はじめに
以前の記事では、Snowflake Openflow × PostgreSQL をテーマに、構造化データの初回同期(Snapshot Load)から増分同期(Incremental Load)までを検証しました。GUIベースでフローを構築し、Amazon Web Services (AWS) 上にBYOC構成での環境構築まで実践できる内容となっており、
「まずOpenflowを触ってみたい!」
「環境構築から始めたい!」
という方には、先にそちらの記事をおすすめします。
今回はいよいよ、非構造化データ(PDF) に挑戦します。
具体的には、PDFファイルをSnowflakeの内部ステージにアップロードし、Openflowを使って文書をチャンク化(分割)、さらにSnowflake Cortexでベクトル埋め込み(EMBED_TEXT)を生成し、RAG(Retrieval-Augmented Generation)検索に活用するためのデータ基盤を整備していきます。
この一連の流れを通じて、「非構造データをベクトル検索やRAGで活用できるように前処理する仕組み」 を解説していきます。
1.RAGとは(簡単に)
LLM(大規模言語モデル)は非常に自然な文章を生成できますが、ときに実在しない情報をもっともらしく答えてしまうことがあります。これを「ハルシネーション(hallucination)」と呼びます。
その対策の一つがRAG(Retrieval-Augmented Generation)です。
RAGは、LLMが応答を生成する前に、正確かつ最新の情報を文書から検索し、それを文脈として活用することで、より事実に基づいた回答を促す仕組みです。
Snowflake公式ブログの図解がとてもわかりやすいので、参考に貼っておきます👇
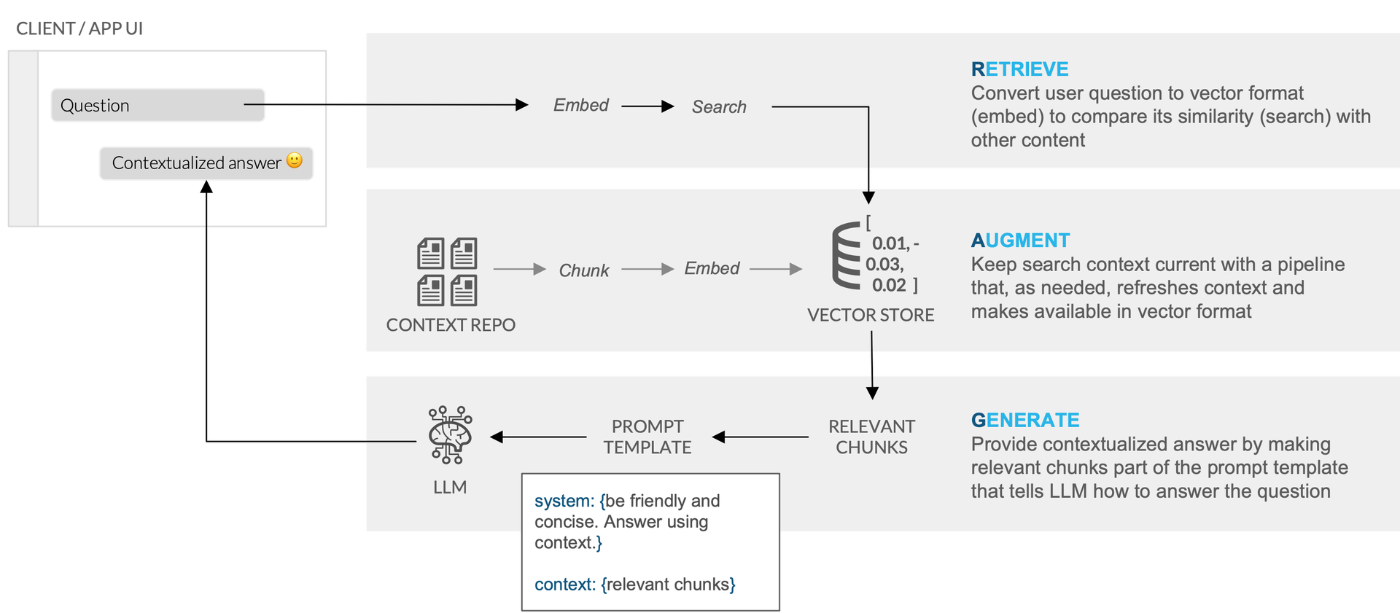
👉 公式ブログはこちら:Snowflake Cortexを使用した簡単かつ安全なRAGからLLMへの推論
なお、このRAGを実現するには、検索対象となる文書(今回はPDF)を LLMが扱いやすい単位に分割(チャンク化) し、 ベクトル形式に変換(エンベディング) しておく必要があります。
この事前処理によって、質問文も同様にベクトル化することで、両者のベクトル同士の類似度(例:コサイン類似度)を比較し、最適なチャンクを効率よく検索できるようになります。
2. Openflowで実現するRAG検索の流れ
以下は今回検証する全体の流れを表しています。

上記を大きく分類すると
- ① PDFをSnowflakeの内部ステージに手動アップロード
- ②〜⑦ Openflowを用いて処理(内部ステージのドキュメントを走査し、ステージ上のPDFをチャンクに分割&チャンクテーブルに格納)
- ⑧〜⑨ チャンクテーブルを元に、Streamlit等のアプリケーションから質問文を投げて検索することも可能です(※本記事では検索部分の実装は扱いません)
2.1 なぜOpenflowを使うのか?
通常、この②〜⑦の処理(PDFの検出〜チャンク化〜ベクトル埋め込み〜テーブル登録)を手動で実行する場合、以下のようなステップが必要になります。
