この記事は「ビギナーズ Advent Calendar 2025」の2日目の記事です。
1. はじめに
データが企業の意思決定、製品開発、顧客体験の向上において中心的な役割を果たす現代において、そのデータの品質を維持・向上させることは極めて重要です。以前、自分が執筆したDATA INSIGHTの記事で、来たるべきAIエージェント時代に向けたビジネス視点でのデータマネジメントの重要性についてを説明しました。本稿では、データマネジメントの実装に焦点を当てて解説します。
特に、ビッグデータを扱う上で重要な分散処理技術であるSparkと、データ品質の維持・向上に役立つDelta Lakeを利用しつつ解説していきます。
対象読者
対象読者として以下のデータエンジニアリングに関わる方を想定しています。
- データエンジニア
- データサイエンティスト
- データアナリスト
- データ基盤管理者
- データ品質管理担当者
参考:SparkとDelta Lakeの概要
Spark
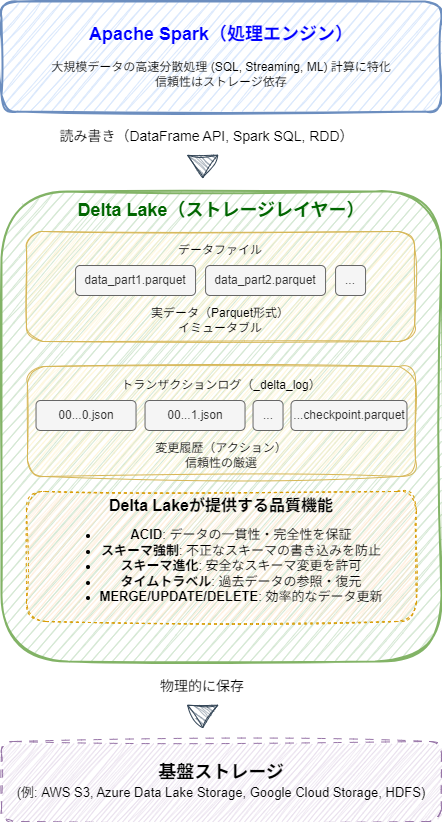
Spark(Apache Spark)は、大規模データセットを高速に処理するための強力なオープンソース分散コンピューティングフレームワークです。インメモリ処理により高速性を実現し、SQL、ストリーミング、機械学習など、構造化データ・非構造化データを問わず多様なワークロードに対応します。
Spark自体は主に計算エンジンであり、データの永続化や信頼性に関しては、基盤となるストレージシステムに依存します。
本稿ではSparkをPythonから実行できるPySparkを利用します。
Delta Lake
Delta Lakeは、データファイル(Parquet形式)とトランザクションログ(_delta_logディレクトリ)の2種類の要素で構成されるストレージレイヤーです。
_delta_logディレクトリ内には、主に以下のファイルが格納されます。
-
コミットJSONファイル (00000...0.json, 00000...1.json, ...):
- 各JSONファイルには、そのトランザクションで行われた操作に関する情報(アクション)が含まれています。
-
チェックポイントファイル (...checkpoint.parquet):
- トランザクションログのJSONファイルが増え続けると、テーブル状態を把握するためのログの読み取りに時間がかかるようになります。
これを防ぐため、Delta Lakeは定期的(通常10コミットごと)に、特定のバージョンまでのテーブル状態のスナップショットをParquet形式のチェックポイントファイルとして書き出します。
- トランザクションログのJSONファイルが増え続けると、テーブル状態を把握するためのログの読み取りに時間がかかるようになります。
Delta Lakeは上記の実装により、ACID、スキーマ強制、スキーマ進化をサポートし、Spark単体では実現が難しいデータ品質管理を補完します。
SparkとDelta Lake
2. データマネジメントにおけるデータ品質
DMBOKの13章冒頭では、データ品質は下記のように定義されています。
品質管理技術をデータに適用するアクティビティを計画し、実施し、制御する。これによって、データが様々な目的で利用されて、データ利用者の要求に合致することを保証する。
やや形式的な表現ですが、要するに分析などのデータ活用の目的に沿った形でデータを準備しようという意味になります。
要求に合致するという表現からも分かるように、データ活用の形態によって優先されるデータ品質の観点も異なるため、これはプロジェクトオーナーと相談しつつ、何を優先するか決める必要があります。
本稿ではDAMA UK(データマネジメント協会UK支部)が示した6次元の評価軸をベースにデータ品質について説明していきます。
データ品質の評価軸
DAMA UKでは、データ品質の核となる6つの評価軸を以下のように定義しています。定義がやや専門的なため、各定義について筆者の解釈も補足します。
| 評価軸 | DAMA UKの定義 | 補足 |
|---|---|---|
| 完全性 | 完全な状態である100%に対する保存されたデータの割合 | 必要なデータが欠落していないか。必須項目に値が存在するか |
| 一意性 | エンティティインスタンス(物事)の識別方法が同じであれば一度しか記録されない。 | データセット内で重複するレコードが存在しないか。主キーや一意制約が守られているか |
| 適時性 | 要求された時点とデータが現実を反映した時点との差 | データの鮮度や発生からの経過時間が期待通りか |
