はじめに
今回は、前回のブログでご紹介した「データスペース」の応用事例の一つとして、データスペースを活用した新たなRAGのアーキテクチャをご紹介します。
想定読者
- LLMやRAGについてなんとなく知っている方
- 新たなRAGのアーキテクチャに関心がある方
- データスペースとAIのインテグレーションに関心がある方
データスペースとは?
データスペースとは、参加する組織・企業同士が互いに信頼できる仕組みのもとで、中央の管理者を置くことなく、ポリシーと契約に基づいて安全かつ自由にデータをやり取りできる分散型の枠組みを指し、現在欧州や日本で広がりを見せつつあります。
データスペースは制度面と技術面の両方から支えられた空間であり、各参加者が自らのデータに対する「データ主権」を保持したまま連携できることが特徴です。独立行政法人 情報処理推進機構(IPA)の発行するデータスペース入門によると、「データの提供元である企業や個人は自身のデータがどのように利用されているか関与できる」状態が「データ主権がある」状態であると定義づけられています。

こうした制度・技術の構築・標準化により、業界・組織・企業間のコラボレーションを加速し、横断的な課題解決や新たなデジタルサービスの創出を支えることができます。
なお、以下の記事にてデータスペースの詳細な解説をデモ付きで公開しております。さらにデータスペースに関心がある方は、こちらの記事をご確認ください。
Retrieval Argumented Generation(RAG)とは?
Retrieval Augmented Generation(検索拡張生成:RAG)とは、LLMの外部にあるナレッジが集約されたナレッジDBを参照しながら回答を生成することで、知識の拡張を可能にする手法です。
RAGでは、以下のような仕組みでLLMの知識補強を行います。

なお、RAGの詳しい仕組みについてさらに知りたい方は、以下のブログをご覧ください。RAGの仕組みに加え、パワーポイント資料を参照した回答生成を行うハンズオンを体験することが出来ます。
RAGの現在地
現在、RAGは社内ナレッジ検索やFAQ応答などを中心にユースケースが拡大しています。実際、当社内でも社内情報を参照して回答してくれるチャットボットが提供されており、筆者自身も日常的に活用しています。
現状、多くのRAGは、中央のナレッジDBに知識を集約し、それを参照して回答を生成する中央集権型のアーキテクチャが一般的です。以下の図は、冒頭で述べた社内チャットボットを例にしたRAGアーキテクチャの概要図です。各部署のメンバーが中央のナレッジベースにデータを集約し、LLMがそれを参照しながら回答を生成することで、通常のLLMでは回答が難しい社内の情報に関する質問に対しても回答を生成することが出来ます。

こちらのアーキテクチャを、会社や団体を跨いで利用するケースを考えてみましょう。各社からデータを中央のナレッジDBに集約し、LLMに参照させて回答を生成することは技術的には可能です。一方で、データを提供する各社は自身のデータの用途の追跡困難性や目的外利用などのリスクを負うことになります。このような懸念から、各組織がデータの共有を躊躇し、結果として多くのデータや知識が組織内に閉じたままとなり、RAGの効果を十分に発揮できない状況が生じることが想定されます。

データスペースが叶える新たなRAGアーキテクチャ
データスペースは、データを提供する主体が自身のデータへのコントロールを維持したままデータの流通を可能にします。データスペースを用いてRAGに情報を付与することが可能になれば、今よりさらに横断的な情報統合や文脈理解が可能となり、これまでにない新たな価値の創出につながると筆者は考えています。昨今、データスペースとRAGを組み合わせた新たなRAGアーキテクチャ(以降、DS-RAGと表記)が提案されています。以下はDS-RAGのイメージ図を表しています。

