[論文紹介]Conformer: Convolution-augmented Transformer for Speech Recognit
論文
Conformer: Convolution-augmented Transformer for Speech Recognit
結論
- TransformerとCNNをうまく結合させたConformerを提案
- LibriSpeechの音声認識タスクにおいてstate-of-the-artを達成
- Transformerを音声認識に使ったモデルはこれが初?
abstract
最近、音声認識の領域では、TransformerとCNNをベースとしたモデルがRNNよりもよいパフォーマンスを出している。Transformerは、globalの相互作用を捉えやすく、CNNはlocalの特徴を効果的に捉える。本論文では、TransformerとCNNの良い面を残したまま結合し、音声認識タスクでstate-of-the-artを達成したConformerを提案する。
introduction
end-to-endの音声認識システムは、RNNをベースとしたモデルによって発展してきた。また、最近では、self-attentionによるTransformerベースのモデルが、様々な領域へと展開されてきている。一方で、音声認識においてはlocalのcontextを捉えることができるCNNが有用であり、いまだによく使われている。
Transformerは、globalの相互作用を捉えやすいが、localの特徴を抽出しにくい。また、CNNはkernelの位置と移動距離によって局所的な特徴量を抽出していくため、globalの相互作用を捉えるのは難しい。ContextNetは、CNNベースでありながら、残差blockを活用することでglobalの特徴を抽出していたが十分とは言えない。ただ最近では、CNNとself-attentionを組み合わせることによって、それぞれを個別に扱うよりも性能が向上することが様々な研究によってわかってきている。
本論では、音声認識モデルにおいて、CNNにself-attentionを結合した独自の方法を紹介する。また、globalとlocalの相互作用を扱うことで、パラメータの効率化も可能であると想定している。
Conformerの性能
LibriSpeech dataset + with external language modelにおいて、Conformerはそれまでのstate-of-the-artから15%も性能を向上させた。また、その他の評価データにおいても少ないパラメータ数で同等水準の性能を達成することができた。
Conformer Encoder
まず最初に、Convolutional subsampling layerを通り、その後複数回Conformer Blockに入る。
Conformer blockは、feed-forward module、self-attention module、a convolution module、a second feed-forward module4つのmoduleから構成されている。まずはそれらのmoduleを紹介する。

Conformer blockは、CNNとself-attentionがfeed-forward moduleによって挟まれているようなアーキテクチャをしている
Multi-Headed Self-Attention Module
self-attention moduleでは、Transformer-XLから着想を得た、正弦波によるpositional encodingを導入している。これにより、inputデータの長さが異なる場合でもself-attentionの生成が可能になり、結果として発話データの長さのばらつきに対してもモデルの頑健性を高めることができる。更に、prenorm residual unitとdropout unitを結合することで、学習と正則化を補助している。

Convolution Module
pointwise convolutionとgate layer unit(GLU)を結合したものを採用しており、これは、gatingメカニズムから着想を得ている。その後、1D-convolutional unit、batchnormalize unitを通過する。

Feed Forward Module
Feed-forward moduleは2つのlinear layerと1つのswish activationから構成され、音声認識用に調整された構造になっている。

