はじめに
最近、社内ドキュメントなどの検索手法としてRAG(Retrieval Augmented Generation)が注目を集めてます。それに伴い、パブリッククラウドではRAGを簡単に構築できるサービスが増えてきました。Amazon Web Services(AWS)ではAWS Bedrock Knowledge Bases(ナレッジベース)が提供されています。
ナレッジベースは非常に便利ですが、内部処理については公式ドキュメントに詳細が記載されておらず、ブラックボックスのようになっています(マネージドサービスにありがちです)。ナレッジベースを利用していると、内部でどのような処理が行われているのか気になってきます。
そこで本記事では、BedrockのログとOpenSearchのログを調査して、内部でどのような処理をしているかを明らかにします。今回は特に2つの処理に焦点を当てます。
- ナレッジベースへのデータ取り込み
- ナレッジベースからの検索(回答生成は除く)
本記事の対象者
すでにナレッジベースを使ってRAGを実装している方
記事の構成
記事の構成は以下の通りです。
- 環境準備
- 検証:データ取り込み
- 検証:ナレッジベースへの検索
- 最後に
注意
ログなどから確認できる「事実」は通常の文章として記載します。一方で、事実から私が「推測」した内容は次のように枠を付けて記載します。
1. 環境準備
ナレッジベースの構築には様々なパターンがありますが、今回は次のパターンで構築します。
- データソース:Amazon S3(対象ドキュメントはPDF)
- データソース解析オプション:基盤モデル
- チャンキング戦略:階層チャンク
- ベクトルDB:Amazon OpenSearch Managed Cluster(OpenSearch Service)

ナレッジベースのベクトルDBとして、最近OpenSearch Serviceが利用可能となりました。 本当は設定が楽なのでOpenSearch Serverlessを使用したいのですが、Serverlessだとクエリログが確認できないため、今回はOpenSearch Serviceで構築します。OpenSearch Service と OpenSearch Serverlessの詳しい違いについては、公式ドキュメントに詳しくまとまっています。
1.1. OpenSearch Serviceの作成
OpenSearch Serviceを事前に作成します。作成方法は次の記事を参考にしました。
作成後に別途スローログの設定を実施します。
スローログの設定
OpenSearchのクエリ内容をログとして出力するために、スローログという仕組みを利用します。本来スローログは閾値よりも遅いクエリをログとして出力し、パフォーマンスチューニングに役立てる設定です。しかし、閾値を0秒にすると、すべての検索クエリをログに出力することが可能となります。
まず、マネジメントコンソールでスローログを有効にします。

次にOpenSearchダッシュボードのDev toolsで次のクエリを実行し、閾値を0秒に設定します。
PUT knowledge-bases-test/_settings
{
"search": {
"slowlog": {
"threshold": {
"query": {
"warn": "0s",
"trace": "0s",
"debug": "0s",
"info": "0s"
}
},
"level": "TRACE"
}
}
}
1.2. Bedrockのログ設定
Bedrockの基盤モデルへのリクエストやレスポンス内容をログに残すため、「モデル呼び出しログ記録」を有効にします。
マネジメントコンソールのBedrock Configurationsでモデル呼び出しのログ記録を有効化します。今回は大容量のログが記録されることに備えて、S3にログを出力しています。

1.3. ナレッジベース作成
OpenSearch ServiceとBedrockの設定が完了したので、ナレッジベースを作成します。まず、データソースにS3を指定します。
次にデータソースの詳細を設定します。
データソース解析オプションは「パーサとしての基盤モデル」のClaude 3.7 Sonnet、チャンキング戦略は「階層チャンキング」を選択します。パーサに基盤モデル(LLM)を使用すると、写真(.png,.jpeg)やPDF等からLLMを通じてテキストや画像を抽出してくれます。

埋め込みモデルはTitan Text Embeddings V2を指定します。

ベクトルDBはOpenSearchで作成したものを設定します。

これで作成完了です。
2. 検証:データ取り込み
今回はAWSのホワイトペーパー(全10ページのPDF)を取り込みます。データの同期方法について詳しくは、次の公式ドキュメントを参考にしてください。
2.1. データ取り込み処理の流れ
データを取り込みは以下のステップで行われます。
- データソース(今回はS3)からPDFを取得
- LLM(大規模言語モデル)を使用して、PDFからテキストを抽出する
- ナレッジベース内でテキストをチャンキングする
- チャンキングしたテキストをベクトル化する
- テキストとそのベクトルをセットでOpenSearchに登録する

この中でBedrockのモデルが関連している②テキスト抽出、④ベクトル生成について、ログを確認してみましょう。
2.2. Bedrockのログを確認
テキスト抽出
最初に10件(PDFのページ分)Claudeへリクエストが送信されます。そのうちの1件のリクエストは以下のようになっていました。
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"messages": [
{
"role": "user",
"content": [
{
"text": "Extract the content from an image page and output in Markdown syntax. Enclose the content in the <markdown></markdown> tag and do not use code blocks. If the image..."
