AzureSpeechServiceでリアルタイム議事録
はじめに
faster-whisperやDeepgramなど、音声認識を簡単に、そして爆速で行うツールが出てきてます。以前から音声データを渡して議事録にするんじゃなく、リアルタイムで文字起こしして、その場で要約なりネクストアクションを提案できたら便利だと考えていたので、作ってみました。
上記爆速の文字起こしツールを使う予定でしたが、コールセンターを作る記事を見てAzureのSpeech to Textも優秀そうなので今回はAzure Cognitive Servicesを使うことにしました。
今後どこかで日本語の文字起こし精度などの比較検証をしたいと思います。
構成は以下のとおりです。
- Azure Cognitive ServicesのSpeech Serviceでマイクから文字起こし
- 起こした文字をプロンプトや事前入力した背景情報となるコンテキストと共にOpenAIのAPIへ投げる
- OpenAIのAPIから受け取った回答を表示
- 簡易的にStreamlitで構築
Speech Service の準備
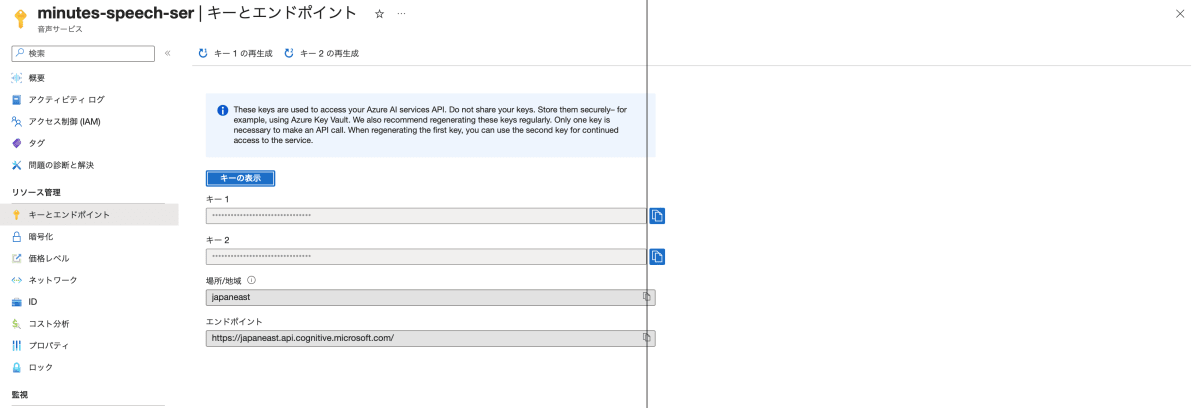
Azure Portal から Speech のリソースを作成し、Subscription Key を取得します。

OpenAI API の準備
OpenAI アカウントを作成するか、サインインします。次に、APIキー ページに移動し、「新しい秘密キーを作成」し、必要に応じてキーに名前を付けます。
必要なライブラリのインストール
streamlit
Streamlitは、Pythonを使ってWebアプリケーションを簡単に作成するためのフレームワークです。
azure-cognitiveservices-speech
Microsoft Azure Cognitive ServicesのSpeech SDKを使用するためのPythonパッケージです。
openai
OpenAI APIを使用するためのPythonクライアントライブラリです。
これらのライブラリをインストールするには、以下のようにまとめてインストールすることができます。
pip install streamlit azure-cognitiveservices-speech openai
s2t.py
マイクから入力された音声をテキストで書き起こすスクリプトです。
app.py
Streamlitのメインスクリプトです。
app.pyを実行すると、Web画面が起動します。「開始」ボタンを押すことで「音声認識を開始しました」と表示されるので、マイクに向かってしゃべると、その言葉が S2T によりテキストに変換されてテキストエリアに表示されます。
実行時output.pyというファイルが自動作成され、そこに一旦文字起こしされたテキストが保存されます。
output.pyが更新される事をトリガーにWebも自動更新されoutput.pyの中身がWebに反映されます。
これによりWeb上では文字起こしされた文字を直接編集することが可能になります。
動作検証
必要最小限の機能は搭載したので、Streamlitを起動させ、動作検証を行います。
streamlit run app.py
「開始」ボタンを押して音声入力を始めます。
なかなかスムーズにリアルタイム書き起こししてくれます。
ある程度話し終えたら横の「要約」ボタンでGPT4に要約を依頼します。
→ 上記動画(音声なし)はテストとしてスマホのマイクに使い実行しました。手元にスマホを置いていたのでしっかり聞き取りしてくれています。実際の使用では話者がある程度離れたところから話すので、ここまでの精度は出ないかもしれません。今後打ち合わせ業務があるタイミングでテストしてみたいと思います。
Discussion