Conformer Block
conformer blockは下図に示すような、2つのfeed-forward moduleでmulti-headed self-attention moduleとconvolution moduleを挟むようなアーキテクチャになっている。
このサンドウィッチ型のアーキテクチャは、Macaron-Netを参考にしている。macaron-layer内のfeed-forward layerをオリジナルに置き換えたことが変更点。
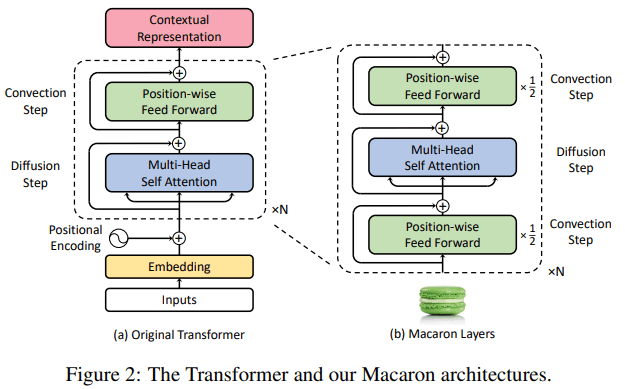
Macaron-Netのアーキテクチャ
これらのアーキテクチャは後に示す実験結果から、最適なものを選んだ結果らしい。
Experiments
Data
実験に用いたデータセットはLibriSpeech Dataset
LibriSpeech Dataset : 970時間のラベル付きスピーチに加えて、language modelを構築用の800Mのwordのコーパスが含まれている。
25msのwindow幅で、10msずつスライドさせて、80-チャネルのフィルターバンク特徴量を作成した。また、mask parameter(F=27)のSpecAugmentと、最大でtime-mask ratio(pS=0.05)の10個の時系列マスクによるaugmentationを行った。(time-mask ratioは発話時間に応じて決めた。)
Conformer Transducer
ネットワークの深さや、モデルの次元、attention-head、model parameter sizeなどを変化させて、small(10M)、medium(30M)、large(118M)の3種類のモデルを準備した。また、全てのモデルにおいてdecoderはsingle-LSTM-layerを用いた。
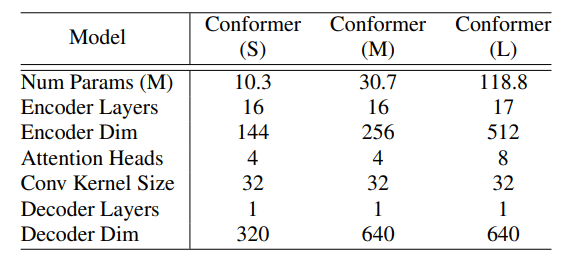
各モデルのハイパーパラメータ
正則化には、conformerの各残差unitにおいて(drop ratio=0.1)のdropout layerを適用している。また、variational noiseは、
また、LibriSpeechの960時間のデータセットから、WPM(word-per-minute)が1kであるようにトークン化したスクリプトによって学習した3層LSTMの言語モデルを用いる。この言語モデルは、開発元のスクリプトとしては、63.9程度の確からしさである。実験に用いたモデルはLingvo toolkitにて実装されている。
Results on LibriSpeech
LibriSpeech datasetでmodelを評価した結果が以下の表である。ContextNet、Transformer transducer、QuanzNetに対して、ConformerはWER(word error rate)が最も低いことがわかる。言語モデルを除いたケースでは、Conformer(M)はtestclearn/testother=2.3/5.0であり、同じサイズのCNNベースのモデルなどよりも優れている。また、言語モデルを入れた場合でも、Conformerは最も性能がよい。以上の結果から、ConformerはTransformerとCNNをうまく結合できたと言える。
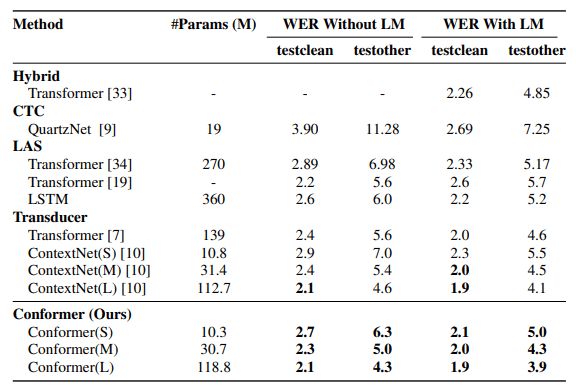
Ablation Studies
Conformer Block vs. Transformer Block
Conformer blockは、Transformer blockといくつか異なる点がある。特に、convolution blockを含み、feed forward unitsがマカロンスタイルのように配置されているような点があげられる。そこで、Conformerにいくつかの変更を加えて影響を調べた。

①SWISHをReLUに置換 ②convolutional blockを削除 ③マカロンスタイルのFFNペアをsingle FFNに置換 ④self-attentionをpositional embeddingに置換
表からわかる通り、convolution blockは最も重要であることが分かった。また、マカロンスタイルのペアfeed forward unitsは同パラメータ数のsingle feed forward unitよりも影響があることもわかった。
Combinations of Convolution and Transformer Modules
CNNとTransformerそれぞれのmoduleの相性を評価した結果を以下に示す。Depthwise-CNNをlightweight-CNNに変更した結果、パフォーマンスは大きく低下することが分かった。次にConvolutional blockを、Multi-Head Self-Attentionの前に移動させたところわずかに性能が劣化した。最後に、CNNとTransformerをparallelに配置するアーキテクチャに変更し評価し、これもパフォーマンスが大きく低下した。

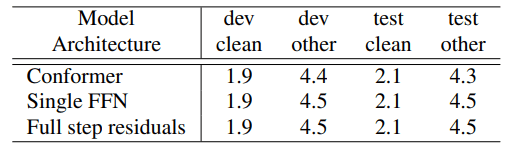
Macaron Feed Forward Modules
Conformer blockにおけるmacaron-like feed forward modulesの評価をした結果。特に、Confomer blockでは、feed forward modulesは、half-step residualsになっているため、single feed forwardやfull-step residualsに変更し、評価を行った。
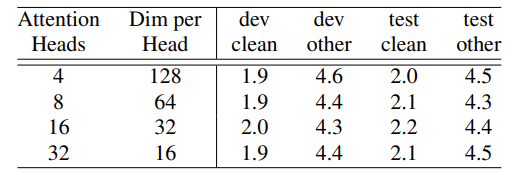
Number of Attention Heads
Multi-head self-attentionのheadの数を評価。dev otherが最も良くなったhead=16を選択したらしい。
Convolution Kernel Sizes
CNNNのkernel sizeの評価。こちらも同様にdev otherが最も良いkernel size=32を選択した。

まとめと所感
Conformerをやっと読めた。Transformerによるglobal相互作用の取入れによって性能が向上したようではある。ただ、音声認識などの時系列データにはglobal系の効果よりも、スライド系の作用素の方が物理側的には相性が良い気がする。
Discussion