はじめに
SnowflakeにはAI & ML機能の一つとしてDocument AIというサービスがあります。
ざっくり言えば、「PDFなどの非構造データから任意のデータを抽出できる」という機能です。
しかし、2025年5月時点では 日本語は正式にサポートされていないため、以下の注意書きされています。
『満足のいく結果が得られない可能性があります』
そこで、日本語環境における Document AIの性能を評価するために、同じフォーマットの履歴書を用いて英語版と日本語版のPDFを比較検証してみました。
検証してみた結果
さっそく検証結果です。
結論、Document AIでは日本語版のPDFからは取得したい値を抽出できませんでした。
(モデルトレーニングは実施していません)
英語版PDFでは、「What is your name」等の定義した項目の多くが正しく抽出できていたのに対し、日本語版では 質問に対する回答がすべて「No Answer」でした。
英語版と同じく質問を定義したにも関わらずこの結果だったため、精度が低いというより「日本語が未対応」 という印象でした。(※実際に公式サポート言語にも日本語は含まれていません)
日本語版PDFは、Complete関数を使用することで、英語版と同等の回答を得ることができました。
やってみた
実際にDocument AIを用いた検証を行った手順を紹介します。
準備
チュートリアルを参考に環境のセットアップを実施します。
チュートリアル:Document AI
-
Document AIで使用するデータベースとスキーマを作成
CREATE DATABASE doc_ai_db; CREATE SCHEMA doc_ai_db.doc_ai_schema; -
操作用のroleを用意
USE ROLE ACCOUNTADMIN; CREATE ROLE doc_ai_role; -
必要権限の付与
//Document AIの操作権限 GRANT DATABASE ROLE SNOWFLAKE.DOCUMENT_INTELLIGENCE_CREATOR TO ROLE doc_ai_role; //ウェアハウスの使用権限と操作権限 GRANT USAGE, OPERATE ON WAREHOUSE <your_warehouse> TO ROLE doc_ai_role; //データベースとスキーマを使用する権限 GRANT USAGE ON DATABASE doc_ai_db TO ROLE doc_ai_role; GRANT USAGE ON SCHEMA doc_ai_db.doc_ai_schema TO ROLE doc_ai_role; //スキーマの作成ステージ権限(PDFの格納用に必要) GRANT CREATE STAGE ON SCHEMA doc_ai_db.doc_ai_schema TO ROLE doc_ai_role; //モデルの作成権限 GRANT CREATE SNOWFLAKE.ML.DOCUMENT_INTELLIGENCE ON SCHEMA doc_ai_db.doc_ai_schema TO ROLE doc_ai_role; //ユーザに付与 GRANT ROLE doc_ai_role TO USER <your_user_name>;
モデルの作成と定義
-
モデルの準備
以下のように、英語履歴書・日本語履歴書のそれぞれ2つのモデルを作成していきます。(キャプチャは英語履歴書用のモデルResume_EN)
作成できました

次に、モデルにデータを学習させるためにPDFファイルをアップロードします。今回は、以下のような架空の履歴書を扱います。


-
英語履歴書からデータの抽出
それでは、自然言語を使って抽出するデータの定義をしましょう。英語版はうまく抽出できていますね。ただし、紫下線の保有資格を抽出してほしい箇所は2行分の回答がほしいところ、1行の回答しか抽出できていません。