まず、PDFを読み取ってチャンクに分割するためのUDFを事前に定義し、毎回実行する必要があります。
CREATE OR REPLACE FUNCTION PDF_TEXT_CHUNKER(FILE_URL STRING)
RETURNS TABLE (CHUNK VARCHAR)
LANGUAGE PYTHON
...
次に、生成されたチャンクに対して、Snowflake Cortexの EMBED_TEXT_768 関数を用いてベクトルを生成し、以下のように手動でチャンクテーブルにINSERT文を発行する必要があります。
INSERT INTO DOCS_CHUNKS_TABLE (...)
SELECT ...
FROM
DIRECTORY(@DOCS),
TABLE(PDF_TEXT_CHUNKER(...)) AS FUNC;
こうした一連の前処理は、運用上の手間や人的ミスのリスクにつながりやすく、再現性や自動化に課題が残ります。
Openflowを使えば、これらの処理をGUI上で構築し、アップロードされたPDFに対してチャンク処理〜ベクトル埋め込み〜保存までを自動で実行できるため、実運用に耐えるフローを簡単に構築できます。
なお、上記のチャンク処理や埋め込み生成の流れについては、以下の記事を参考にしました。SnowflakeでRAG環境を構築する際の全体像を把握したい方には特におすすめです。
2.2 Openflowのメリット
Openflowを使えば、PDFのチャンク化 → ベクトル化 → テーブル登録といった一連の前処理を、GUI上で自動化できます。
本検証では内部ステージを使い、定期実行または手動トリガーで処理を実行していますが、Google Driveなど外部ソースと連携すればファイル更新をトリガーに自動実行する構成(イベントドリブン) も実現可能と考えています。
「PDFを置くだけで、RAGに必要なベクトルデータが生成される」
そんな柔軟な運用を、OpenflowならGUIだけで構築できます。
3. 実装ステップの全体像
第2章で、RAG検索の全体フローを確認しました。ここでは、改めてそのフローを構成する技術要素や処理ブロックを簡単に整理しておきます。
まずは全体像をもう一度図で振り返ってみましょう👇

- ① PDFをSnowflakeの内部ステージに手動アップロード
- ②〜⑦ Openflowを用いて処理(内部ステージのドキュメントを走査し、ステージ上のPDFをチャンクに分割&チャンクテーブルに格納)
- ⑧〜⑨ チャンクテーブルを元に、Streamlit等のアプリケーションから質問文を投げて検索することも可能です(※本記事では検索部分の実装は扱いません)
3.1 Openflowのフロー構成
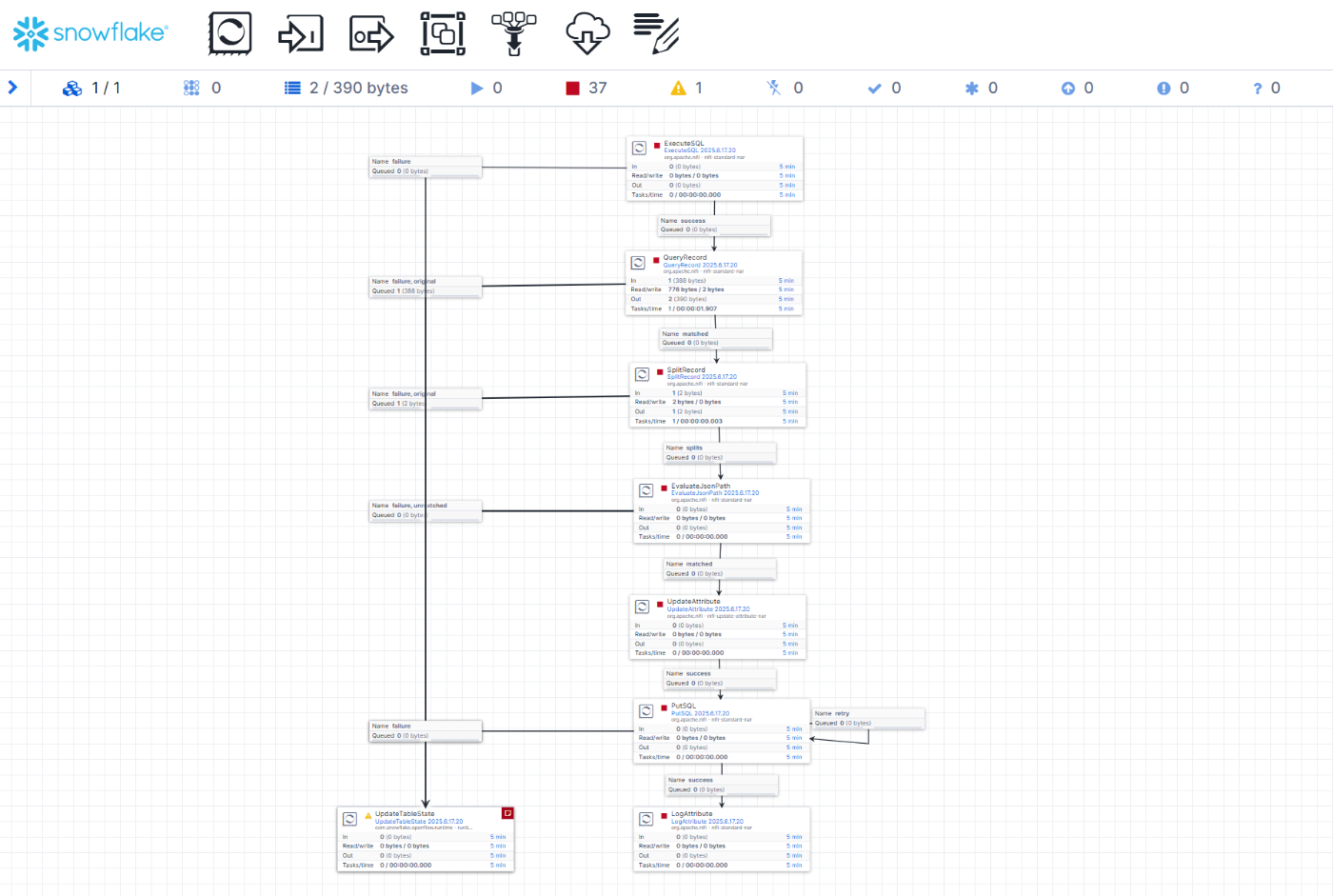
②〜⑦の処理について、Openflow上で構築しているProcessorの流れを見ていきましょう。
この一連のフローでは、PDFのファイル検出 → チャンク化処理 → ベクトル埋め込み → データ登録までを実行しています。
