Webアプリケーション開発Shallow Dive

はじめに
本記事はWebアプリケーション開発を行いたいが、どのように学べば良いかわからないという人が「Webアプリケーションってこういう感じか」というような大雑把な理解をできるよう促すという目的で書かれています。
はじめに(その2)
本記事の学習は、可能な限りスムーズに学べるように記述しましたが、それでも分かりにくいという部分はとても多いと思います。その際は違うリソースをあたり、理解を促してください。
その理解を促すことに役に立つと思われる記事, サイトを以下に紹介します
特にChatGPTを有効活用することをお勧めします。以下本編です。
Webアプリケーションとは何か
ブラウザで動作し、ダウンロードが不要なアプリケーション(という理解で一旦大丈夫のはず)
ブラウザとは何か
- Chrome, Firefox, Microsoft Edgeなど
- インターネット上のページを見るために使われるソフトウェア
- ブラウザを使い、外部のコンピュータ(サーバ)と通信し、情報を取得する
ブラウザが何をしているのかを簡単に
- ユーザからの入力をもとに、サーバと通信し、HTML, CSS, JavaScriptファイルを要求する
- サーバからのレスポンス(ファイルの内容など)を受け取る
- HTML, CSS, JavaScriptファイルの内容を一つにまとめる(DOMツリー)
- その情報をもとに、ブラウザに搭載されている画面を描画する機能を使用して、画面を構築し、表示する
HTML, CSS, JavaScriptとは
| ファイルの種類 | 説明 |
|---|---|
| HTML | ページの骨組みを形成するマークアップ言語で、ページの構造や内容を定義する |
| CSS | ページのデザインやレイアウトを指定するスタイルシート言語で、文字の色、大きさ、間隔などを定義し、サイトのビジュアル面を整える |
| JavaScript | ページにインタラクティビティを提供するプログラミング言語で、ユーザーの操作に応じた動的な変更やデータのやり取りを実現する |
「HTML, CSSは見た目を作り、JavaScriptで動きをつける」と言われることが多い気がします。
ブラウザにはJavaScriptで書かれたプログラムを実行する機能があります。その機能を利用してHTMLを書き換えることで、ページの構造や内容を変更し、ページに動きをつけることができます
Webアプリケーションの構成要素
Webアプリケーションは、主に以下の要素で構成されています。
- ブラウザ
- HTTP, HTTP
- HTML
- CSS
- JavaScript
- データベース
- クライアント
- サーバー
これらについて簡単に説明します。ただし、ブラウザ, HTML, CSS, JavaScriptについては以前の資料を参照してください。
HTTP, HTTPSとは
HTTP(HyperText Transfer Protocol)は、インターネット上でデータをやり取りするためのプロトコル(コンピュータ間で情報をやり取りする際の共通の規則や手順)で、ブラウザとサーバのやり取りはこのプロトコルを使う。ブラウザがサーバにデータの要求を送り、サーバがその要求に応じてデータをブラウザに送り返すというプロセスを管理する。HTTPは基本的に平文で通信されるため、第三者によるデータの盗聴が可能。
HTTPS(HTTP Secure)は、HTTPにセキュリティを追加したもの。HTTPSでは、通信内容が暗号化されるため、第三者がデータを盗聴したとしても、内容を理解することは困難。また、HTTPSは通信が安全であることを示すために、SSL(Secure Socket Layer)またはTLS(Transport Layer Security)という技術を使用している。これにより、ユーザーとサーバ間のデータの完全性と秘密性が保たれる。HTTPSが現代のウェブで推奨される標準である。
データベースとは
データベースは、構造化された情報やデータを効率的に保存、管理、検索するためのシステム。Webアプリケーションにおいては、ユーザー情報、商品情報、注文履歴など、さまざまなデータを格納し、必要に応じてこれらのデータを取り出したり更新したりするために使用される。データベースを使用しなければ、電源が切れたときやシステムがクラッシュしたときにデータが失われる可能性がある。
クライアント, サーバとは
クライアントは、サービスやデータの要求を行うデバイスやソフトウェアを指す。一般的に、ウェブブラウザを使用しているユーザーのコンピューターやスマートフォンなどがこれに該当する。クライアントはサーバーに対して情報やサービスの要求を送り、サーバーからの応答を受け取る。
サーバは、クライアントからの要求に応じてデータやサービスを提供するデバイスやソフトウェアを指す。サーバはウェブページ、データベースのアクセス、電子メールの処理など、さまざまなサービスを提供することができる。サーバは一度に多数のクライアントの要求に応えるよう設計されている。
この中で特に理解したいのは、クライアント, サーバです。
意識したことのない人には考えたこともないかもしれませんが、あるページにアクセスをしたときにページを表示することができるのは、そのページを構成するHTML, CSS, JavaScriptファイルを、ブラウザの要求に応じて送信するためのコンピュータが存在するためです。
ただし、サーバというのは大きなジャンルで、さまざまな種類のサーバがあります。HTML, CSS, JavaScriptファイルを返すサーバもあれば、データベースから情報を取得して返すデータベースサーバ、メールを処理するメールサーバなど、特定の機能を持ったさまざまな種類のサーバが存在します。これらはすべて、クライアント(例えば、あなたのウェブブラウザ)からの特定の要求に応じて異なる種類の応答を返すように設計されています。
