世界一わかりやすいクリーンアーキテクチャ - 技術レイヤー分割より大切なモノ
本記事は、株式会社ハイヤールーさん主催のRe:TechTalk 世界一わかりやすいクリーンアーキテクチャ - 技術レイヤー分割より大切なモノの発表の登壇原稿となります。
本稿のサンプルコード・PPTはこちらで公開しています。 「CC BY-SA 4.0」で公開していますので、気に入っていただけたら営利目的含め、ライセンスの範囲で自由に利用していただいて問題ありません。
はじめに
まず初めに、クリーンアーキテクチャの誤解されがちな二つのことについてお話させていただきます。
その上で、クリーンアーキテクチャの本質とは何か?押さえておくべき、本当に重要だと考えている三つの事について、お話しします。
注意事項
さて本題に入る前に、少し注意事項があります。
今回お話しするのは、あくまで私の解釈です。
特に極端に要約しているので、今日お話しすることがすべてではないことはご理解ください。また明確に書籍に書かれているわけではないですが、拡大気味に解釈している箇所もありますし、書籍の記載とやや異なる説明もします。
それでも私は著者が本当に言いたかったこと、クリーンアーキテクチャでもっとも大切なことは今日お話しする三点にあると考えています。
なお異論・反論は大歓迎です。ぜひ議論させていただけると嬉しいです。
誤解されがちな二つのこと
この図をご覧になったことのある方は多いんじゃないかと思います。

実はこの図が良くできてい過ぎることが、二つの、大きな誤解を招く要因になっていると私は考えています。
この図の何がそんなに誤解を生んでいるのでしょうか?

ひとつは、この図は決してソフトウェアの関心をControllerやUseCase、Entityに分離しろという意味でもなく、レイヤーをこの4つに分割しろという意味ではないということです。

そしてふたつ目は右下のこれです。
これはデータや処理の流れを一方通行にしろという意味ではないですし、Presentationを古典的なMVCのように設計しろと言っている訳でもありません。
では、どういう意味でしょうか?

この図で本当に大切なことは、依存性は外から中だけに向かっていなくてはいけない。
というたった一点にあります。
では、例えばEntitiesの状態が変わったことで、UIを受動的に変化させたい、といった中から外を呼ばなければいけないときはどうすれば良いのでしょうか?という疑問が、すぐに湧いてきますよね?

右下の図は、内側の変化に応じて外側を呼び出したい場合に、依存性は外から中に向けたまま、処理の流れとして中から外に戻すにはどうすればよいのか?を例示しているものです。
そんなこと言っても、本当に合っているのか?って、今皆さん思いましたよね?
はい。もちろん根拠があっての話です。

Clean Architectureが発表された当時、Hexagonal ArchitectureやOnion Architectureといったアーキテクチャが非常に注目されていました。
そしてこれらのアーキテクチャには類似点が多いことも認識されていました。
Clean Architectureの最初のブログの記事に記載された、あの図は、それらのアーキテクチャを汎化し、単一のモデルに統合できることを例示したものにすぎません。

書籍を読めば、ちゃんと先の図があくまで例示であると書かれています。

つまり、本当にすべてのソフトウェアが同一のアーキテクチャに帰結するとすれば
- レイヤーが4つ限定であったり
- UIがMVC的でMVVMなどを否定していたり
- そもそもWeb限定だったり
- 中から外の呼び出しがApplicationレイヤーとInterface Adapterレイヤーの間だけで発生する
なんてことはないですよね?