各Processorの役割は以下の通りです👇
| ステップ | Processor名 | 処理内容 |
|---|---|---|
| ② | ExecuteSQL |
チャンクテーブルとステージ内ファイルを比較し、未登録のPDFファイル名のみを抽出 |
| ③ | QueryRecord |
②で取得した結果(Avro形式)をJSON形式に変換して扱いやすくする |
| ④ | SplitRecord |
複数件あるレコードを1ファイルにつき1FlowFileになるよう分割 |
| ⑤ | EvaluateJsonPath |
JSON構造から、PDFパスやファイル名などの属性を抽出しFlowFile属性として保持 |
| ⑥ | UpdateAttribute |
⑤で抽出した属性をもとに、チャンク化および埋め込みを行うSQLクエリを生成 |
| ⑦ | PutSQL |
⑥で生成されたクエリを実行し、チャンクテーブルへデータをINSERT |
4. OpenflowでPDFチャンク化を自動化する
先ほど各プロセッサの役割をご紹介したとおり、以下のような構成で実装しています👇
4.1 事前準備
この後に続く Openflow のチャンク化処理を実行するために、以下の ステージ/テーブル/UDF をあらかじめ作成しておきます。
-- Openflow用に作成したデータベースとスキーマを指定
USE DATABASE MY_OPENFLOW_DB;
CREATE SCHEMA MY_OPENFLOW_SCHEMA;
-- pdf用のステージ作成
CREATE OR REPLACE STAGE openflow_pdf_stage;
-- チャンクテーブルの作成
CREATE OR REPLACE TABLE DOCS_CHUNKS_TABLE (
RELATIVE_PATH VARCHAR(16777216), -- PDFファイルへの相対パス
SIZE NUMBER(38,0), -- PDFファイルのサイズ
FILE_URL VARCHAR(16777216), -- PDFのURL
SCOPED_FILE_URL VARCHAR(16777216), -- スコープ付きURL
CHUNK VARCHAR(16777216), -- テキストの一部
CHUNK_VEC VECTOR(FLOAT, 768) ); -- VECTORデータタイプの埋め込み
-- チャンク処理用のUDF
CREATE OR REPLACE FUNCTION MY_OPENFLOW_DB.MY_OPENFLOW_SCHEMA.OPENFLOW_PDF_TEXT_CHUNKER("FILE_URL" VARCHAR)
RETURNS TABLE ("CHUNK" VARCHAR)
LANGUAGE PYTHON
RUNTIME_VERSION = '3.9'
PACKAGES = ('snowflake-snowpark-python','PyPDF2','langchain')
HANDLER = 'pdf_text_chunker'
AS '