質問の仕方を変えてみましょう。
(前)What is your skill?
(後)What qualifications or certifications do you have?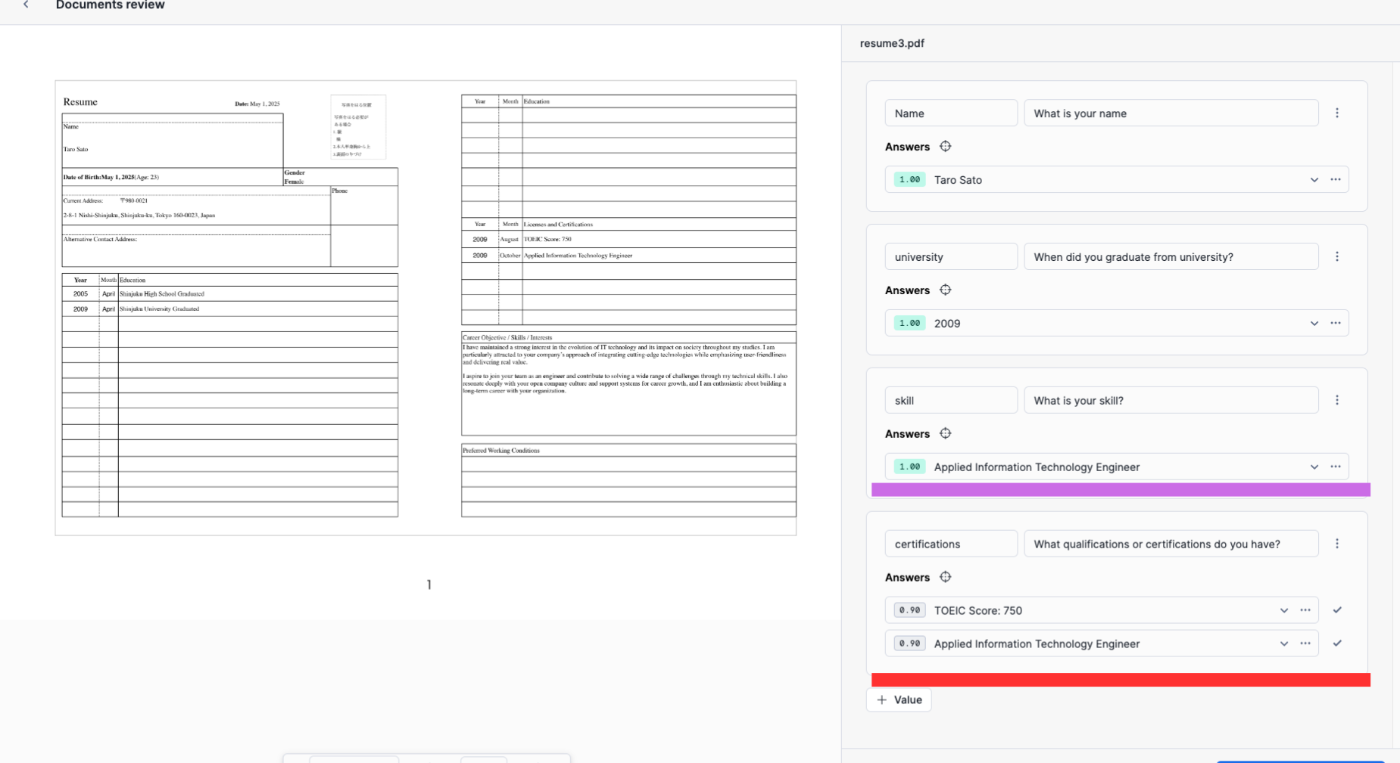
お、ちゃんと複数回答してくれましたね。
skillはなんですか?という質問の仕方が抽象的すぎたのかもしれませんね。
-
日本語履歴書からデータの抽出
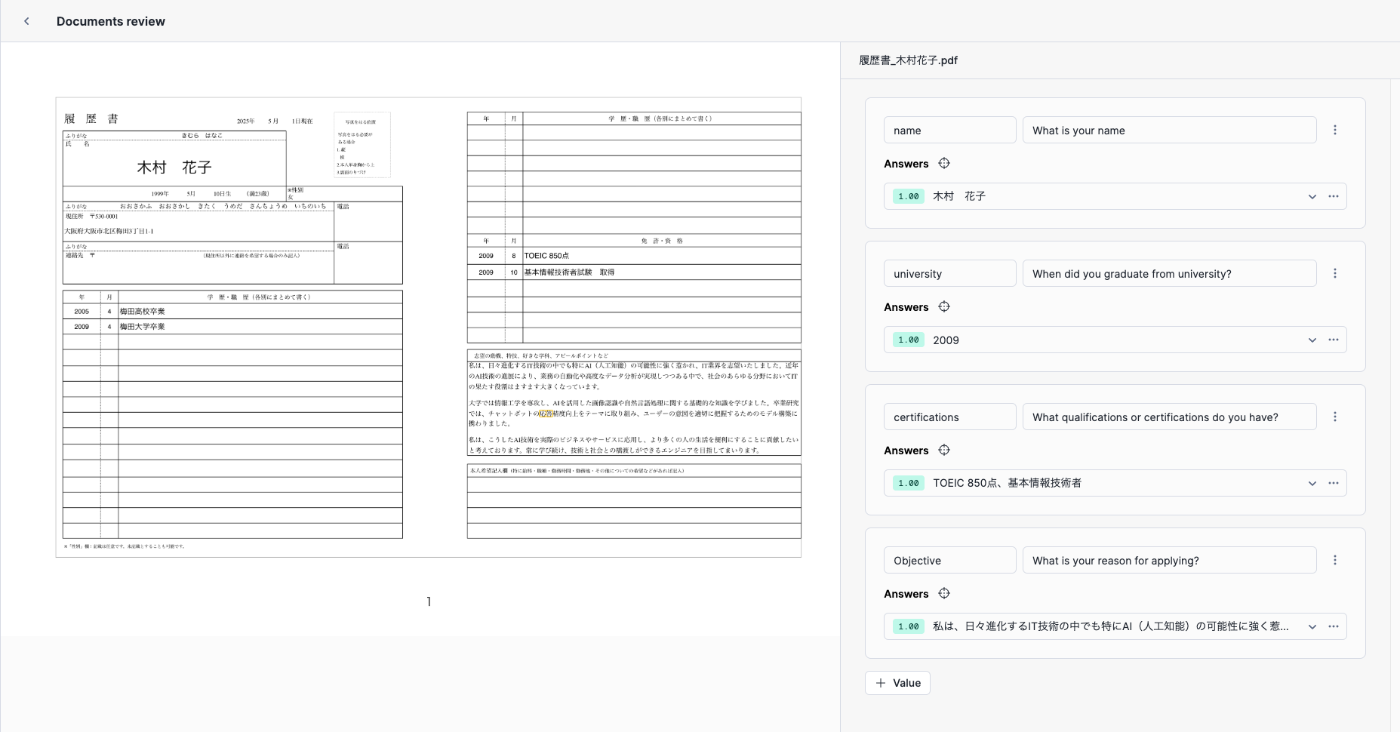
英語版と同じ質問を定義してみましたが、『満足のいく結果が得られませんでした』What系の質問には回答なしですが、唯一、When系の質問(大学卒業は?)に2009と正確な回答が返ってきたので、確認のために、高校卒業年度と誕生日を聞いてみましたが、全て一律2009と返ってきました。なので、日本語の中身を理解して結果を返しているようではなさそうです。

