Amazon Q in Connectとは
Amazon Web Services(AWS)のクラウドコンタクトセンターサービスであるAmazon Connectには、同AWSの生成AIアシスタントサービスである、Amazon Qを簡単に統合することができます。
Amazon Qを統合することで、以下のような、AIによるコンタクトセンターの高度化、対応の効率化が可能です。
- 手動検索:エージェント(オペレータ)が手動でナレッジを検索
- セルフサービス:生成AIエージェントが、直接問い合わせ元(顧客)と会話し、エージェント(オペレータ)を介さずに問題の切り分けや顧客課題解決を自律的に行う
Amazon Q in Connectの機能は、リリースノートの通り2025/11現在も活発に拡充されています。
少しピックアップした限りでも、以下の通りの機能拡充がされています。
- 2024/12:『Amazon Q in Connect がエージェント支援機能で 64 言語をサポート』がリリース。日本語でAmazon Q in Connectのエージェント支援が使えるようになりました。
- 2025/03:『Connect 管理者ウェブサイトから直接 Amazon Q in Connectを設定する』がリリース。プロンプトの作成などがGUIで可能となり、開発が容易となりました
- 2025/10:『生成 AI を活用した E メール会話の概要と推奨される応答』がリリース。
また、Amazon Connect全体としてはさらに多くの機能追加がされていることもリリースノートから確認でき、Amazon Connectは将来性のあるコンタクトセンターサービスの1つです。
実際に2025年のGartner社『2025 Gartner Magic Quadrant for Contact Center as a Service』でもLeaderとして選出されております。
これ以降の記事で使用される用語について補足させていただきます。
本記事では、エージェントではなくオペレータを問い合わせ対応などを実施する人の意味で使用させていただきます。
Amazon Connectの用語としてはエージェントが正しいのですが、本記事では読者へのわかりやすさを考慮して、上記の通りとします。尚、機能名やサービス名に含まれる場合はエージェントのままとします。
上記、ご了承ください。
Amazon Q in Connect手動検索とは
本記事で主に取り上げるAmazon Q in Connectの機能は手動検索です。