あの図は、複数の著名なアーキテクチャを単一のアイデアに統合できることを例示するために書かれた、Clean Architectureを採用したソフトウェアの具体例の一つにすぎません。
そもそも著者は書籍の冒頭でこう明言しています。

「アーキテクチャのルールはどれも同じである!」
日本語版では帯にも書かれていますよね。
誤解を恐れずに言えば、あの図の構成要素には本質的な価値はありません。
本当に価値があるのは、あの図が実現しようとした目的、そこに至った背景、そしてそれを実現する手段です。

なお目的とは、フレームワーク非依存・テスト可能・UI非依存・データベース非依存・外部エージェント非依存などを実現することだと、説明されています。
この書籍は、それらの目的・背景・手段が凝縮されている名著だと私は信じています。
おさえるべき三つのこと
では先の図のように実装することがクリーンアーキテクチャではないとしたら、クリーンアーキテクチャについて何を押さえたらよいのでしょうか?
私は次の三つこそ、本質的に重要なことだと考えています。

ひとつめは先ほども話しました。
ソフトウェアは、より上位レベルの方針にのみ依存せよということ。
ふたつ目は、ひとつめを実現するために、依存性を制御の流れから分離してコントロールする必要があるということ
そして最後に、「上位レベル」とは相対的かつ再帰的であることに留意する必要がある。ということです。
さあ具体例を見てみよう!
てことで、ここからは具体例を見ながら解説したいと思います。
具体例はC#で記述されたコンソールアプリケーションを例にお話しします。

対象のアプリケーションは、位置情報から周囲の店舗を検索するコンソールアプリケーションHatPepperです。
店舗の検索にはリクルートさんのグルメサーチAPIを使わせていただいています。もう10年以上、ことあるごとに利用させていただいています。
調べたらAPI自体は15年前から存在しているようです。変わらず利用できることで、発表内容が陳腐化せずに済んでいます。
本当に感謝です。
という訳で、コードを見てみましょう
Layered Architecture
さて、コードだけでは理解しにくいため、図でも見てみましょう。

全体は大きくPresentation、Application、Gatewayの三つに分割されています。
Gatewayには、外部のWebサービスを利用するAPI・デバイスから位置情報を取得するコンポーネントが含まれています。

それぞれのコンポーネントにはこちらのようなクラスが含まれています。
で、さっきはコンポーネント図をお見せしたんですが、実際はこの辺の依存関係がごちゃごちゃしていて・・・

こんな依存関係になっています。
で実行時はどうなっているかというと・・・

こんな感じで動作します。
アプリケーションのエントリーポイントであるBootstrapのProgramクラスからControllerが呼び出されるところから、スタートしています。
ControllerはApplicationレイヤーのSearchRestarurantを呼び出して近隣のレストランを取得します。
SearchRestaurantは、GeoCordinatorから現在位置を取得して、GurmetSearviceから近隣のレストランを取得します。
そしてControllerまでもどって、取得したレストラン情報をViewに渡して画面表示して終了です。
一見、そんなに悪くないように見えますよね。しかし実際には大きな問題を含んでいます。
では一体、何が悪いのでしょうか?

それは安定度と柔軟性のバランス配分です。
このレイヤーモデルでは、柔軟性と安定度は、こちらの図のような配分になっています。
ApplicationとGatewayの柔軟性と安定度の配分に問題があります。
なぜこのような配分になって、何が問題なのでしょうか?
それを理解するためには、依存関係による安定度と柔軟性のトレードオフを理解する必要があります。
依存関係による安定度と柔軟性のトレードオフ

依存関係にあるオブジェクトがあったとします。
オブジェクトはクラスでもいいですし、コンポーネントでもいいですし、なんならサブシステムでも構いません。
それぞれを変更することを考えてみると、理解できます。

まずは依存される側を変更することを考えてみましょう。依存される側を変更すると、

依存する側は、何らかの影響を受けます。
従って、依存する側は、依存される側より安定度が低くなります。自明の理ですよね。
逆に

依存する側を変更しても依存される側には影響を与えず、依存先を考慮せず、自由に変更できることから、依存する側の柔軟性は、相対的に高くなります。
そうです。
依存関係にあるオブジェクトの間の安定度と柔軟性は、どうしてもトレードオフの関係が発生します。
さて、これを逆説的に考えると

変更頻度の高いオブジェクトは、依存する側として、関係性を設計すべきですし

アプリケーションの本質的な価値を提供する「上位レベル」のオブジェクトは、軽微な変更の影響を受けないよう、依存される側として設計すべきです。
先ほどのモデルを振り返ってみましょう。

全体として依存の方向は、上から下へと統一されています。
さて、これらの構成要素の中でもっとも柔軟性が大切なのは、どこでしょうか?