次の章では、実際にどのような仕組みでRAGとデータスペースを統合することができるかご紹介します。
DS-RAGを構成するアーキテクチャ
本章では、On Data Spaces for Retrieval Augmented Generation (2024)[1]にて提案されているDS-RAGのアーキテクチャの構成パターンを3つ紹介します。
なお、こちらの論文は、ドイツ情報科学会(Gesellschaft für Informatik, GI)が主催するドイツ最大級の情報系学会「INFORMATIK 2024」において発表されたものであり、同学会が発行する査読付き論文集「Lecture Notes in Informatics(LNI)」に掲載されています。
LNI はドイツを中心としたEU圏で認知されている学術シリーズであり、データスペースを含む応用情報分野において、学術・政策・産業界を横断した実務的研究の発信基盤として位置付けられています。
こちらの論文で提案されているアーキテクチャは、以下の6つの要素から構成されます。
| 構成要素 | 概要 |
|---|---|
| User | Consumer環境に自然文でプロンプトを送信し、回答を受信する主体 |
| Provider | 文脈情報となるデータを提供する主体 |
| Consumer環境 | Userからプロンプトを受け取り、Userに回答を返すソフトウェアコンポネント |
| Provider環境 | 文脈情報となる元データを持つソフトウェアコンポネント |
| Federator環境 | Consumer環境・Provider環境 双方から分離された中立的な仲介サービス |
| Broker | Consumer環境から必要なデータの情報を受け取り、適切なProvider環境の宛先情報を返すソフトウェアコンポネント |
提案された3つのアーキテクチャの違いは、コネクタ間でやり取りされるデータの違いにあります。やり取りされるデータは、ナレッジDBとLLMをConsumer環境、Provider環境のどちらに配置するかで違いが生じます。
以降の章では、それぞれのアーキテクチャについて詳細に説明します。
Concept 1: LLM, ナレッジDBともにConsumer環境に配置
Concept 1では、LLMもナレッジDBもConsumer環境に配置され、文脈取得・生成処理はすべてConsumer環境で行われます。Userがプロンプトを送信してから、回答が返されるまでのフローは以下の通りです。

本アーキテクチャの長所は、他のアーキテクチャと比較して容易に実装可能な点です。本アーキテクチャのコネクタ間でやり取りされる情報は契約交渉・締結に関する情報の送受信となります。これらの情報の送受信は既存のEclipse Dataspace Components(EDC)をはじめとするデータスペース関連ソフトウェアですでに実装されており、こちらをほぼそのまま流用することが出来ます。
一方、Provider環境から共有されるデータの主権保持が問題点として指摘されています。Provider環境のデータがそのままConsumer環境のナレッジDBに保存されることになり、Consumer環境上でのデータの目的外利用の制限などが困難になります。
Concept 2: LLMはConsumer環境、ナレッジDBはProvider環境に配置
Concept 2では、ナレッジDBはProvider環境に、LLMはConsumer環境に配置されます。Userがプロンプトを送信してから、回答が返されるまでのフローは以下の通りです。