},
{
"image": {
"format": "png",
"source": {
"s3Uri": "<S3バケットのURI>"
}
}
},
{
"text": "\nBased on the image provided, try to format the context into markdown format.\n<context>\nAWS リソースのタグ付けのベストプラクティス AWS ホワイトペーパー\n\n..."
}
]
}
]
},
"inputTokenCount": 2373
},
このリクエストでは、PDFの内容をMarkdownで出力するように指示しています。各リクエストで含まれるコンテンツは次の通りです。
| 項目 | 種類 | 内容 | 目的 |
|---|---|---|---|
| ① | テキスト | "Extract the content from an image page and output in Markdown syntax..." で始まる指示文 | PDFパーサーとしてのLLMへの指示 |
| ② | 画像 | PDFの1ページ分の画像(S3URI形式で指定) | LLMに解析させるPDFページの視覚情報 |
| ③ | テキスト | "Based on the image provided, try to format the context into markdown format."で始まる指示文とPDFに元々組み込まれているテキスト情報 | LLMがコンテキストとして利用する生のテキストデータ |
コンテンツを確認すると、PDFがページごとに分割されてMarkdown形式で生成されています。また、PDFの視覚情報(画像)と埋め込まれたテキストの両方を使って、PDFからMarkdownを生成している事が分かります。これにより画像のみでは取得できない正確なテキスト情報と、レイアウト情報の両方を活用する賢い設計です。
※PDFは構造化データであり、pypdf等のツールを使えばテキスト情報のみを抽出することが可能です。
ベクトル化
次に、33件Titanへリクエストを送信しています。そのうちの1件のリクエストは以下のようになっていました。
"operation": "InvokeModel",
"modelId": "arn:aws:bedrock:ap-northeast-1::foundation-model/amazon.titan-embed-text-v2:0",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"inputText": "# AWS リソースのタグ付けのベストプラクティス AWS ホワイトペーパー ## AWS 用語集...",
"dimensions": 1024,
"embeddingTypes": [
"float"
]
},
"inputTokenCount": 46
},
このリクエストでは、先程Claudeが生成したMarkdownテキストを適切なサイズに分割した「子チャンク」ごとに1024次元のベクトルが生成されます。今回の例では、10ページのPDFが33チャンクに分割されていたため、33回リクエストが送信されます。
2.3. データ取り込みのまとめ
データ取り込みについて、今回分かった処理ステップをまとめます。
3. 検証:ナレッジベースへの検索
今回は以下の条件で検索します。
- データソースの取得のみ(LLMによる回答生成はなし)
- 検索件数:5件
- 検索タイプ:
- セマンティック検索(ベクトル検索)
- ハイブリッド検索(全文検索+ベクトル検索)
- フィルター:
- なし(全ドキュメントから検索)
- 特定のページ数を指定(例:「ページ番号が3のドキュメントだけを検索対象」)
- 検索クエリ:
テストのクエリ
検索結果のページ番号はメタデータのx-amz-bedrock-kb-document-page-numberに保持されているので、この値でフィルターしていきます。今回はマネジメントコンソールから検索を実施しました。
3.1. 検索処理の流れ
検索は以下のステップで行われます。
- 質問をベクトル化する
- OpenSearchへ検索クエリを送信する
- ユーザーに対して、検索結果を返却する

この中で②OpenSearchへの検索について、実際に動かしながらログを確認していきます。