それは間違いなく、HotPepperのAPIを呼び出している個所でしょう。
外部サービスが変更されても、アプリケーション全体には影響をあたえず、API呼び出し個所を自由に修正できる柔軟性が、このアプリケーションでは大切です。
その結果、アプリケーションに影響を与えずに、Web APIの変更をGatewayで吸収できます。
しかし実際には、Gatewayはもっとも柔軟性が低くなっています。
また、アプリケーションの本質的な価値は何でしょうか?
それは、これが開発されることになった背景に立ち戻ればはっきりします。

これら、アプリケーションを開発する目的、つまり「位置情報から周辺の店舗を検索すること」がこのアプリケーションの本質的な価値となるでしょう。
ビジネスロジックこそがアプリケーションの本質です。

そしてその価値を提供しているのはApplicationレイヤーです。
したがってApplicationレイヤーは、ほかの枝葉の変更に引きずられてはならず、高い安定度となるように設計されなくてはなりません。
Gatewayの柔軟性が低い事と、Applicationの安定度が低いことが、このモデルの問題点になります。

このようなバランスになっているのは、依存が上から下へ一方になっていることが要因となっています。
依存性は、より上位レベルの方針にのみ向けよ
依存性は、より本質的な価値を提供する部分。
つまり、より上位レベルの方針に向ける必要があるのです。

具体的には、依存関係をこのようになるよう設計する必要があります。
でもそれは実現可能なのでしょうか?

制御の向きはどうしても上から下にならざるを得ないなか、それと反する依存方向に設計する必要があります。
つまり、制御の流れと依存関係を分離する必要があるのです。
制御の流れと依存関係の分離

一般的に依存方向は制御の流れに引っ張られがちです。
しかし、これらは分離してコントロールすることが可能です。

そのためには二つの依存関係の間のコントラクト、つまり契約・仕様・お約束を文脈によって制御する必要があります。
まず、抽象的なコントラクト、契約ぶっちゃけインターフェースですね。
抽象的なインターフェースを導出することで、それぞれの具象概念をどちらも抽象概念であるコントラクトに依存させます。
そしてこのコントラクトをどちらの文脈で定義するかによって、具象概念間の依存関係をコントロールします。

具体的には、コントラクトをサーバー側の文脈で規定したとします。
すると、文脈単位でみると、クライアントがサーバーに依存している構造になりますし

逆にクライアントの文脈で規定すれば、サーバーがクライアントへ依存している構造となります。

つまり依存性逆転の原則を適用するということです。
具体例に戻りましょう。

全てを見ると、ちょっと分かりにくいので今回はApplicationとHotPepperの関係に着目してみます。

これらのクラスのうち、ここの依存関係にフォーカスします。

具体的にはApplicationがWebサービスを利用するための呼び出しです。

これのGourmetSearchResultという検索結果オブジェクトと、GurmetSearviceのFindNearbyAsync関数のシグニチャーこそが、まさにコントラクトになります。
この構造には二つの問題があります。
- コントラクトがGateway側に定義されていること
- コントラクトがWebサービスの文脈で記述されていること

ホットペッパーのAPIを呼び出すと、このようなJSONが返却されます。
GourmetServiceの戻り値となるGrourmetSearchResultクラスは、このJSONの形状のままです。
つまりApplication全体がWebサービスに依存してしまっているのです。
ではどうすれば、よいでしょうか?

