はじめに
Databricksビジネス推進室の下山です。
リアルタイムデータ処理やイベントストリーミングがますます注目される昨今、「Apache Kafka × Databricks」という構成を試してみたい方も多いのではないでしょうか?
本記事では、Apache KafkaのAmazon Web Services(AWS)マネージドサービスである Amazon MSK を構築し、EC2上のKafkaクライアントからメッセージを送信し、Databricksクラスタにてメッセージを受信する一連の流れをご紹介します。
Kafkaの基本用語(サクッとおさらい)
- ブローカー:メッセージを中継・保管するサーバー(MSKクラスタが該当)
- トピック:メッセージをやり取りする論理的なチャンネル
- プロデューサー:トピックにメッセージを送る側(今回はEC2インスタンス)
- コンシューマー:トピックからメッセージを読む側(今回はDatabricksクラスタ)
Kafkaって何?という方はこちらもどうぞ 👉 Apache Kafka - Wikipedia
事前準備
まずは以下の環境を準備しておきます。
- Databricksワークスペース
- MSKクラスタを配置するためのVPCおよびプライベートサブネット×2(それぞれ異なるAZ)
- クライアント用のEC2インスタンスを配置するためのパブリックサブネット(今回はMSKクラスタと同VPC内とする)
- MSKクラスタ用のVPCとDatabricksワークスペースに紐づいているVPC間のPeering接続および、MSKクラスタ用のサブネットとワークスペースに紐づいているサブネットのルートテーブルで相互の通信を設定
構築/設定(AWS)
MSKクラスタ作成~トピック作成は以下ドキュメントに沿って進めていきます。
MSKクラスタ作成
今回はプロビジョンドタイプを選択します。
検証用ですので最小構成とします。
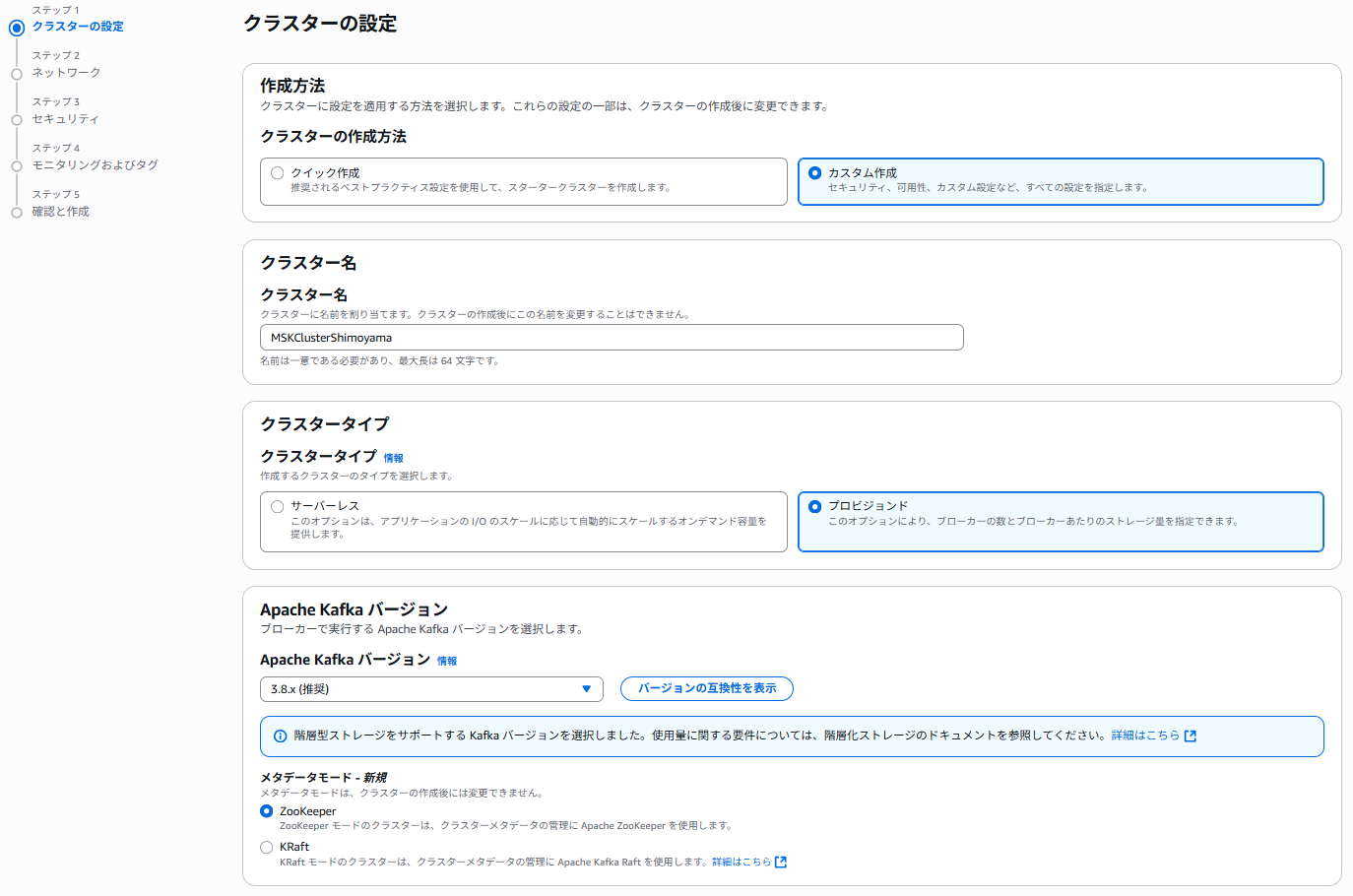