Amazon Q in Connect手動検索機能は、S3バケットに配置したファイル(テキストファイルやWord、PDF、HTMLファイルや、各種の統合先のナレッジベース(SalesforceやServiceNow等)について、オペレータが自然言語でナレッジ検索できる機能です。
例えば、オペレータが、問い合わせ元のお客様などに案内するための裏付けとして、
「○○手続きの顧客管理システムへの登録方法」などを検索するというユースケースがあります。
手動検索の精度向上とコンテンツのセグメンテーション
Amazon Q in Connectの手動検索精度をあげる方法にはいくつかあります。
その中でも、公式のブログの最後に紹介されているコンテンツのセグメンテーションを利用する方法を今回は取り上げます。
コンテンツセグメンテーションとは、Amazon Q in Connectの検索対象となるコンテンツ(ドキュメント等)にタグ付けをして、そのタグを元に検索対象を絞ることです。
検索対象が絞られることで、紛らわしい記載や矛盾した情報が入り込みにくくなり、検索結果の精度向上が期待されます。
セグメンテーションの実施タイミングとstep-by-stepガイド
"セグメンテーションをどのタイミングで実施するのか?"という点は検討が必要です。
例えばIVR(Interactive Voice Response:自動音声応答)の中で問い合わせ元が入力した番号を元にセグメンテーションを自動実施するというのは1つの手です。
一方で、実際のコールセンター業務においては、
- コールセンター人員の制約(1人が広範な問い合わせを対応している等)
- 開発当初と現在の運用の間での乖離("その他の問い合わせ"に分類される問い合わせが増えてしまっている等)
- 顧客に入力してもらうには、顧客負担が大きい(人の案内なしには確認が難しい箇所にある製造番号や品番でセグメンテーションをしたい等)
といった背景などにより、IVRの情報を用いたセグメンテーション適用があまり有効でないケースが考えられます。
こういったケースにおいては、Amazon Connectのセルフサービス(生成AIエージェントが、問い合わせ元と直接やり取りする)機能を用いるなどして、より高度な問い合わせの分類や絞り込みを行うことも可能です。
一方で、一足飛びに問い合わせ元とAIが直接対応する機能を導入するにはセキュリティ懸念等様々なハードルがあります。
そこで、今回はAmazon Connectの step-by-stepガイドを用いて、オペレータが手動でコンテンツセグメンテーションを適用するサンプルをご紹介します。
Amazon Connectのstep-by-stepガイドとは
step-by-stepガイドとは、クリックして画面遷移するようなインタラクティブな手順書(UI)を表示し、オペレータがより効率的に手順を確認できるようになるAmazon Connectの機能です。