あくまで、クライアント, サーバとは、役割の名前である点に注意してください。あるコンピュータがある処理についてはクライアントであり、他の処理についてはサーバであることは多々あります。
クライアントとサーバの関係は、インターネット上のほとんどの活動の基礎であり、このモデルを理解することは、ウェブがどのように機能するかを理解する上で重要です。
Webアプリケーションの全体像
前に学んだ内容をビジュアル化し、Webアプリケーションの全体像を大雑把に把握しましょう。
仮想的なブログサイトの全体像
登場するもの
- クライアント
- アプリケーションサーバ
- データベースサーバ
簡易的な全体像
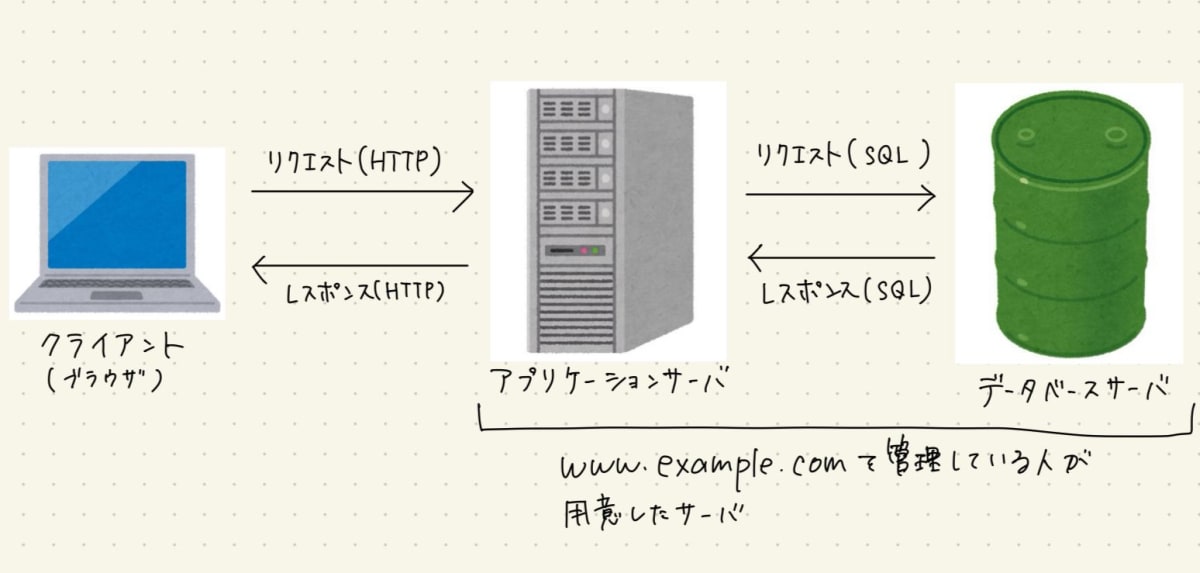
順番としては以下の通り。データベースはPostgreSQLを使用していると仮定する。
- ブラウザがブログのページを取得するリクエストをHTTP通信のルールに則ってアプリケーションサーバに送信する
- アプリケーションサーバがブラウザからのリクエストを受け取り、ページを構成する情報を取得するために、PostgreSQLの文法を使ってデータベースサーバと通信する
- データベースサーバは送られてきたSQL文を解析し、それに則ってデータを取得してそれをアプリケーションサーバに返す
- アプリケーションサーバはそのデータをもとにブログページを構成し、HTML, CSS, JavaScriptファイルをブラウザに送信する
- ブラウザは受け取ったファイルをも用いてページを描画する
SQLとは
SQL(Structured Query Language)は、リレーショナルデータベース管理システム(RDBMS)でデータを管理するための標準的な言語です。データを挿入、更新、削除、取得するために用いられます。SQLを使うことで、アプリケーションサーバはデータベースサーバに対して、特定のデータを要求したり、データベース内の情報を変更したりすることが可能になります。
SQLとPostgreSQLの違い
SQLについて
SQL(Structured Query Language)は、データベースでデータを操作するための標準的な言語です。これには、データを検索、挿入、更新、削除するための文法規則やコマンドが定義されています。SQLはリレーショナルデータベース管理システム(RDBMS)において、表形式のデータとその関係を効率的に操作するために設計されています。
PostgreSQLについて
PostgreSQLは、SQL言語をサポートするオープンソースのリレーショナルデータベース管理システム(RDBMS)の一つです。これは、SQLのクエリを解析し、データベース内でデータを管理、格納、取得するための機能を提供します。PostgreSQLは、SQL規格の多くの拡張機能をサポートしており、そのため高度なデータベース機能を利用可能です。
つまり、SQLはデータを操作するための言語であり、PostgreSQLはそのSQL命令を解析して実行するデータベースの「エンジン」です。ユーザーはSQLを使用してデータに対する操作を記述し、PostgreSQLはそのSQLを解析して実際のデータに対して指示された操作を実行します。このプロセスによって、ユーザーはデータベースに格納された情報を効率的に管理できるようになります。
ソフトウェアエンジニアについて
ソフトウェアエンジニアには、作業領域に応じてさまざまな職種に分けられます。雰囲気を理解するための記述なので、各人で思うところがあるかもしれませんが、ご了承ください。
フロントエンドエンジニアとは
フロントエンドエンジニアは、ウェブサイトやアプリケーションのユーザーインターフェースを開発する役割を持っています。彼らはHTML、CSS、JavaScriptなどの言語を使用して、ユーザーが直接対話するウェブページの見た目と機能を構築します。フロントエンドエンジニアは、ユーザーエクスペリエンス(UX)とユーザーインターフェース(UI)の設計に密接に関わり、ウェブサイトのレスポンシブデザインやアクセシビリティを確保します。
バックエンドエンジニアとは
バックエンドエンジニアは、ウェブサイトやアプリケーションのサーバー、データベース、アプリケーションロジックを担当します。彼らは主にサーバーサイドのプログラミングに関わり、データベース管理、サーバーの構成、APIの開発などを行います。バックエンドエンジニアは、データの保存、取得、処理、セキュリティ対策などを担当し、フロントエンドと連携してユーザーにシームレスな体験を提供します。
SREとは
SRE(サイト信頼性エンジニア)は、システムの可用性、信頼性、パフォーマンスを保証する役割を担います。DevOpsの文化や原則に基づき、開発と運用の間のギャップを埋めることを目指しています。SREは、システムの監視、トラブルシューティング、自動化、システムの強化を通じて、インフラストラクチャのスケーラビリティと安定性を維持します。SREは、障害発生時の迅速な対応や予防措置の策定を含むDevOpsプラクティスを実践して、システムのダウンタイムを最小限に抑えます。
データエンジニアとは
データエンジニアは、データの収集、蓄積、処理、分析のためのシステムを構築します。彼らはデータベースの設計、データパイプラインの構築、データクレンジング、データウェアハウスの管理などを行います。データエンジニアは、ビッグデータ技術やクラウドサービスを駆使して、大量のデータを効率的に処理し、分析チームやビジネスユーザーがアクセスしやすい形でデータを提供します。
ML/DLエンジニアとは