本アーキテクチャの長所は、Concept 1 と比較してデータ主権の保持に寄与しやすい点です。特に、LLM への文脈情報としてデータを一時的に使用し、その後揮発させることができる設計であれば、データが Consumer 環境に恒常的に保存されることを避けられるため、データ主権の観点から望ましいアーキテクチャとなります。
一方で、UserのプロンプトがProvider環境に流出し、そのプロンプトの意図を知られてしまう点が問題点として指摘されています。実際には、LLMとナレッジDBとの間でやり取りされるのは自然文のプロンプトではなく、それを機械判読可能なベクトルに変換したものがやり取りされるため、直接意味を解釈することは困難です。しかし、ベクトル情報から元の文章を復元する研究も進められており、データが明らかにされる潜在的な危険があるため、Userの意図がProvider環境に簡単に知られてしまうアーキテクチャとなっています。
Concept 3: LLMはFederator環境, ナレッジDBはProvider環境に配置
Concept 3では、LLMはConsumer環境・Provider環境 双方から分離された中立的なFederator環境、ナレッジDBはProvider環境に配置されます。Userがプロンプトを送信してから、回答が返されるまでのフローは以下の通りです。
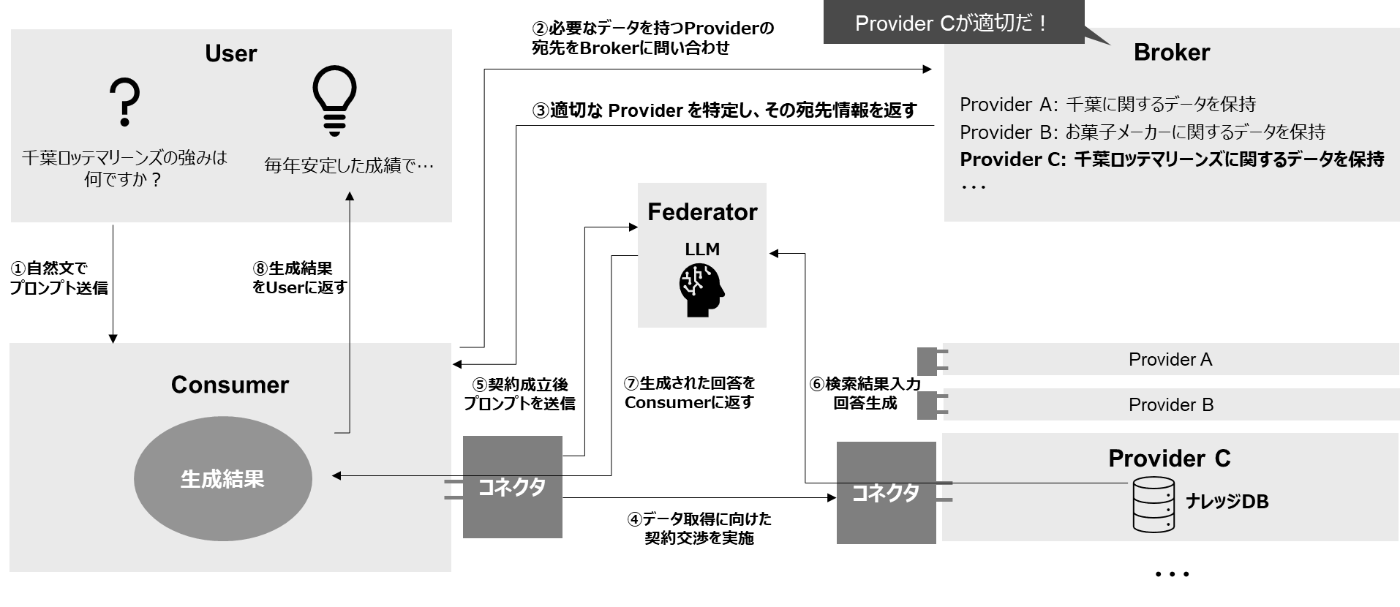
こちらのアーキテクチャの長所は、Consumer環境におけるデータ主権の侵害リスクを大幅に低減できる点です。本アーキテクチャでは、検索から回答生成までの一連の処理を Consumer 環境の外部、すなわち中立的な Federator 環境で実行し、その最終的な生成結果のみが Consumer 環境および User に返されます。このため、Provider 環境の元データ自体が直接 Consumer 側に渡ることはありません。
ただし、Federator 環境におけるデータ主権の侵害リスクについては別途留意が必要です。仲介者たる Federator が検索・生成プロセスに関与する構成である以上、その運用形態や制御不能性に起因する懸念は残ります。これに関する設計上の論点および実証的な検討については、後述の 論文に対する私の私見 パートにて詳述します。
また、LLMの回答生成過程の透明性の担保が難しくなることも課題として挙げられます。LLMによる回答生成過程がConsumer側の環境から確認することが出来ないため、LLMが確かにProvider環境のデータを参照し、正当な方法で回答を生成したことを保証することが困難なアーキテクチャとなります。
論文の提案に対する私見
Concept 1:LLM, ナレッジDBともにConsumer環境に配置
Concept 1における回答生成フローを再掲します。