| 有効性 | データはその定義が要求する構文(フオーマット、タイプ、範囲)に準拠する場合に有効である | データが定義された形式、型、範囲、またはドメイン(許容値リスト)に準拠しているか |
| 正確性 | 表現すべき「現実世界」の対象や事象をデータが正しく表す度合い | データが現実世界の事象や参照元(マスターデータなど)と一致しているか |
| 一貫性 | ある物事に対して異なった表現が使われても定義上同等である | 同じ事象を表すデータがシステム内または複数のシステム間で矛盾なく表現されているか |
3. PySparkを用いたデータ品質チェックの実装
データ品質について実装するにあたり、実際のデータを利用した方が実案件にも応用しやすいと考え、以下に示すニューヨーク市のタクシーデータを利用します。
データ準備
ニューヨーク市タクシー&リムジン委員会(NYC TLC)が公開するTLC Trip Record Dataのイエローキャブ(2025年1月分のデータ)を使用します。
このデータセットには、主に以下の情報が含まれています。
- 乗車・降車の日時と場所(ロケーションID)
- 移動距離
- 項目別運賃、料金種別、支払種別
- ドライバー報告による乗客数
テーブル定義
各カラムの定義は以下の通りです。
原本は英語で表記されており、正確な表現を確認したい場合は公式サイトを確認してください。
| フィールド名 (FieldName) | 説明 (Description) |
|---|---|
| VendorID | レコードを提供したTPEP提供者(タクシー運行会社)を示すコード。 例, 1= Creative Mobile Technologies, LLC; 2= Curb Mobility, LLC; 6= Myle Technologies Inc; 7= Helix |
| tpep_pickup_datetime | メーターが作動(乗車)した日時。 |
| tpep_dropoff_datetime | メーターが停止(降車)した日時。 |
| passenger_count | 車両に乗車していた乗客の数。 |
| trip_distance | タクシーメーターによって報告された経過移動距離(マイル単位)。 |
| RatecodeID | 移動終了時に有効だった最終料金コード。 例, 1= 標準料金; 2= JFK; 3= Newark; 4= NassauまたはWestchester; 5= 交渉料金; 6= グループ乗車; 99= Null/不明 |
| store_and_fwd_flag | 車両がサーバーに接続できなかったため、ベンダーに送信する前に車両メモリに移動記録が保持されたか(ストア&フォワード)を示すフラグ。 $Y= ストア&フォワード記録; $N= ストア&フォワード記録ではない |
| PULocationID | タクシーメーターが作動(乗車)したTLC Taxi Zone |
| DOLocationID | タクシーメーターが停止(降車)したTLC Taxi Zone |
| payment_type | 乗客がどのように支払ったかを示す数値コード。 $0= Flex Fare trip(固定料金); $1= クレジットカード; $2= 現金; $3= 無料; $4= 異議申し立て; $5= 不明; $6= 無効な移動 |
| fare_amount | メーターで計算された時間距離運賃。詳細: https://www.nyc.gov/site/tlc/passengers/taxi-fare.page |
| extra | その他の追加料金やサーチャージ。 |
| mta_tax | 使用中のメーター料金に基づいて自動的に発生する税金。 |
| tip_amount | チップの金額。クレジットカードのチップに対して自動的に入力される。現金チップは含まれない。 |
| tolls_amount | 移動中に支払われた全ての通行料金の合計(有料道路など)額。 |
| improvement_surcharge | メーター作動時に課される改善サーチャージ。2015年に導入開始。 |
| total_amount | 乗客に請求された総額。現金チップは含まない。 |
| congestion_surcharge | ニューヨーク州の混雑サーチャージとして移動中に徴収された合計額。 |
| airport_fee | ラガーディア空港およびジョン・F・ケネディ空港での乗車時にのみ適用。 |
| cbd_congestion_fee | 2025年1月5日から開始されたMTAの混雑緩和ゾーンに対する移動ごとの料金。 |
初期設定
# 必要ライブラリー読み込み
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, when, to_timestamp, current_timestamp, datediff, rlike, first