機械学習(ML)や深層学習(DL)エンジニアは、アルゴリズムとモデルを構築して、データから学習し予測を行うシステムを開発します。彼らは数学と統計学、プログラミングスキルを活用して、パターン認識や予測分析のためのモデルを作成します。ML/DLエンジニアは、データの前処理、特徴抽出、モデルの訓練、評価、そして最適化を行い、実際の問題解決に応用します。これには画像認識、自然言語処理、推薦システムなど、さまざまなアプリケーションが含まれます。彼らは、モデルが現実世界のデータと予測において高い精度を持つように、継続的な改善を行います。
仮想的なサービスを通してWebアプリを学ぶ
以前の記事でブログアプリケーションの全体像を見ましたが、今回はより詳細に、実践的な全体像を紹介していきます。
また、ここに出てくる用語を説明してさらなる学習を行いやすくします。
次の記事で、どのようなフローでアプリが動作するのかを見ていきます。
登場人物
- クライアント
- アプリケーションサーバ
- データベースサーバ
- 認証認可
- ロードバランサ
- リバースプロキシ
- DNS
- GCPのシークレットマネージャ
- キャッシュサーバ
- CI/CD
- モニタリングとログ管理
全体像

クライアント
クライアントは、ユーザーが使用するデバイス(PC、スマートフォンなど)にインストールされたブラウザです。ユーザーがブログのURLをブラウザに入力すると、クライアントはサーバーにHTTPリクエストを送信し、コンテンツの表示を求めます。
HTTPとは
HTTP(HyperText Transfer Protocol)とは、インターネット上で情報をやり取りするためのルールや手順を定義したプロトコルです。ウェブ上でページや画像などのコンテンツをブラウザからサーバーに要求し、サーバーからブラウザへとコンテンツを送り返す際に使用されます。
簡単に言えば、HTTPはインターネット上での会話のルールのようなもので、クライアント(例えばウェブブラウザ)がサーバーに対して「このページを見せてください」とリクエストを送り、サーバーが「はい、どうぞ」と応答してコンテンツを送り返す方法を定義しています。このプロセスを通じて、ユーザーはウェブサイトを閲覧したり、フォームを送信したりすることができます。
DNS
DNS(Domain Name System)は、ユーザーがブラウザに入力したウェブサイトの名前(例:www.exampleblog.com)を、アプリケーションサーバのIPアドレスに変換します。これにより、クライアントは正しいサーバーにリクエストを送信できます。
IPアドレスとは
IPアドレスとは、インターネット上のデバイスを一意に識別するための番号です。このアドレスは、インターネット上でデータが正しい目的地に送信されることを保証する役割を持っています。
ただし、IPアドレスにはプライベートIPアドレスというものがあります。
プライベートIPアドレスは、インターネット全体に公開されることなく、一般的には家庭内や企業内のネットワークで使用されるIPアドレスです。これらのアドレスは、同じネットワーク内のデバイス間での通信に使われ、外部のインターネットに直接接続することはありません。プライベートIPアドレスによって、ネットワーク内のデバイスは互いに識別し、通信できる一方で、インターネット上でユニークでなくても問題ないため、公共のIPアドレスの範囲を節約することができます。
IPアドレスの範囲を節約とは?
IPアドレスとは、IPv4, IPv6という形式があります。IPv4アドレスは、32ビットの番号で構成されており、約43億のユニークなアドレスを提供しますが、インターネットの急速な成長により、利用可能なIPv4アドレスの数が不足してきています。一方、IPv6アドレスは128ビットで構成され、ほぼ無限に近い数のユニークなアドレスを生成することができます。これにより、IPアドレスの不足問題を解決し、今後のデバイスの増加に対応できるようになります。プライベートIPアドレスを使用することで、公共のIPv4アドレスを節約することができ、企業や家庭内ネットワークなどでは、限られた範囲のアドレスを効率的に利用して内部通信を行うことができます。
IPv4アドレスの例: 192.168.1.1
IPv6アドレスの例: 2001:0db8:85a3:0000:0000:8a2e:0370:7334
ブラウザの検索欄に、IPアドレスを指定するとどうなる?
ブラウザの検索欄にIPアドレスを直接入力すると、そのIPアドレスに関連付けられているウェブサーバーに直接アクセスします。DNS解決を経由せずに指定されたアドレスのサーバーに直接リクエストが送信されるため、ウェブサイトの名前ではなく、数値のアドレスを使用してインターネット上の特定のリソースやサービスに直接アクセスすることができます。
例えば、https://www.google.comと検索するのと、https://216.58.220.142と検索するのでは、同じ結果になります。
ロードバランサ
ロードバランサは、複数のアプリケーションサーバーに対してクライアントからのリクエストを分散します。これにより、単一のサーバーに過負荷がかかることを防ぎ、アプリケーションの可用性とパフォーマンスを向上させます。
過負荷とは
過負荷とは、システムやサーバーが正常に処理できる以上の量のリクエストやデータを受け取った状態を指します。この状態では、システムが遅くなる、応答しなくなる、あるいは完全に停止するなど、パフォーマンスが著しく低下します。過負荷は、ユーザーの体験を損ない、システムの信頼性に影響を与えるため、避けるべき状態です。
可用性とは
可用性とは、システムやサービスが必要とされる時に、正常にアクセス可能であり、機能している状態のことを指します。高い可用性を持つシステムは、障害やメンテナンスなどで一部のコンポーネントが停止しても、全体としては正常に機能し続けることができます。可用性が高いほど、システムは信頼性が高いと評価され、ユーザーの満足度やビジネスの継続性が保たれます。
アプリケーションサーバ
