なぜDependency Injectionなのか? ~関心の分離と疎結合~
本稿は「アーキテクチャを突き詰める Online Conference」における発表「なぜDependency Injectionなのか? ~関心の分離と疎結合~」の登壇原稿となります。
発表時の動画アーカイブは後日公開されたタイミングでリンクを追加いたします。
また、本稿のサンプルコードとPower PointはGitHubで公開しています。 「CC BY-SA 4.0」で公開していますので、気に入っていただけたら営利目的含め、ライセンスの範囲で自由に利用していただいて問題ありません。
というわけで、本稿の目指すゴールはこちら。

今日は、この場にいる皆さんが「なぜDependency Injectionを利用するのか?」ということを、理解いただくのが本日のゴールとなります。
というわけで本題に入りましょう。まずは改めて、DIとはなにか?少し振り返ってみたいと思います。

Dependency Injection、通称DIとはオブジェクトの依存関係を外部から注入する設計パターンです。そのため、自らオブジェクトを生成せずに、外部から注入してもらって利用します。
これによって疎結合やモジュール性、テスト容易性や保守性が得られると、一般的に考えられています。

DIは、Inversion of Control、制御の反転の概念が登場し、それまでソフトウェアの再利用がライブラリ形式に限られていたところに、フレームワークの概念が登場、普及してきたことが発端の一つだと思います。当初はDIという概念はなく、サービスロケーターパターンが利用されていました。
その後、ラルフ・ジョンソンらが、論文で提唱したのが初出だと思いますが、③2000年初頭にIoCの実現手段としてDIが注目されはじめたように思います。
ただ、爆発的に普及したのは2004年にマーティン・ファウラーが「Inversion of Control Containers and the Dependency Injection pattern」という文献を発表したことが大きな切っ掛けだった、という認識です。

初期のDIコンテナーといえば、Spring Frameworkや、Googleのジュース、MicrosoftのUnityなんかが著名だと思います。

近年では、多様なフレームワークが、DI前提に設計されていたりもします。
すでに当たり前となったDIですが、たぶん誰でも一度は、こう思ったことがあるのではないかと思います。

「DIってわかりにくくね?」ということです。
私も20年くらい前にDIに触れたときに全く同じことを思いました。
あれから20年。毎年、どこかでDI不要論が唱えられ続け、なんならXで毎年違う人が炎上しているのを見かけます。
なぜなのか?本稿はその理由について、深堀していきたいと思います。
というわけで、本日のセッションの概略です。