from delta.tables import DeltaTable
# セッション&データ読み込み
spark = SparkSession.builder.appName("DataQualityCheck").getOrCreate()
df = spark.read.parquet("yellow_tripdata_2025-01.parquet")
完全性 (Completeness)
データの完全性とは、完全な状態である100%に対する保存されたデータの割合で評価されます。つまり、必要なデータが欠落していないか、必須項目に値が存在するかといった観点で、データがどれだけ満たされているかを示す指標となります。
データの完全性を確保し向上させるためには、確認された欠損値をどのように扱うかの戦略を検討する必要があります。
例えば、運賃予測やチップ額予測モデルを作成する場合、多くの機械学習アルゴリズムでは欠損値をそのままでは扱えません。そのため、欠損値を何らかの代表値(平均値、中央値、最頻値など)で補完する、欠損していることを示す特別な値で補完する、あるいは場合によっては該当のデータ行を削除するといった対応策を検討します。
今回のデータではpassenger_countに欠損値が多く含まれていることが確認できます。
passenger_count = df.select("passenger_count").filter(col("passenger_count").isNull()).count()
df_count = df.count()
print(f"NULL値の数: {passenger_count}/{df_count}")
# 出力結果: NULL値の数: 540149/3475226
チップ額予測モデルを作成するためにデータを利用するという前提で、最頻値で埋めていきます。
df = df.fillna(df.groupBy().agg(first(col("passenger_count")).alias("passenger_count")).collect()[0]["passenger_count"])
# 結果の再確認
passenger_count = df.select("passenger_count").filter(col("passenger_count").isNull()).count()
print(f"NULL値の数: {passenger_count}/{df_count}")
# 出力結果: NULL値の数: 0/3475226
予測モデルを構築する上で必須となるカラムの完全性を高めることができました。
一意性 (Uniqueness)
一意性とはエンティティインスタンス(物事)の識別方法が同じであれば一度しか記録されないことを指します。これは、データセット内で重複するレコードが存在せず、各レコードがユニークに識別できる状態を意味します。
一意性の検証にあたり、主キーや特定のカラムの組み合わせに基づいて重複レコードを検出します。
以下のコード例では、指定カラムの組み合わせにおいて、重複が存在するかどうかを確認します。
key_columns = [
"VendorID",
"tpep_pickup_datetime",
"tpep_dropoff_datetime",
]
print(f"以下のカラムの組み合わせで一意性をチェックします: {key_columns}")
# 1. キー候補カラムでグループ化し、各組み合わせの出現回数をカウント
duplicates_check_df = df.groupBy(key_columns).count()
# 2. 出現回数が1より大きいレコード(重複)をフィルタリング
duplicates_df = duplicates_check_df.where(col("count") > 1)
# 3. 重複レコードの件数を確認
num_duplicate_combinations = duplicates_df.count()
if num_duplicate_combinations == 0:
print("\n指定されたカラムの組み合わせにおいて、重複するレコードはありませんでした。")
print("データはこのキー候補で一意です。")
else:
print(f"\n指定されたカラムの組み合わせにおいて、{num_duplicate_combinations} 件の重複が見つかりました。")
print("重複している組み合わせと、その出現回数を表示します:")
duplicates_df.show(truncate=False)