アプリケーションサーバは、クライアントからのリクエストを受け取り、適切な処理(データベースへのクエリ、HTMLページの生成など)を実行します。そして、処理結果をクライアントに戻します。アプリケーションのロジック部分はこのサーバが提供します。
データベースサーバ
データベースサーバは、ブログの記事、ユーザー情報、コメントなどのデータを保存し、アプリケーションサーバからのクエリに応じてデータを提供します。データベースの冗長化を行うことで、データの可用性と安全性を高めることができます。ほとんどのアプリケーションにとって、データベースサーバは超重要です。データを損失してしまうと、ユーザーからの信頼を失うことにつながります。
データベース冗長化とは
データベースはアプリケーションにとって最上位レベルで重要です。そのため、データベースサーバが一つの場合、そのデータベースが壊れたときにそのアプリケーションは崩壊します。それをデータベースサーバを複数台用意し、コピーをすることで回避することができます。これをレプリケーションと言います。ただのバックアップとして使うこともありますが、アプリのユーザが増えてデータベースサーバへのアクセスが集中した場合、レスポンスが遅くなります。そのため、レスポンスを返すデータベースサーバを複数台にすることでその問題を軽減します。それで解決するアプリケーションであれば良いですが、データを同期することが必須のアプリケーションの場合は、複数台のデータベースの中身を同期するという課題もあります。
リバースプロキシ
リバースプロキシとは、アプリケーションサーバが行うやり取りをさまざまなユーザを相手にすることがないように、ユーザからのアクセスを一旦受け止め、代表してサーバとやり取りをするためのサーバです。リバースプロキシがサーバとやり取りを代行することで、いくつかの重要な利点が生まれます。まず、セキュリティ面での強化が挙げられます。リバースプロキシはアプリケーションサーバの前に位置し、外部からの直接的なアクセスを防ぎます。これにより、不正アクセスや攻撃からアプリケーションサーバを保護することができます。
また、リバースプロキシはクライアントからのリクエストを集約するため、ロードバランシングの役割も果たします。複数のアプリケーションサーバがある場合、リバースプロキシはこれらのサーバ間でリクエストを適切に分散し、各サーバの負荷を均等にします。これにより、サービスの可用性とパフォーマンスが向上します。
さらに、リバースプロキシは静的コンテンツのキャッシングも行います。ウェブサイトにアクセスする際、画像やCSSファイルなどの静的リソースは頻繁に再利用されます。リバースプロキシがこれらのコンテンツをキャッシュしておくことで、同じコンテンツのリクエストがあった際には、直接リバースプロキシから迅速に提供することができ、アプリケーションサーバの負担を減らし、ユーザー体験を向上させます。
さらに、SSL終端の機能をリバースプロキシが担うこともあります。これは、リバースプロキシがクライアントからの暗号化された通信を受け取り、復号化してから内部ネットワークのサーバに転送する作業を指します。これにより、内部ネットワークのセキュリティが強化されるとともに、アプリケーションサーバの負担を軽減することができます。
キャッシュとは
キャッシュは、頻繁に使用されるデータや計算結果を一時的に保存するための領域です。これにより、毎回データベースサーバにアクセスしてデータを取得する代わりに、高速なメモリから直接データを取得できます。結果として、アプリケーションのレスポンス時間が短縮され、全体的なパフォーマンスが向上します。キャッシュは、リピートされるクエリや静的コンテンツに対する高速なアクセスを提供することで、システムの効率を大幅に改善することができます。
キャッシュとはあくまでそういう役割であり、さまざまな種類のキャッシュがあります。CPU内や、ブラウザにもキャッシュは存在します。キャッシュというのはコンピュータの処理を早くするためにさまざまなところで使用されます。ちなみに欲しい情報がキャッシュにあった場合はキャッシュヒット, なかった場合はキャッシュミスという言われ方をします。
メモリとは
メモリを理解するために、大まかなコンピュータの構造を把握しましょう。
コンピュータの三代構成要素は、CPU, メモリ, 外部記憶装置があげられます。
CPUはメモリにある情報を用いて計算します。コンピュータで使用するデータはメモリになければなりませんが、全てのデータがメモリに乗っかるとは限らず、ほとんど乗っかりません。そのため、乗っからない分を保存しておくために外部記憶装置(HDD, SSDなど)が必要になります。
コンピュータの構造的に、CPUとメモリアクセスに比べてHDDへのアクセスにかかる時間は大きく異なり、HDDへのアクセスはメモリへのアクセスより数万倍長くかかります。
そのため、二次記憶装置へのアクセスはソフトウェアの処理速度に大きな影響を及ぼします。
キャッシュサーバ
キャッシュサーバ(例:Redis)は、頻繁にアクセスされるデータや計算結果を一時的に保存します。これにより、同じリクエストに対して毎回データベースにアクセスする必要がなくなり、アプリケーションのレスポンス時間が短縮されます。
なぜデータベースへのアクセスを少なくしたいのか
データベースへのアクセスを減らすことは、Webアプリケーションのパフォーマンス向上に不可欠です。データベースへのアクセスはCPUやディスクI/Oといったリソースを多く消費し、特に大量のユーザーが同時にアクセスする場合には、レスポンスタイムが著しく遅くなる可能性があります。これに対して、キャッシュはメモリ上にデータを保持するため、データベースよりもはるかに高速にデータを取得することができます。
CI/CD (Continuous Integration/Continuous Deployment)
