VOICEPEAKのセーブデータを解析してみた
VOICEPEAKのセーブデータについて
VOICEPEAKで「プロジェクトの保存」を実行した際に生成されるセーブデータについて
内容を可能な限り解析したので、ここに共有します。
解析したとか大層なこと抜かしおりますが、セーブデータの実態は終端にNUL文字が有るjsonファイルでした。
VSCodeで開いてjsonでフォーマットすれば誰でも簡単に覗けます。
検証環境
- 検証したバージョン:1.2.13
- 所持しているVOICEPEAK:フリモメン、ずんだもん、東北きりたん、音街ウナ
- 検証環境:東北きりたんv101を選択し、「おはようございます」と入力した状態。また幾つかパラメータを操作している。

内容
"version": "1.2.13"
VOICEPEAKのバージョン
"params": {
"speed": 1.0,
"pitch": 0.0,
"pause": 1.0,
"volume": 1.0
},
プロジェクト全体設定の速さ、ピッチ、ポーズ、音量のパラメータ
値は画面上のパラメータの値ではなく、VOICEPEAK画面上部にある「全体の速さ」「全体のピッチ」等の設定がここに反映される
"emotions": {
"happy": 0.0,
"angry": 0.0,
"sad": 0.0,
"ochoushimono": 0.0,
"amaama": 0.0,
"aori": 0.0,
"hisohiso": 0.0,
"live": 0.0,
"tsuntsun": 0.0,
"bright": 0.0,
"dere": 0.0,
"dull": 0.0,
"teary": 0.0,
"joy": 0.0,
"sasayaki": 0.0,
"genki": 0.0
},
感情パラメータ。
フリモメン、ずんだもん、東北きりたん、音街ウナの感情パラメータが並んでいる。
恐らく所持しているVOICEPEAKによってパラメータの数や種類が異なると思われる。
恐らく値は0.0固定
"global-emotions": [
{
"nar": "\u30d5\u30ea\u30e2\u30e1\u30f3",
"em": {
"normal": 0.0,
"happy": 0.0,
"angry": 0.0,
"sad": 0.0,
"ochoushimono": 0.0
}
},
{
"nar": "\u305a\u3093\u3060\u3082\u3093",
"em": {
"normal": 0.0,
"amaama": 0.0,
"aori": 0.0,
"hisohiso": 0.0,
"live": 0.0,
"tsuntsun": 0.0
}
},
{
"nar": "\u6771\u5317\u304d\u308a\u305f\u3093",
"em": {
"normal": 0.0,
"bright": 0.0,
"dere": 0.0,
"dull": 0.0,
"angry": 0.0,
"teary": 0.0
}
},
{
"nar": "\u97f3\u8857\u30a6\u30ca",
"em": {
"normal": 0.0,
"joy": 0.0,
"sad": 0.0,
"angry": 0.0,
"sasayaki": 0.0,
"genki": 0.0
}
}
],
キャラごとの感情値
値はVOICEPEAKの「各ボイスの補正」の値が反映されている
narの部分はキャラの名前(フリモメンとか)
emはそのキャラの持っている感情値、ただnormalの扱いは不明・・・
"global-settings": [
{
"nar": "\u30d5\u30ea\u30e2\u30e1\u30f3",
"pm": {
"speed": 1.0,
"pitch": 0.0,
"pause": 1.0,
"volume": 1.0
}
},
{
"nar": "\u305a\u3093\u3060\u3082\u3093",
"pm": {
"speed": 1.0,
"pitch": 0.0,
"pause": 1.0,
"volume": 1.0
}
},
{
"nar": "\u6771\u5317\u304d\u308a\u305f\u3093",
"pm": {
"speed": 1.0,
"pitch": 0.0,
"pause": 1.0,
"volume": 1.0
}
},
{
"nar": "\u97f3\u8857\u30a6\u30ca",
"pm": {
"speed": 1.0,
"pitch": 0.0,
"pause": 1.0,
"volume": 1.0
}
}
],
キャラごとの設定
値はVOICEPEAKの「各ボイスの補正」の値が反映されている
"export": {
"mode": 2,
"audio-format": 0,
"sample-rate": 96000,
"write-scripts": false,
"write-text": true,
"write-srt": false,
"write-lab": false,
"name-rule": false,
"char-code": 0,
"name-formats": [
1,
0,
0
]
},
出力設定
VOICEPEAKの出力設定に準拠している。ただしmodeが何を指しているのかは不明。
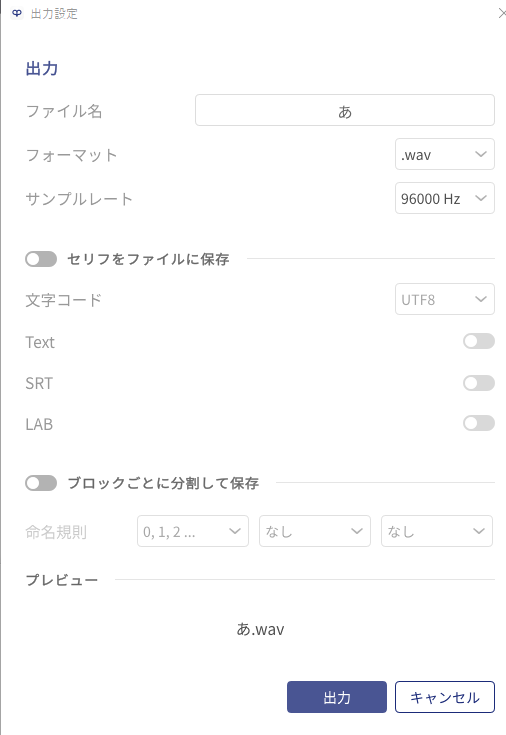
またaudio-formatやchar-code、name-formatsに指定されている値は恐らくGUIのプルダウンの何番目の値かを示している
audio-formatやchar-codeはプルダウンの一番上を選んでるので0番
name-format(命名規則)は1番目、0番目、0番目を指定しているので1,0,0
"narrator": {
"key": "\u6771\u5317\u304d\u308a\u305f\u3093",