私は、本アーキテクチャを採用する課題が多いと考えています。前述の通り、本アーキテクチャではProvider側のデータが、そのままConsumer環境のナレッジDBに保存される構成となっており、データ主権の保持が困難である点が大きな課題と指摘されています。
RAGにデータスペースを導入する最大の意義は、データ主権を確保しながら、信頼できるかたちで複数のデータソースを安全に流通・連携させることにあると考えています。これにより、データの共有を躊躇していた主体も安心してデータを流通させることができ、従来の中央集権型RAGでは難しかった組織横断的な回答生成が可能になります。
しかしながら、データ主権が担保されないのであれば、データ主権侵害リスクによるデータ共有の躊躇を拭うことは難しく、中央集権型RAGと本質的に差異が小さいと考えます。
むしろ、本アーキテクチャでは中間処理が多く、通信経路も複雑化するため、レイテンシの増大やUXの低下が懸念される点で、現状の中央集権型よりもむしろ不利となる可能性も考えられます。
Concept 2:LLMはConsumer環境、ナレッジDBはProvider環境に配置
Concept 2における回答生成フローを再掲します。
本アーキテクチャでは、UserのプロンプトがProvider環境に流出することがリスクとして言及されています。
私は、このプロンプトの扱いについて、Provider、User双方の視点から主権の担保を考える必要があると考えます。
-
Provider側の視点
Providerは、自身の保有するデータが不適切な目的で利用されることを防ぐ必要があります。その中には、プロンプトの内容に応じてデータの提供可否を判断するケースも想定されます。
たとえば、プロンプトが以下のような内容を含む場合:
- 業務上の競合調査につながるもの
- 法的・倫理的に扱いが難しいテーマを含むもの
このようなケースでは、Providerがポリシーに基づき回答を拒否することが、Provider側の「データ主権」の一部として重要です。これらを可能にするには、プロンプトがProvider側から確認可能であることが技術的前提となります。
-
User側の視点
プロンプトはUserが生成した知的財産的な入力であり、それ自体が個人や組織の意図・戦略・関心を内包するセンシティブな情報であると考えます。
したがって、プロンプトにも提供されるデータと同様に、明確な「データ主権」が存在すると考えられます。特に重要なのは、プロンプトがProvider環境に渡った場合でも、それはデータ提供可否の判断、及びナレッジDBの検索クエリとしての目的に限定して使用されるべきであり、
- ロギング
- 再学習への利用
- プロンプトの蓄積による意図推定
など、本来の目的を超えた利用は厳格に制限する機構が必要だと考えます。
このように、プロンプトは一方的に秘匿されるべき情報ではないと考えます。
データ提供の適切性を判断するために、Providerに対して開示される必要はある一方で、User側の主権を守るために、その使用目的は「データ提供可否の判断材料」「ナレッジDBの検索クエリ」の2点に限定すべきです。
つまり、プロンプトとは、
- 共有されることが必要な情報でありながら
- 厳格に制限された文脈でのみ使用されるべき情報
であり、これらを叶える機構があれば、Concept 2は中央集権から脱却した新たなRAGアーキテクチャになり得ると考えます。
Concept 3:LLMはFederator環境, ナレッジDBはProvider環境に配置
Concept 3における回答生成フローを再掲します。

私は、本アーキテクチャはデータ主権を守りつつ、信頼性のある回答生成を可能にする有効な選択肢であると考えます。ただし、その実現には、Federator環境の信頼性を保証する枠組みが必須となります。
例えば、以下の3点を保証する必要があります。
-
Federator環境を提供する主体の信頼性
Trust Frameworkを通じて、Federator環境を提供する主体が信頼できることを制度的・技術的に保証すること -
Federator環境における回答生成の過程に対する透明性:
どのような手順・根拠で回答が生成されたのかを、Userが確認可能であること -
Federator環境で使用されたデータのトレーサビリティ:
データがいつ・どのように使用されたのかを、Providerが追跡可能であること
このような、データスペース等に属する主体や、それらが提供するサービスの信頼性担保のための代表的な仕組みの一つとして、 Trust Framework(トラストフレームワーク)が挙げられます。
Trust Frameworkでは、例えば以下のような要素が検証されます。
-
データスペース等に属する各主体の属性情報
各主体がどんな組織であり、どの権限を持っているのかを確認する。 -
ポリシーや契約条件への準拠状況
サービスを提供する主体が、どのルールや法的要件に従っているのかを確認する。 -
サービスの信頼性評価
可用性・安全性・正当性など、サービスそのものが信頼できるかを確認する。
EU圏ではすでに「Gaia-X」プロジェクトにおいて、EUの法制度・文化の元でフレームワークの検討、および認証プロセス、コンプライアンス検証などの具体的な実装が進んでいます。
Trust Frameworkのような信頼性担保の仕組みを活用することで、本コンセプトで提案された信頼性ある回答生成が成立すると考えます。
最後に
本記事では、データスペースとRAGを組み合わせた新たなアーキテクチャについて、その構成と特性をご紹介しました。
従来のRAGが抱えていた「知識の集中」と「データ主権」のトレードオフに対し、データスペースは一つの有効な解決策を提示してくれると筆者は考えています。
プロンプトの扱いや回答生成過程の透明性、中間処理の多さによるレイテンシなど、まだまだ検討課題は残るものの、データ流通の活性化による新たなAI活用の未来はデータスペースの普及とともに見えつつあります。今後もAIに限らず、データスペースがどんな価値創出を可能にするのか、引き続き向き合っていけたらと考えています。
本当は参考実装とともにご紹介したいところでしたが、本記事が冗長になってしまうのは本意ではないため、今回は論文紹介のみとさせて頂きました。続編として、DS-RAGの参考実装もご紹介する予定です。お楽しみに!
-
Hermsen, Felix et al. (2024).
On Data Spaces for Retrieval Augmented Generation.
INFORMATIK 2024, Lecture Notes in Informatics (LNI), pp. 701–707. ↩︎

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。