はじめに
こんにちは、NTTデータの山口です。
Amazon Web ServicesからAmazon Kiroが公開されてから、1ヶ月が経ちました。
仕様駆動開発を支援するKiroを活用すれば、忙しい開発者の手を離れてアプリ開発を任せられるのでしょうか? プレビュー版のKiroを使用してアプリ開発を任せた結果として、現時点(2025年8月時点)のAI開発のリアルをご紹介します!!
AI活用における制約
今回のアプリ開発にあたって、以下のような制約を課してみました。
- Amazon Kiro以外のAIは併用しない。
- 折角プレビュー版を使い倒せるのであれば、フル活用してみたい。
- Amazon Kiroの利用上限を超過したら、その日の開発はストップ。
- プライベートや仕事の隙間時間を意識。
- コンテキスト量や利用上限を意識することで、コスパ・タイパの高いAI活用を考えたい。
- 開発、テストに極力自分の手を動かさない。
- 同上。プライベートや仕事の隙間時間を意識。
- 「やむをえず開発者自ら手を動かす」箇所は、AI活用における開発者の意識どころになるはず。
作成したアプリ
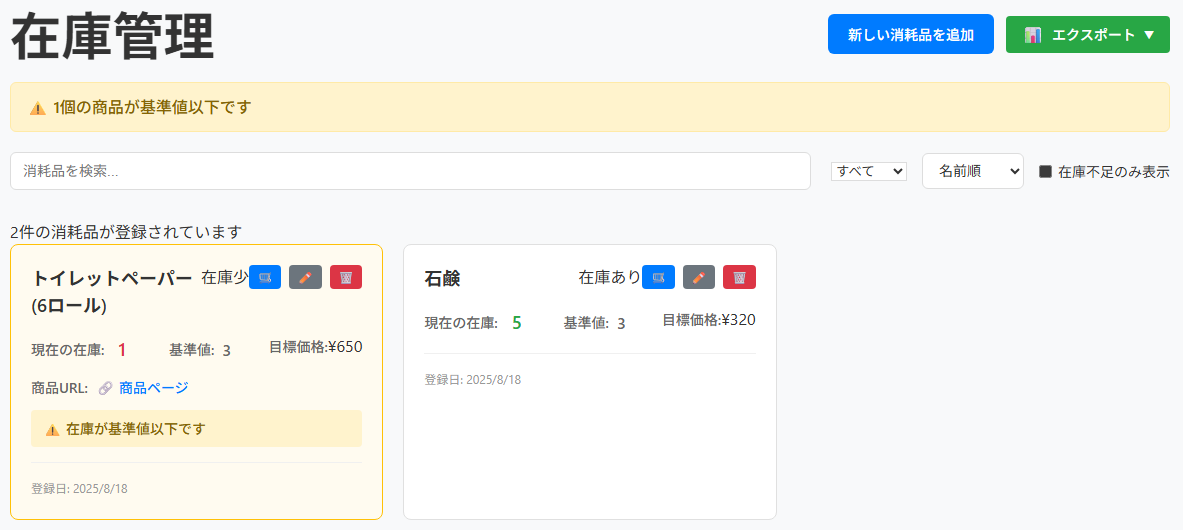
簡単な買い物リストアプリを作成してみました。簡単なアーキテクチャ図は以下の通り。

- ウチにまだ在庫あったかな...
- いくらだったら買ってもいいんだっけ...
- いつも使ってる洗剤ってどれだっけ...
といった悩みを解消するアプリです。一般サービスのようなイケてる見た目まで作りこんではいませんが、十分使えそうですね。このレベルであればプレビュー版1ヶ月の内に形になってしまいました。
本記事の着目観点
コンテキスト削減
プレビュー期間中のAmazon Kiroは無料で使用できる一方、日次の使用量制限がありました。具体的な使用量制限については明記されていませんが、Vibe request, Spec requestの実行中に、以下メッセージが出ることから、コンテキストの総量も関係していると考えます。