# 出力結果:
# 指定されたカラムの組み合わせにおいて、62428 件の重複が見つかりました。
# 重複している組み合わせと、その出現回数を表示します:
# +--------+--------------------+---------------------+-----+
# |VendorID|tpep_pickup_datetime|tpep_dropoff_datetime|count|
# +--------+--------------------+---------------------+-----+
# |2 |2025-01-01 00:22:21 |2025-01-01 00:52:54 |2 |
# |2 |2025-01-01 00:57:01 |2025-01-01 01:23:00 |2 |
# ...
重複しているレコードの具体的な内容を確認することで、なぜ一意性が損なわれているのか、その原因を探る手がかりが得られます。
以下のコードは、上記で重複が確認された特定の組み合わせに該当する元のレコードを表示します。
(
df
.where(col("VendorID") == 2)
.where(col("tpep_pickup_datetime") == "2025-01-01 02:35:33")
.where(col("tpep_dropoff_datetime") == "2025-01-01 02:46:48")
.show(truncate=False)
)
| VendorID | tpep_pickup_datetime | tpep_dropoff_datetime | passenger_count | trip_distance | RatecodeID | store_and_fwd_flag | PULocationID | DOLocationID | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | congestion_surcharge | Airport_fee | cbd_congestion_fee |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2025-01-01 02:35:33 | 2025-01-01 02:46:48 | 1 | 3.12 | 1 | N | 261 | 4 | 4 | -15.6 | -1.0 | -0.5 | 0.0 | 0.0 | -1.0 | -20.6 | -2.5 | 0.0 | 0.0 |
| 2 | 2025-01-01 02:35:33 | 2025-01-01 02:46:48 | 1 | 3.12 | 1 | N | 261 | 4 | 4 | 15.6 | 1.0 | 0.5 | 0.0 | 0.0 | 1.0 | 20.6 | 2.5 | 0.0 | 0.0 |
payment_typeが4となっているため、キャンセルされた取引であると考えられます。
分析の目的によっては、このような「実質的にキャンセルされた取引」を示すレコードペアは除外する必要があるかもしれません。例えば、有効な移動パターンや実際の売上を分析する際には、payment_type = 4 のレコードを除外することで、よりデータの一意性を高め、分析の精度を向上させることができます。
一意性を回復するための一つのアプローチとして、以下のように特定の条件(この例では payment_type = 4)に基づいてレコードを除外する方法があります。
元データを直接変更せず、フィルタリングした結果を新しいデータフレームに格納することで、後から元データや除外したデータを確認・利用できるため、安全かつ明確な処理となります。
df_only_valid_payment = df.where(col("payment_type") != 4)
適時性 (Timeliness)
適時性は、要求された時点とデータが現実を反映した時点との差を評価するものです。つまり、データが利用されるタイミングに対して十分に新しいか(鮮度)、古すぎないか、そして期待されるべき時間的範囲内に収まっているか(例:特定の分析対象期間内のデータか)といった観点が重要になります。適時性が低いデータは、誤った意思決定や分析結果の信頼性低下に繋がる可能性があります。
今回のデータでは以下の2つの観点から検討します。
- データが期待される特定の期間内に存在するか。
- データが示す時刻情報が論理的に整合しており、現実を適切に反映しているか(これはデータの「有効性」や「一貫性」とも関連する内容です)。
まずは、データが期待される期間(例えば、ここでは2025年1月分のデータと仮定)に含まれているかを確認するために、tpep_dropoff_datetime(降車日時)の最小値と最大値を見ていきます。
df.select(min("tpep_dropoff_datetime"), max("tpep_dropoff_datetime")).show()
# 出力結果:
# +--------------------------+--------------------------+
# |min(tpep_dropoff_datetime)|max(tpep_dropoff_datetime)|
# +--------------------------+--------------------------+
# | 2024-12-18 07:52:40| 2025-02-01 23:44:11|
# +--------------------------+--------------------------+
出力結果から期待される期間(2025年1月)以外のデータ(2024年12月や2025年2月のデータなど)が含まれていることが確認できます。これは「適時性」の観点から問題となる可能性があります。
このような期間外データが混入する原因としては、以下のようなものが考えられます。