from snowflake.snowpark.types import StringType, StructField, StructType
from langchain.text_splitter import RecursiveCharacterTextSplitter
from snowflake.snowpark.files import SnowflakeFile
import PyPDF2, io
import logging
import pandas as pd
class pdf_text_chunker:
def read_pdf(self, file_url: str) -> str:
logger = logging.getLogger("udf_logger")
logger.info(f"Opening file {file_url}")
with SnowflakeFile.open(file_url, ''rb'') as f:
buffer = io.BytesIO(f.readall())
reader = PyPDF2.PdfReader(buffer)
text = ""
for page in reader.pages:
try:
text += page.extract_text().replace(''\\n'', '' '').replace(''\\0'', '' '')
except:
text = "Unable to Extract"
logger.warn(f"Unable to extract from file {file_url}, page {page}")
return text
def process(self,file_url: str):
text = self.read_pdf(file_url)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 4000, #Adjust this as you see fit
chunk_overlap = 400, #This let''s text have some form of overlap. Useful for keeping chunks contextual
length_function = len
)
chunks = text_splitter.split_text(text)
df = pd.DataFrame(chunks, columns=[''chunks''])
yield from df.itertuples(index=False, name=None)
';
4.2 Openflowの構成をセットアップする
それでは、PDFをチャンク化・処理するフローを構築するために、Openflow上で必要な構成をセットアップしていきます。
①プロセッサグループを新規作成
チャンク処理用のフローをまとめるために、専用のプロセッサグループを作成します。
② Controller Service の設定
次に、必要な Controller Service(接続設定やデータ変換の共通定義) を追加します。
まずは、全体のイメージをご覧ください👇
