナルで次のコマンドを実行します:
dotnet build- ビルドが成功したら、アプリケーションをローカルで実行するには、次のコマンドをターミナルで実行します:
dotnet runAPIのテスト:
- ブラウザやAPIテストツール(Postmanなど)を使用して、APIエンドポイントをテストします。例えば、コントローラーに
[HttpGet]属性で定義されたエンドポイントにアクセスするには、次のようなURLをブラウザに入力します:
https://localhost:***/cognitivesearch?searchText=your_query※ ここで
***はアプリケーションがリッスンしているポート番号、your_queryは実際の検索クエリに置き換えてください。 -
Azureにデプロイ:
- Azure CLIを使用して、コマンドラインからAzureにログインします。
az login-
アプリケーションのビルドと発行
ターミナルで以下のコマンドを使ってアプリケーションをリリース構成でビルドし、./publishディレクトリに出力します。
dotnet publish -c Release -o ./publish-
Azure App Service拡張機能を開く
- Visual Studio Codeで、左側のアクティビティバーにある「Azure」アイコンをクリックします。(Azureの機能拡張をインストールしてなければインストールしてください)
- サインイン後、デプロイしたいApp Serviceが属しているサブスクリプションを選択します。
- App Serviceのリストから、デプロイ先のApp Serviceを選択します。
- App Serviceを右クリックし、「Deploy to Web App」を選択します。
- ポップアップが表示されたら、「Browse」を選択し、先ほどdotnet publishで生成した./publishフォルダを選択します。
- 続いて、「Deploy」を選択してデプロイを開始します。
-
GPTsのActions設定
ActionsGPTに作ってもらったActions の設定(Schema)が以下になります。
openapi: 3.0.1
info:
title: GPTs and Azure AI Service Integration API
description: API for relaying requests from GPTs to Azure AI Service and returning responses.
version: 1.0.0
servers:
- url: https://"App Serviceの既定のドメイン"/CognitiveSearch
description: Production server
paths:
/:
get:
summary: Retrieve search results from Azure AI Service
operationId: search
parameters:
- name: searchText
in: query
description: Text to search for in Azure AI Service.
required: true
schema:
type: string
responses:
'200':
description: A JSON array of search results.
content:
application/json:
schema:
$ref: '#/components/schemas/SearchResults'
'400':
description: Bad request. The request was invalid.
'500':
description: Internal server error.
components:
schemas:
SearchResults:
type: object
properties:
results:
type: array
items:
$ref: '#/components/schemas/SearchResultItem'
SearchResultItem:
type: object
properties:
chunk:
type: string
description: The chunk field from the search result.
securitySchemes:
ApiKeyAuth:
type: apiKey
in: header
name: X-API-KEY
security:
- ApiKeyAuth: []
おわりに
GPTとAzure AI Searchの連携により、精度の高い RAG 機能を持ったGPTsを構築できました。API接続についてハマりましたが、GPTさんが親切丁寧に教えてくれるので本当に助かります。
RAGの精度としては根本的な問題として参照元のデータのクリーニングが一番の課題です。Azure AI Document Intelligence (旧 Form Recognizer) を使うことでかなり精度高くテキストを抜き出せるそうなので、次はこちらを深掘りしていきたいと思います。
Gemini 1.5でRAGの構築不要じゃね?って言われ始めましたが、トークン費用のことを考えると必須の技術なので、優先的に学んでいきたいですね。
Discussion