- データ抽出時のフィルタリング条件の誤り
- タクシーメーターや車載器の時計の大幅なずれ
- データ処理時のタイムゾーン解釈や変換の誤り
次に、時刻情報の論理的な整合性を確認します。
上記で発見された最も古い降車日時のレコード (2024-12-18 07:52:40) の詳細を見てみましょう。
(
df
.where(col("tpep_dropoff_datetime") == "2024-12-18 07:52:40")
.select("tpep_pickup_datetime", "tpep_dropoff_datetime") # 乗った地点・降りた地点のみ表示
.show()
)
# 出力結果:
# +--------------------+---------------------+
# |tpep_pickup_datetime|tpep_dropoff_datetime|
# +--------------------+---------------------+
# | 2025-01-23 01:44:59| 2024-12-18 07:52:40|
# +--------------------+---------------------+
このレコードでは、降車日時 (2024-12-18) が乗車日時 (2025-01-23) よりも前になっています。
これは、データの有効性の観点(論理的にありえない時刻関係)、正確性の観点(現実を正しく反映していない)、そしてデータ内部の一貫性の観点から重大な問題です。
このような時刻の矛盾は、結果としてデータの時間的な信頼性を損ない、「適時性」の評価にも影響します。
なぜなら、期待される時間的文脈から逸脱したデータは、その鮮度や有用性が疑わしくなるためです。トリップの所要時間がマイナスになるなど、このままでは多くの分析(平均移動時間、速度計算、時間帯別分析など)に悪影響を及ぼします。
ここでは、乗車日時よりも降車日時が前になっている、論理的に矛盾したレコードを除外する処理を行います。
df_corrected_time = df.where(col("tpep_dropoff_datetime") > col("tpep_pickup_datetime"))
# 処理した結果を再表示
df_corrected_time.select(min("tpep_pickup_datetime"), max("tpep_pickup_datetime")).show()
# 出力結果:
# +-------------------------+-------------------------+
# |min(tpep_pickup_datetime)|max(tpep_pickup_datetime)|
# +-------------------------+-------------------------+
# | 2024-12-31 20:47:55| 2025-02-01 00:00:44|
# +-------------------------+-------------------------+
上記の処理により、乗車時刻と降車時刻が矛盾するレコードは除外され、データの時間的な整合性がある程度改善されました。
妥当性 (Validity)
妥当性は、「データがその定義(データディクショナリやスキーマ定義など)が要求する構文(フォーマット、データ型、値の範囲など)に準拠している」度合いを指します。
つまり、データが定義された形式、型、取りうる値の範囲、あるいは許容される値のリストに従っているかを確認します。
妥当性が低いデータは、システムエラーを引き起こしたり、データの処理や分析において予期せぬ結果や誤解を招いたりする可能性があります。
以下では、タクシー乗車データの RatecodeID(料金コード)を例に、特にドメイン(許容される値のリスト)への準拠という観点からデータの妥当性を検証し、改善するアプローチを示します。
まず、現状のRatecodeIDにNULL値がどれだけ含まれているかを確認します。
print(f"RatecodeIDのNull件数: {df.filter(df.RatecodeID.isNull()).count()}")
# 出力結果: RatecodeIDのNull件数: 540149
データ辞書(データの定義書)において、RatecodeIDの99という値は「Null/unknown(不明または適用外)」を示す意図的なコードとして定義されているとします。
しかし、上記の通り、実際のデータにはデータベース上のNULL値が多数含まれています。この状態は、データの妥当性の観点から見ると、以下のような問題点があります。
- 定義への不準拠: データ辞書では「不明」を 99 で示すと定義されているにも関わらず、実際のデータではNULLという異なる表現で「不明」が存在しており、定義に準拠していません。
- 解釈の曖昧さ: 「不明」という情報がNULLと 99 の二通りで存在しうるため、データの利用者が混乱したり、集計や分析時に考慮漏れが発生したりする可能性があります。
データの妥当性を高め、データ辞書の定義に準拠させるため、これらのNULL値を定義済みのコードである 99 に置き換えます。
これにより、RatecodeIDが取りうる値はデータ辞書で定義されたドメインに収まり、「不明」という状態が一貫して 99 で表現されるようになります。
df = df.withColumn("RatecodeID", when(col("RatecodeID").isNull(), lit(99)).otherwise(col("RatecodeID")))
print(f"RatecodeIDのNull件数: {df.filter(df.RatecodeID.isNull()).count()}")
# 出力結果: RatecodeIDのNull件数: 0
この処理により、RatecodeIDにおけるNULL値の問題が解消され、データ辞書の定義に沿った、より「妥当な」データセットになりました。