目的はもちろん、なぜDIを利用するのか?理解することです。
そのため、実際の良いとは言えないコードから、よりよいコードにリファクタリングしながら、DIが何を解決してくれるのか?見ていただきます。
その上で、それを解決するための別の手法を紹介した後、なぜ現在もDIが使われ続けているのか?私の考えをお伝えしたいと思います。
てことで、ここからは具体なコードを見ながら解説したいと思います・・・の、まえに。
どんなアプリケーションなのか、簡単に説明しておきます。
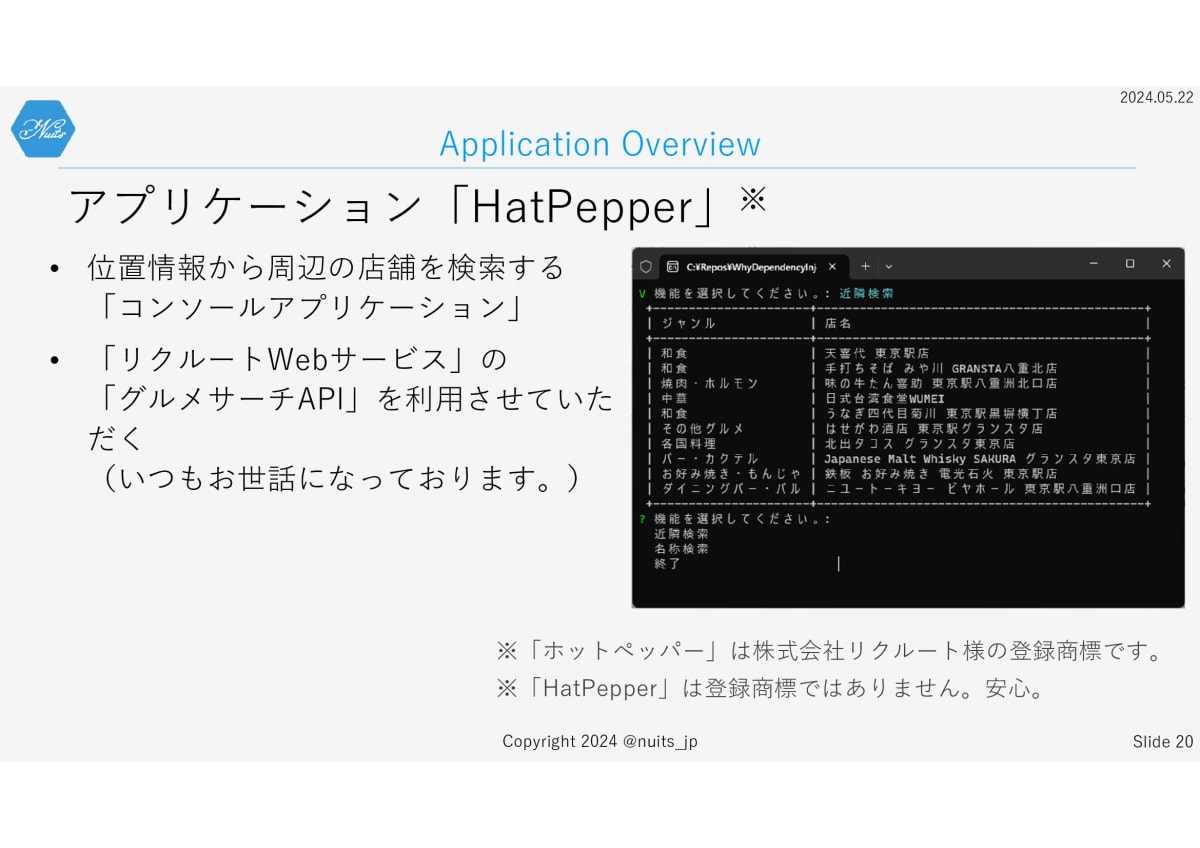
対象のアプリケーションは、位置情報から周囲の店舗を検索するコンソールアプリケーション、HatPepperです。
店舗の検索にはリクルートさんのグルメサーチAPIを使わせていただいています。もう5年以上、ことあるごとに利用させていただいています。本当に感謝です。
という訳で、コードを見てみましょう
【ここでコードを見ます。動画閲覧推奨】
ちょっとコードだと全体像が分かりにくいと思いますので、図にしてみました。
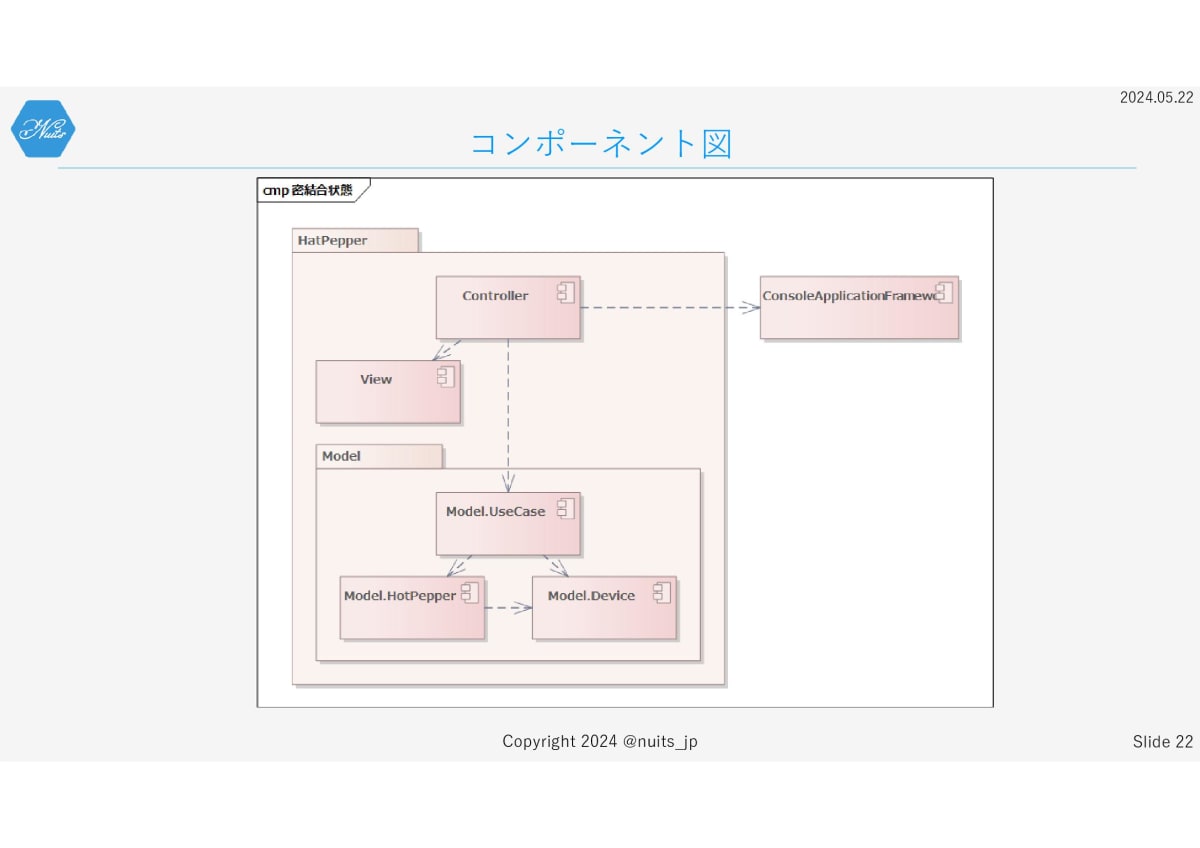
ざっくりこんな風に作ったつもりで、基本はMVCパターンです。ModelはVとC以外全部という定義です。
なので、ビジネスロジックを表すユースケースと、Web PAIを呼び出すHot Pepperコンポーネント、デバイスの位置情報を取得するためのDeviceコンポーネントが存在します。
ただ、実際にはこんなにきれいになっていません。
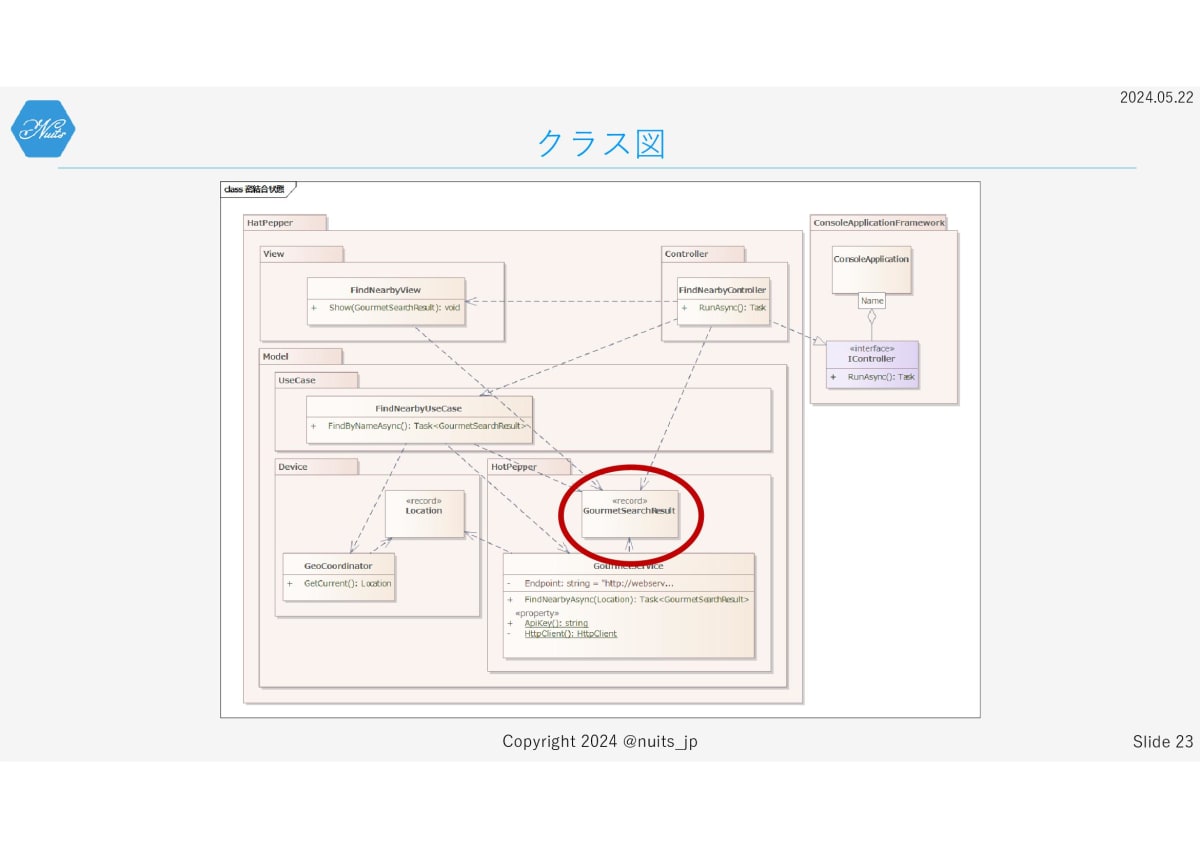
というのは、この部分のGourmetSearchResult、検索結果ですね。これにMVCほぼ全部が依存してしまっています。
これの何が良くないかというと、ホットペッパーさん側のAPI変更があると、アプリケーション全体が影響を受けてしまうという事です。
それはこのクラスが、ホットペッパーさんのWeb APIのメッセージフォーマットに完全一致していることに起因します。つまりホットペッパーAPIに対する関心が分離できていないんですね。