現在、Applicationとinfrastructureの間のコントラクトはGatewayの文脈で記述されています。
このコントラクトをApplicationの文脈で再定義します。

つまり、ここの依存関係を断ち切ります。
ということで、設計を見直してみましょう。

GourmetSearchResultは、Gatewayに押し込んで、アプリケーション全体からはアプリに必要な情報だけをもつ、アプリケーションの文脈で設計されたRestaurantクラスを追加しましょう。

そして、GourmetSearchResultへの依存を排除し

各コンポーネントはRestaurantオブジェクトに依存するように設計を変更します。これによってAPIの関心を分離します。
さて、ここで一つの課題が生まれます。

ApplicationとHotPepperが循環参照してしまいました。
どうしましょう?ってことでこうします。

GourmetSearviceのインターフェースを導出して、Application側に配置します。
ただ、このままだとまだ

ただ、Locationのせいで、ApplicationからGatewayへの依存が排除しきれていません。
ということで、HotPepper側と同じ対応をします。
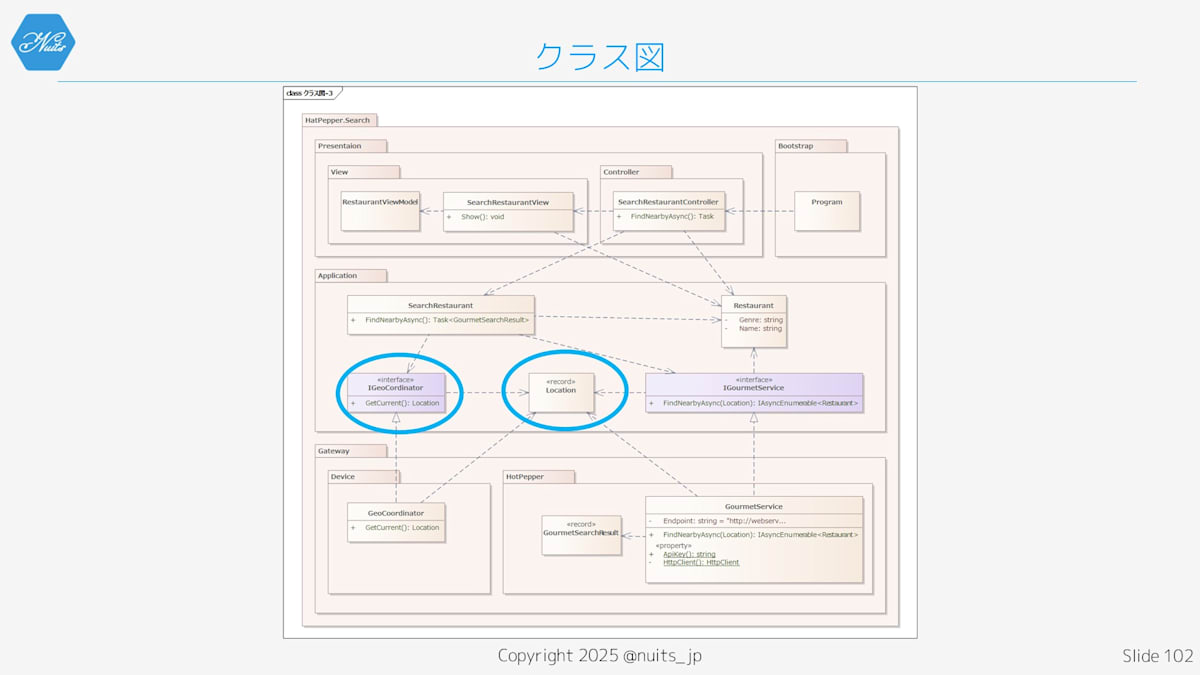
インターフェースを抽出し、LocationもApplicationに持ってきましょう。

これで、制御の方向と依存方向が狙った通りになったはずです。
ただ本当に実装できるの?

