はじめに
データエンジニアをやっておりますTaichiです。
最近Apache Icebergという単語をよく耳にするようになりました。
Icebergの処理エンジンといえば
- Apache Spark
- Apache Flink
- Trino
などでしょうか。このラインナップ、構築/運用するのは結構ハードなものが多いと思いませんか?
例えば、私のプロジェクトではSparkを使った構成でデータ処理を実施していますが、以下のような具体的な課題に直面しました。
- Apache Hadoopのクラスタ構築作業や、Sparkを動かすために専用の記述(PySpark)が必要になる等、一定の学習が必要。
- PySparkの記述の仕方によっては、性能が全然出ずにレスポンスが返ってこなかったり、OutOfMemoryになる場合があり、かつ解析やチューニングの難易度が高い。
クラウド前提であれば、マネージドHadoopやKubernetesがあるので良いですがオンプレミスで使っていくのはなかなか骨が折れそうです。
そのため、非機能要件がそれほど高くないのであれば、もっと軽量で簡単に使える製品でIcebergを触りたいというニーズはあると考えています。
現状、Icebergに対応している処理エンジンの中で軽量に使えるのはPyicebergなどがありますが、Pyarrowベースでの記述になるため閾値が少し高い印象です。SQLなどより利用者が多いクエリ言語で操作できることでより多くのユーザが手軽にIcebergを使えるようになると考えています。
そこで、今回手軽にIceberg上のデータを参照する方法としてDuckDBを調査しました。
Apache Icebergとは
Apache Icebergは、オープンソーステーブルフォーマットです。従来のParquetなどのファイル形式に対して、メタデータを合わせて保持することでテーブルの概念をデータレイクにもたらし、高速なクエリパフォーマンスやACID準拠のトランザクション、タイムトラベルクエリ、スキーマ進化などを実現します。Netflixが開発し、現在はApacheプロジェクトとして多くの企業で採用されています。
↓↓Icebergとはについて、こちらの記事でかなり詳しく紹介されています。
DuckDBとは
DuckDBは、列指向の組込みデータベースです。OLAP版SQLiteというとイメージが付きやすい方もいるかもしれません。
組込みデータベースとは
組込みデータベースとは、ホストアプリケーション内に統合されたコンポーネントとして動作するデータベースシステムです。
従来の独立したサーバープロセスとして動作する一般的なデータベースとは異なり、組込みデータベースはライブラリとしてアプリケーションに直接コンパイルされます。これにより、ホストアプリケーションと同じプロセス空間で実行され、クライアント・サーバー間の通信プロトコルが不要になります。
(参考)
DuckDBの特徴
DuckDBの特徴としては下記が主に挙げられます。
- 軽量
- デプロイが簡単
- 速い
- 豊富な拡張機能
(参考)
DuckDBを用いたアーキテクチャのイメージ
前述のDuckDBの特徴である軽量性を活かすことで以下のアーキテクチャが実現できるのではないかと考えております。
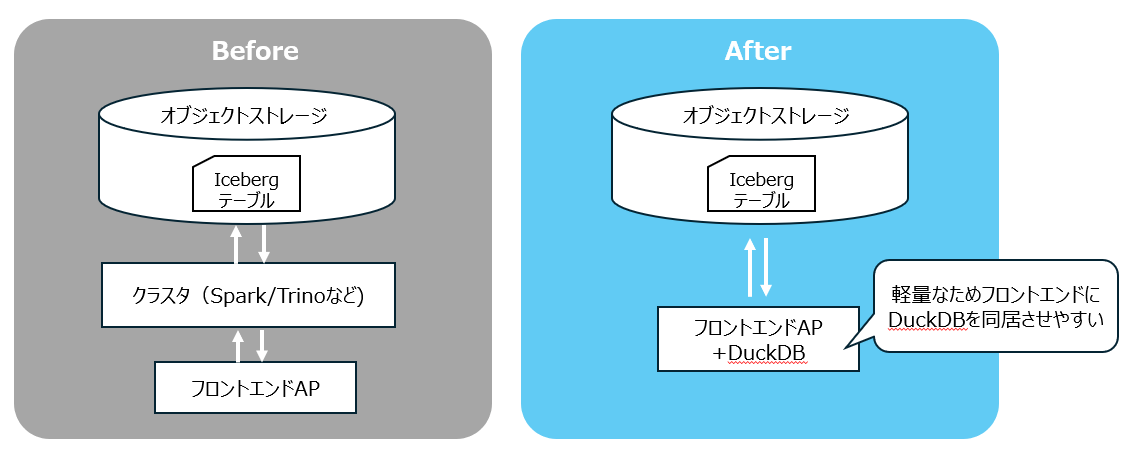
(ハンズオン)DuckDBで読み取ってみる
検証環境の構成イメージ
今回の検証環境の構成は下記の通り。
ローカルに用意したIceberg形式のデータに対して、Pythonのアプリケーションから読み取り操作を実施します。

0.環境前提
- OS:Windows11
- Pythonバージョン:3.11.6
- VSCode
1.環境準備
Icebergデータの用意
Icebergデータは、自分で用意するのが少し手間なので、公式ドキュメントを参考に下記データを用いることにします。
用意したIcebergデータのディレクトリ構成は下記の通り。
lineitem_icebergテーブルのデータが入っています。
iceberg_data
└── data
└── iceberg
└── lineitem_iceberg
├── data
│ ├── .00000-411-0792dcfe-4e25-4ca3-8ada-175286069a47-00001.parquet.crc