自分たちに管理できない領域の影響を、アプリケーション全体が受けてしまうことは避けるべきです。これは議論の余地がないでしょう。
そこで、GourmetSearchResultの代替として、アプリに必要な最低限の情報をもつRestaurantクラスを追加しましょう。
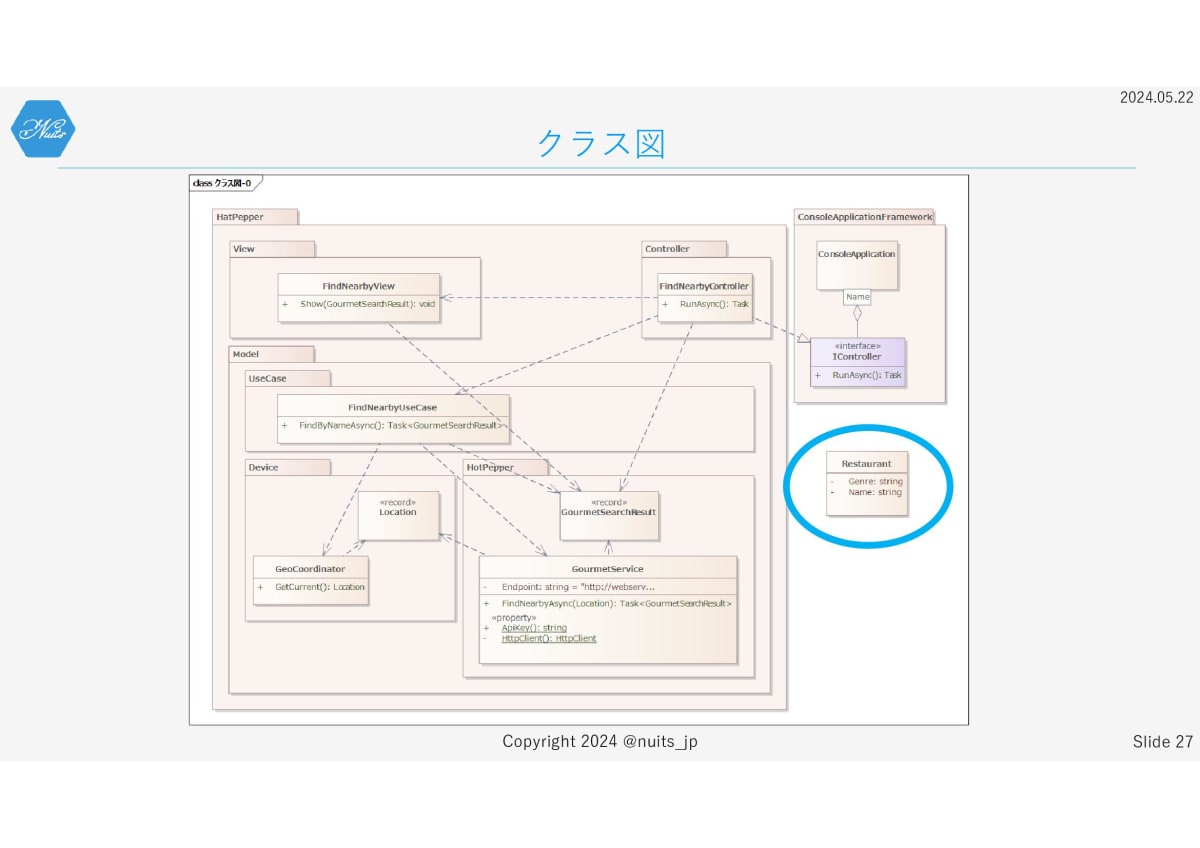
そして、GourmetSearchResultへの依存を排除し、各コンポーネントはRestaurantオブジェクトに依存するように設計を変更します。これによってAPIの関心を分離します。
さて、ここで一つの課題が生まれます。
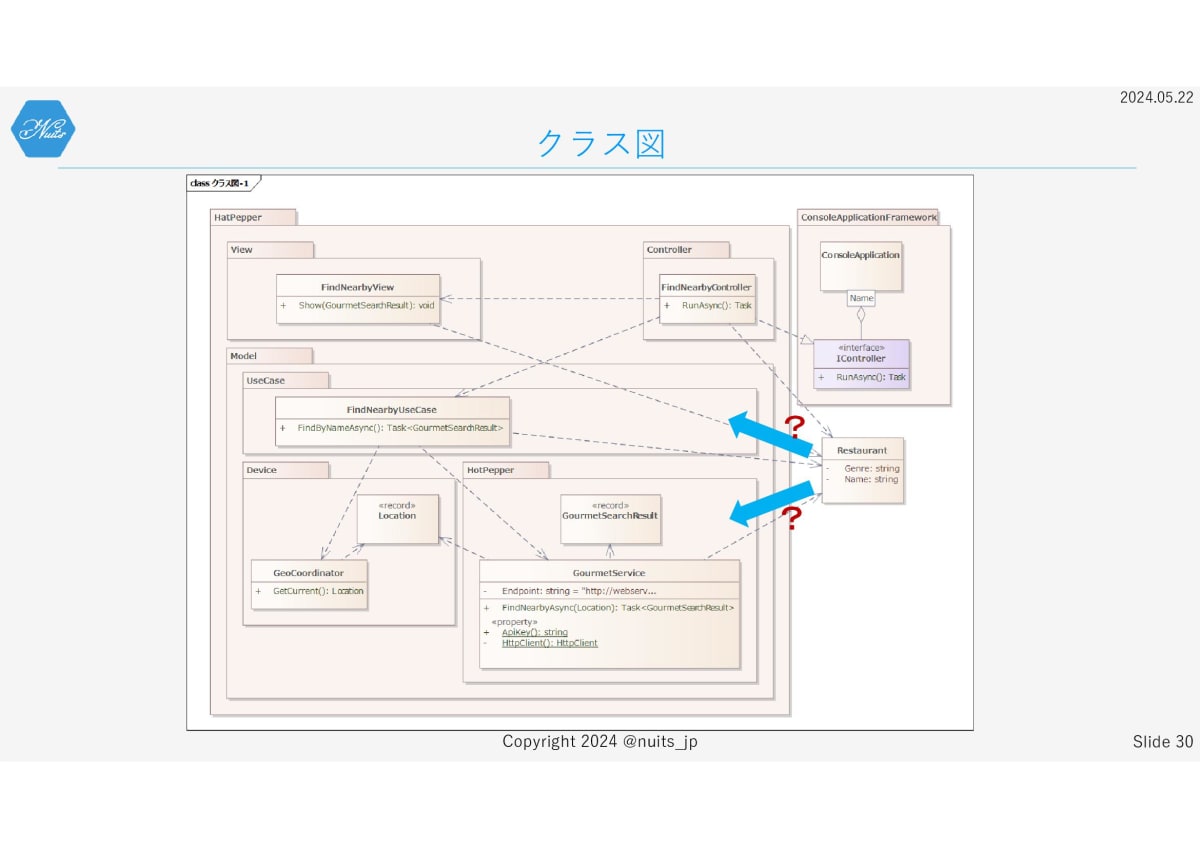
Restaurantはユースケース側に置くべきでしょうか?それともHot Pepper側に置くべきでしょうか?
それを判断するためには、依存関係による安定度と柔軟性のトレードオフを理解する必要があります。
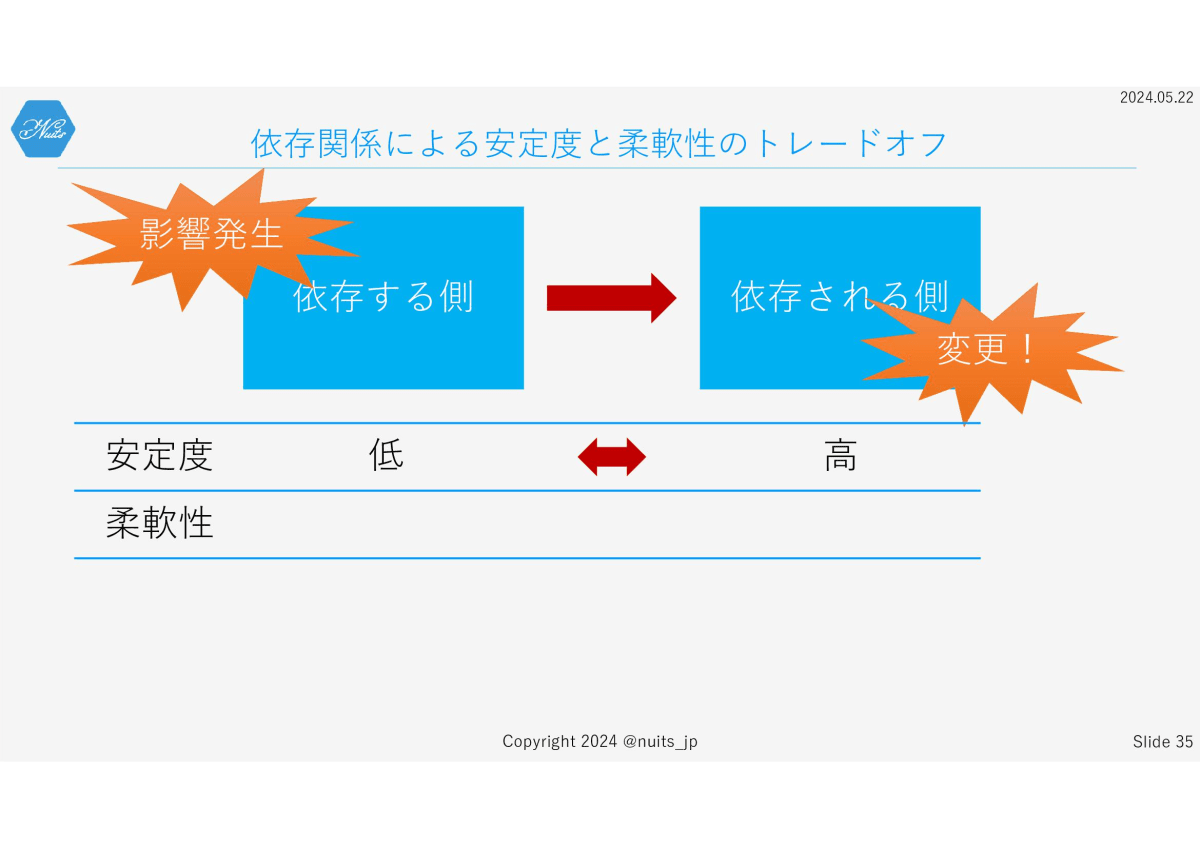
依存関係にあるオブジェクトがあったとします。オブジェクトはクラスでもいいですし、コンポーネントでもいいですし、サブシステムでも構いません。なんなら外部のシステムでも同じです。
それぞれを変更することを考えてみると、理解できます。まずは依存される側を変更することを考えてみましょう。
依存される側を変更すると、依存する側は、何らかの影響を受けます。従って、依存する側は、依存される側より安定度が低くなります。自明の理ですよね。
逆に
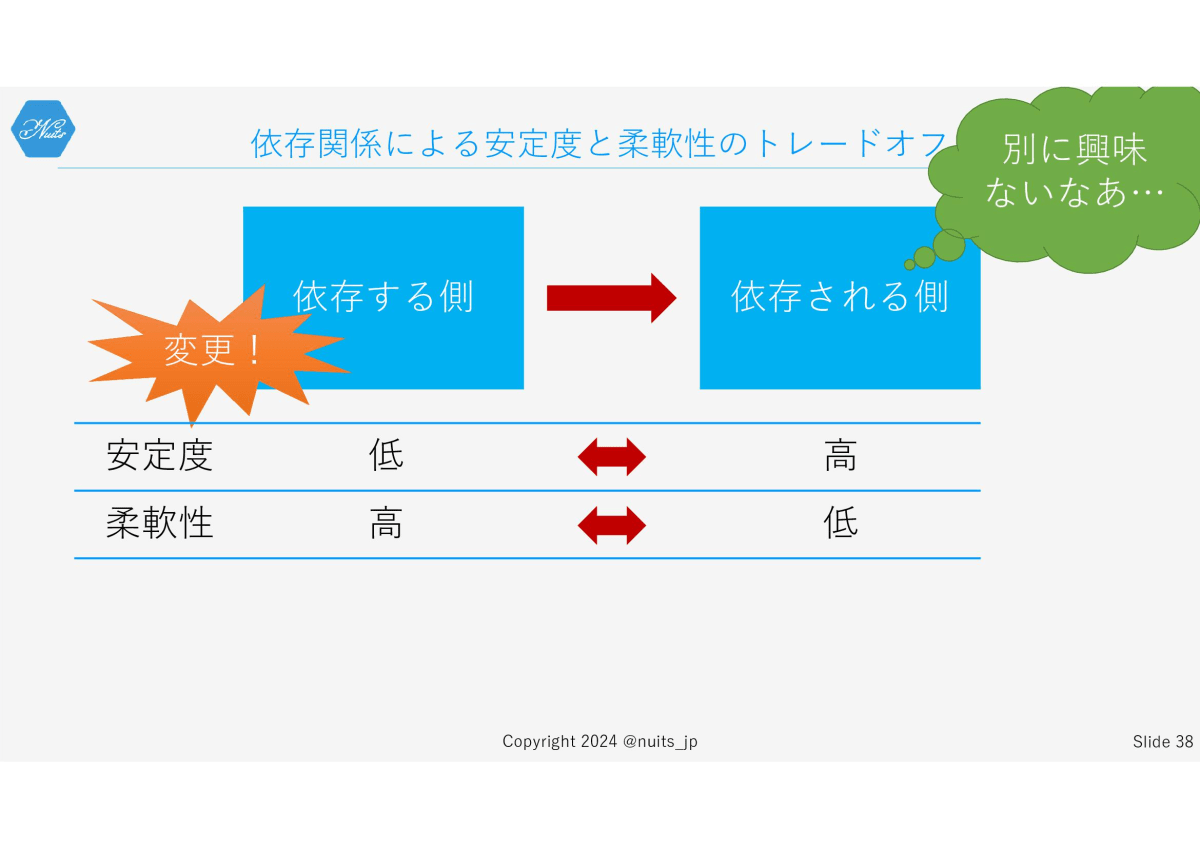
依存する側を変更しても、依存される側には影響を与えず、依存先を考慮せず自由に変更できることから、依存する側の柔軟性は相対的に高くなります。
そうです。
依存関係にあるオブジェクトの間の安定度と柔軟性は、どうしてもトレードオフの関係が発生します。
さて、これを逆説的に考えると
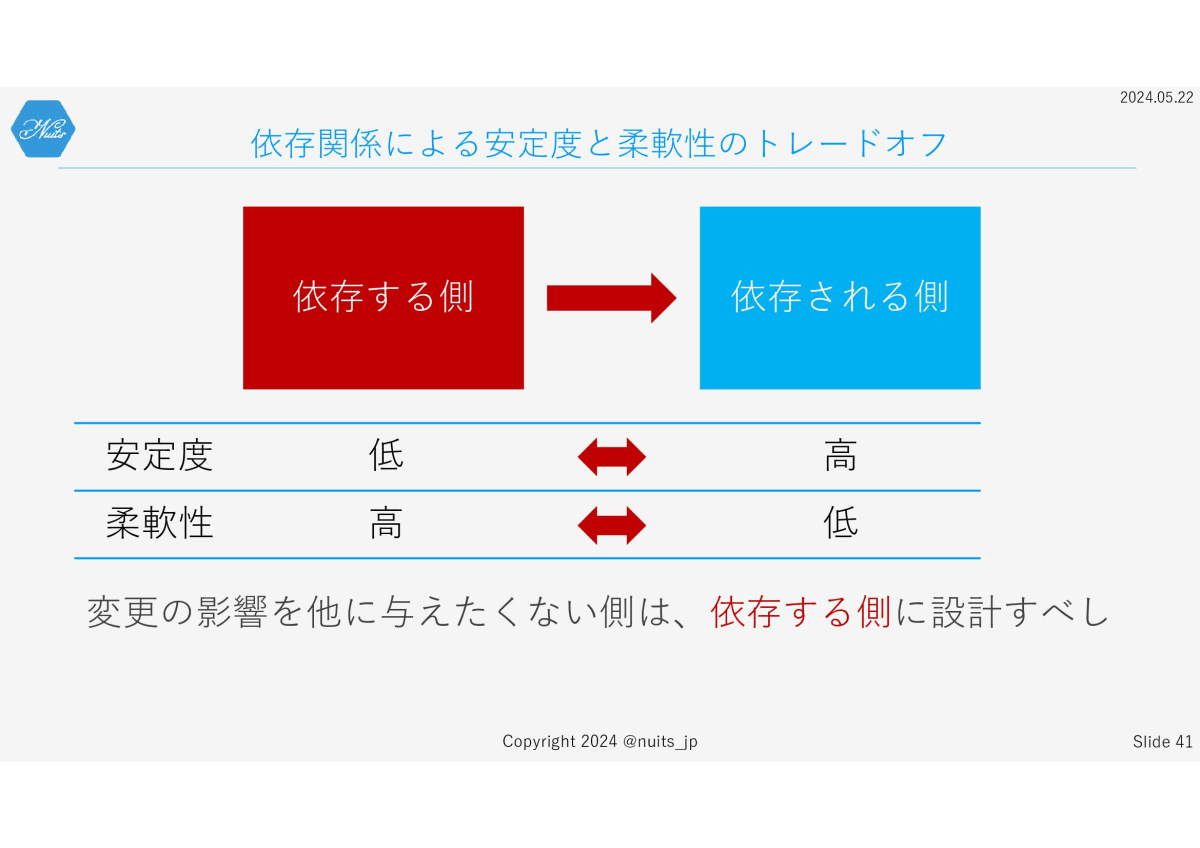
変更の影響を、ほかに与えたくない側は、依存する側に設計するべきで
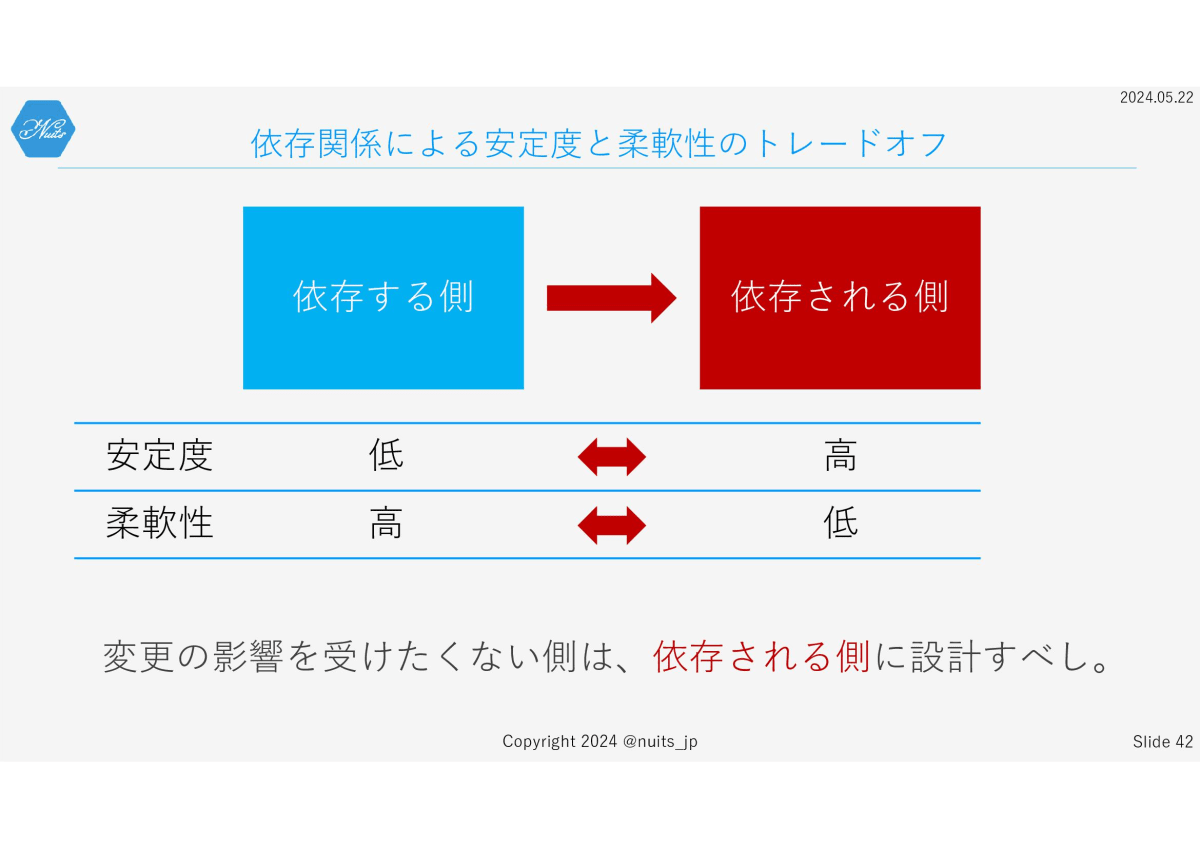
変更の影響を受けたくない側は、依存される側に設計すべきです