step-by-stepガイドはノーコードで作成することができ、Amazon Connect標準のオペレータ向けアプリケーション "エージェントワークスペース"で表示させることができます。
Amazon Connectのドキュメントでは、『生成AIを利用して関連するガイドを提案する』統合が紹介されていますが、今回は、『ガイドを利用してインタラクティブに生成AIの検索範囲を変更する』という統合を行うことを考えます。
こうすることで既存のオペレータのワークフローはあまり大きく変えずに、かつ精度よく生成AIによるナレッジ検索を導入することを目指します。
今回はごく簡単な例で、実装及び動作確認を行います。
実装及び動作確認
Amazon Connectインスタンス及びS3ナレッジソースでのAmazon Q in Connectの設定
事前準備として、Amazon Connectのインスタンスと、Amazon Q in Connectの設定をS3ナレッジソース設定を含めて実施します。
本記事ではこの後の設定が本題であるため、事前準備に関する手順は詳細には扱わず、公式ドキュメントの紹介にて代えさせていただきます。
検索対象ドキュメントの準備
今回はごく簡単に、以下の2つのドキュメントを用意し、ナレッジソースであるS3へとアップロードしておきます。
この時、エンコーディングがutf-8である必要があるため、特にWindows環境の方は留意が必要です。
旧データ
NTTデータデモシステムの社長は「旧社長太郎です」
新データ
NTTデータデモシステムの社長は「新社長次郎です」
検索対象ドキュメントへのタグ付け
以下の手順でS3にあるドキュメントにタグ付けをします。
まず、ナレッジベースの一覧を取得します。一覧の中から今回の対象とするナレッジベースのIDを控えておきます。
aws qconnect list-knowledge-bases
{
"knowledgeBaseSummaries": [
{
"knowledgeBaseId": "<ナレッジベースID>",
"knowledgeBaseArn": "<ナレッジベースArn>",
"name": "<対象のナレッジベース名>",
"knowledgeBaseType": "EXTERNAL",
"status": "ACTIVE",
<他パラメタ略>
}
]
}
次に、ナレッジベース内にあるコンテンツ一覧を取得します。
aws qconnect list-contents --knowledge-base-id <ナレッジベースID>
{