CI/CDは、開発プロセスを自動化し、コードの品質を保ちながら迅速にアプリケーションをビルド、テスト、デプロイするためのシステムです。Continuous Integration(継続的統合)では、コード変更がリポジトリにプッシュされるたびに自動的にビルドとテストが行われ、エラーを早期に検出します。Continuous Deployment(継続的デプロイメント)では、テストをパスしたコードが自動的に本番環境にデプロイされます。これにより、手動のデプロイメントプロセスにおけるエラーを減らし、リリースサイクルを加速します。
開発プロセスとは
開発プロセスとは、ソフトウェアやアプリケーションを開発するための一連の手順や活動を指します。これには、要件定義、設計、コーディング、テスト、デプロイメントなど、アイデアから最終製品までの全ステップが含まれます
コード品質とは
コード品質とは、ソフトウェアコードの信頼性、保守性、読みやすさ、効率性などの属性を指します。高品質のコードはバグが少なく、他の開発者によって簡単に理解され、変更が容易です。コード品質を維持することは、長期的にソフトウェアのパフォーマンスと安定性を保つ上で重要です。
ビルドとは
ビルドとは、ソースコードから実行可能なソフトウェアアプリケーションを生成するプロセスです。これには、コードのコンパイル、ライブラリのリンクなどが含まれます。ビルドプロセスは、コードの変更をアプリケーションに統合し、テストやデプロイメントのための成果物を生成します。
コンパイルとは
コンパイルとは、プログラミング言語で書かれたソースコードをコンピュータが直接実行できる形式、つまり機械語やバイナリコードに変換するプロセスです。
リンクとは
リンクとは、複数のコンパイルされたコード(オブジェクトファイル)やライブラリを一つの実行可能ファイルに統合するプロセスです。この過程では、異なるファイルに分散している関数や変数の参照を解決し、プログラムが正しく動作するために必要な全てのコードとデータを連結します。
テストとは
テストとは、ソフトウェアが設計通りに正しく動作することを確認するプロセスです。これには、単体テスト、統合テスト、システムテスト、受け入れテストなどが含まれます。テストを行うことで、バグや問題を早期に特定し、製品の品質を保証します。
基本的にテストを行うためにもテスト用のコードを書く必要があります。
デプロイとは
デプロイとは、完成したソフトウェアをユーザーがアクセスできる環境に配置するプロセスです。これには、サーバーへのアップロード、データベースの設定、依存関係のインストールなどが含まれます。デプロイメントにより、ソフトウェアがエンドユーザーに提供され、実際に使用されるようになります。
リポジトリとは
リポジトリとは、ソースコード、ドキュメント、その他のプロジェクトファイルを保存するための場所です。リポジトリは、バージョン管理システム(例:Git)を使用して、コードの変更履歴を追跡し、複数の開発者が共同で作業できるようにします。リポジトリは、プロジェクトのコードベースに対する変更を管理し、協調作業を容易にする重要なツールです。
モニタリングとログ管理
モニタリングツールは、アプリケーションのパフォーマンスと健康状態をリアルタイムで追跡します。これにより、システムの問題を早期に発見し、迅速に対応することが可能になります。ログ管理システムは、アプリケーションとシステムのログを収集、保存、分析します。これにより、問題の診断、システムの動作理解、セキュリティ監査などが容易になります。
健康状態とは
ヘルスチェックという言葉がソフトウェア開発には出てきます。
ソフトウェア開発における「健康状態」とは、アプリケーションやシステムが正常に機能しているかどうかを示す状態を指します。この文脈でのヘルスチェックは、ウェブサーバー、データベース、その他のシステムコンポーネントが適切に応答しているかを定期的に検証するプロセスを意味します。例えば、ウェブアプリケーションのヘルスチェックでは、特定のURLへのリクエストに対する応答時間やステータスコードを確認することが含まれる場合があります。
ログとは
ログとは、ソフトウェアやシステムが実行中に生成する記録のことで、ユーザーのリクエスト、システムのエラー、その他のイベントの詳細を含みます。これらのログは、開発者が問題の診断、システムのパフォーマンスのモニタリング、セキュリティ監視などを行うのに役立ちます。
GCPのSecret Manager
GCPのSecret Managerは、APIキー、パスワードなどの機密情報を安全に管理し、アクセスを制御するサービスです。これにより、アプリケーションコードから機密情報を分離し、セキュリティを強化することができます。アプリケーションは必要に応じてシークレットマネージャから機密情報を取得できます。データベースサーバへのアクセスは非常にセキュリティが重要視されるため、アクセス認証のためにパスワードやその他の認証情報が必要になります。そのため、データベースへのアクセスにはパスワードが必要です。パスワードを安全に管理するために、GCPのシークレットマネージャのような、専門的にセキュリティ対策が施されたサービスを利用して機密情報を管理します
GCPとは(クラウドサービスとは)
GCPとはGoogleが提供するクラウドサービスの総称で、上のSecret Managerもクラウドサービスの一つです。
クラウドサービスにはさまざまものがあり、どこで動いているのかというと、Googleのもつデータセンターのことです。
これによりユーザーは物理的なインフラストラクチャ(サーバ, ネットワーク, 電力など)を自身で管理することなく、必要に応じたリソースを使用することができます。リソースの使用量に応じて費用がかかります。
データセンターとは