とうことで、先ほどのモデルを振り返ってみましょう。
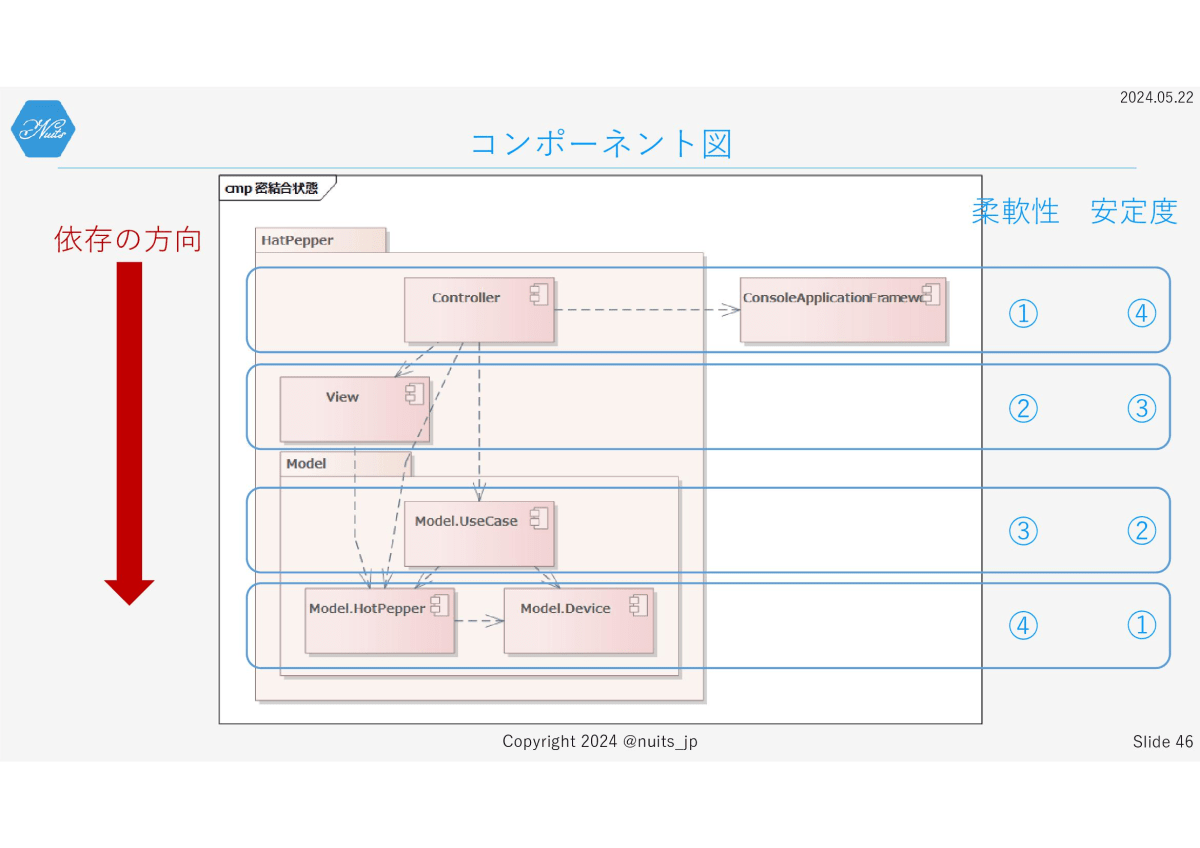
依存関係は、おおむね上から下に、こんな感じの関係になっているため、柔軟性と安定度はこんな感じになります。
で、良くないのがここです。
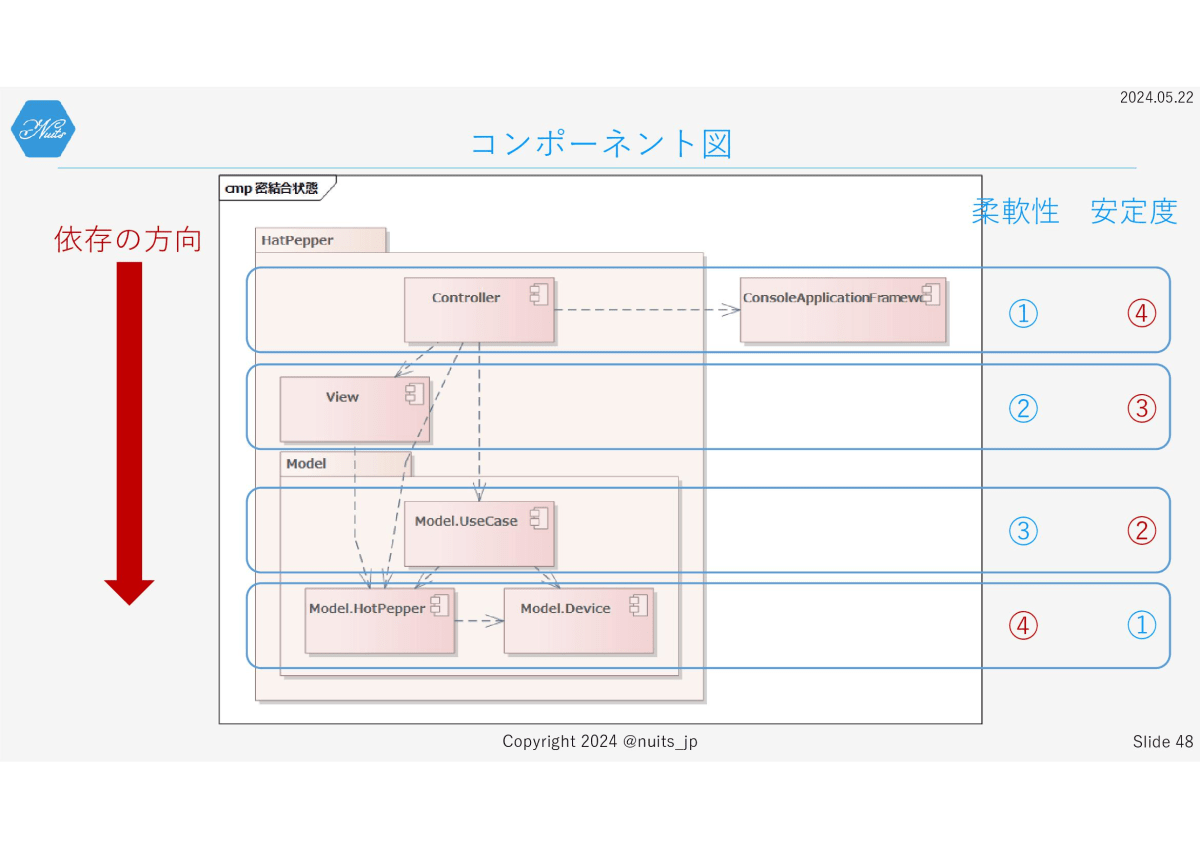
一番下の層の柔軟性が、一番引くくなっています。そのため結果的に他の層の安定度が下がってしまっています。
このバランスが現在の設計の問題点になります。このバランスを
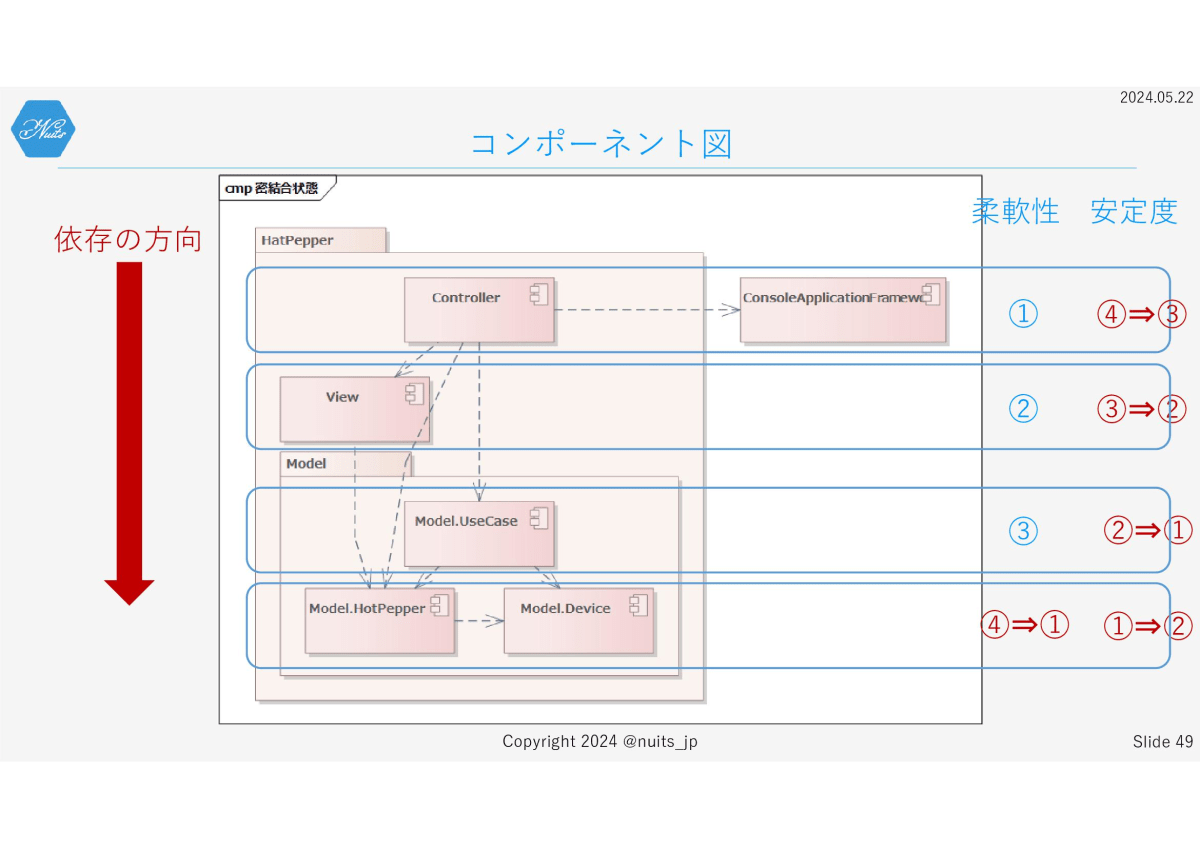
こうしたいです。
特にHotPepperコンポーネントの柔軟性を高めることで、Web APIに変更が入ることでHotPepperコンポーネントの修正が入っても、その影響をHotPepperコンポーネントの中で閉じられるようにしたいです。
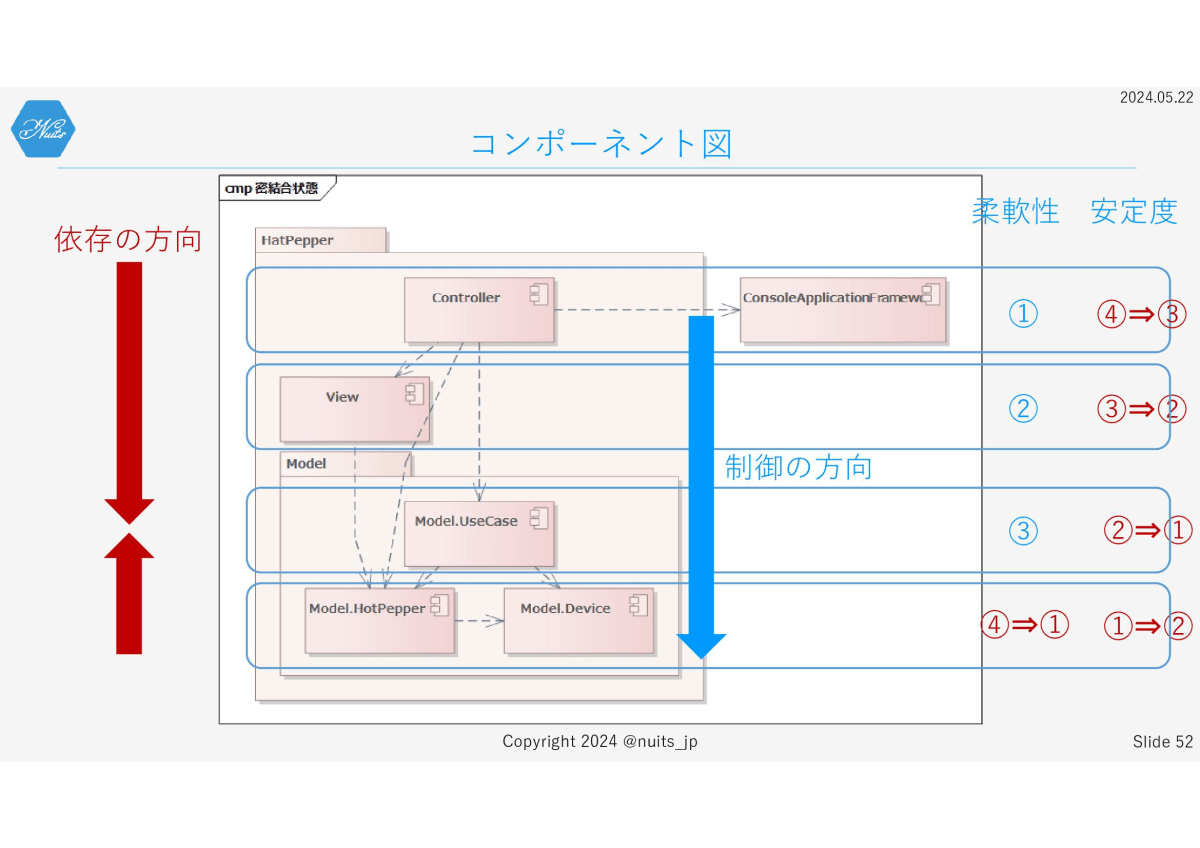
そのためには、依存の方向をこのように、すべてがUse Caseに向かうように設計したいところです。つまりRestaurantはUse Caseに含めたいわけです。
でも制御、つまり呼び出しの青の矢印の方向になっていますよね?
制御の方向と、依存方向を逆にするなんてことが、可能なんでしょうか?
もちろん可能です。とうことで、コードに戻って、リファクタリングしてみましょう!
【ここでコードを見ます。動画閲覧推奨】
さて、では全体がどうなったのか改めてモデルで確認してみましょう。
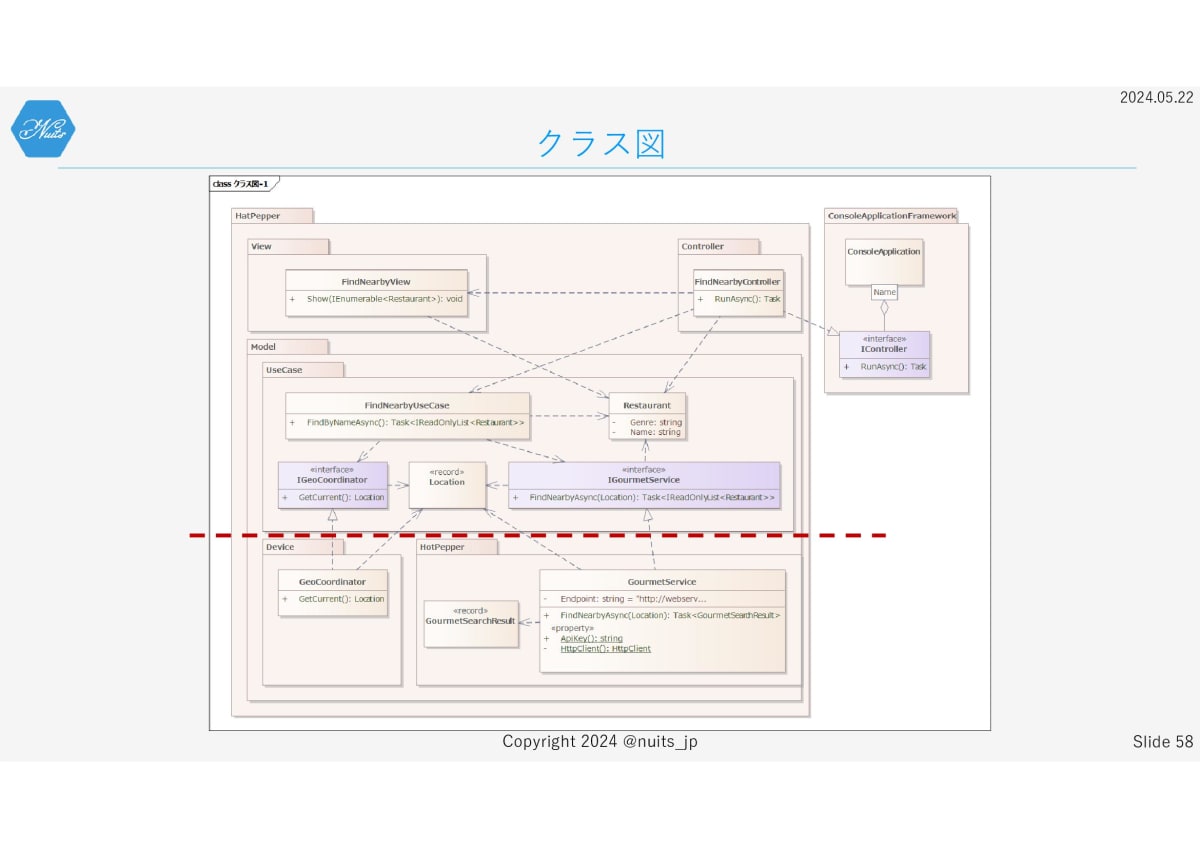
RestaurantとLocationがUse Caseコンポーネントに作成されています。
またGeoCoordinatorとGourmetServiceのそれぞれのインターフェースも、UseCaseコンポーネント内に定義されていて、それぞれを実装する形になっています。
このため、UseCase層は、その下のDeviceやHotPepperへ一切依存しないようになっていて、疎結合が実現されています。
実際の変更前後のコードを見比べてみましょう。