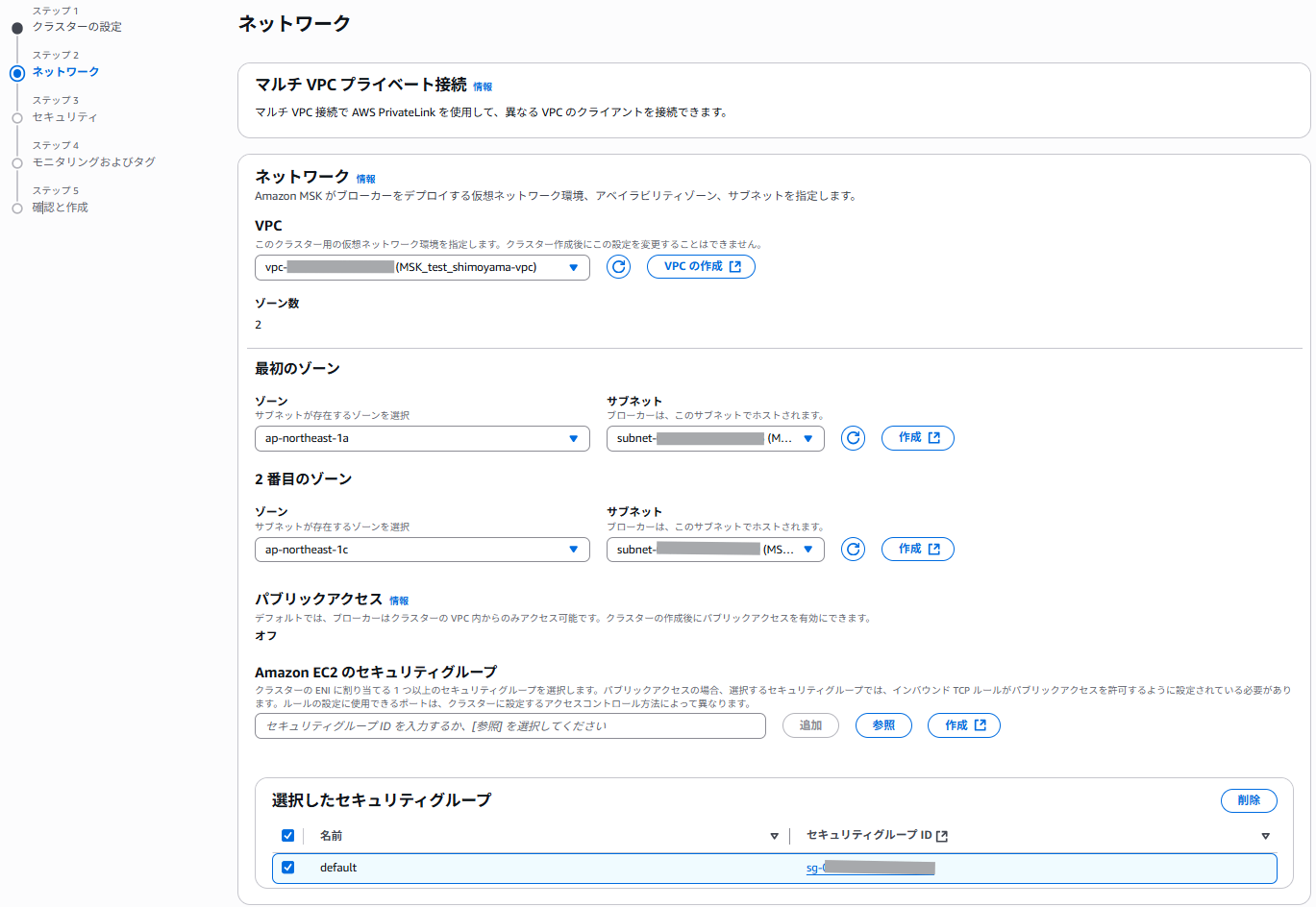
MSKクラスタを配置するVPCおよびサブネットを指定します。
セキュリティグループは、インバウンドルールにてクライアント用のEC2インスタンスおよびDatabricksクラスタからの通信ルールが必要です。
なお、今回はMSKクラスタと各クライアントがプライベート接続できる構成としていますが、設定次第ではパブリック接続やプライベートリンク接続も可能です。
認証はIAM認証とします。
※後ほどDatabricksクラスタにインスタンスプロファイルをアタッチする設定を行います。