ってことで、リファクタリングしてみましょう!
・・・
さて無事、この実装は実現できましたということで資料に戻りましょう。

実装を見ていて気が付かれたかと思いますが、依存関係の解決をBootstrapに集中させたことで、こんな依存関係になっています。
ロジックの中に、依存関係の解決を混ぜると、すぐに依存と制御の方向があやしくなってきます。
依存関係の解決は、ロジックを含まないエントリーポイントを設けて、すべて集中させることを個人的には好んでいます。
さて、その結果・・・

制御の流れと依存関係を分離することができ、柔軟性と安定度を任意のバランスにコントロールすることができました。
できましたが・・・

この部分、実際のアプリケーションになると、大きく複雑になりがちです。
今回は近隣店舗の検索のユースケースしかありませんでしたが、実際にはほかのユースケースも含まれてくるでしょう。
この分はユースケース固有の概念と、システム全体に共通する概念を分離して整理したいです。

ということで、こう、アプリケーションからドメインを分離しましょう。
またRestaurantは、ドメイン駆動設計でいうところのEntityであり、集約です。なのでIGourmetServiceは・・・

こんな感じで、Restaurantのリポジトリーとして定義・実装するのを個人的には好んでいます。
ということで、

出来上がったコンポーネントの関係がこうなりました。綺麗に整理されましたね?
そしてこれを同心円状に並べ直すと・・・

あら不思議、どこかで見たようなモデルになりましたね。依存関係は外から中に統一されていることが見て取れます。
一部同一レイヤーへの依存が見てとれますが、これは許容することにします。気に入らなければ、緑とオレンジの間にもう一層追加してそこに書いたらいいんじゃないでしょうか?レイヤー数はべつに限定されないので、満足いくように設計したらいいと思います。
思いますが・・・
実際にはコンポーネント数はこんなもんじゃ絶対にすまないので、私はこういう図を書くことはあきらめています。
参考までに、現在開発しているプロダクトではコンポーネント数が158個あります。こういった図を描いても、理解の助けにならないので、普段は書いたりしていません。

というわけで、依存性は上位レベルの方針のみに向ける必要があり、そのためには、制御の流れと依存方向を分離、コントロールしなくてはならないということに、共感いただけたのではないかと思います。
視点を上げてみよう
さて、ここまで技術レイヤーのお話をしてきました。
でも今日の副題は、「技術レイヤー分割より大切なこと」でしたよね?
というわけで、ここで視点を少しあげてみましょう。
ここまで作ってきたアプリケーションは、近隣のレストランを検索するだけのものでした。ただ実際にはそんな小さいアプリケーションはそうないですし、そんな小さなアプリケーションには、クリーンアーキテクチャなんて大それたアーキテクチャーは必要ないでしょう。

そこでもう少し大きなシステムを想定してみましょう。
例えば、店舗を検索するだけでなく、お店の予約まで含めた予約サイトをドメイン駆動設計を活用して、構築することを想定します。
検索と予約だけだと、十分に大きいとは言いかねますが、本当に大きくすると説明しきれません。なのでそこは、みなさんの想像力を膨らませてください。

さて、検索して予約できるシステムとすると、システム全体、ドメインはたとえば「検索」と「予約」の二つのサブドメインに分割されるかもしれません。
それ以外のサポートサブドメインも登場してきます。認証・認可とか。

検索と予約のサブドメインは、一枚岩で作られるなんてことはないでしょう。
ここまでしつこく繰り返してきたように、外部のWeb APIへの依存は分離したいので、サブドメインは複数の「境界付けられたコンテキスト」にします。
境界付けられたコンテキスト、「bounded context」はドメイン駆動設計の用語です。
検索サブドメインは、アプリの本質である検索アプリと、HotPepper APIの変更を吸収する腐敗防止層としての検索Gatewayに分割するはずです。
もちろん予約サブドメインも同様です。

検索した店舗から予約するとすると、その間には共通の語彙があるはずです。
少なくとも店舗IDなんかは共通の語彙、Value Objectとして登場しないと検索結果から選ばれたレストランを予約サブドメインに知らせる事ができません。
となると汎用のドメインにそれらを定義するコンテキストが登場するはずです。