左が変更前、右が変更後です。
左でインスタンスを生成していた箇所がなくなって、コンストラクターで外部からインスタンスが注入されています。先にお話しした、Dependency Injectionの説明の通りですね。
この制御の方向と依存の方向を任意に制御する方法を依存性逆転の原則といいます。
これをシンプルに実現できるのが、DIの強みの一つだと思っています。
このあたりの依存関係の整理については、過去にClean Architectureの動画をYouTubeに上げさせていただいていますので、よかったらご覧ください。
この手の動画としては珍しく1.3万PVも見られている動画でおすすめです。

そしてもう一つ、初期化する側が大きく変わっています。コンストラクターでインスタンスを注入していますね。
そんな言葉はありませんが、手動Dependency Injectionになっています。
よくDIパターンとDIコンテナーを混同した発言を見かけますが、DIパターン自体は実のところ、別にDIコンテナーが無くても利用できます。
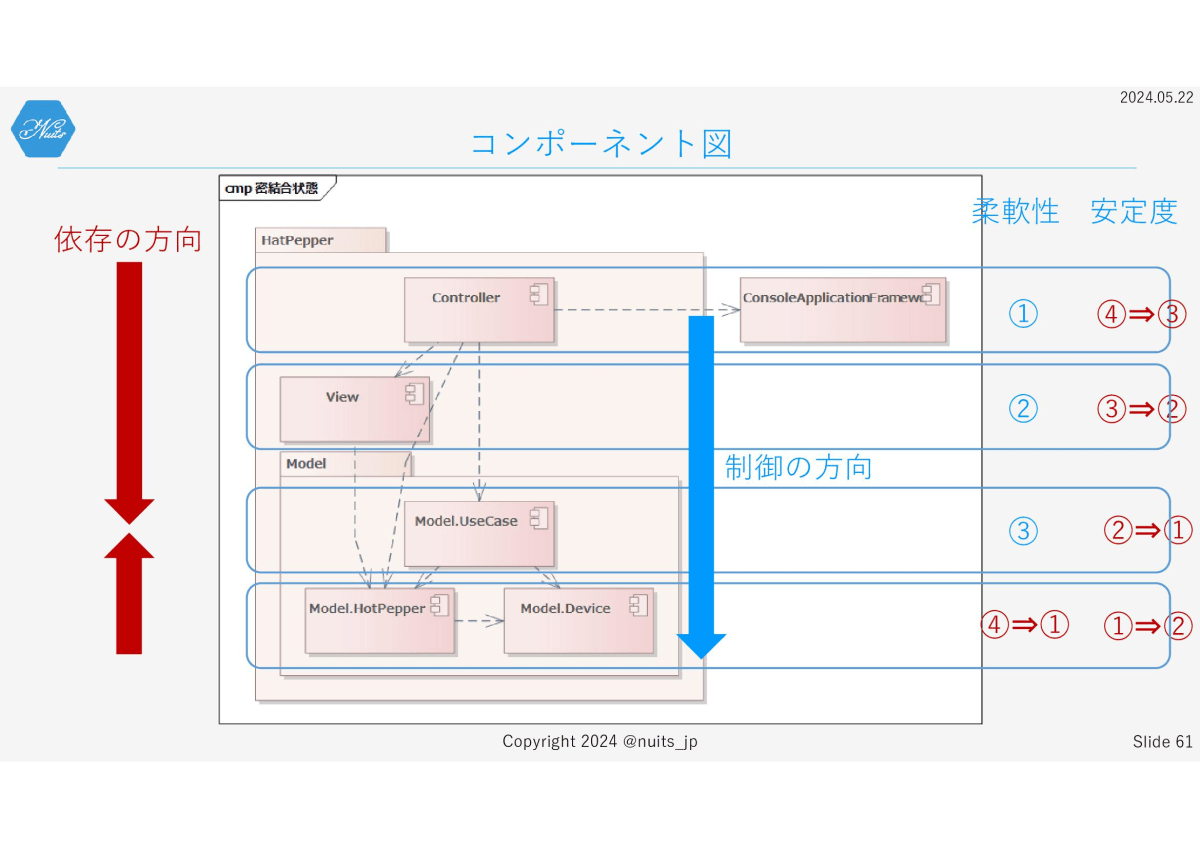
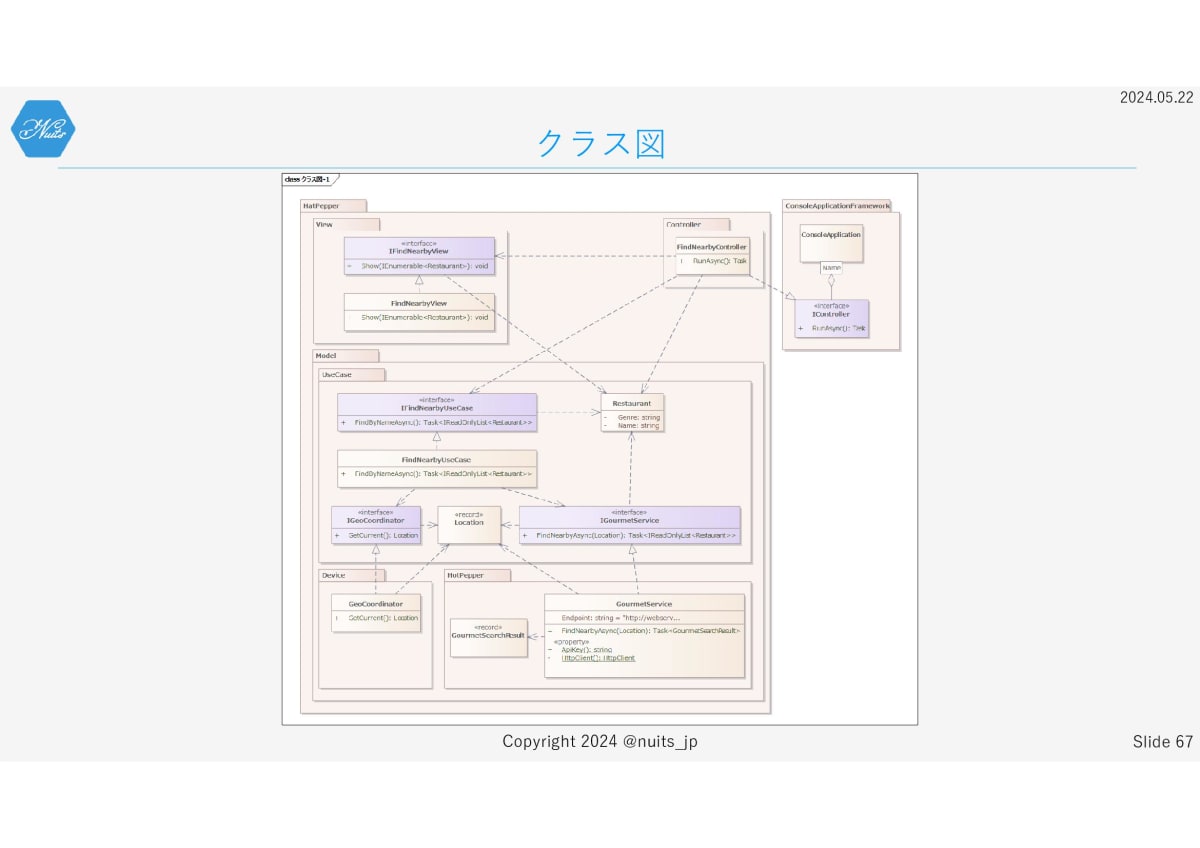
ということで、UseCaseと、Device・HotPepper間が疎結合になりました。せっかくなので、ControllerとView・UseCase間も疎結合にしてしまいましょう。
こんな感じです。
先ほどと違って、今度はControllerからの依存先側にインターフェースを定義しています。
これは先ほどお見せした柔軟性と安定度の図で、Controllerがもっとも柔軟性を高く設計していたためです。結合のインターフェースは、それぞれ依存される側であるViewとUseCaseに定義しています。
Dependency Injection Containerの適用
ここまで、DI Patternを適用してきましたが、まだDI Containerは利用していません。
DI Patternを利用することと、DI Containerを利用することは必ずしも同義ではありませんが、今回のケースでは利用しない理由がありません。
ということで、DI Containerを適用しましょう。