"contentSummaries": [
{
<他パラメタ略>
"contentId": "<コンテンツID>",
"contentArn": "<コンテンツArn>",
"metadata": {
<他パラメタ略>
"s3.object.key": "old.txt",
}
},
{
<他パラメタ略>
"contentId": "<コンテンツID>",
"contentArn": "<コンテンツArn>",
"metadata": {
<他パラメタ略>
"s3.object.key": "new.txt",
}
}
]
}
最後に、それぞれのコンテンツにタグを付与します。
今回は、datatypeにold,newをそれぞれold.txt, new.txtに設定します。
また、タグ付けは複数可能ですので、今回は利用しませんがサンプルとしてcontent_typeのタグも設定しておきます。
aws qconnect tag-resource --resource-arn <コンテンツArn> --tags '{"datatype":"<old もしくは new>","content_type":"IR"}'
再びコンテンツ一覧を取得すると、タグが付与されていることが確認できます。
aws qconnect list-contents --knowledge-base-id <ナレッジベースID>
{
"contentSummaries": [
{
<他パラメタ略>
"contentId": "<コンテンツID>",
"contentArn": "<コンテンツArn>",
"metadata": {
<他パラメタ略>
"s3.object.key": "old.txt",
},
"tags": {
"content_type": "IR",
"datatype": "old"
}
},
{
<他パラメタ略>
"contentId": "<コンテンツID>",
"contentArn": "<コンテンツArn>",
"metadata": {
<他パラメタ略>
"s3.object.key": "new.txt",
},
"tags": {
"content_type": "IR",
"datatype": "new"
}
}
]
}
セグメンテーション適用Lambda関数の作成
セグメンテーションの適用部分は、AWS公式WorkShopのLambdaコードを利用します。
留意点として、このLambdaコードは17行目で
AWS_REGION = os.environ.get('AWS_REGION', 'us-west-2')