3.2. OpenSearchのログ
セマンティック検索 & フィルタリングなし
この条件で検索すると、OpenSearchへ検索クエリが1回だけ実行されています。具体的には
- k-NN近傍によるベクトル検索を実施
-
sizeにて検索結果として返す件数を5件に設定
していることが分かります。単純なベクトル検索です。
[2025-04-04T08:40:37,981][WARN ][index.search.slowlog.query] [6b722bc89d9a394edfdd2eb4330efe79] [knowledge-bases-test][1] took[258.7ms], took_millis[258], total_hits[5 hits], stats[], search_type[QUERY_THEN_FETCH], total_shards[5], source[
{
"size": 5,
"query": {
"knn": {
"bedrock-knowledge-base-default-vector": {
"vector": [
-0.04912188,...
],
"k": 10,
"boost": 1
}
}
}
}
], id[],
脱線
ここで少し脱線して、このクエリをOpenSearchに直接検索してみました。すると、次のように5件の結果が返却されます(重要でない箇所やS3URIの記載の場所は省略しています)。
OpenSearchの検索結果
"hits": [
{
"_source": {
"x-amz-bedrock-kb-document-page-number": 4,
"AMAZON_BEDROCK_METADATA": """{"parentText":"# AWS リソースのタグ付けのベストプラクティス 発行日: 2023 年 3 月 30 日 (ドキュメントの改訂) アマゾン ウェブ サービス (AWS) では、タグの形式でメタデータを多くの AWS リソースに割り当てることができます。"}""",
"bedrock-knowledge-base-default-vector": [
0.0030231706,...
],
"id": "453e3709-5189-4777-a420-706f46716330",
"AMAZON_BEDROCK_TEXT_CHUNK": "追加情報については、「AWSクラウド基盤の構築」を参照してください。 ## Well-Architected の実現状況の確認 AWS Well-Architected フレームワークは、クラウド内でのシステム構築に伴う意思決定の長所と短所を理解するのに役立ちます。このフレームワークの 6 つの柱により、信頼性、安全性、効率、費用対効果、持続可能性の高いシステムを設計および運用するための、アーキテクチャのベストプラクティスを確認できます。AWS Management Console で無料で提供されている AWS Well-Architected Tool を使用すると、柱ごとに一連の質問に答えることで、これらのベストプラクティスに照らしてワークロードを評価できます。"
}
},
{
"_source": {
"x-amz-bedrock-kb-document-page-number": 9,
"AMAZON_BEDROCK_METADATA": """{"parentText":"# AWS リソースのタグ付けのベストプラクティス\n## AWS ホワイトペーパー\n| ユースケース | タグキー | 根拠 | 許可された値 |\n|-|-|-|-|\n| | | | assurance , production |\n| ディザスタリカバリ | example-i nc:disaster-recovery:rpo | リソースの目標復旧時点 (RPO) の定義 | 6h, 24h |\n| コスト配分 | example-i nc:cost-a llocation:business-unit | 財務チームには、各チームの使用状況と支出に関するコストレポートが必要です。 | corporate , recruitme nt , support, engineering "}""",
"bedrock-knowledge-base-default-vector": [
-0.020821953,...