ど~ん!適用しました。
変わるのはアプリケーションの初期化部分くらいです。左がContainer未使用のコードで、右がContainer使用したコードです。
パッと見、Container使用時の方が整然としているように見えますよね。
右のほうは、宣言的に記述されていますし、インターフェースに対する、実装クラスが何なのか明確に表現できています。
左側は、インターフェースと実体のマップが見た目ではわかりませんし、手続的で、個人的には右のほうがわかりやすいなと思ってます。

分かりやすい以外にも、例えばインスタンスの生成方法を柔軟に制御できたり、依存関係の変更があったときに、インスタンス生成個所を個別に修正して回ったりしなくてよいメリットがあります。
DI PatternにDI Containerは必須ではありませんが、利用できるなら利用したほうがいいでしょう。
ちなみに、コンテナーを意図的に利用しない場合も、もちろんあります。
Dependency Injectionとパラダイムシフト
さて、みなさん。ここまでDIパターンとDIコンテナの話をしてきましたが、DIは難しいですか?
まぁぶっちゃけ難しいと思います。それはなぜか?
それはDIがパラダイムシフトを伴うからです。
でも、なれます。なぜなら、所詮はパラダイムシフトでしかないからです。DIは、設計の観点からは複雑ではありません
DIの設計はシンプルです。なので、パラダイムがシフトできれば、理解できます。誰でも使ってれば慣れます。たぶん。
Service Locator パターン
とはいえ、DI以外の選択肢はないのか?
もちろんあります。それがサービスロケーターパターンです。