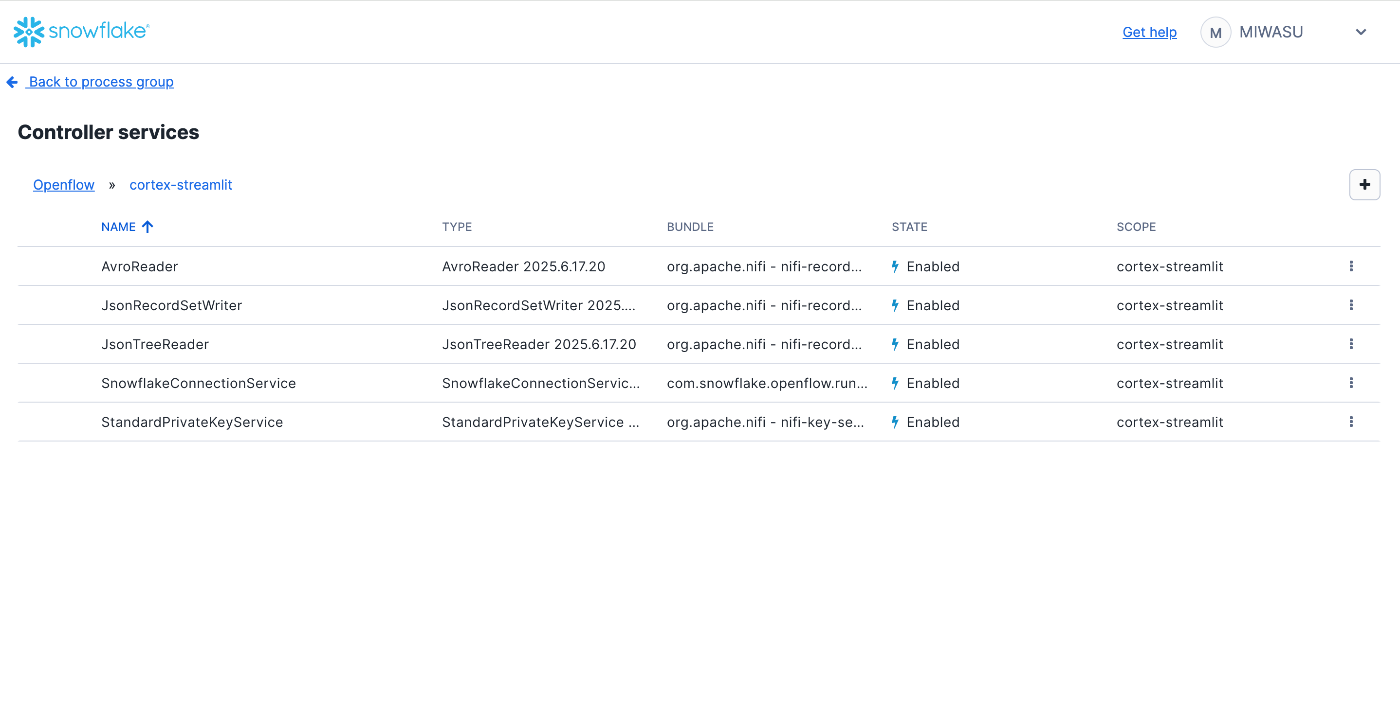
上図のように、今回は以下の5つのController Serviceを利用します。
| 用途 | サービス名 | 説明 |
|---|---|---|
| 接続用 | SnowflakeConnectionService |
SnowflakeとのJDBC接続 |
| 認証用 | StandardPrivateKeyService |
秘密鍵による認証情報の管理 |
| データ変換 | AvroReader |
Avro形式の読み取り |
JsonRecordSetWriter |
JSON形式への書き出し | |
JsonTreeReader |
JSONからの読み取り |
詳細な設定内容は、以下の公式ドキュメントを参照してください:
All controllers
③ プロセッサを配置・設定する
今回の処理で使用するプロセッサ一覧は以下の通りです。
PDFの検出からチャンク保存までをつなぎます👇
| ステップ | Processor名 | 処理内容 |
|---|---|---|
| ② | ExecuteSQL |
チャンクテーブルとステージを比較し、未登録のPDFファイルだけ抽出 |
| ③ | QueryRecord |
抽出結果(Avro形式)をJSON形式に変換 |
| ④ | SplitRecord |
複数行レコードを1ファイル = 1FlowFile に分割 |
| ⑤ | EvaluateJsonPath |
JSONからファイルパスやURLを属性として抽出 |
| ⑥ | UpdateAttribute |
抽出した属性を元に、チャンク&ベクトル化のSQLクエリを生成 |
| ⑦ | PutSQL |
生成したクエリを実行し、チャンクテーブルへINSERT |
各Processorの細かい設定内容は、以下のドキュメントが参考になります:
All processors
ここからは、各Processorの役割とポイントを1つずつ見ていきましょう👇
ステップ②ExecuteSQL:未チャンク化ファイルを抽出

まず最初に、チャンク化がまだ行われていないPDFを選定するステップです。
ExecuteSQL プロセッサでは、以下の2つのSQLを使って一時テーブルを作成・参照します。
-- SQL Pre-Query
CREATE OR REPLACE TEMPORARY TABLE new_docs AS
SELECT *
FROM directory(@docs)
WHERE RELATIVE_PATH NOT IN (
SELECT DISTINCT RELATIVE_PATH FROM DOCS_CHUNKS_TABLE
);
-- SQL Query
SELECT * FROM new_docs;
ステップ③ QueryRecord:Avro → JSON に変換

Snowflakeから取得した結果はAvro形式なので、扱いやすいJSON形式に変換します。
| 項目 | 設定内容 |
|---|---|
| Record Reader | AvroReader |