また、検索と予約のそれぞれの機能を制御するオーケストレーションを担うコンテキストもあるでしょうし

全体の依存関係を管理するBootstrapも必要です。

これでアプリケーションはBootstrapから起動され、オーケストレーターからアプリを呼び出し、Gatewayを経由して取得されたHotPepperの情報を利用して動作します。
実際にWebアプリケーションであれば、フロントエンドとバックエンドのコンテキストも分けるでしょうし、こちらはあくまで単純なシステムの一例だと思ってください。
ただ、ここから感じていただけた事があるかとおもいます。
上位レベルとは相対的・再帰的であることに留意せよ
そうです。ここで3つ目の大切なこと。
「上位レベル」というのは相対的かつ再帰的であり、それに留意する必要があるということです。

実際、この部分はまさに依存性逆転の原則そのものですよね。
そもそもソフトウェアは良くフラクタルのようだと言われていますよね。

複数の技術レイヤーがまとまって境界付けられたコンテキストを構成し

境界付けられたコンテキストがまとまってサブドメインになります。そして

サブドメインとサブドメインがまとまってドメインになります。

ここではこれらを、ソフトウェア オブジェクトと呼ぶことにしましょう。
ソフトウェアオブジェクトのすべてにおいて、ここまでした話の内容は適用できます。複数のシステム間であっても同様です。
もちろんシステム間は例えばWeb APIになったり、なんならCSVをFTPで連携するなんてこともあるでしょう。
ただ、どの要素間であっても、コントラクトの文脈を管理する事で、制御の流れと依存関係は制御することが可能です。

アーキテクチャ設計というと技術的なレイヤーばかり着目されがちですが

それより大切なものがある事が理解いただけたのではないでしょうか?

実際、右側の同心円のモデルは、一つのサブドメインの内部設計にすぎないからです。

「アーキテクチャのルールはどれも同じである」
という真意が何となく伝わってきたのではないでしょうか?
What is Software Architecture?
さて、ここまではどちらかというと、ボトムアップ的なアプローチで説明してきました。
ここからは少し、トップダウン的なアプローチでお話してみたいと思います。
なおここからはクリーンアーキテクチャの書籍に書かれてる内容だったり世間の共通見解だったりするわけではなく、私個人の私見が多くなります。
私はそう考えてるというお話であることにご注意ください。
さて、そもそもアーキテクチャ、ここではソフトウェアアーキテクチャですね。
ソフトウェアアーキテクチャとは何なんでしょうか?

Webや書籍上でよく見かける、ソフトウェア アーキテクチャというとたとえばこのあたりが該当するように思います。
これらは類型的なソフトウェアアーキテクチャのパターン群です。
ただし特定領域のパターンであって、ソフトウェアアーキテクチャの全てではありません。
では、ソフトウェアアーキテクチャとは何か?ドン!

うん、良く分からん。別の意見を見てみましょう。
多分、世界的なアーキテクトの第一人者を10人上げろと言われると、多くの方がそのうちの一人として、マーティン ファウラー氏をあげるのではないかと思います。
彼はこう言っています。

ふむ。
ちなみにWikipediaには、こんなことが書かれています。

そう、厳密で共通認識の定義は存在しないんですね。
みんな気軽にアーキテクチャ・アーキテクトと言いますが定義はあいまいなんです。
とは言え、おおよその共通認識はもちろんあります。

まずソフトウェアアーキテクチャとは、システムアーキテクチャのうち、ソフトウェア領域のアーキテクチャを指します。
本来システムというのは、制度や組織などのことを指すので、システムアーキテクチャと言った場合、ソフトウェア外も含めて語られることもあります。
実際、最近私は、システム設計の最上位ドキュメントには、システム外部の活動も含めたビジネスを定義するようにしています。
ただ今回はソフトウェアアーキテクチャについてです。

そしてソフトウェアアーキテクチャとは、ソフトウェア構築における重要な決定事項の全てを指します。
その中でもどう分割し、どう結合・相互作用するかが、特に重要です。

またソフトウェアアーキテクチャとを構築すする目的とは
- システムの実現をサポートする
- 持続可能なソフトウェアを
- バランス良く構築する為
だと、私は考えています。
最後のバランスとは、QCDだと私は考えています。
特にアーキテクチャは非機能要求からも、おおきな影響をうける傾向が強いと言われています。