てことで、コードを見てみましょう。
ここも3分間クッキング方式です。
【ここでコードを見ます。動画閲覧推奨】
で実際、これまでの蜜結合なコードやDIのコードとどう違うのか、並べて比べてみたいと思います。
まずオブジェクトを利用している箇所です。
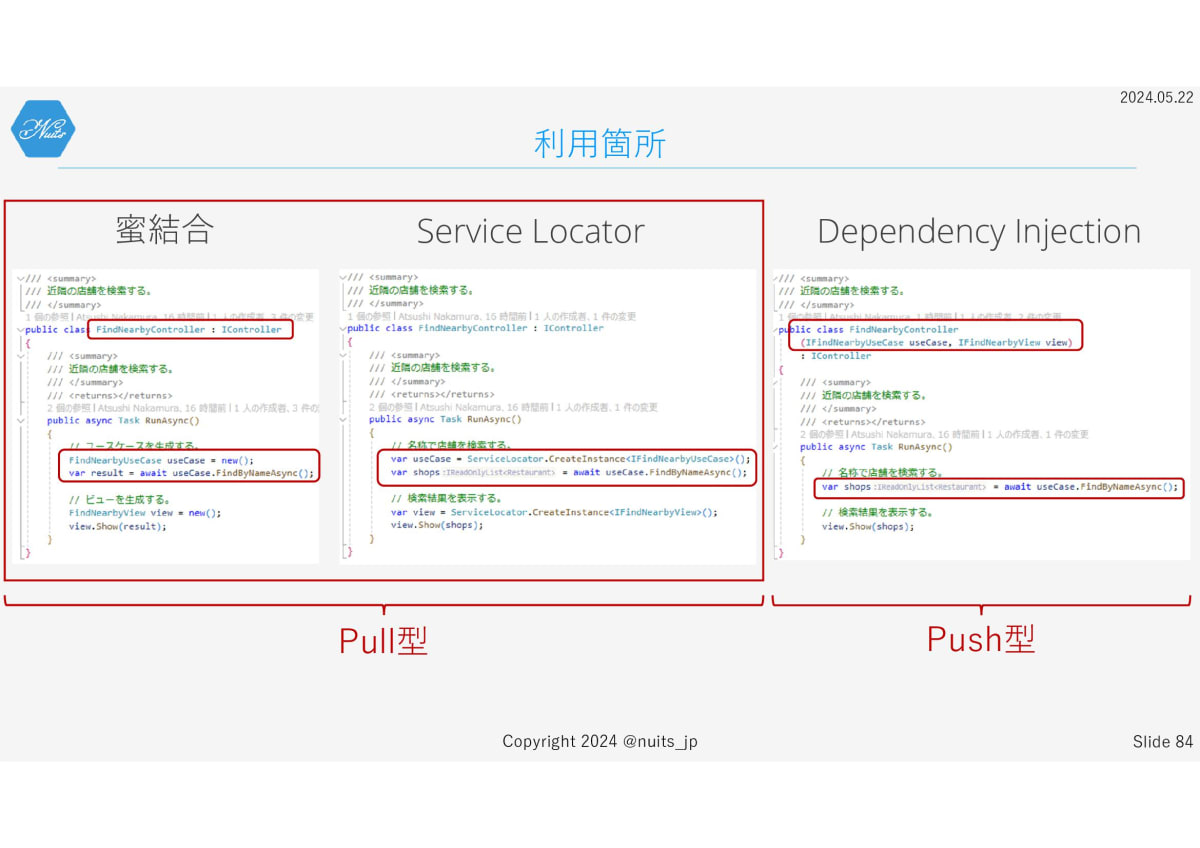
Service LocatorパターンはDIより蜜結合のコードに近いですね。そのため、個人的にはDIよりとっつきやすいと思っています。
私は個人的に、Pull型のインスタンス解決と、Push型のインスタンス解決と勝手に呼んでます。そんな定義はないと思いますが、そう考えるとわかりやすいです。
そして初期化の箇所です。