│ ├── .00041-414-f3c73457-bbd6-4b92-9c15-17b241171b16-00001.parquet.crc
│ ├── 00000-411-0792dcfe-4e25-4ca3-8ada-175286069a47-00001.parquet
│ └── 00041-414-f3c73457-bbd6-4b92-9c15-17b241171b16-00001.parquet
├── metadata
│ ├── .10eaca8a-1e1c-421e-ad6d-b232e5ee23d3-m0.avro.crc
│ ├── .10eaca8a-1e1c-421e-ad6d-b232e5ee23d3-m1.avro.crc
│ ├── .cf3d0be5-cf70-453d-ad8f-48fdc412e608-m0.avro.crc
│ ├── .snap-3776207205136740581-1-cf3d0be5-cf70-453d-ad8f-48fdc412e608.avro.crc
│ ├── .snap-7635660646343998149-1-10eaca8a-1e1c-421e-ad6d-b232e5ee23d3.avro.crc
│ ├── .v1.metadata.json.crc
│ ├── .v2.metadata.json.crc
│ ├── .version-hint.text.crc
│ ├── 10eaca8a-1e1c-421e-ad6d-b232e5ee23d3-m0.avro
│ ├── 10eaca8a-1e1c-421e-ad6d-b232e5ee23d3-m1.avro
│ ├── cf3d0be5-cf70-453d-ad8f-48fdc412e608-m0.avro
│ ├── snap-3776207205136740581-1-cf3d0be5-cf70-453d-ad8f-48fdc412e608.avro
│ ├── snap-7635660646343998149-1-10eaca8a-1e1c-421e-ad6d-b232e5ee23d3.avro
│ ├── v1.metadata.json
│ ├── v2.metadata.json
│ └── version-hint.text
└── README.md
Python環境の用意
venvで仮想環境を作成。
python -m venv dev_env
activateで仮想環境を起動する。
.\dev_env\Scripts\Activate.ps1
Windowsの場合、activate 用スクリプトの実行がポリシーで制限されている趣旨のエラーが生じることがあるので、下記コマンドで一時的に制限を無視させる。
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process
(参考)
必要なライブラリをpipする
duckdbをインストールする。
pip install duckdb
VSCodeを開きノートブックファイルを作成する。
私は、右上から用意したPython仮想環境をカーネルとして選択する。
2.DuckDBの拡張機能でIcebergデータを読み取る
Iceberg Extensionのインストール
公式ドキュメントに従いIceberg Extensionをインストールする。
import duckdb
initial_sql = f"""
INSTALL iceberg;
LOAD iceberg;
"""
duckdb.sql(initial_sql)
クエリを発行する
iceberg_scanメソッドを用いてテーブルパスを指定すると、データをクエリできる!
query = """
SELECT *
FROM iceberg_scan('data/iceberg/lineitem_iceberg', allow_moved_paths = true) limit 10;
"""
duckdb.sql(query).show()

Iceberg Catalogはどこ?
通常Icebergのデータを扱う際は、Iceberg Catalogを介してRead/Writeが処理されます(例:Apache Spark, Trinoなど)。今回DuckDBでの読み取り時はIceberg Catalogは登場していません。
ではどうやってIcebergデータにアクセスしているのか?