データセンターとは、高性能のコンピューター機器と大規模なストレージシステムを集約した施設で、普通のパソコンよりもはるかに強力です。これらの施設は、膨大なデータを処理し、インターネットベースのサービスを提供するために設計されています。データセンターは大量の電力を消費し、高度な冷却システムと厳重なセキュリティ対策を備えており、企業のデータ保管やクラウドコンピューティングサービスなどに不可欠な基盤を提供します。
APIとは
API(Application Programming Interface)とは、ソフトウェアやアプリケーション間で情報を交換し、相互に機能を利用できるようにするための規約やインターフェースです。APIは、異なるプログラムがお互いに「話し合い、協力し合う」ための方法を提供します。
以下にしよう例をいくつか紹介します。
天気情報の表示
ウェブアプリケーションやスマートフォンアプリで、ユーザーの現在地に基づいて最新の天気情報を表示したい場合、開発者は天気情報を提供するサービスのAPIを使用して、リアルタイムの天気データを取得し、アプリケーションに表示します。
ソーシャルメディアへの投稿
アプリケーションから直接FacebookやTwitterなどのソーシャルメディアプラットフォームに投稿する機能を提供したい場合、それぞれのプラットフォームが提供するAPIを利用して、ユーザーのアカウントと連携し、投稿を行うことができます。
支払い処理の統合
オンラインショップやサービスで顧客に安全な支払い手段を提供するには、PayPalやStripeなどの支払いサービスのAPIを統合することにより、購入処理中にこれらのサービスを通じて支払いを処理し、取引情報を管理できます。
地図データの利用 アプリケーション内で地図を表示したい場合や、ルート案内を提供したい場合、Google Maps APIやOpenStreetMap APIを利用して、地図データをアプリケーションに組み込み、ユーザーに対して視覚的な情報を提供できます。
これらの例では、APIを利用することで、開発者は独自に複雑な機能を一から実装する必要なく、既存のサービスやデータをアプリケーション内で活用することができます。これにより開発の効率が大幅に向上し、ユーザーにとって価値ある機能を迅速に提供できるようになります。
APIという言葉は概念としてふわっとしていて、理解するのは難しいと思います。しかし繰り返し学んでいく中で、APIが何なのかということを体が受け入れられるようになるはずなので、初めからしっかり理解する必要はありません。
APIキーとは
APIキーは、APIを使用する際に認証と認可を行うためのコードやトークンです。APIキーを使用することで、開発者はAPIへのアクセスを安全に管理し、不正アクセスを防ぐことができます。APIキーは通常、APIを提供するサービスによって生成され、APIリクエストを行う際にパラメータとして送信されます。これにより、サービス提供者はリクエストを行ったユーザーやアプリケーションを識別し、アクセス権を制御することができます。
仮想的なサービスを通してWebアプリを学ぶ(フロー編)
前章で必要となるトピックをさらったので、この章で処理の流れを見ていきましょう。ブログサービスのURLは、www.exampleblog.comとします。
ただし、これはあくまで一例であり、方針によってさまざまなフローが考えられます。ご了承ください。
全体像
ページ取得
クライアントがページを取得する時

- ブラウザが
www.exampleblog.comにページ取得をリクエスト。その際にクライアントのPCがそのURLのIPアドレスを調べるために、DNSサーバに問い合わせる - DNSサーバがIPアドレスをクライアントに送信
- そのIPアドレスに対して、ページ取得をリクエストする。そのIPアドレスの行き先はnginxなどのリバースプロキシになっており、一旦リバースプロキシがそのリクエストを受け止める。ちなみにこの時リバースプロキシのIPアドレスはクライアントPCにキャしゅされます
- リバースプロキシが、負荷が均等になるようにするなどの目的で、適切なAPサーバにリクエストを割り振る
- APサーバがレスポンスを返すために必要な情報をDBサーバから取得するためにリクエストを送信する。取得の際はマスターではなくスレーブのDBサーバへアクセスする
- DBサーバがAPサーバに情報を送信する
- APサーバがその情報をもとにファイルを作成し、リバースプロキシに送信する
- リバースプロキシがそのファイルたちをブラウザに送信する。その際にリバースプロキシはそのファイルたちがまたリクエストされた時に備えて、キャッシュしておく(破棄せずにメモリに保持しておく)
他のクライアントが同じページを取得する時
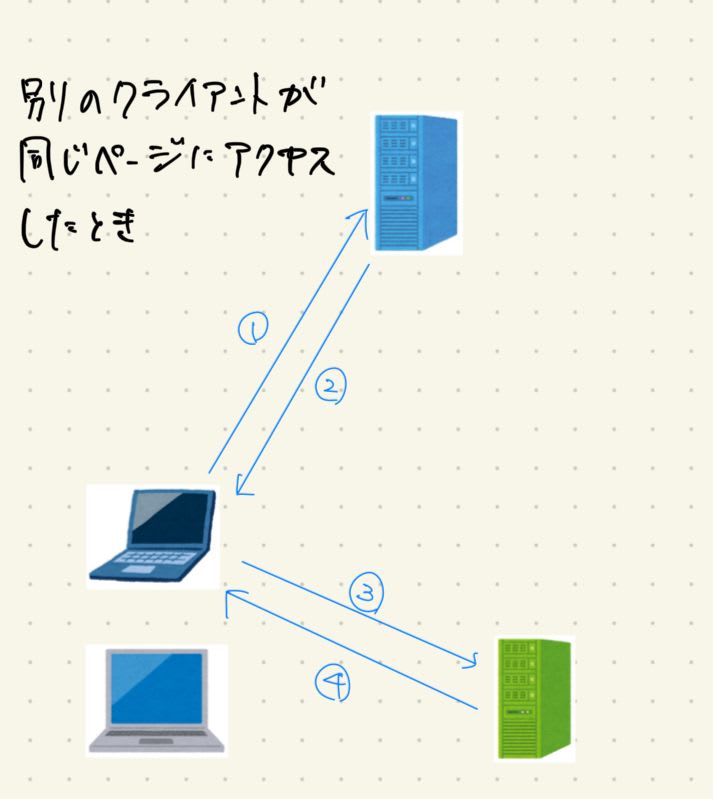
- ブラウザが
www.exampleblog.comにページ取得をリクエスト。その際にクライアントのPCがそのURLのIPアドレスを調べるために、DNSサーバに問い合わせる - DNSサーバがIPアドレスをクライアントに送信
- そのIPアドレスに対して、ページ取得をリクエストする。そのIPアドレスの行き先はnginxなどのリバースプロキシになっており、一旦リバースプロキシがそのリクエストを受け止める
- そのページに関するファイルはキャッシュにあるので、それを返す
このようにして、キャッシュが働くことでAPサーバ, DBサーバとの通信時間を削減したり、サーバへの負荷を軽減することができます。ただし、リバースプロキシのキャッシュ領域にも制限があるので、そこおさまらなくなれば古い情報などから破棄し、入れ替えを行います。キャッシュミスをすればまたAPサーバ, DBサーバへアクセスすることになります。
冗長化, 高可用性について
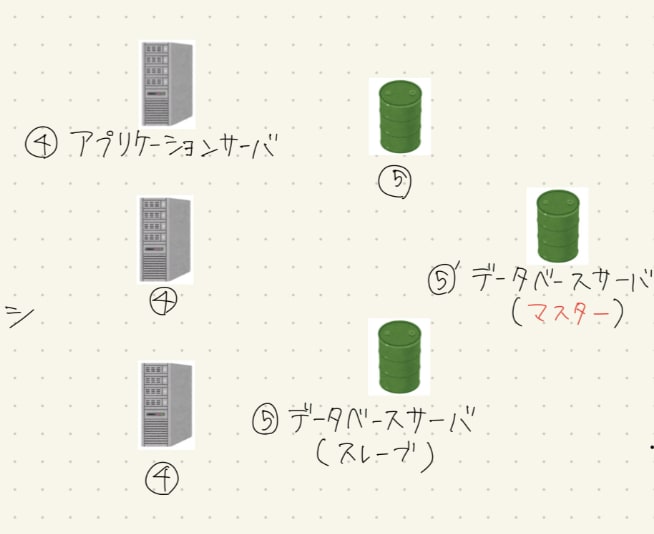
上の画像のようにAPサーバやDBサーバを複数配置し。冗長にすることで、以下のようなケースに対応できます。特にDBサーバの冗長化については、マスター-スレーブレプリケーション、マスター-マスターレプリケーションなど、異なる種類の冗長化戦略があり、この例ではマスター-スレーブレプリケーションを採用しています