の通りリージョンを設定しています。環境変数AWS_REGIONをLambda関数で、Amazon Connectインスタンスと同じリージョンになるようLambdaを作成します。
Lambda関数の権限については、同じくAWS公式Workshopの例に従って設定すれば問題ありません。
その後、Lambda関数のConnectインスタンスに追加も実施しておきます。
step-by-stepガイドのUI作成
続けて、今回の本題であるstep-by-stepガイドのUI作成を行います。
step-by-stepガイドのUIは、"フロー"ページの"ビュー"タブから新規作成することができます。
step-by-stepガイド全体のドキュメントはこちらですが、今回作成したビューのいくつかポイントをお伝えします。
まず、全体のレイアウト幅を指定できます。今回は2:10としていますが、自由に調整可能です。
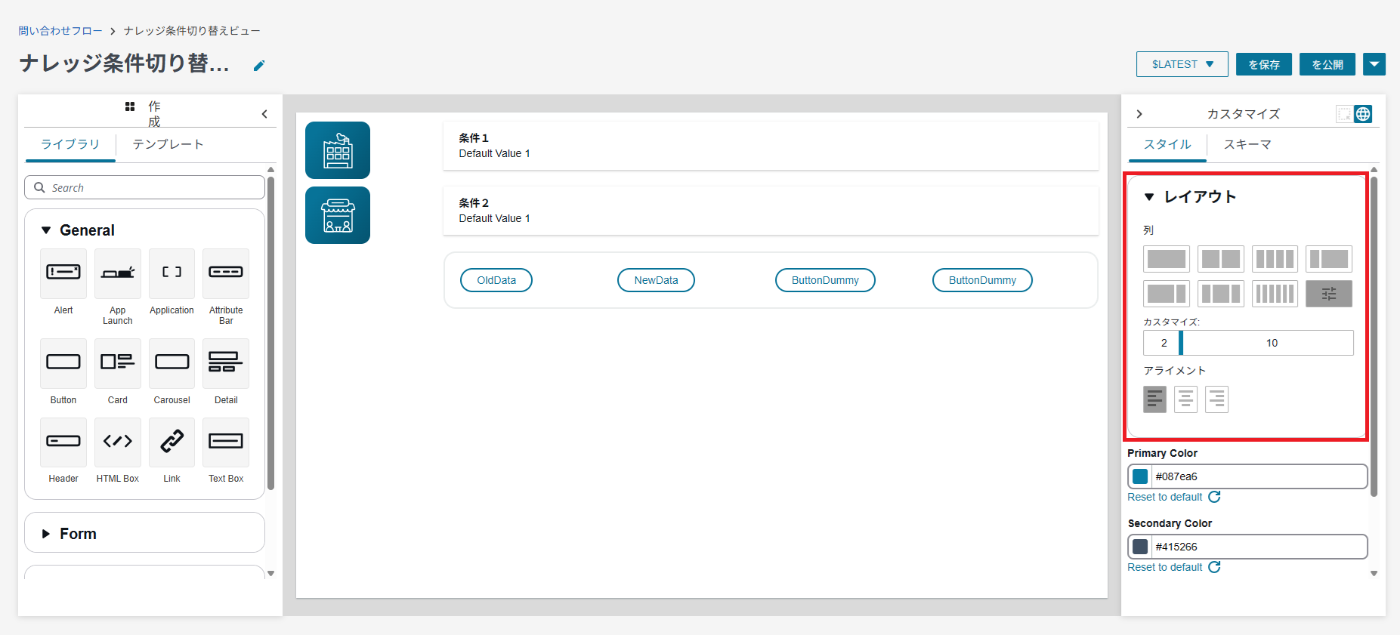 レイアウト設定
レイアウト設定
全体のレイアウト幅ではインデントが合わない場合は、空白のテキストボックスなどを配置して調整します。
 空白のテキストボックスで埋める
空白のテキストボックスで埋める
また、レイアウト幅を調整する方法として、コンテナも利用可能です。今回はボタンを複数横に並べるために、コンテナを利用しました。
 コンテナでのレイアウト設定
コンテナでのレイアウト設定
最後にコンポーネントの見た目や、内部の文字列を設定します。固定文字列を設定するほかに、右側にある雷マークを有効にすることで、フローから動的に値を渡すことも可能です。
今回は現在のコンテンツセグメンテーションの設定を動的に表示するのに利用します。
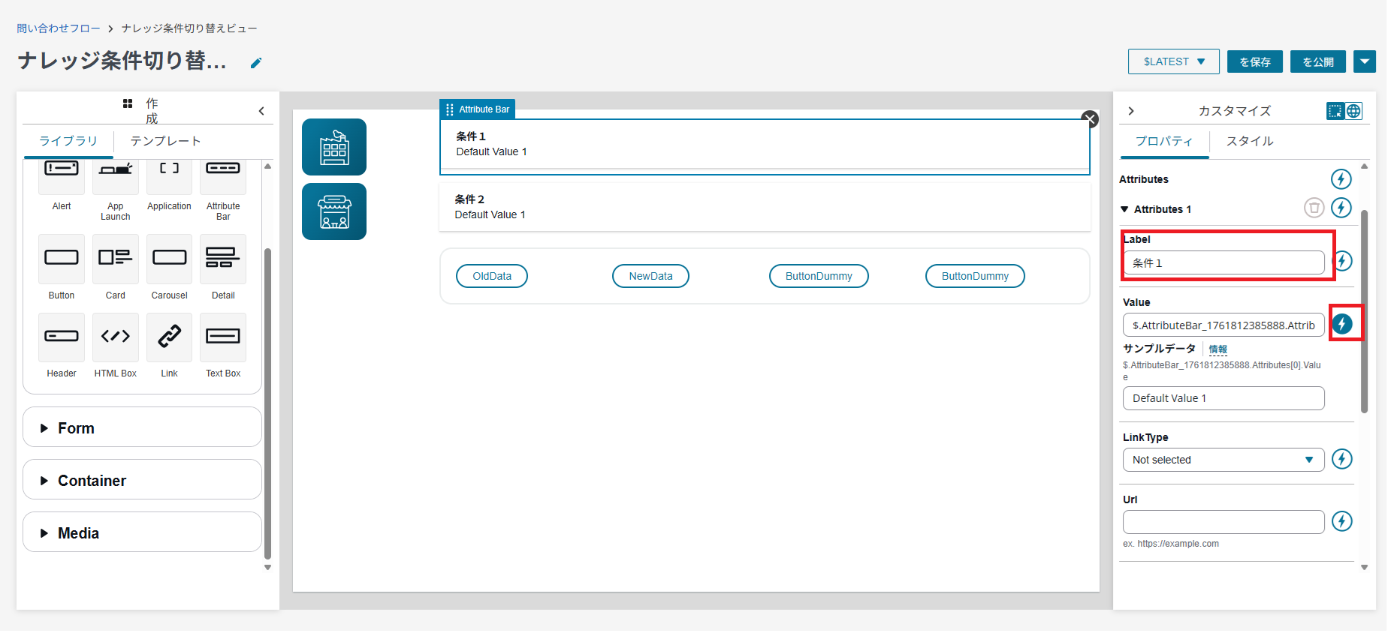 コンポーネントの設定
コンポーネントの設定
フローの作成
作成したstep-by-stepガイドを表示し、また、Step by Step内のボタンクリックに応じて遷移する、表示用フローを作成します。
全体像は以下の通りで、ボタンクリックされた場合該当の検索条件をLambdaで設定するシンプルな作りです。
 ビュー表示フロー全体像
ビュー表示フロー全体像
また、現在検索条件がどうなっているかを確認するため、ビューの動的表示を設定します。
ビューの動的パラメタに、コンタクト属性の値を渡します。
 ビューへの動的値の設定
ビューへの動的値の設定
AWS公式ワークショップの例を参考にしつつ、Lambda関数にold/newのタグでの絞り込み用の入力値を渡します。
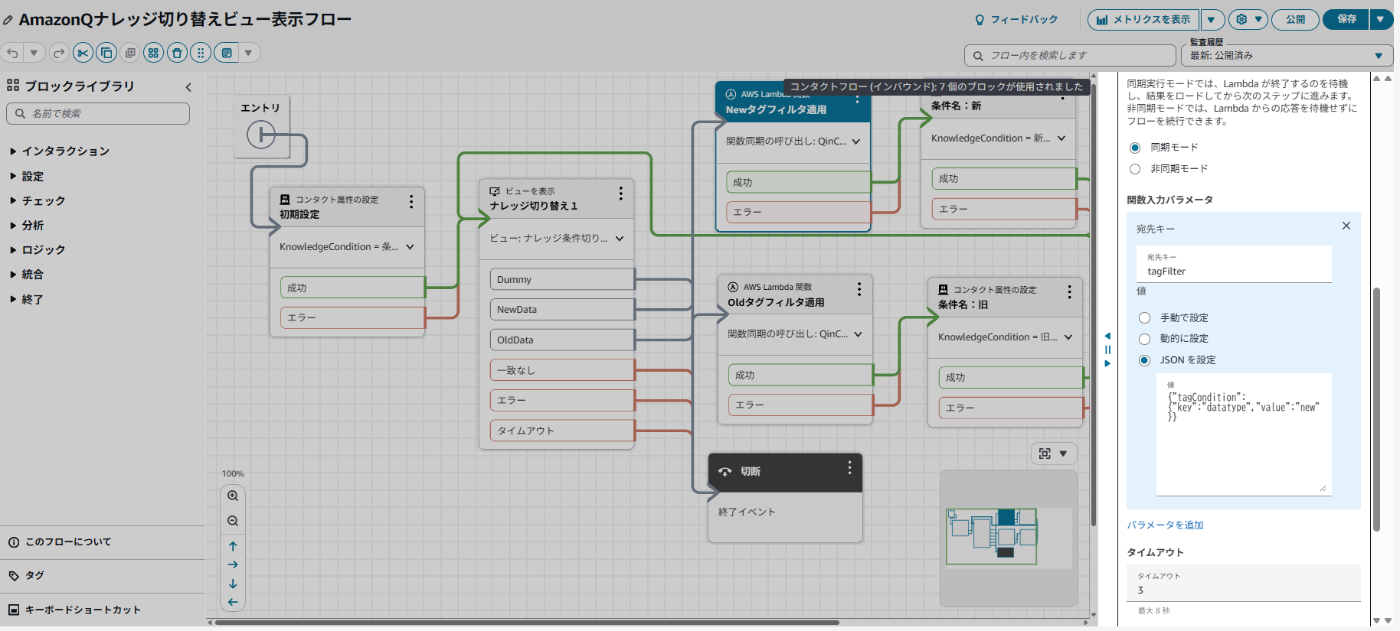 Lambdaへの入力値
Lambdaへの入力値