DuckDBでは、Iceberg Catalogが対応しているテーブル名とmetadata fileの紐づけ処理をDuckDBのiceberg_scan関数で実施しているのです。
iceberg_scanによる最新のメタデータの特定
先のクエリではテーブル名しか情報を与えていないがmetadata fileを特定しています。
iceberg_scan関数では、Iceberg Table Specによりメタデータは必ず metadata/ディレクトリ内に存在するためそちらへの走査がなされます。
- ユーザーが指定したパス(例:lineitem_iceberg)を受け取る
- そこに/metadata/ディレクトリがあるか確認
- そこから最新のメタデータファイル(vN.metadata.json)を探す
- 見つけたらそのファイルパスを返す
これは、iceberg_scan関数実行時に呼び出されるIcebergMultiFileReaderのGetMetaDataPath関数が担っています。
DuckDBのIceberg Catalog対応について
Iceberg Catalogが無い場合、当たり前ですがテーブル情報の管理が難しいです。
なので、例えば「データレイクに入っているテーブルの一覧が欲しい」という場合にListするDuckDBネイティブな手段がないのです。
ローカル環境で手元で数テーブル確認したい程度の用途なら問題ないですが、商用環境で大量にテーブルがある際にテーブルの一覧が取得できないのはつらいと思います。
そのため、DuckDBがIcebergCatalogに対応することが期待されます。
Amazon S3 Tables/Glue Data Catalogへの対応
Amazon S3 Tables/Glue Data Catalogに関しては、現在プレビュー中ではありますがDuckDBにIcebergCatalogとしてマウントが可能になっています。これにより、テーブルのList等の操作ができるようになります。
duckdb-icebergのGitHubを見てみると、さらにマウントできるカタログの範囲の拡張を実施していくようです。今後のアップデートが楽しみですね!
書き込み処理は?
残念ながらDuckDBでは2025/04/10時点では、Icebergへの書き込みができません。
duckdb-icebergのGitHubを見ているとwriteサポートに対する意見は集まっていますが、開発の時期感については言及されていない状況です。
今後、書き込み処理が機能追加されるとよりIceberg+DuckDB構成が増えてくるのではないかと思います。
まとめ
DuckDBを使った感想としては、デプロイがとても簡単でAPに組込みやすいという印象です。
実際本番相当のデータ量でどこまでDuckDBが耐えるのかなどは気になりますが、それはまた別の機会で検証したいと思います。
はじめに書いたもっと軽量で簡単に使える製品でIcebergを触りたいというニーズに対しては、一定満たせるものの下記課題があるので今後のアップデートに期待と考えています。
- Iceberg Catalogにまだ対応していない(一部はしている)
- 書き込み操作に対応していない
将来的な構成イメージ
前述の課題が解消することで、将来的には下記のような構成がいいのではと想像しています。
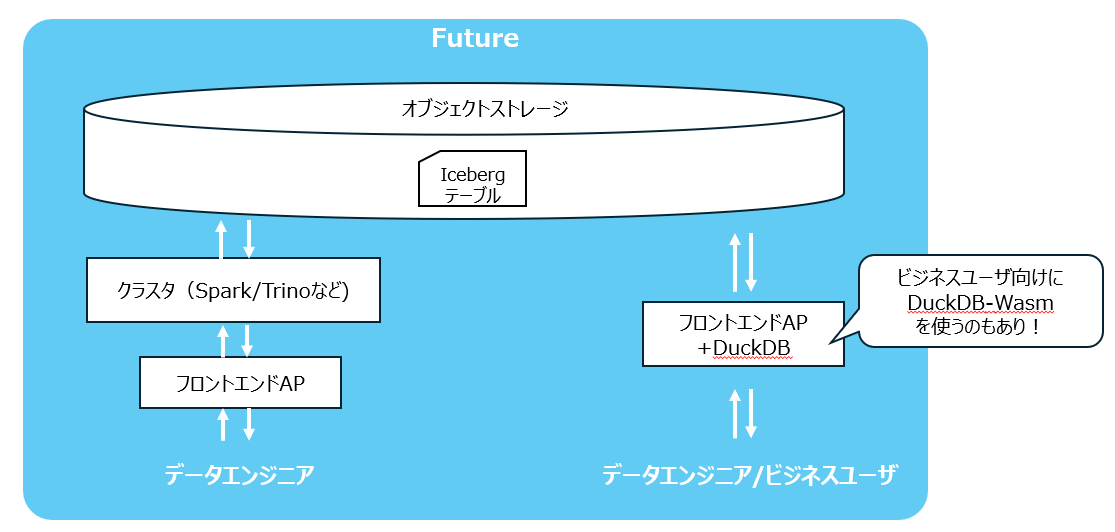
- 大量データ処理にはSpark/Trinoを用いる
- ライトなユースにはDuckDBを用いる
- ビジネスユーザ向けにはDuckDB-Wasmを用いてブラウザベースでアクセスさせる

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。