正確性 (Accuracy)
正確性は、「表現すべき「現実世界」の対象や事象をデータが正しく表す度合い」を評価するものです。つまり、データが現実世界の事象や、信頼できる参照元(例:マスターデータ、公的な統計データ、検証済みの外部データソースなど)と一致しているかを確認します。
TLC Taxi Zone公式のマスターデータを利用して、実データとマスターデータの乗車ローケーションIDを比較して、トリップデータ内のPULocationIDが「既知の有効なコード」であることを確認していきます。
valid_location_ids_df = df_taxi_zone.select(col("LocationID").alias("zone_LocationID")).distinct()
# dfのPULocationIDが、上記で作成した有効なロケーションIDリスト(valid_location_ids_df)に存在しないレコードを抽出
invalid_pulocationid_df = df.join(
valid_location_ids_df,
df["PULocationID"] == valid_location_ids_df["zone_LocationID"],
"left_anti"
)
# dfから、PULocationIDがNULL(欠損)ではないレコードのみをフィルタリング
df_non_null_puloc = df.filter(col("PULocationID").isNotNull())
invalid_pulocationid_referential_df = df_non_null_puloc.join(
valid_location_ids_df,
df_non_null_puloc["PULocationID"] == valid_location_ids_df["zone_LocationID"],
"left_anti"
)
# 参照整合性違反(有効なロケーションIDリストに存在しない、かつNULLでもないPULocationID)のレコード数をカウント
num_invalid_pulocationid_referential = invalid_pulocationid_referential_df.count()
if num_invalid_pulocationid_referential == 0:
print("dfのPULocationIDは、df_taxi_zoneのLocationIDに存在")
else:
print(f"dfのPULocationIDのうち、df_taxi_zoneのLocationIDに存在しないものが {num_invalid_pulocationid_referential} 件見つかりました。")
# 出力結果: dfのPULocationIDは、df_taxi_zoneのLocationIDに存在
今回の検証により、PULocationIDが参照元であるマスターデータに存在する有効なコードである、つまり参照整合性が保たれていることが確認できました。
しかし、定義にある 「表現すべき「現実世界」の対象や事象をデータが正しく表す度合い」 という観点から見ると、これでPULocationID が完全に「正確」であると断言するには限界があります。
例えば、以下の点が挙げられます。
- 実際の事象との一致: PULocationID がマスターデータに存在する有効なIDだとしても、それが 「記録された乗車が実際にそのIDが示すゾーンで行われたか」 という事実を正しく反映しているとは限りません。例えば、ドライバーが誤ったゾーンIDを入力した可能性や、システムが誤ったIDを記録した可能性も考えられます。
- マスターデータの正確性: 参照元であるマスターデータ自体が誤りを含んでいたり、最新の状態を反映していなかったりする可能性もゼロではありません。
実際の乗車地点との一致といった、より深いレベルの正確性を検証するには、GPSログ、乗客からのフィードバック、あるいは他の独立した位置情報源といった、さらに詳細かつ信頼性の高い情報との比較照合が必要となります。
したがって、今回行ったのは、利用可能なマスターデータに基づく範囲での正確性の検証(主として参照整合性の確認)であり、データの正確性を評価する上で重要な第一歩と言えます。
完全な正確性を追求するには、複数の情報源を用いた多角的な検証や、実世界の事象を捉えるためのより直接的な証拠との照合が求められます。
一貫性 (Consistency)
一貫性は、「ある物事に対して異なった表現が使われても定義上同等である」こと、あるいは「同じ事象を表すデータが、システム内または複数のシステム間で矛盾なく表現されているか」 を評価するものです。
具体的には、以下のような観点が含まれています。
- レコード内部の論理的整合性: 個々のレコード内で、異なるカラム間の値が論理的に矛盾していないか
- データ表現の統一性: 同じ意味を持つ情報が、異なる場所や時点で異なる形式や値で表現されていないか
- 関連データ間の整合性: 複数のテーブルやデータセット間で、関連するデータが整合しているか
一貫性のないデータは、混乱を招き、信頼性の低い分析結果やシステム動作の不具合に繋がる可能性があります。
ここでは、タクシー乗車データのpayment_type(支払い方法)と tip_amount(チップ額)の間に期待される関係性、つまりレコード内部の論理的な一貫性に着目します。
テーブル定義によれば、「現金払い(payment_type=2)の場合、tip_amountは通常記録されないか、あるいは0であるべき」というルールが想定されます。
まず、現金払い(payment_type=2)のレコードにおけるtip_amount の値の種類を確認してみましょう。
(
df
.where(col("payment_type") == 2)
.select("tip_amount")
.distinct()
.show()
)