You've reached your daily usage limit. Please return tomorrow to continue building.
2025年8月4日、Kiroの料金プランの導入が告知されました。
Pro(月額 20 ドル)、Pro+(月額 40 ドル)、Power(月額 200 ドル)プランにおいても、Vibe request, Spec requestの回数制限は設けられるはずです。プロンプトのコンテキスト量の基準を超えると、Session Too Longと表示されて、それ以上同プロンプトで作業が出来なくなるため、コンテキストを節約すれば、1 request(= 1プロンプト)上で対応できる処理量が増えることになります。したがって、開発担当者一人ひとりが契約プランに応じた濃度の高いリクエストやコンテキスト量の節約を意識するのはAmazon Kiroでも変わりはなさそうです。後ろの章でコンテキスト量を削減する方法を何点かご紹介します。
"お作法"と乖離するポイント
人間の開発者がアプリ設計を進めていく上では当然気を遣うような箇所が、AIエージェントでは抜け落ちてしまう事項を特筆したいと考えています。理想はAutoPilotで実装・検証を進めてもらい、ある程度形がまとまってきた時点で人のレビューを入れる、といった良いループが回ることです。AIがやりがちなミス、行き届かない配慮ポイントがあれば、人が気を付けて見直しを行うか、事前にルール・ベストプラクティスとしてAIに指示しておく必要があります。
具体的なKiro開発Tips
前章で整理した観点を踏まえて、具体的な注意事項を以下にまとめました。
設計時
原則:アプリ仕様・プロジェクトルールを初めに固める
ここでは以下ファイルの定義を指します。
- アプリ仕様
requirement.mddesign.mdtasks.md
- プロジェクトルール
-
.kiro/steeringディレクトリ配下のmdファイル
-
人のアプリ開発でも同じですが、後から仕様修正・ルール修正を行うと手戻りが発生します。プロジェクト当初から参画していたメンバであれば、比較的手戻り対応も早く済むかもしれませんが、新しいプロンプトで手戻り対応を依頼した場合、コンテキストが含まれない状態でプロジェクトのソースコード読み込み・状況把握から作業が始まってしまいます。
いわば新規参画者が一からソースコードを読み始め、理解し、手戻り対応を行うようなものです。AIでも対応に漏れが発生することはありますし、全ソースコードを読み込もうとする分、コンテキスト量が増えます。初めからルールが決まっており、ルールに準じて0からソースを作成したほうが漏れも発生せず、統一感のあるソースが生成できます。
もちろん、Kiroは仕様を反復して強化・改良し、アプリを改善するアプローチを良しとしているため、すべての仕様修正・ルール修正を否定するものではありません。事前に詰められる仕様は詰めて明記した方が結果として初動スタートを早められる、というお話でした。
プロンプトの出力、ソースコードのコメントの言語を指定する
コンテキスト量を抑えるためには、プロンプト入力に英語を使用する旨が指摘されています。一方で、プロンプト出力内容が英語になったことで、AIが何を把握し、どのような対応を行おうとしているか判断できなかったり、読み飛ばしてしまうと本末転倒です。プロンプト出力側は理解しやすい言語に設定しましょう。また、AIはソースコード生成時に適度にコメントを記載してくれたり、テストケース(ここではVitest等のテストコードを想定)の名称を考えて記載してくれますが、こちらも必要に応じて日本語で設定してもらうのもアリです。
---
inclusion: always
---
# 日本語回答設定
## 言語設定
- すべての回答は日本語で行ってください
- 技術的な用語は適切な日本語訳を使用し、必要に応じて英語を併記してください
- コードコメントやドキュメントも日本語で記述してください
ドキュメントの残し方を指示する
Spec requestで新しい要件を伝える度に、Kiroはrequirement.md、design.md、tasks.mdファイルを作成してくれます。これらは新規要件に絞った仕様書であり、新規mdファイルを作成するのか、既存mdファイルに新規仕様を追記するのかも、Kiro判断になります。
.kiro/specs/ディレクトリ配下をそのまま全体の基本仕様書とするのは難しく、この中には例えば全体アーキテクチャ、構成図等、全体を鳥瞰した資料を整理しにくいと感じました。.kiro/specs/ディレクトリは要件と実装状況の管理に保持するとして、別途doc/ディレクトリ配下に仕様書の作成を指示し、各要件実装時にドキュメントのメンテナンスをお願いするとよいでしょう。「作成したアプリ」でお見せした図も、requirement.md、design.md、tasks.mdとは別に作成を指示したアーキテクチャ図です。
実装時
非推奨モジュール・パッケージを利用していないか確認する
日々進歩するライブラリに追随できず、AIが非推奨なモジュール・パッケージを利用してしまうケースがあります。セットアップ時に非推奨(deprecated)のメッセージが出力されても、原則AIエージェントは該当モジュールの使用を取りやめたり、差し替えるような対応はされませんでした。開発者自身で非推奨モジュール・パッケージが利用されていないか確認するようにしましょう。
npm warn deprecated @esbuild-kit/esm-loader@2.6.5: Merged into tsx: https://tsx.is