],
"id": "ce1da241-55d3-4c4c-a1e3-1370d0cd2496",
"AMAZON_BEDROCK_TEXT_CHUNK": "# AWS リソースのタグ付けのベストプラクティス ## AWS ホワイトペーパー ユースケース タグキー 根拠 許可された値 assurance , production ディザスタリカバリ examplei nc:disasterrecovery:rpo リソースの目標復旧時点 (RPO) の定義 6h, 24h コスト配分 examplei nc:costa llocation:businessunit 財務チームには、各チームの使用状況と支出に関するコストレポートが必要です。 corporate , recruitme nt , support, engineering"
}
},
{
"_source": {
"x-amz-bedrock-kb-document-page-number": 9,
"AMAZON_BEDROCK_METADATA": """{"parentText":"# AWS リソースのタグ付けのベストプラクティス\n## AWS ホワイトペーパー\n| ユースケース | タグキー | 根拠 | 許可された値 |\n|-|-|-|-|\n| | | | assurance , production |\n| ディザスタリカバリ | example-i nc:disaster-recovery:rpo | リソースの目標復旧時点 (RPO) の定義 | 6h, 24h |\n| コスト配分 | example-i nc:cost-a llocation:business-unit | 財務チームには、各チームの使用状況と支出に関するコストレポートが必要です。 | corporate , recruitme nt , support, engineering "}""",
"bedrock-knowledge-base-default-vector": [
-0.004895878,...
],
"id": "64986125-7184-4356-9ca5-73b22f821389",
"AMAZON_BEDROCK_TEXT_CHUNK": "# AWS リソースのタグ付けのベストプラクティス ## AWS ホワイトペーパー"
}
},
{
"_source": {
"x-amz-bedrock-kb-document-page-number": 7,
"AMAZON_BEDROCK_METADATA": """{"parentText":"# AWS リソースのタグ付けのベストプラクティス\n## AWS 生成されたタグキー\n| AWS 生成されたタグキー | 根拠 |\n|-|-|\n| aws:cloudformation:stack-name | リソースを作成した AWS CloudFormation スタックを識別します |\n| lambda-console:blueprint | AWS Lambda 関数のテンプレートとして使用されるブループリントを識別します。 |\n| elasticbeanstalk:environment-name | リソースを作成したアプリケーションを識別します。 |\n|"}""",
"bedrock-knowledge-base-default-vector": [
-0.028639283,...
],
"id": "80ebe479-043b-4a5e-9804-d8e8880c8a25",
"AMAZON_BEDROCK_TEXT_CHUNK": "# AWS リソースのタグ付けのベストプラクティス ## AWS 生成されたタグキー"
}
},
{
"_source": {
"x-amz-bedrock-kb-document-page-number": 9,
"AMAZON_BEDROCK_METADATA": """{"parentText":"# AWS リソースのタグ付けのベストプラクティス\n## AWS ホワイトペーパー\n| ユースケース | タグキー | 根拠 | 許可された値 |\n|-|-|-|-|\n| | | | assurance , production |\n| ディザスタリカバリ | example-i nc:disaster-recovery:rpo | リソースの目標復旧時点 (RPO) の定義 | 6h, 24h |\n| コスト配分 | example-i nc:cost-a llocation:business-unit | 財務チームには、各チームの使用状況と支出に関するコストレポートが必要です。 | corporate , recruitme nt , support, engineering "}""",
"bedrock-knowledge-base-default-vector": [
0.02869649,...