| Record Writer | JsonRecordSetWriter |
| クエリ | SELECT RELATIVE_PATH, FILE_URL FROM FLOWFILE |
ステップ④ SplitRecord(1ファイルごとに分割)

QueryRecord で抽出したPDFファイル情報は複数レコードを含む可能性があります。
ここで SplitRecord を使って、1レコード=1 FlowFile に分割します。
ステップ⑤EvaluateJsonPath:属性として取り出す

JSONから必要な値だけをFlowFile属性として取り出します。
| 属性名 | JSONPath式 |
|---|---|
file_url |
$.FILE_URL |
relative_path |
$.RELATIVE_PATH |
ステップ⑥UpdateAttribute:チャンク処理用のSQLを生成

各PDFファイルごとに、チャンク化+ベクトル生成+INSERTを行うSQL文を sql.query 属性として定義します。生成したクエリは次のPutSQLで実行します。
INSERT INTO docs_chunks_table (
relative_path, size, file_url, scoped_file_url, chunk, chunk_vec
)
SELECT
'${relative_path}',
${fileSize},
'${file_url}',
build_scoped_file_url(@docs, '${relative_path}'),
func.chunk,
SNOWFLAKE.CORTEX.EMBED_TEXT_768('e5-base-v2', chunk)
FROM TABLE(
openflow_pdf_text_chunker(build_scoped_file_url(@docs, '${relative_path}'))
) AS func;
📌 主なポイント:
openflow_pdf_text_chunker(...) でPDFをチャンク化
EMBED_TEXT_768(...) で各チャンクをベクトル化
結果を docs_chunks_table に INSERT
※PDFの読み取りには「PerformSnowflakeCortexOCR」、チャンク処理には「ChunkRecordText」、エンベディングには「CreateSnowflakeEmbeddings」など、Snowflakeが提供するプロセッサの活用を検討していましたが、検証に用いているアカウントのパラメータなどの制約により、今回は見送ることとしました。今回は、代替手段としてUDFを用いて対応していますが、今後あらためて検証を行い、結果を記事として公開する予定です。
ステップ⑦PutSQL:生成したSQLを実行

最後に、UpdateAttribute で定義した sql.query をそのまま実行して、チャンクとベクトルを登録します。
✅ ここまでの流れで、PDFの検出からチャンク生成・ベクトル化・保存までが 完全自動化 されています!