npm warn deprecated @miniflare/storage-memory@2.12.0: Miniflare v2 is no longer supported. Please upgrade to Miniflare v4
npm warn deprecated @miniflare/storage-file@2.12.0: Miniflare v2 is no longer supported. Please upgrade to Miniflare v4
npm warn deprecated @miniflare/runner-vm@2.12.0: Miniflare v2 is no longer supported. Please upgrade to Miniflare v4
コミット粒度は小さく頻繁に
AIエージェントがソースコードを修正した場合は、人作業以上にコミットを残し、いつでもロールバックできるようにしましょう。
-
tasks.mdの1タスクが完了したらコミット - バイブコーディングでソースコード改修後、意味のある塊が出来たらコミット
- 失敗テストケース解消後にコミット
AIエージェントはセッション毎にソースコードや共通ルールを読みなおすため、これまでのセッションで設計・実装したソースコードがどれだけ重要なものか重みづけ判断できない事が多いです。人は共通部品やインターフェース周りのソースを触る時に怖がりますが、AIエージェントは躊躇なく既存コードを改修(破壊)してしまう場合があります。
実際に発生したケース
- 新規機能のE2Eテストケースが失敗したので、AIエージェントに原因調査・改修までを依頼。
- AIエージェントは、あくまで新規テストケースの失敗を疎通させるために、すべてのE2Eテストケースが触る認証ヘルパー、DBヘルパーを改修。既存機能のE2Eテストケースが全て疎通不可に...
- ローカル環境 E2E検証時、モックDBのグローバルセットアップを改修。既存E2Eテストケースが疎通不可に...
検証時
テストフレームワークのHTMLレポーターは使用しない
例えば、プロンプト上でAIエージェントがnpx playwright testを実行するケースが該当します。標準では、playwrightはテスト実施後もHTMLレポーターを提供し続け、上記コマンドへのレスポンスを返さないため、プロンプト上のAIエージェントは待ち状態となってしまいます。
--reporter=listや、--reporter=dotオプションを用いて、ターミナル上にテスト結果が返却するようにルール設定しましょう。
テスト結果は必要な部分だけを読み取らせる
失敗テストの調査・疎通成功までの対応をAIにお願いすると、以下のように複数回のテスト実行が行われます。
- プロンプトの始めにテストを実施し、失敗テストの把握
- (必要に応じてデバッグログを埋め込み、追加調査を目的にテストを再実施)※
- テストケース修正、または機能修正後にテストを実施し、失敗テストの疎通を確認
- 最後に全テストを実施し、ソースコード改修による無影響を確認
※以下は、デバッグ目的でテスト再実行が行われているイメージ
これ自体は問題ないのですが、ユニットテスト全量やE2Eテスト全量を実行した場合、ターミナル上にテスト実施中の標準出力が大量に含まれた形でレスポンスが返るため、AIエージェントが全量を受け取ることでコンテキスト量の肥大化に繋がります。テストの成功/失敗ステータス、失敗ケースのエラー箇所だけをコンパクトに伝えるため、以下のような対策を検討できます。
- テストコマンドに
--silentオプションを付与し、標準出力を非表示にする。 - テスト結果を一時ファイルに出力し、tailやgrepコマンドで必要箇所のみを読み取らせる。
- >(リダイレクト演算子)を使用すると、危険なコマンドと判断されて毎回コマンドの許可を求められる。
- Kiroが定義する危険パターンを回避する工夫は必要になる。
失敗テストケースは開発者が管理する
Kiroは実装タスクをtasks.mdに整理してくれますが、ユニットテスト、結合テスト、E2Eテストケースも作成、検証してくれます。失敗したケースは原因調査・ケース修正まで行ってくれますが、失敗ケース量が多いと、全量解消せずにタスク完了としてしまう事があるようです。1セッションのコンテキスト量が上限に近づくと、タスク完了を急ぐ姿勢になるのかも。
- 統合テスト・E2Eテストが失敗のままタスクステータスを完了としているケース

- 一時的にテストケースをスキップしたまま、放置するケース

- エラー調査中に修正完了のまとめに移るケース
タスクが完了しても、AIエージェントが何を未完了のままタスクを終えたのか把握し、特に放置された失敗ケースの解消は別プロンプトで調査を依頼すると良いでしょう。
終わりに
1ヶ月Kiroに触れてみた感想です。アプリに期待する振る舞いや、タスクを整理するステップがあることで、開発者とAIの認識差異が格段に減った印象です。実現したい要件一言を、実際の開発スケジュールや要件書・仕様書に落とし込まなければならない、そんな心理的負担感が軽減されるのは大きいです。
一方で、一般的なサービスレベルの機能要件・非機能要件・セキュリティレベルをAIに伝える役割はまだ十二分に人間側にありそうです。加えて、AIエージェントにやってほしくない事を文章化して、共通ルールを整備していく事も、アウトプットの品質を大きく左右する秘訣だと感じました。
今後も新たな開発プロセスやワークフローが生まれ、バイブコーディングがより開発に組み込まれていくことを楽しみにしています!!

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。