# 出力結果:
# +----------+
# |tip_amount|
# +----------+
# | 8.0|
# | 0.0|
# | 0.2|
# ...
上記のコードの出力結果例から、現金払い(payment_type=2)であるにも関わらず、tip_amountに0.0 以外の値が含まれているレコードが存在することが確認できます。
これは、前述の「現金払いの場合はチップ額は0であるべき」という仮定されたルールと矛盾しており、データの一貫性が損なわれている状態を示します。
データの一貫性を回復するため、このルールに違反しているレコードに対し、payment_typeが2の場合はtip_amountを 0.0 に修正する処理を行います。
# 現金払いの場合、tip_amountを0にする
df = df.withColumn(
"tip_amount",
when(
col("payment_type") == 2,
lit(0)
).otherwise(
col("tip_amount")
)
)
# tip_amountカラムのユニーク値を再度確認
df.where(col("payment_type") == 2).select("tip_amount").distinct().show()
# 出力結果:
# +----------+
# |tip_amount|
# +----------+
# | 0.0|
# +----------+
この修正により、payment_type が現金払いの場合における tip_amountは一律0.0となり、テーブル定義との一貫性が確保されました。
このように、定義やルールと矛盾していたデータを修正することで、データセット全体の信頼性を向上させることができます。
4. Delta Lake機能を活用したデータ品質担保
Delta Lakeは、明示的な品質チェックを実行する前段階で、本質的にデータ品質の維持・向上に貢献します。本章では、Delta Lakeを利用して、データ品質の低下予防に役立つ機能について解説と実装を行っていきます。
前準備
Parquet形式で読み込んだデータをDelta Lake形式に変換します。
# TLC Trip Record DataをDelta Lake形式に変換し、再読み込み
delta_table_path = "nyctaxi_trips.delta"
df.write.format("delta").mode("overwrite").save(delta_table_path)
df = spark.read.format("delta").load(delta_table_path)
スキーマ強制
スキーマ強制は、Deltaテーブルへのデータ書き込み時に、書き込もうとするデータのスキーマがテーブルの既存スキーマと互換性があるかを自動的に検証する機能です。
デフォルトでこの機能は有効になっており、以下のようなスキーマの不一致が検出されると、書き込み処理を失敗させます。
- カラムのデータ型が異なる場合: 例えば、テーブルの既存スキーマで特定のカラムが整数型(IntegerType)で定義されているのに、書き込もうとするデータで同名カラムが文字列型(StringType)になっている場合。
-
カラムの不一致:テーブルに定義されていないカラムが書き込みデータに存在する(かつ、後述するスキーマ進化が有効になっていない場合)。
テーブルで定義されているカラムが書き込みデータに存在しない(NULL許容でない場合など、状況による)。 - カラム名の不一致: 大文字・小文字の違いなど(Sparkのオプション設定によるが、Delta Lakeは通常スキーマで定義されたカラム名を強制する)。
このスキーマ強制により、意図しないデータの混入やスキーマの破壊を防ぎ、テーブルのデータの妥当性と一貫性を強力に保護します。結果として、データパイプライン全体の信頼性と堅牢性が向上します。
実際にスキーマ強制がどのように機能するかを、以下のコード例で見てみましょう。
既存のDeltaテーブルに対して、意図的にスキーマが異なる(この例では VendorID カラムのデータ型を既存の型から変更した)DataFrameを追記しようと試みます。
delta_table_path = mount_load_path+"nyctaxi_trips.delta"
# データ型を整数から文字列に変更した新しいDataFrameを作成
df_incompatible_schema = df.limit(1).withColumn(
"VendorID",
col("VendorID").cast(StringType())
)
print(f"\nスキーマが異なるDataFrameを既存のDeltaテーブルに追記します...")