],
"id": "ea26de9b-4db0-4676-8d8e-bb5fe04aa912",
"AMAZON_BEDROCK_TEXT_CHUNK": "タグはシンプルで柔軟性があります。タグのキーと値はどちらも可変長の文字列で、幅広い文字セットをサポートできます。長さと文字セットの詳細については、AWS 全般リファレンスの「AWS リソースのタグ付け」を参照してください。タグでは大文字と小文字を区別します。つまり、costCenter と costcenterとは別のタグキーです。国によって単語のスペルが異なる場合があり、それがキーに影響する可能性があります。たとえば、米国ではキーを costcenter と定義しても、英国では costcentre が優先される場合があります。リソースタグ付けの観点から見ると、これらは異なるキーです。タグ付け戦略の一環として、スペル、大文字と小文字、句読点を定義します。"
}
}
]
}
}
ここで重要なのは、AMAZON_BEDROCK_METADATA内に子チャンクに対する親チャンクが格納されていることです。検索結果を見ると、今回の5件の検索結果のうち3件(2位・3位・5位)の親チャンクが同じでした。もし、そのまま親チャンクをナレッジベースに出力すると、ナレッジベースの回答が重複します。
しかし、実際にナレッジベース上の検索結果を見ると、3件だけ表示されてます。
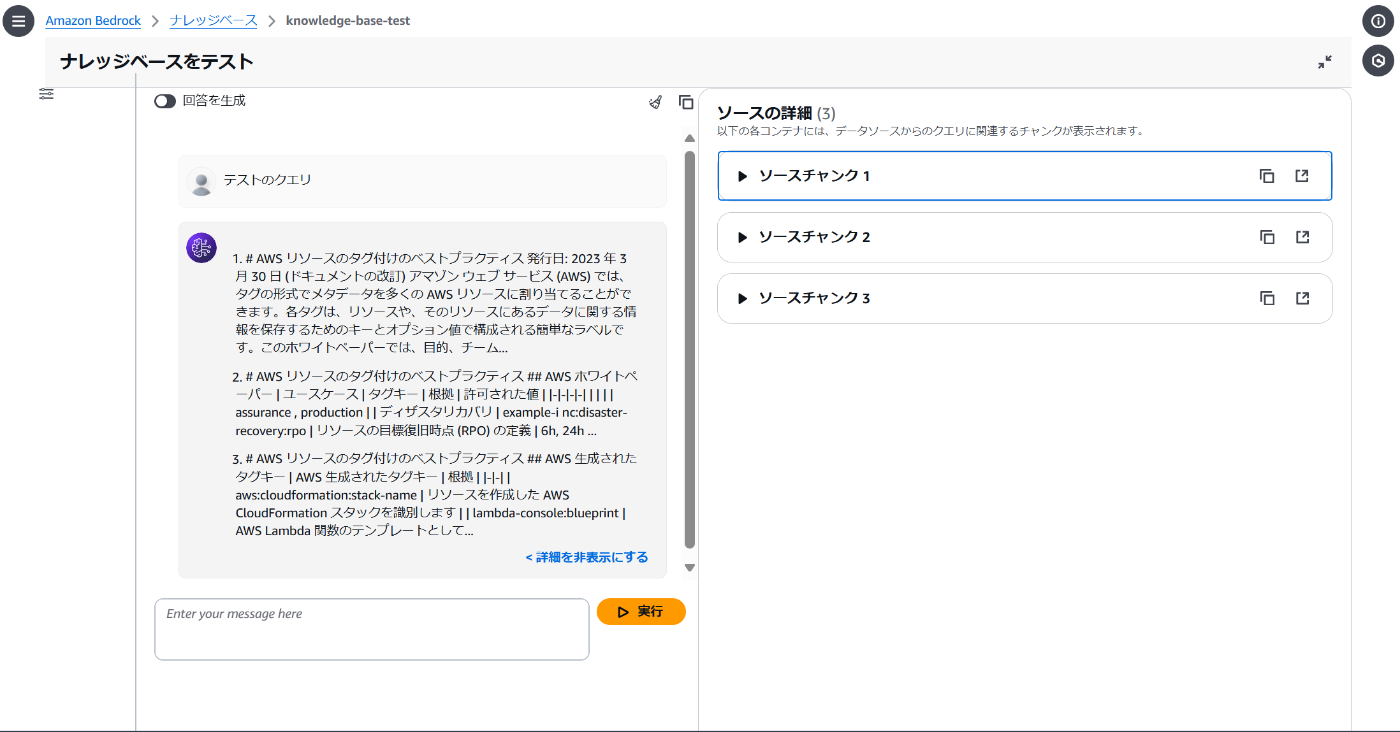
中身を確認すると、ナレッジベースが表示したのはOpenSearchの検索結果の1位・2位・4位のチャンクでした。整理すると以下の図のようになります。

ハイブリッド検索 & フィルタリングなし
この条件で検索すると、OpenSearchへベクトル検索と全文検索が別々のクエリとして実行されています。
- ベクトル検索(セマンティック検索のときと全く同じ)
[2025-04-04T08:48:08,602][WARN ][index.search.slowlog.query] [6b722bc89d9a394edfdd2eb4330efe79] [knowledge-bases-test][4] took[3ms], took_millis[3], total_hits[7 hits], stats[], search_type[QUERY_THEN_FETCH], total_shards[10], source[
{
"size": 5,
"query": {
"knn": {
"bedrock-knowledge-base-default-vector": {
"vector": [
-0.04912188,...