これはもうDIと完全に一致ってやつですね。DIでやりたかったことは、Service Locatorでもだいたいできます。
となると、あれれ?Service Locatorっていいとこどりで、こっちでいいんじゃね?って思いますよね?
でも、そんなことはないです。そもそも思い出してください。

DIはService Locatorより後にでてきて普及した概念で、Service Locatorのデメリットを解消した概念になっています。
では何が違うんでしょうか?コンポーネント図で依存関係を見ると明確になります。
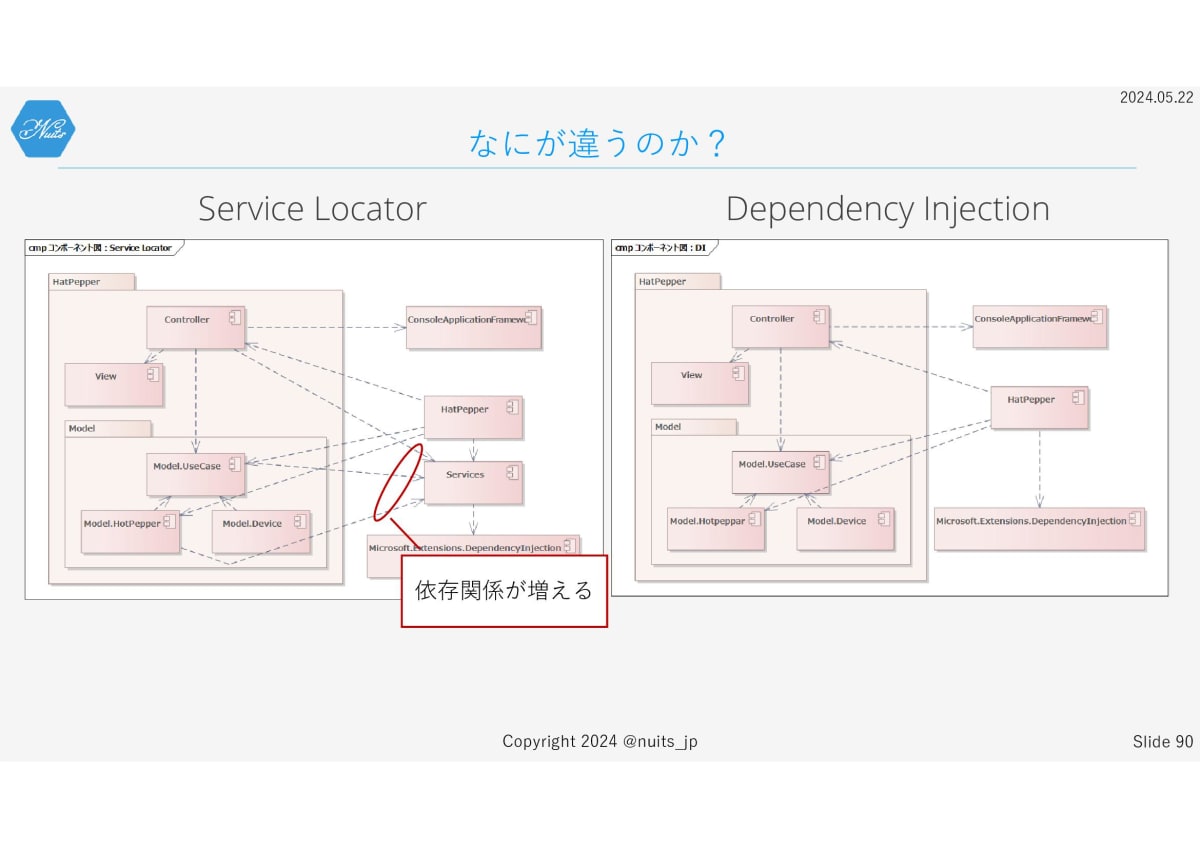
インスタンス生成が必要な場所すべてで、Service Locatorを含むServicesコンポーネントへの依存関係が増えてしまいます。
そもそもDIもService Locatorも、特に実装クラスへの依存関係を減らして、疎結合を実現することが大きな目的の一つです。
なのにほとんどすべてのコンポーネントが、staticなレジストリークラスに依存してしまうのは本末転倒です。
また、Service Locatorはちゃんと作るとそれなりに複雑な実装になります。
そうなったとき、Service Locatorが独立した単一コンポーネントならいいのですが、複数の他のコンポーネントに依存して実装されることも十分に考えれれます。
そうなると、Service Locatorとアプリケーションの双方で利用するコンポーネントで、バージョン競合が発生する可能性があります。そして、それが発生しない保証はしようがありません。

他にもテストの並行性問題もあります。
Service Locatorは基本的にStaticなレジストリになります。そのため、テスト時にスタブを差し替えたい場合、ケースAで差し替えた結果、並行で実行していたケースBに影響を与えエラーとなることがあります。
レジストリに「Thread local storage Pattern」を適用して回避することも考えられますが、それは設計をより複雑化します。
そもそも、DIはパラダイムシフトでしかないため、別に複雑性は増しません。
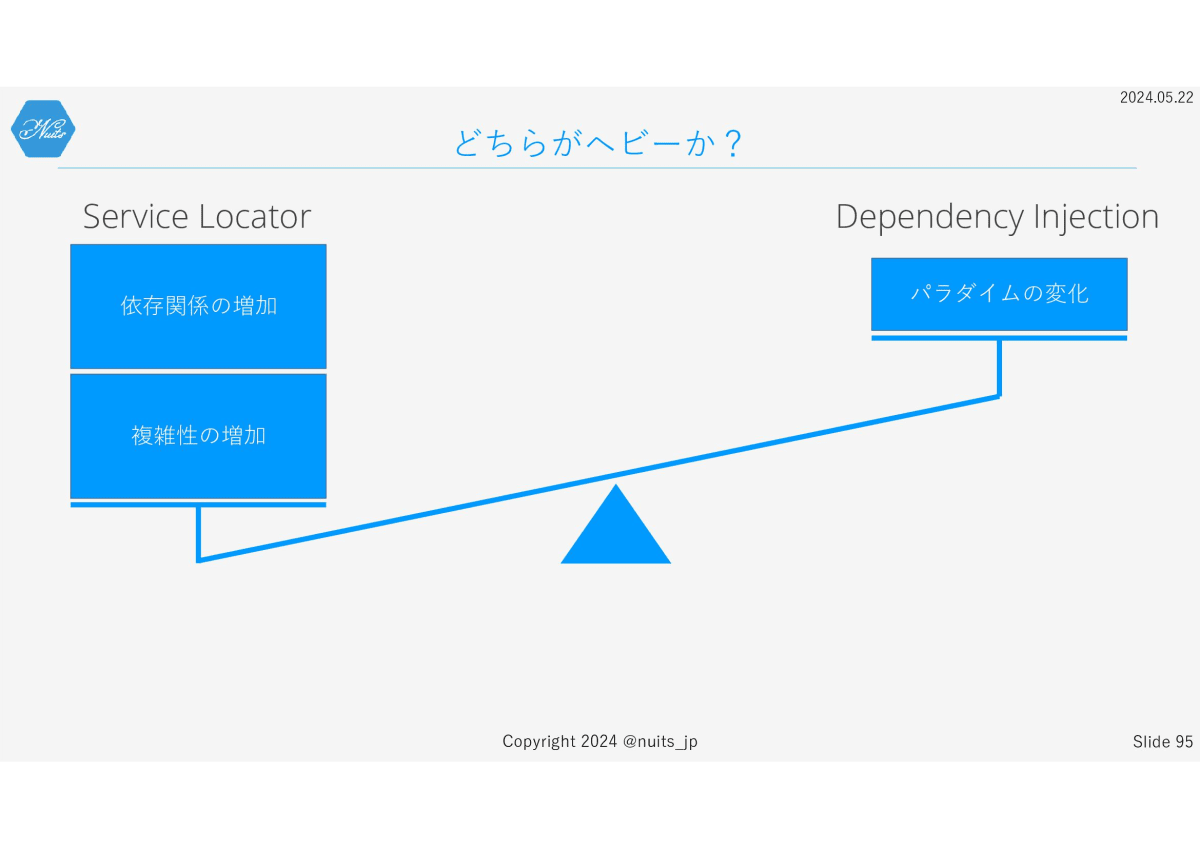
Service Locatorは理論上、DIより必ず複雑化します。複雑性とパラダイムシフト、どちらを取るべきでしょうか?
パラダイムシフトはなれます。でも複雑性は、慣れても解消しません。
もう皆さんも理解いただいていると思います。
DIは難しいですが、ほかの手段よりもよりベターな選択なんです。
ところで本日のお話の冒頭で、ライブラリからフレームワークへの進化の過程で、DIが急速に普及した。というお話をしたことを覚えていらっしゃるかと思います。
どういう事か、気になっている方もいると思いますので、最後に、実際にフレームワークの中で、どのようにDIが利用されているのか、確認してみましょう。
【ここでコードを見ます。動画閲覧推奨】
まとめ
最後に簡単にまとめましょう。

- DIは、関心を分離し、疎結合を保ちつつ、依存方向を任意に設計することを可能にします
- DIは、むずかしいです。それはパラダイムがシフトすることが要因です。そのため慣れます。
- DIは、決して最高にハッピーな解決策ではありません。ですが、この20年、人類はそれ以上のものを生み出せていません。
というわけで

みなさん、「なぜDependency Injection」を利用するのか?ご理解いただけましたね?
以上です。
Discussion
DIの歴史から学べて参考になりました。ありがとうございます。
※このあたりはtypoかもです
引くく->低く蜜結合->密結合