try:
# スキーマが異なるDataFrameを 'append' モードで書き込む
df_incompatible_schema.write.format("delta").mode("append").save(delta_table_path)
except Exception as e:
print("\n書き込みが失敗しました!")
print(f"エラーメッセージ: {e}")
# 出力結果:
# スキーマが異なるDataFrameを既存のDeltaテーブルに追記します...
# 書き込みが失敗しました!
# エラーメッセージ: [DELTA_FAILED_TO_MERGE_FIELDS] Failed to merge fields 'VendorID' and 'VendorID'
スキーマが異なるDataFrameを書き込もうとすると、処理は失敗しエラーメッセージが表示されます。
スキーマ進化
Delta Lakeのスキーマ進化は、スキーマ強制とは対照的に、テーブルのスキーマをデータの書き込みに合わせて安全に変更(進化)させる機能です。
テーブル全体を再書き込みすることなく、ビジネス要件の変化やソースデータの変更などによって必要となるスキーマの更新(特に新しいカラムの追加)を制御しながら許可します。
スキーマ進化は、書き込み時に.option("mergeSchema", "true")を設定することで有効になります。このオプションを指定すると、Delta Lakeは書き込みデータのスキーマとテーブルの既存スキーマを比較し、互換性のある変更を自動的に適用します。
最も一般的なユースケースは、書き込みデータに存在する新しいカラムを既存のテーブルスキーマに安全に追加することです。
スキーマ進化により、スキーマ強制によってデータパイプラインが予期せず停止するのを防ぎつつ、進化するデータ要件に柔軟に対応できるようになります。これにより、データパイプラインの継続性と拡張性を維持する上で役立ちます。
実際にスキーマ進化(カラム追加)がどのように機能するかを、以下のコード例で見てみましょう。
# スキーマ進化テスト用の新しいパス
delta_table_path = "nyctaxi_trips_evo_success.delta"
print(f"スキーマ進化前のテーブルのスキーマ:{df.schema[0]}")
# VendorIDをStringTypeにキャスト
df_new_schema = df
df_new_schema = df_new_schema.withColumn("VendorID", col("VendorID").cast(StringType()))
# スキーマが異なるDataFrameを 'append' モードで、mergeSchema オプションを true にして書き込む
df_new_schema.write.format("delta") \
.option("mergeSchema", "true") \
.mode("append") \
.save(delta_table_path)
print("書き込みが成功しました! (スキーマ進化)")
# スキーマ進化後のテーブルを確認
df_after_evolution = spark.read.format("delta").load(delta_table_path)
print(f"スキーマ進化後のテーブルのスキーマ:{df_after_evolution.schema[0]}")
# 出力結果:
# スキーマ進化前のテーブルのスキーマ:StructField('VendorID', IntegerType(), True)
# 書き込みが成功しました! (スキーマ進化)
# スキーマ進化後のテーブルのスキーマ:StructField('VendorID', StringType(), True)
この例では.option("mergeSchema", "true") を指定したため、Delta Lakeは既存のテーブルスキーマを自動的に更新し、VendorIDカラムのデータ型をIntegerTypeからStringTypeに変更しました。これにより、書き込みは成功し、テーブルは新しいスキーマ(VendorIDがStringType)を持つようになります。
このように、スキーマ進化を利用することで、データソースの変更や分析要件の追加に伴うスキーマの更新(またはカラム追加)に、データパイプラインを停止させることなく柔軟に対応できます。
5. まとめ
本稿では、データ活用の重要性が増す現代において不可欠となる「データ品質」に焦点を当て、その概念と実践的な管理手法について解説しました。
特に、ビッグデータ処理の分野で広く利用されるApache Sparkと、データレイクに信頼性をもたらすDelta Lakeを組み合わせることで、どのようにデータ品質を維持・向上できるかを具体的な実装例と共に示しました。
Sparkの高速なデータ処理能力と、Delta Lakeの信頼性保証機能を組み合わせることは、データ品質に関する課題に対処し、高品質で信頼性の高いデータ基盤を構築するための有効なアプローチです。
本稿で紹介した概念と実装が、データマネジメント業務、特にデータ品質管理の実践において一助となれば幸いです。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。