APサーバの場合
- 高負荷によってダウン、または低速になったサーバがあった際に、他のサーバにリクエストを割り振ることができる
- 負荷を分散することで、全体のパフォーマンスを向上させることができる
DBサーバの場合
- 何かしらの要因によってDBが壊れた際に、他のDBにもコピーがあるおかげで、データを失わずに済む
- 高負荷によってダウン、または低速になったサーバがあった際に、他のサーバにリクエストを割り振ることができる
可用性について
可用性とは、システムやサービスが必要とされるときに、利用可能でアクセス可能である程度を指します。つまり、ユーザーがサービスやリソースにアクセスしようとしたとき、そのサービスやリソースが正常に動作して、適切に応答できる状態を意味します。
例えば、ウェブサイトやオンラインサービスの可用性が高い場合、そのウェブサイトやサービスは24時間365日、いつでもアクセスでき、正常に機能します。逆に、可用性が低いと、システムのダウンタイムが多くなり、ユーザーがサービスにアクセスできない時間が長くなります。
可用性は、システムがどれだけ信頼できるか、またはどれだけ連続して稼働できるかを示す重要な指標であり、特にビジネスや緊急サービスにとっては不可欠な要素です
書き込み時
データベースに内容を保存する際の流れを見てみましょう。ここではクライアントのPC上にリバースプロキシへのIPアドレスがキャッシュされているとします。
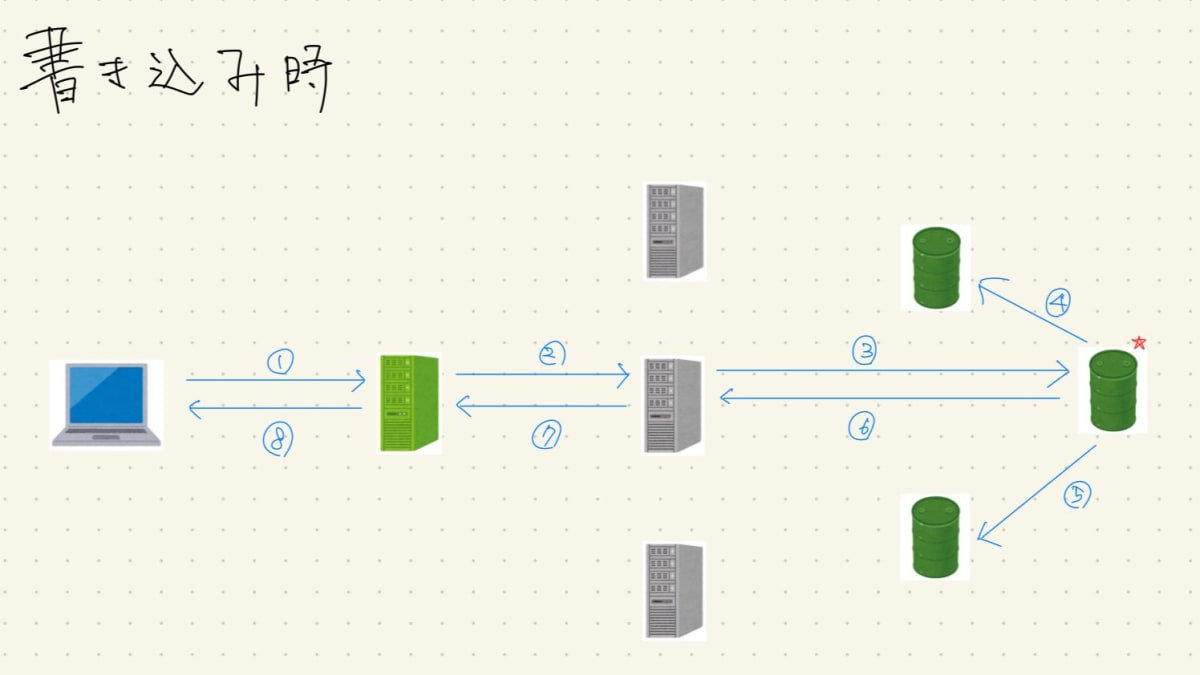
- 保存したい内容を含めたHTTPリクエストをサーバ宛に送信する
- リバースプロキシがそのリクエストを受け止め、適切なAPサーバへリクエストを送信する
- 書き込み処理なので、マスターのDBサーバへ書き込みをしにいく
- 書き込み処理を行ったマスターのDBサーバが、他のスレーブのDBサーバの内容と同期する処理を行い、アプリケーション全体のデータの同期を行う
- 4と同様
- 書き込みが完了したという内容をAPサーバに返す
- その内容をAPサーバからリバースプロキシに返す
- その内容をリバースプロキシからクライアントに返す
モニタリングとログ管理
システムを適切に管理するために、サーバが出力するログを管理し、システムの状況を把握することが必要になる場合があります。その際にそれ用のサーバとDBサーバを用意した場合の例を紹介します。
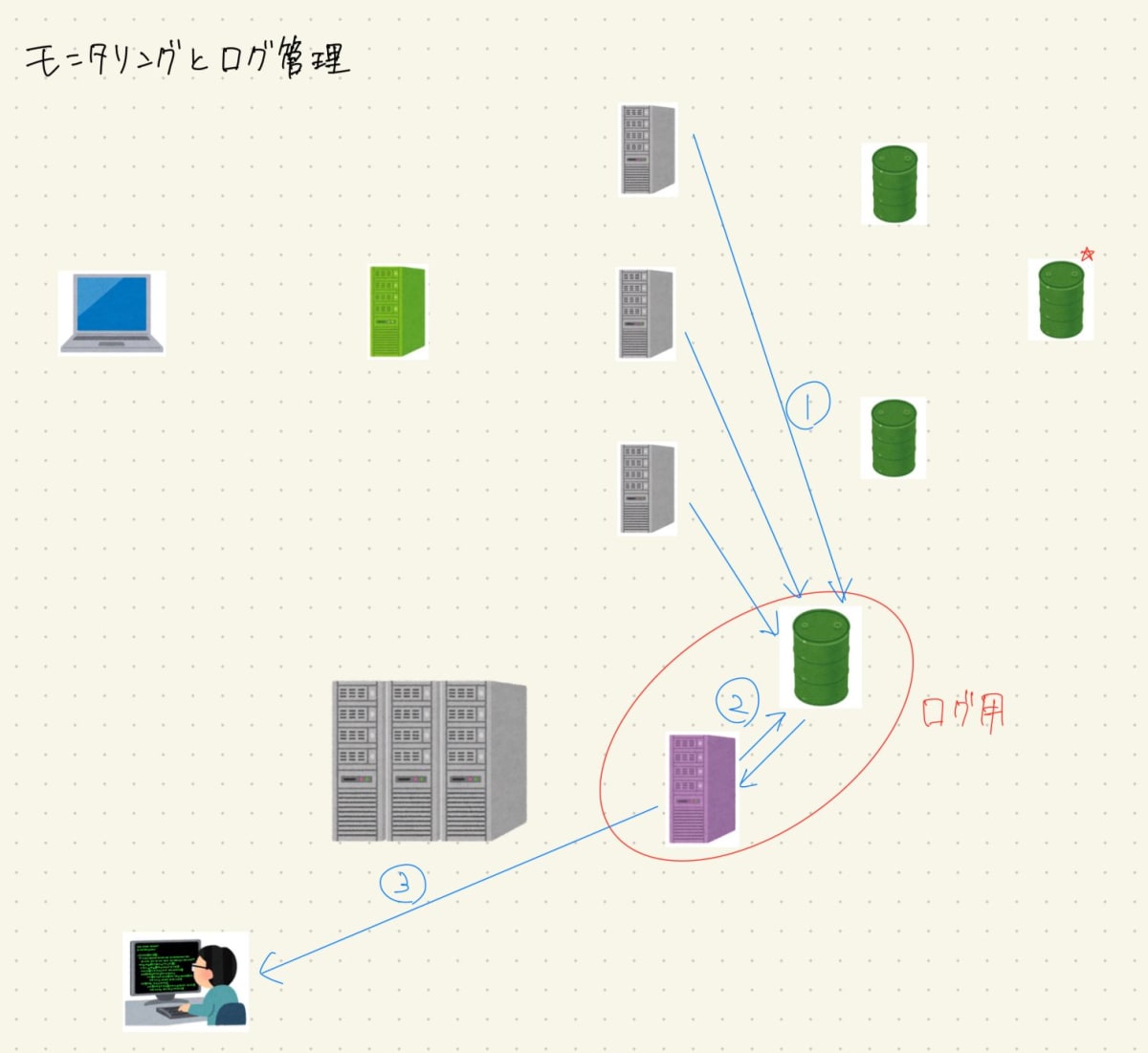
- APサーバが出力するログを、ログ収集用DBサーバに送信する
- ログ管理, モニタリング用のサーバがログ収集用DBサーバからデータを取得し、データを可視化などして管理者が分析をしやすくする
- 「こういう状況になったら不具合かもしれないから知らせてほしい」というラインを超えた場合に、管理者にメール等で知らせる。これをアラートと呼ぶ
企業やチームでエンジニアリングを行う際に考えること
個人開発とチーム開発では、開発プロセスにおける考慮事項に大きな違いがあります。特に、企業レベルのチーム開発では、以下のような側面を重視する必要があります。
- 技術選定, 運用コスト
- 権限管理
- コードレビューについて
- シンプルさ
技術選定について
技術選定を行う際に考えるポイントには以下のようなものがあります。
要件を満たすか
選定する技術が、プロジェクトの目的や機能要件を満たしているかを評価します。これには、パフォーマンス、セキュリティ、拡張性など、必要とされる特定の特性が含まれます。
運用コスト
選定した技術を継続して運用するために必要なコストを評価します。これには、ライセンス料、サーバー費用、メンテナンスコスト、さらには将来的なアップグレードやスケーリングのコストも含まれる場合があります。
社員がその技術を学びやすいか
技術の学習曲線や、学習リソース(オンラインコース、ワークショップ、書籍など)の利用可能性を考慮します。社員が新しい技術を効率良く学び、プロジェクトに活用できるかどうかは、プロジェクトの成功に直結します。
社員がその技術を知っているかどうか
既存のチームメンバーが選定した技術について既に知識や経験を持っているかを評価します。技術スキルのマッチングは、プロジェクトのスタートアップ速度や開発効率に大きく影響します。
その技術に関する知見が得やすいか(情報が多いか)
選定した技術に関するドキュメント、チュートリアル、コミュニティのサポート、インターネット上の情報の量など、必要な情報を容易に入手できるかを評価します。
GitHubのスター数などが多いと、ユーザーが多いということなので、色々と安心できることが多い。
開発が滞ってないか
選定した技術が積極的に開発・メンテナンスされているか、定期的にアップデートが行われているかを確認します。滞っている技術を採用すると、将来的にサポートや互換性の問題に直面する可能性があります。
権限管理について
アプリケーションのデータベースやその他の重要なシステムへのアクセスを厳密に制限することによって、セキュリティインシデントを最小限に抑えるための重要なプロセスです。この管理により、機密情報への不正アクセスやデータの不正使用を防ぎ、システムの整合性と信頼性を維持します。
新人のエンジニアが悪意なく重要なデータを消したりすることを防ぐために、そもそも新人のアクセス権を付与しないなどすることで対処したりしています。
コードレビューについて
コードレビューは、ソフトウェア開発プロセスにおいてコード品質を向上させるために欠かせないステップです。このプロセスでは、実際にコードを書いた人以外の別のエンジニアがコードを検証し、可能性のあるエラーや改善点を指摘します。効果的なコードレビューを行うためには、変数の命名規則の明確化、コードの意図を説明するコメントの追加、GitHubなどのツールを利用した明確なフィードバックの提供などが推奨されます。これにより、コードレビューのプロセスがスムーズに進行し、すべての開発者がより読みやすく、理解しやすいコードを生み出すことができるようになります。
