⛳
[FastAPI × 外部API]asyncio.to_threadで起きたAPI実行時のフリーズ
事象
AWS App RunnerにデプロイしたFastAPIアプリケーション上で、OpenAI APIを並列処理で利用したく実装したコードが実行されたとき以下の事象が起きました。
- 1人目のユーザーがAPIを呼び出し(約60秒前後の処理)=>約5並列でOpenAIのAPIを実行
- 2人目のユーザーがアクセスすると画面がフリーズ
- 1人目のユーザー画面も動かないのでリロード等してるとフリーズ
- 当然、3人目以降のユーザー利用はアクセス不可
サーバを再起動しなければ、使えない状態になりました。
結論
正確には、フリーズではなくアクセスのあったプロセス全体が、内部的に同期処理になってしまい1人目のAPIの処理が終わるまで2人目は、待機する必要があり1人目の処理が終われば2人目の処理も動くという流れでした。
ではどうしてこのようなことが起きてしまったのか。
原因:asyncio.to_threadの落とし穴
問題のコード
@app.post("/chat")
async def chat_endpoint(prompt: str):
# asyncio.to_threadでOpenAI APIを呼び出し
result = await asyncio.to_thread(
openai_api_call, # 60秒かかる同期的な処理
prompt
)
return {"response": result}
検証で判明した事実
1. スレッドプール制限
asyncio.to_threadのデフォルトスレッドプールサイズ:
min(32, (os.cpu_count() or 1) + 4)
- 10コアCPU環境: 14スレッド
- AWS App Runner(2 vCPU): 6スレッド
2. 実測結果(15人同時アクセス、60秒処理)
- 14人: 60.01〜60.06秒で完了
- 1人(15人目): 120.09秒で完了
15人目はスレッドが空くまで待機していました。
curlで再現した実際の挙動
テスト1:2ユーザー連続アクセス(60秒処理)
# Terminal 1
curl -X POST "http://localhost:8004/bad/global_lock?user_id=User1" &
# Terminal 2(2秒後)
time curl -X POST "http://localhost:8004/bad/global_lock?user_id=User2"
結果: User2は106.92秒(1分46秒)かかりました
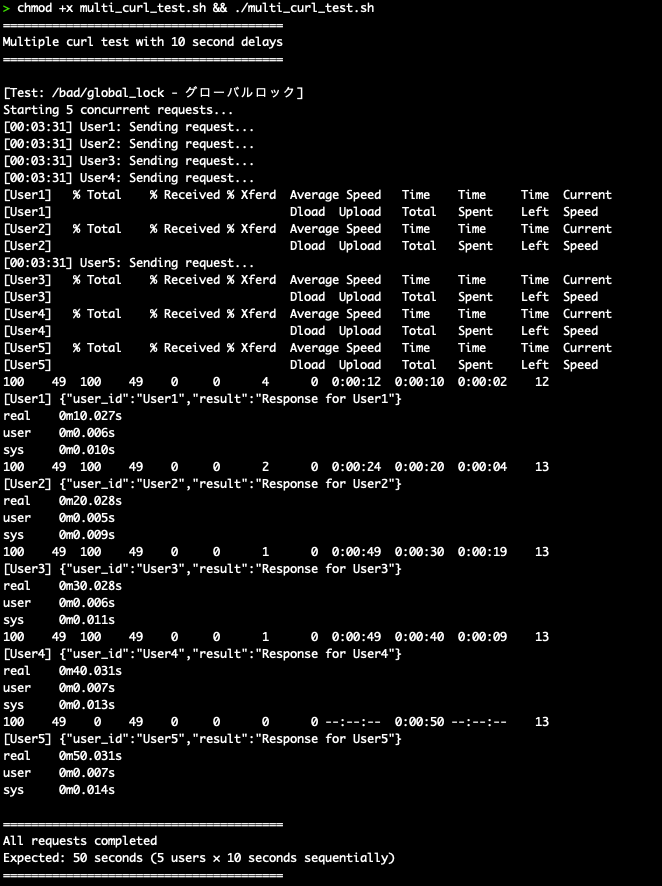
テスト2:5ユーザー同時アクセス(10秒処理)
| ユーザー | 完了時間 | 状態 |
|---|---|---|
| User1 | 10.036秒 | 即座に処理 |
| User2 | 20.033秒 | User1待ち |
| User3 | 30.034秒 | User1,2待ち |
| User4 | 40.036秒 | User1,2,3待ち |
| User5 | 50.036秒 | User1,2,3,4待ち |
完全な順番待ちが発生しました。
なぜ気づけなかったのか
環境の違い
| 環境 | CPU | スレッドプール | 同時処理可能数 |
|---|---|---|---|
| ローカル開発 | 10コア | 14スレッド | 14人 |
| AWS App Runner | 2 vCPU | 6スレッド | 6人 |
OpenAI APIの特性
- 応答時間: 30〜60秒(モデルやプロンプトによる)
- スレッドを長時間占有
- 7人目以降は完全にブロック
解決方法
専用ThreadPoolExecutorの使用
from concurrent.futures import ThreadPoolExecutor
# 専用のexecutorを作成(重要!)
executor = ThreadPoolExecutor(max_workers=10)
@app.post("/chat")
async def chat_endpoint(prompt: str):
loop = asyncio.get_event_loop()
result = await loop.run_in_executor(
executor, # asyncio.to_threadではなく専用executor
openai_api_call,
prompt
)
return {"response": result}
効果の実測
| パターン | 50人同時(5秒処理) | 平均応答時間 | 最大応答時間 |
|---|---|---|---|
| asyncio.to_thread | 20.04秒 | 11.61秒 | 20.01秒 |
| ThreadPoolExecutor(10) | 25.06秒 | 15.00秒 | 25.02秒 |
| Pure Async(理想) | 5.05秒 | 5.00秒 | 5.00秒 |
他の問題パターン
1. グローバルロック
global_lock = threading.Lock()
@app.post("/bad")
def bad_endpoint():
with global_lock: # 全員が待機
time.sleep(60)
2. グローバルフラグ
is_processing = False
async def bad_endpoint():
global is_processing
while is_processing: # ビジーウェイト
await asyncio.sleep(0.1)
is_processing = True
# 処理...
これらは論外ですが、実際のコードレビューで見かけることがあります。
教訓
-
asyncio.to_threadのデフォルト設定を過信しない- デフォルトスレッドプール: CPU数+4(最大32)
- 本番環境では予想以上に小さい
-
長時間のブロッキング処理には専用ThreadPoolExecutor
- max_workersを明示的に設定
- 処理時間とユーザー数を考慮
-
本番環境の制約を理解する
- AWS App Runner: 通常1-2 vCPU
- コンテナ環境: リソース制限あり
-
負荷テストの重要性
- 単純なcurlコマンドでも問題は発見できる
- 同時アクセス数を実環境に合わせてテスト
まとめ
今回の問題は「asyncio.to_threadを使えば並行処理できる」という思い込みから生じました。実際にはデフォルトのスレッドプール制限により、本番環境では6人までしか同時処理できませんでした。
専用のThreadPoolExecutorを使用することで問題は解決しましたが、この経験から並行処理の実装では必ず以下を確認すべきです:
- スレッドプールのサイズ
- 実際の処理時間
- 想定される同時アクセス数
- 本番環境のリソース制限
シンプルなcurlコマンドでの検証が、複雑な問題の発見に繋がることも学びました。
Discussion