"language": "japanese",
"narrator-version": -1
},
ナレーター情報
現在選択しているのは東北きりたんなので、keyには東北きりたんが指定されている。
narrator-versionに関しては何の値を参照しているのか不明
"time-offset-mode": 2,
"time-offset": 0.0,
"params": {
"speed": 1.0,
"pitch": -0.3499999940395355,
"pause": 1.0,
"volume": 1.0
},
"emotions": {
"happy": 0.0,
"angry": 0.0,
"sad": 0.0,
"ochoushimono": 0.0,
"amaama": 0.0,
"aori": 0.0,
"hisohiso": 0.0,
"live": 0.0,
"tsuntsun": 0.0,
"bright": 0.300000011920929,
"dere": 0.0,
"dull": 0.300000011920929,
"teary": 0.0,
"joy": 0.0,
"sasayaki": 0.0,
"genki": 0.0
},
各種設定や感情の値
東北きりたんの「ピッチ」を低くし、「明るい」「ダルい」を高く設定してあり、
GUI上で設定した値がそのまま反映されている。
"sentence-list": [
{
"text": "\u304a\u306f\u3088\u3046\u3054\u3056\u3044\u307e\u3059",
"has-eos": true,
"tokens": [
(ここの記載は後記)
]
}
],
"sentence-ranges": [
[
0,
9
]
]
あまりにも長かったのでtokenの部分のみ後述
- "text"は文字コードUTF16-BEで「おはようございます」と書いてある
- "has-eos"は恐らくEnd Of String、文末かどうかを示している?
- "sentence-ranges"は文章の長さ。「おはようございます」なので9文字
会話が複数行ある場合、sentence-listのリストの中も複数になる
"tokens": [
{
"s": "\u304a\u306f\u3088\u3046",
"pos": 4100,
"lang": 0,
"pe": false,
"syl": [
{
"s": "\u30aa",
"ig": true,
"a": 8192,
"i": 0.0,
"u": false,
"p": [
{
"s": "o",
"d": 1.0,
"n": true
}
]
},
{
"s": "\u30cf",
"ig": true,
"a": 8193,
"i": 0.0,
"u": false,
"p": [
{
"s": "h",
"d": 1.0,
"n": false
},
{
"s": "a",
"d": 1.0,
"n": true
}
]
},
{
"s": "\u30e8",
"ig": true,
"a": 8193,
"i": 0.0,
"u": false,
"p": [
{
"s": "y",
"d": 1.0,
"n": false
},
{
"s": "o",
"d": 1.0,
"n": true
}
]
},
{
"s": "\u30aa",
"ig": true,
"a": 8193,
"i": 0.0,
"u": false,
"p": [
{
"s": "o",
"d": 1.0,
"n": true
}
]
}
],
"r8": [
0,
12
],
"r32": [
0,
4
]
},
~以下省略~
tokenの部分
ここでは「おはようございます」の「おはよう」の部分のパラメータ、
また"syl"以下では「お」「は」「よ」「お」のそれぞれのパラメータが記載されている。
省略した部分では「ござい」「ます」のそれぞれの設定が記載されている。
tokenの部分について
- "s"は「おはよう」
- "pos"は恐らくpart of speech(品詞)の略語、動詞や形容詞等といったカテゴリごとに番号が振られていると思われる。
- "lang"は不明。英語で試した際も0だったので日本語ってわけでもなさそう・・・
- "pe"は音節を初期状態から修正したかどうか。修正している場合true
sylの部分について
- "s"は音節、因みに「おはよう」の「う」は発音的に「お」になるのでここでも「お」となっている
- "ig"は発音するかどうか、句読点のみの場合falseになる
- "a"は不明。番号からして何かしらのカテゴリである説
- "i"は不明
- "u"はアクセント。上がっている場合はtrueで下がっている場合はfalse
- "p"は発音に関する詳細な情報
pの部分について
- "s"は音節のローマ字表記
- "d"は発音の長さ、VOICEPEAKの「長さ」の部分の設定が反映される
- "n"は母音かどうかの判定。発音の長さはここがtrueの文字に反映される
"voices": {
"\u30d5\u30ea\u30e2\u30e1\u30f3": {
"latest": 100,
"nid": "\u30d5\u30ea\u30e2\u30e1\u30f3"
},
"\u305a\u3093\u3060\u3082\u3093": {
"latest": 100,
"nid": "\u305a\u3093\u3060\u3082\u3093"
},
"\u6771\u5317\u304d\u308a\u305f\u3093": {
"latest": 101,
"nid": "\u6771\u5317\u304d\u308a\u305f\u3093"
},
"\u97f3\u8857\u30a6\u30ca": {
"latest": 100,
"nid": "\u97f3\u8857\u30a6\u30ca"
}
}
各種ボイスの名前とバージョン。
Discussion