シンプルさについて
シンプルさは、ソフトウェア開発において非常に重要な原則です。シンプルな設計やコードは、理解しやすく、問題を特定しやすく、そして維持しやすいです。シンプルなソリューションは、余分な複雑さを避けるために必要な要素だけに焦点を当て、結果としてバグやエラーのリスクを減少させます。また、シンプルなコードは、他の開発者が新しい機能を追加したり、既存のコードを修正したりする際に、時間と労力を節約することができます。
実装内容や方針をシンプルに保つことは、チーム全体の生産性を向上させるだけでなく、将来の拡張性や保守性にも寄与します。シンプルで明瞭なソフトウェアは、長期的な視点で見ると、時間とコストの両方を削減することに繋がります。したがって、ソフトウェアを設計する際には、複雑さを最小限に抑えることを心がけ、シンプルさを目指すべきです。
何を学べばWebエンジニアインターンに参加できるのか
これについてはもちろん企業によるのですが、多くの企業で必要とされる機能があります。それは何で、どうして必要なのかということについて解説していきます。(もちろん偏見もある)
以下の内容についてある程度身についていると言えるようになれば、あとはインターン先を見つけ、参加することができると考えています。
- プログラミングの基礎
- Webアプリケーションの基本要素とHTTP通信
- TCP/IPの基本的な知識
- Git, GitHubの基本的な使い方
- データベース, SQLの基本的な知識
- Webアプリケーション構築に必要な要素
- Linuxの基本知識
- Docker, コンテナを利用する目的
- フロントエンド. バックエンドの基本的な知識
- 何か自分でWebアプリケーションを作成した経験
プログラミングの基礎
以下の内容を理解して使えるようになると良いと思います
- データ型
- 変数
- 関数
- 配列
- 辞書, キーバリュー
- if文
- for文
- モジュールとパッケージ
Webアプリケーションの基本要素(入門)とHTTP通信
- クライアント
- サーバ
- ブラウザ
- HTML, CSS, JavaScript
- API
- データベース
- HTTP, HTTPS
- ステータスコード, ヘッダー, Cookie
TCP/IPの基本的な知識
- IPアドレスとは
- MACアドレスとは
- ルータとは
- TCPとは
- パケットとは
- イーサネットとは
Git, GitHubの基本的な使い方
- add, commit, push
- pull, switch, merge
- rebase
データベース, SQLの基本的な知識
- データベースサーバとは
- リレーショナルデータベースとは
- カラム, レコード
- 正規化
- SQLとは
- SQLの基本文法
- select, insert, update, delete
- where, join
Webアプリケーション構築に必要な要素(実践)
- クライアント
- サーバ
- アプリケーションサーバ
- データベースサーバ
- 認証認可
- ロードバランサ
- リバースプロキシ
- DNS
- キャッシュサーバ
- CI/CD
- モニタリングとログ管理
Linuxの基本知識
- なぜLinuxが広く使われているのか
- ファイルシステムの大まかな理解
- 基本的なコマンド
- cd, ls, mkdir, touch, rm
Docker, コンテナを利用する目的
- コンテナとは
- 可搬性とは
- 環境の差異をなくすとは
- docker build, imageとは
何か自分でWebアプリケーションを作成した経験
- フロントエンド, バックエンドでの両方の開発
- API開発
- データベースへの接続
- デプロイし、アクセスできるようにする
- Git, GitHubでソースコードを管理する
そして、さらに以下の内容について、それを行うメリットややり方を理解していると、かなり評価されると思います
- 保守性を意識した開発
- 分かりやすい変数名, 適切なディレクトリ構成, 適切な技術選定など
- テスト
- Dockerの利用
- クラウドサービスの利用(AWS, GCP)
- CI/CDの利用(GitHub Actions)
おすすめ書籍
私が読んだ中で、Webアプリ開発の学習に役立つと思う書籍を紹介します
ネットワーク
- マスタリングTCP/IP―入門編
- DNSがよくわかる教科書
- Linuxで動かしながら学ぶTCP/IPネットワーク入門
Linux
- 新しいLinuxの教科書
Docker, コンテナ
- 図解即戦力 仮想化&コンテナがこれ1冊でしっかりわかる教科書
- 仕組みと使い方がわかるDocker&Kubernetesのきほんのきほん
データベース, SQL
- SQL 第2版 ゼロからはじめるデータベース操作
- データ指向アプリケーションデザイン(多く、難しいがとても良い書籍)
Web
- Webを支える技術
- Webフロントエンドハイパフォーマンスチューニング(前半)
サービス全体
- 大規模サービス技術入門
プログラミングの基礎
- ゼロからわかる TypeScript
- プロを目指す人のためのTypeScript入門
プログラミング言語やフレームワークで何を使用すれば良いんだと悩んでいる人がいると思います。まずなんとなく動くwebアプリケーションを作るなら、Next.jsがおすすめです。理由は多くのユーザーがいて、チュートリアルも充実しているため、深く理解していなくてもある程度のものが作れることが期待できるためです。
Discussion