コンタクトフローは、ビューの表示用のイベントフロー設定程度しか行わないシンプルなものです。冒頭のマスキングがある部分は、動作確認中に意図しない箇所から電話がかかってくるのを防ぐため、筆者の電話番号以外からは切断するよう判定しています。
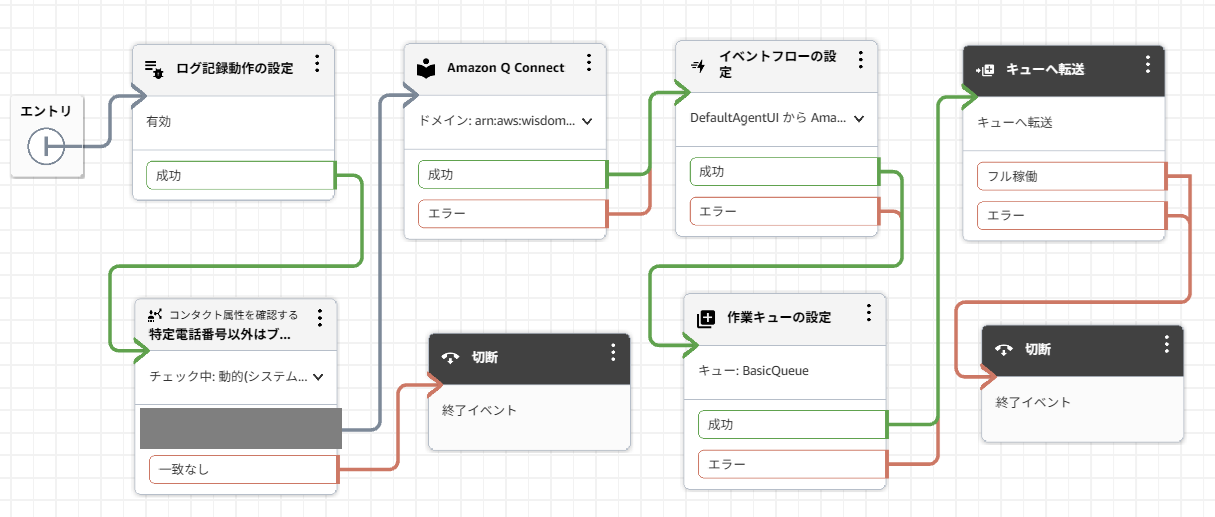 コンタクトフロー全体像
コンタクトフロー全体像
動作確認
実際に顧客からの電話が来たと仮定して動作確認をします。
まず、オペレータが電話を取ったのち、特に絞り込みのボタンを押下せずにAmazon Q in Connectへ問い合わせをします。
初期状態のため、検索条件は設定されていません。
 問い合わせ初期画面
問い合わせ初期画面
初期状態で、手動検索を実施すると矛盾する情報がある状態での回答となってしまいます。
 検索条件設定なしでの手動検索
検索条件設定なしでの手動検索
次に、旧データに絞り込みをするためのボタンを押下して手動検索を実施します。
UIに設定した動的データの受け渡しによって、現在の検索条件が表示されるとともに、検索で返ってくる回答が旧データの情報のみに基づいての回答となります。
 旧データに絞り込んでの手動検索
旧データに絞り込んでの手動検索
最後に、同様に新データのみでの絞り込みを実施すると、新データの情報のみに基づいての回答を取得できます。
 新データに絞り込んでの手動検索
新データに絞り込んでの手動検索
まとめ
本記事では、Amazon Q in Connectにおいて参照するナレッジベースのコンテンツをタグによって絞り込むことで精度向上を図る、コンテンツセグメンテーションとstep-by-stepガイドの組み合わせについて取り上げました。
実現したいコンタクトフローによっては、自動でのセグメンテーション適用よりも、オペレータによるコンテンツ絞り込みが有効な場合もあります。
step-by-stepガイドでのUI操作を利用して、別途自前でのアプリケーション構築無しにオペレータがインタラクティブに検索範囲を絞り込むことができる例をご紹介しました。
ご参考になれば幸いです。
仲間募集中です!
NTTデータ クラウド&データセンタ事業部では、以下の職種を募集しています。
- プライベートクラウドコンサル/エンジニア
- デジタルワークスペース構築/新規ソリューション開発におけるプロジェクトリーダー
- IT基盤(パブリッククラウド、プライベートクラウド)エンジニア
- パブリッククラウド/プライベートクラウドを用いた大規模プロジェクトをリードするインフラエンジニア
ソリューション紹介

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。