5. 実行結果と考察
設定が完了したので、実際にフローを実行してみます。
まずは、チャンクテーブルにすでに格納されているPDFファイルを確認します。
tabako.pdf、alcohol.pdf(いずれも厚生労働省のホームページより引用)については、すでにチャンク化済みです。
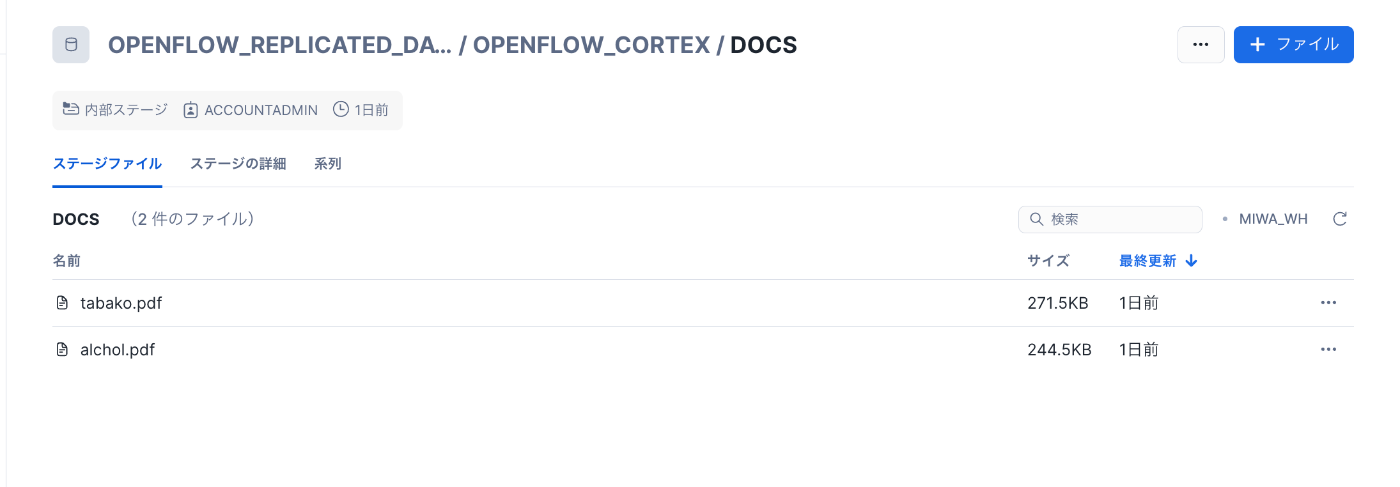

出典:厚生労働省ホームページ
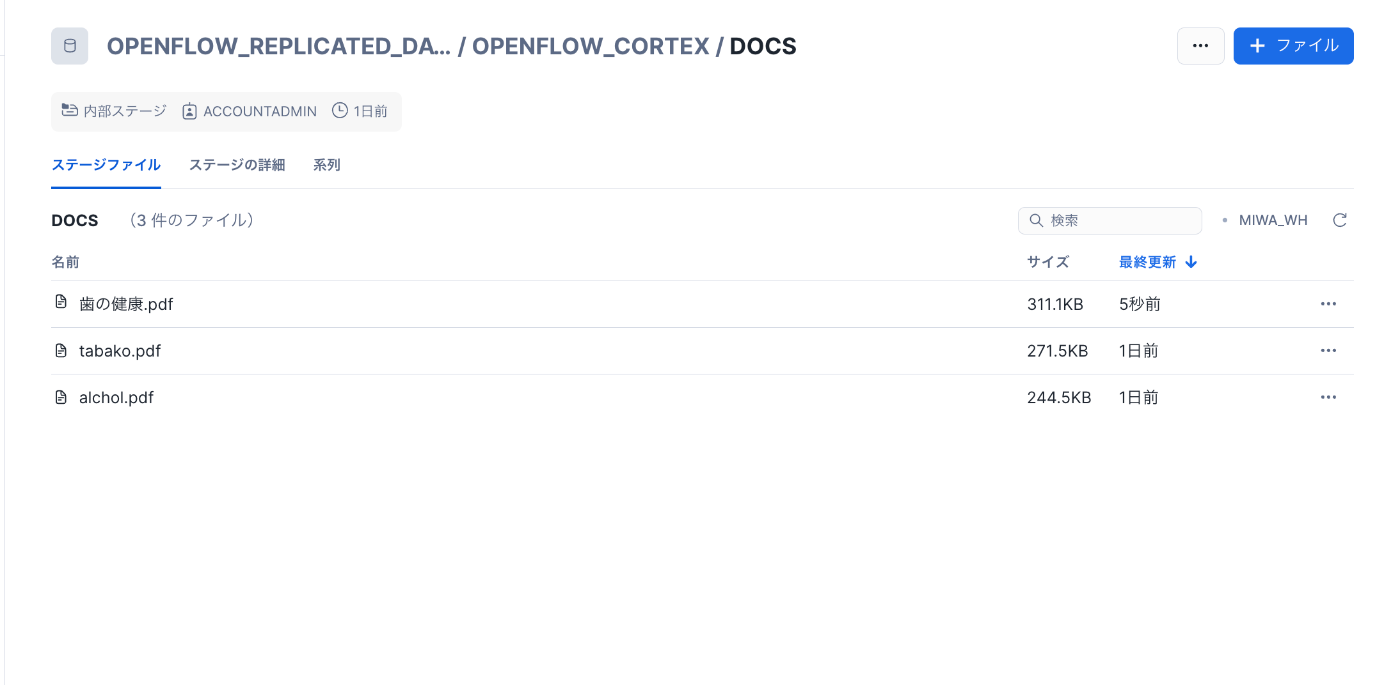
続いて、新たに「歯の健康.pdf」(こちらも厚生労働省のPDF)をステージにアップロードし、Openflowのフローを実行してみます。
-
ステージにファイルをアップロード
-
プロセッサグループからフローを起動

-
🎉 すべてのプロセッサが正常に動作し、PDFのチャンク化〜ベクトル化〜テーブル登録までが自動で完了しました。

-
チャンクテーブルに新PDFが追加されたことを確認

これで、新規にアップロードしたPDFに対して、チャンク化 → ベクトル化 → テーブル格納までの一連の処理が正しく動作することを確認できました。
OpenflowとSnowflake Cortexを組み合わせることで、シームレスにRAG用データ基盤を構築できるのは非常に強力です。
6. まとめ:Openflow × Cortexの価値とは?
本記事では、PDFファイルをSnowflakeのステージにアップロードし、それをOpenflowで処理することで、チャンク化〜ベクトル化〜テーブル登録までを一貫して実現する流れを構築しました。
現時点では、Openflowのフローは定期的なポーリングや手動実行でトリガーしている形ですが、今後は
ステージ上の新規ファイルを自動検知してフローを起動する仕組み(イベントドリブン実行)
にも挑戦してみたいと考えています。
このような構成が整えば、
ユーザーがPDFをアップするだけで、RAGに必要なベクトルデータが自動生成される
という運用に一歩近づけます。
また、Openflowプロセッサとして提供されている PerformSnowflakeCortexOCR や CreateCohereEmbeddings といった専用プロセッサの活用にも取り組んでみる予定です。
今回のポイントを整理すると:
- ✅ Openflowでチャンク化とベクトル埋め込みを自動化
- ✅ Cortexの
EMBED_TEXT_768でRAG向けベクトルテーブルを生成 - ✅ 手動 or 定期実行でも、RAG基盤の構築はここまでできる
Openflow × Cortex の組み合わせは、構造化データだけでなく、
非構造データにも対応した「生成AIの前処理基盤」 として非常に有効です。
構造・非構造の垣根を越えて、Snowflake上でAI活用の土台を整える──
そんな時代が、いよいよ現実のものとなってきました。
本記事が、みなさんの RAG 活用や生成AI基盤づくりのヒントになれば幸いです。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。