],
"k": 10,
"boost": 1
}
}
}
}
- 全文検索
AMAZON_BEDROCK_TEXT_CHUNKに対する全文検索です。
[2025-04-04T09:59:10,455][WARN ][index.search.slowlog.query] [6b722bc89d9a394edfdd2eb4330efe79] [knowledge-bases-test][3] took[1.1s], took_millis[1122], total_hits[9 hits], stats[], search_type[QUERY_THEN_FETCH], total_shards[5], source[
{
"size": 5,
"query": {
"match": {
"AMAZON_BEDROCK_TEXT_CHUNK": {
"query": "テストのクエリ",
"operator": "OR",
"prefix_length": 0,
"max_expansions": 50,
"fuzzy_transpositions": true,
"lenient": false,
"zero_terms_query": "NONE",
"auto_generate_synonyms_phrase_query": true,
"boost": 1
}
}
}
}
], id[],
OpenSearchでは2.11以降では、パイプラインを使ったネイティブなハイブリッド検索機能があります。しかし、ナレッジベースではその機能は使用せず、ベクトル検索と全文検索を別々に実行してます。
現在、サーバーレスコレクションは OpenSearch バージョン 2.0.x を実行します。
セマンティック検索 & フィルタリングあり
この条件で検索すると、OpenSearchへ検索クエリが1回だけ実行されています。具体的には
- k-NN近傍によるベクトル検索
- knnクエリ内に
filterを配置し、x-amz-bedrock-kb-document-page-numberでフィルタリング
していることが分かります。
[2025-04-04T10:29:18,538][WARN ][index.search.slowlog.query] [6b722bc89d9a394edfdd2eb4330efe79] [knowledge-bases-test][4] took[8.8ms], took_millis[8], total_hits[0 hits], stats[], search_type[QUERY_THEN_FETCH], total_shards[5], source[
{
"size": 5,
"query": {
"knn": {
"bedrock-knowledge-base-default-vector": {
"vector": [
-0.04912188,...
],
"k": 10,
"filter": {
"bool": {
"must": [
{
"term": {
"x-amz-bedrock-kb-document-page-number": {
"value": 8,
"boost": 1
}
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"boost": 1
}
}
}
}
], id[],
ここで使われているフィルタリングは、Efficient k-NN filteringという手法で、ベクトル探索中にフィルター処理を適用します。Pre-filtering(最初にフィルタリングして候補を絞ってから、その中でベクトル検索する方法)と同じ結果ですが、非常に高速な処理になります。詳細は公式ドキュメントが参考になります。
3.3. ナレッジベースへの検索のまとめ
検索処理について、今回分かったことをまとめます。
4. 最後に
本記事では、ナレッジベースの内部処理について、BedrockとOpenSearchのログを調べることで明らかにしました。PDFからのテキスト抽出や親チャンクの重複削除など、ナレッジベース側で工夫している箇所があり、マネージドサービスを使いたくなります。本記事がナレッジベースの内部処理に興味がある方にとって役立てば幸いです。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。