Big Queryとは



なぜこの記事を記載したか?
私がBigQueryについてぼんやりしたイメージしか持っておらず、
わかっているつもりで普段会話していますが作業者ではないので
自分なりに改めて基礎的な項目から調べてみたメモです。
ですので基本的には自分のためのまとめなのですが、
「そもそもBigQueryってなに?」という初心者の方には役立つかもしれません!
BigQueryとは?
公式サイトより
マシンラーニング、地理空間分析、ビジネスインテリジェンスなどの組み込み昨日を使用してデータの管理と分析を支援する、フルマネージドのエンタープラズウェアハウスです
ま、データ管理と分析することができるってことは知っています。
簡単な表現を検索してしっくりきたのはこちら!
BigQueryとは、Googleのクラウド側のデータベースで、Google Cloud Platformにて提供されています。数テラバイトや数ペタバイトというビッグデータでの超高速で解析可能!
また実行処理速度が高速なため、リアルタイムでデータ解析も可能!
※参照:https://aiacademy.jp/media/?p=1184
リアルタイムに強みがあるというのは改めて言われて認識しました。
また、一般的にコストパフォーマンスが高くて、専門性がなくても扱うことができることがgoodポイントとされています。
できること
- データ分析
- PythonとAPI連携
pipp install google-cloud-bigquery
を行うことで手軽にpythonで扱えます
-
Google Analyticsとの連携
-これはありがたいですよね。自社サイトやサービスの訪問分析などに手軽に使えます。 -
Google Workplaceとの連携
-情報共有やファイル作成、情報の保管など会社などのグループで統括して管理できるサービスです。ここと連携しやすくできていて、連携すれば自社の分析などできるのは容易に想像がつきますよね。
料金
大きく分けると「データを保存するための料金」と「SQLを実行して結果を取得するための料金」の2つがある。
- データを保存するための料金=ストレージ料金
- GBあたり$0.02/月が発生
- SQLを実行して結果を取得するための料金=クエリ実行料金
- オンデマンド料金(使った分だけ料金)は、各クエリによって処理されたバイト数に基づく。毎月1TBまでは無料
ここら辺の料金周りは公式をご確認ください
ちなみにSQLって何?って感じの人はudemyなどで学ぶのもおすすめなので書籍だとこちらいいですよ
私はこの本にお世話になりました。
達人に学ぶとなっていますが基本的な内容が網羅的にまとまっていて尚且つそこまで難しくない言葉とレイアウトなので完全なる初心者の方もサラっとであればそこまで苦労せずに読めると思います。
ちなみに...BigQueryの歴史
Googleの社内では、Dremelというツールによってビッグデータの解析を行なっていたそうです。
ちなみすぎますが、ドレメルとは1932年のアメリカで設立された工具メーカーのようです。最初に名付けた人は、データ分析は最高の道具だぜ!って感じで名付けたのでしょうか..?
ちなみに..なぜGoogle BigQueryは高速なんだろうか?(とてもざっくり理解)
- カラム型データストア
一般的はRDBでは行単位にデータを保存します!横向きにデータを保存してるって単純にイメージしてみてください。
それに対して、BigQueryでは列ごとにまとめてデータを保存しています。
なぜこれで高速になるのかというと...
| 商品番号 | 商品名 | 価格 | 発売日 |
|---|---|---|---|
| 001 | BANANA | ¥120 | 1/1 |
| 002 | PEACH | ¥360 | 1/2 |
| 003 | GRAPE | ¥390 | 1/1 |
| 004 | APPLE | ¥200 | 1/2 |
この表でGRAPEを探したい時に上から→の方向にチェックしていくのが従来のRDBです。
これでは3回、目を上から通さないと見つからないですよね?
それに対してカラム型では商品名を↓向きにザクっと見るので検索が早いです。
ただし!その分データの追加が実は遅いというトレードオフがあります。
- ツリーアーキテクチャ
ツリーアキテクチャによって分散処理を行なっています。
ツリーアキテクチャというのは、クエリ(質問文のようなもの)を受け取るサーバーと、実際に探してくるサーバーがカラム型ではなくツリー構造になっているということです。
ここからは私の理解なので間違っているかもですが、、、
通常のアーキテクチャでは、人間に例えると、店長がアルバイト1人に向かって「商品番号が1000番台で腐ってて返品されたグレープが先月あったけどその伝票持ってきて!」って指示しています。
それに対して、ツリーアーキテクチャでは、店長がアルバイトリーダーに向かって同じ指示を出すと、さらに4人くらいのアルバイトたちが同時に条件を分解してそれぞれが探してくれるイメージです。
何が言いたかったかというと複数のサーバーが並行処理で探してくれるのがツリーアーキテクチャです。
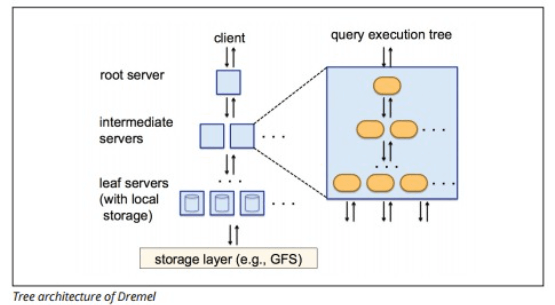
公式サイトより
おしまい。
手軽に始められそうなハンズオン
次回は、何か簡単な状況を設定して、この辺りのハンズオンをやってみたいと思います。
Discussion