数分待つと、MSKクラスタが「アクティブ」状態になることが確認できます。

IAMロール作成
MSKクラスタに接続する権限を持ったIAMロールを作成します。
このIAMロールは以下のリソースにアタッチする想定です。
・クライアント用のEC2インスタンス
・Databricksクラスタ
※ここでは同一ロールを使っていますが、本番環境ではリソースごとにIAMロールを分けることが推奨です。
IAMポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:Connect",
"kafka-cluster:AlterCluster",
"kafka-cluster:DescribeCluster"
],
"Resource": [
"arn:aws:kafka:{region}:{Account-ID}:cluster/{MSKクラスタ名}/{MSKクラスタID}"
]
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:*Topic*",
"kafka-cluster:WriteData",
"kafka-cluster:ReadData"
],
"Resource": [
"arn:aws:kafka:{region}:{Account-ID}:topic/{MSKクラスタ名}/*"
]
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:AlterGroup",
"kafka-cluster:DescribeGroup"
],
"Resource": [
"arn:aws:kafka:{region}:{Account-ID}:group/{MSKクラスタ名}/*"
]
}
]
}
IAMロール作成
信頼されたエンティティタイプ はEC2を指定します。

先ほど作成したポリシーをアタッチします。

EC2 / Kafkaクライアント構築
EC2インスタンス(Amazon Linux 2)をLaunchします。
インスタンスプロファイルは先ほど作成したIAMロールとします。
セキュリティグループには、以下のインバウンド/アウトバウンドルールを設定します。
- インバウンド:SSH
- アウトバウンド:MSKクラスタへの通信
SSH接続し、Kafkaクライアントツールを設定します。
sudo yum -y install java-11
export KAFKA_VERSION=3.8.0
wget https://archive.apache.org/dist/kafka/$KAFKA_VERSION/kafka_2.13-$KAFKA_VERSION.tgz
tar -xzf kafka_2.13-$KAFKA_VERSION.tgz
export KAFKA_ROOT=$(pwd)/kafka_2.13-$KAFKA_VERSION
wget -P $KAFKA_ROOT/libs https://github.com/aws/aws-msk-iam-auth/releases/latest/download/aws-msk-iam-auth-2.3.2-all.jar
echo "security.protocol=SASL_SSL" >> $KAFKA_ROOT/config/client.properties
echo "sasl.mechanism=AWS_MSK_IAM" >> $KAFKA_ROOT/config/client.properties
echo "sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;" >> $KAFKA_ROOT/config/client.properties
echo "sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler" >> $KAFKA_ROOT/config/client.properties
export BOOTSTRAP_SERVER={ブートストラップサーバーのエンドポイント}
ブートストラップサーバーのエンドポイントはMSKコンソール上の クライアント情報の表示 から確認できます。