そしてクリーンアーキテクチャによると、アーキテクチャは、これらのものを与えてくれます。
個人的にはこれは少しスコープが狭いかなとは思っています。
Clean Architectureを考えるうえで重要なポイント
さて、アーキテクチャが仮に先のようなものだとしたとき、Clean Architectureを考える上で重要なポイントがあります。

それはこのどう分割・結合し、どう相互作用させるか?
という点です。

そして、これらを実現するために最も重要となる、ソフトウェアアーキテクチャ3種の神器があります。
それが

関心の分離、疎結合、依存性逆転の原則だと、私は考えています。
整理してみましょう。

なんらかの大きな目的を表す上位の関心があったとします。
この時、現代のソフトウェア開発の現場では、これをそのまま、モノリシックなソフトウェアとして開発したりしませんよね?
まずは粒度の小さい、個別の関心に分離します。
これが関心の分離です。
このとき関心が何か?は、このとき皆さんに見えているスコープによって異なります。

上位の関心がドメインであれば、個別の関心はサブドメインかもしれませんし、上位の関心がサブドメインであれば、個別の関心は境界付けられたコンテキストでしょう。
ただ実際にはこんな単純に分離できない事もあると思っていて、これらとは全く軸の異なる、直行した関心も登場しがちです。非機能なんかはありがちですね。
これらを「うまいことやる」のがアーキテクトの仕事です。
話を戻しましょう。

さて、分離した関心は、それ単独では上位の関心を満たせません。
そのため、関心は再度結合する必要があります。そこで重要なのが疎結合ですよね。
せっかく関心を分離しても、密結合してしまってはありがたみが半減してしまいます。
ただ、本当の意味での疎結合を実現するためにはもう一つの概念が必要です。

そう。依存性逆転の原則です。
ここまでお付き合いいただいた皆さんは、もうご理解されていることでしょう。
結合は疎であるだけではなく、その結合時の依存関係を適切にコントロールすることで、より効果が高まります。
そのためには、制御の流れにとらわれず、依存方向を分離し、設計する必要があります。
そうすることで、上位の安定度と、下位の柔軟性を高めます。
What is Clean Architecture?
ではクリーンアーキテクチャとはなんでしょう?
私は次のように解釈しています。

クリーンアーキテクチャというのは、ソフトウェアアーキテクチャの3種の神器を適用した、リファレンスアーキテクチャのひとつだと私は解釈しています。
まとめ
とうわけで、今日のお話は終わりになります。
最後に簡単にまとめましょう。
クリーンアーキテクチャは、どんなソフトウェアにも適用可能な普遍的なアーキテクチャです

クリーンアーキテクチャは3種の神器を適用した、リファレンスアーキテクチャのひとつです。

ソフトウェアアーキテクチャ3種の神器とは、関心の分離・疎結合・依存性逆転の原則だと、私は考えています。

クリーンアーキテクチャの本当に大切なことが三つあると私は考えています。
ひとつは、依存性はより上位レベルの方針、つまりオニオンアーキテクチャであれば外から中にだけ依存するべきであること
ふたつめは、制御の流れと依存方向は分離してコントロールしなさいということ。
そして最後に、上位レベルというのは、相対的・再帰的なものであるということです。

参考の図のとおりに関心を分離することや、データや処理の流れを一方通行にせよ、ということがクリーンアーキテクチャではありません。

クリーンアーキテクチャの本質的な価値とは、この図が実現しようとした目的、そこに至った背景、そしてそれを実現する手段にあります。
と、著者がなんと言おうと、この解釈だからこそクリーンアーキテクチャには価値がありますし

この書籍は、そのための手段を広く紹介している、名著だと私は信じています。
というわけで

みなさん
「クリーンアーキテクチャチョットデキル」
ようになりましたね?
Discussion
すごく良い記事だと思うのですが、画像が表示されていないです‥