トピック作成
トピックはクライアントから直接作成・管理できます。先ほどクライアントを設定したので、このままトピックを作成します。
ここではトピック名は Topic01 としています。
[ec2-user@ip-172-10-12-239 ~]$ $KAFKA_ROOT/bin/kafka-topics.sh --create --bootstrap-server $BOOTSTRAP_SERVER --command-config $KAFKA_ROOT/config/client.properties --replication-factor 2 --partitions 1 --topic Topic01
Created topic Topic01.
一覧表示にて作成されていることを確認します。
[ec2-user@ip-172-10-12-239 ~]$ $KAFKA_ROOT/bin/kafka-topics.sh --list --bootstrap-server $BOOTSTRAP_SERVER --command-config $KAFKA_ROOT/config/client.properties
Topic01
__amazon_msk_canary
__consumer_offsets
PassRole権限の付与
Databricksにてワークスペースを作成する際、Databricksクラスタの実態となるEC2インスタンスデプロイ用のIAMロールを指定しているはずです。
Databricksクラスタにインスタンスプロファイルを付与するために、そのIAMロールに以下のPassRole権限を付与します。
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::{Account-ID}:role/{前の手順で作成したIAMロール名}"
}
設定(Databricks)
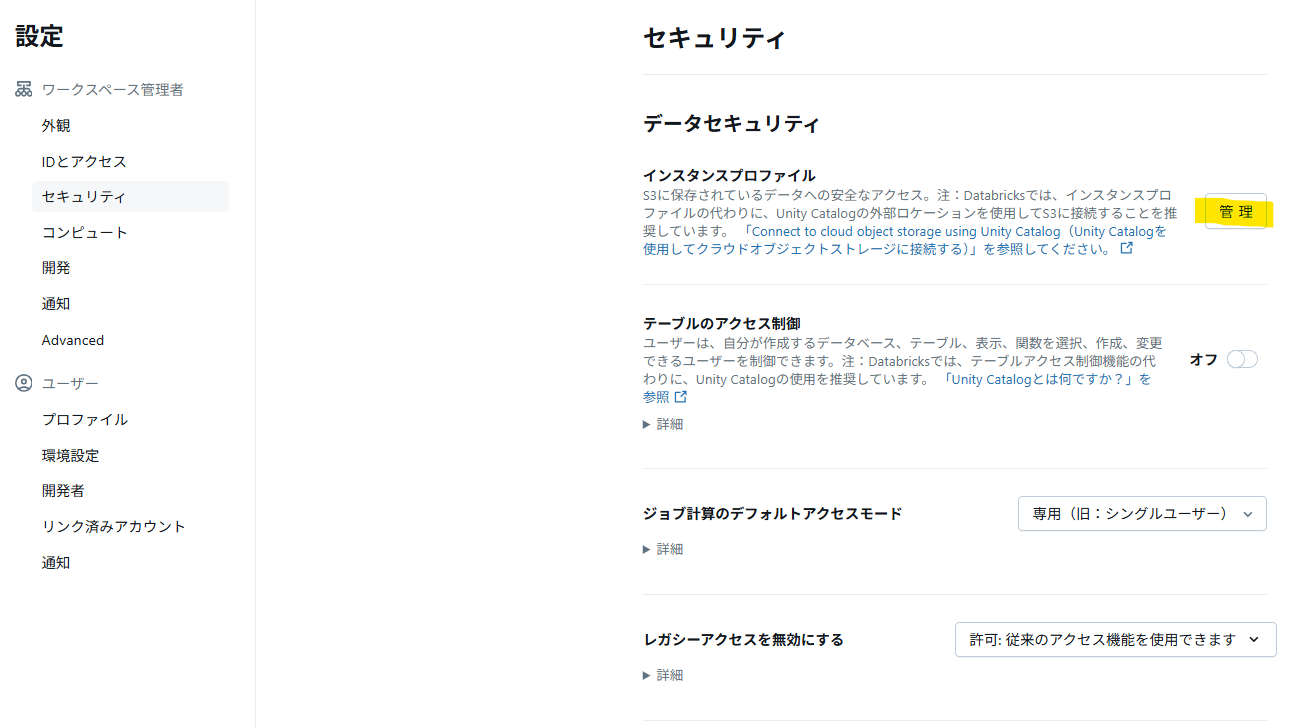
インスタンスプロファイルの登録
ワークスペースの管理者設定からインスタンスプロファイルを登録します。
DatabricksクラスタからMSKクラスタにアクセスするために必要な権限設定です。

Databricksクラスタ作成
汎用コンピューティングを作成します。
登録したインスタンスプロファイルをここで指定します。

メッセージの連携確認
メッセージ生成
環境の構築・設定ができましたので、メッセージ連携を確認していきます。
まずはクライアント用のEC2インスタンス上でメッセージを生成します。
kafka-console-producer.shを実行するとプロンプトが表示されるため、入力してメッセージを生成します。
[ec2-user@ip-172-10-12-239 ~]$ $KAFKA_ROOT/bin/kafka-console-producer.sh --broker-list $BOOTSTRAP_SERVER --producer.config $KAFKA_ROOT/config/client.properties --topic Topic01 --property "parse.key=true" --property "key.separator=="
>key01={"table":"table01","op_type":"insert","sequence":"00000100","cdc":{"userid":050,"username":"takahashi"}}
>key02={"table":"table01","op_type":"update","sequence":"00000101","cdc":{"userid":010,"username":"satou"}}
>key03={"table":"table01","op_type":"delete","sequence":"00000102","cdc":{"userid":025,"username":"tanaka"}}
>
メッセージ読み取り
メッセージをDatabricksから読み取ります。
前の手順で作成したDatabricksクラスタを利用し、ノートブック上からストリーム読み取りのコマンドを実行します。
df = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", {ブートストラップサーバーのエンドポイント})
.option("kafka.sasl.mechanism", "AWS_MSK_IAM")
.option("kafka.sasl.jaas.config", "shadedmskiam.software.amazon.msk.auth.iam.IAMLoginModule required;")
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.client.callback.handler.class", "shadedmskiam.software.amazon.msk.auth.iam.IAMClientCallbackHandler")
.option("subscribe", "Topic01")
.option("startingOffsets", "earliest")
.load()
.withColumn("key", col("key").cast("string"))
.withColumn("value", col("value").cast("string"))
)
display() でストリームを表示し、Databricks上でKafkaのメッセージを受信できていることが確認できました!
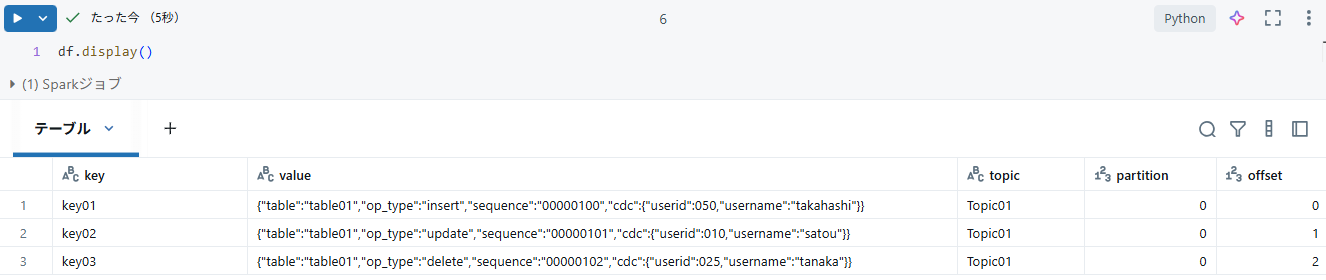
テーブル書き込みは以下の通りです。
チェックポイントファイルを指定することで、自動でoffsetを管理して未処理のメッセージのみ処理対象とできます。
チェックポイントファイルはあらかじめボリュームにディレクトリを作成しておく必要があります。
(df
.writeStream
.option("checkpointLocation", {ボリュームパス})
.trigger(processingTime="2 seconds") #指定のスパンでトピックの新規メッセージを読み取る
#.trigger(availableNow=True) #availableNow指定の場合は単発処理となり実行後処理が止まる
.toTable({書き込み先のテーブル名})
)
まとめ
本記事では、Amazon MSKクラスタの構築からトピックへのメッセージ送信、そしてDatabricks によるメッセージの受信までを一連の流れとして紹介しました。
フルマネージドなKafka環境と柔軟な分析基盤であるDatabricksを組み合わせることで、スケーラブルなストリーミングデータ処理基盤を手軽に構築できることがご理解いただけたのではないでしょうか。
なお、今年2025年のDAISでは「Zerobus」という新機能も発表されました。これは、Databricks上のテーブルに直接書き込むためのAPIを提供するもので、Kafkaなどの中間層を省略した、よりシンプルなアーキテクチャの実現が期待されています。 58分あたりです。
仲間募集
NTTデータ ソリューション事業本部 では、以下の職種を募集しています。
Databricks、生成AIを活用したデータ基盤構築/活用支援(Databricks Championとの協働)
Snowflake、生成AIを活用したデータ基盤構築/活用支援(Snowflake Data Superheroesとの協働)
プロジェクトマネージャー(データ分析プラットフォームソリューションの企画~開発~導入/生成AI活用)
クラウドを活用したデータ分析プラットフォームの開発(ITアーキテクト/PM/クラウドエンジニア)
データドリブンDXを推進するデータサイエンティスト
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start)と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~ TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。
NTTデータとSnowflakeについて
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。
NTTデータとInformaticaについて
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
NTTデータとTableauについて
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータとDataRobotについて
DataRobotは、包括的なAIライフサイクルプラットフォームです。
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
:::

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。