わるあがきとして、公式のドキュメントの「結果が不正解の場合は手動入力してください。」に従い、
ほしい結果を手入力して、次のPDFの出力結果を確認しましたが、特に変化は見られませんでした。
結果が満足のいくものでない場合は、 Document AI モデルをトレーニングして結果を改善することができます。
とさらにできることはありそうですが、本記事では扱わないこととします。
作成したモデルをパイプラインに組み込んでみる
英語履歴書のモデルがPDFから定義した内容を抽出できることがわかりました。
次に実践として、以下のドキュメント処理パイプラインを構築します。
- 英語履歴書のモデルを組み込んだパイプラインを作成
- パイプラインの処理結果を格納するテーブルを作成
- 内部ステージ上に英語履歴書.pdfをアップロード
- パイプラインが英語履歴書から定義した内容を抽出し、テーブルに挿入する
-
パイプラインの作成
//内部ステージの作成 CREATE OR REPLACE STAGE resume_pdf_stage DIRECTORY = (ENABLE = TRUE) ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE'); //ステージ上にstreamを作成 CREATE STREAM resume_pdf_stream ON STAGE resume_pdf_stage; //英語履歴書から抽出したデータを格納するテーブルを作成 CREATE OR REPLACE TABLE resume_pdf_reviews ( file_name VARCHAR, file_size VARIANT, last_modified VARCHAR, snowflake_file_url VARCHAR, json_content VARCHAR ); //タスクの作成 CREATE OR REPLACE TASK load_new_resume_file_data WAREHOUSE = 'DOC_AI_WH' SCHEDULE = '1 minute' WHEN SYSTEM$STREAM_HAS_DATA('resume_pdf_stream') AS INSERT INTO resume_pdf_reviews ( SELECT RELATIVE_PATH AS file_name, size AS file_size, last_modified, file_url AS snowflake_file_url, RESUME_EN!PREDICT(GET_PRESIGNED_URL('@resume_pdf_stage', RELATIVE_PATH), 1) AS json_content FROM resume_pdf_stream WHERE METADATA$ACTION = 'INSERT' );
-
実行
作成したステージにPDFアップロード

アップロードしたPDFの内容

- 結果
パイプラインで処理した結果、抽出値をJSON_CONTENT列に格納できました。
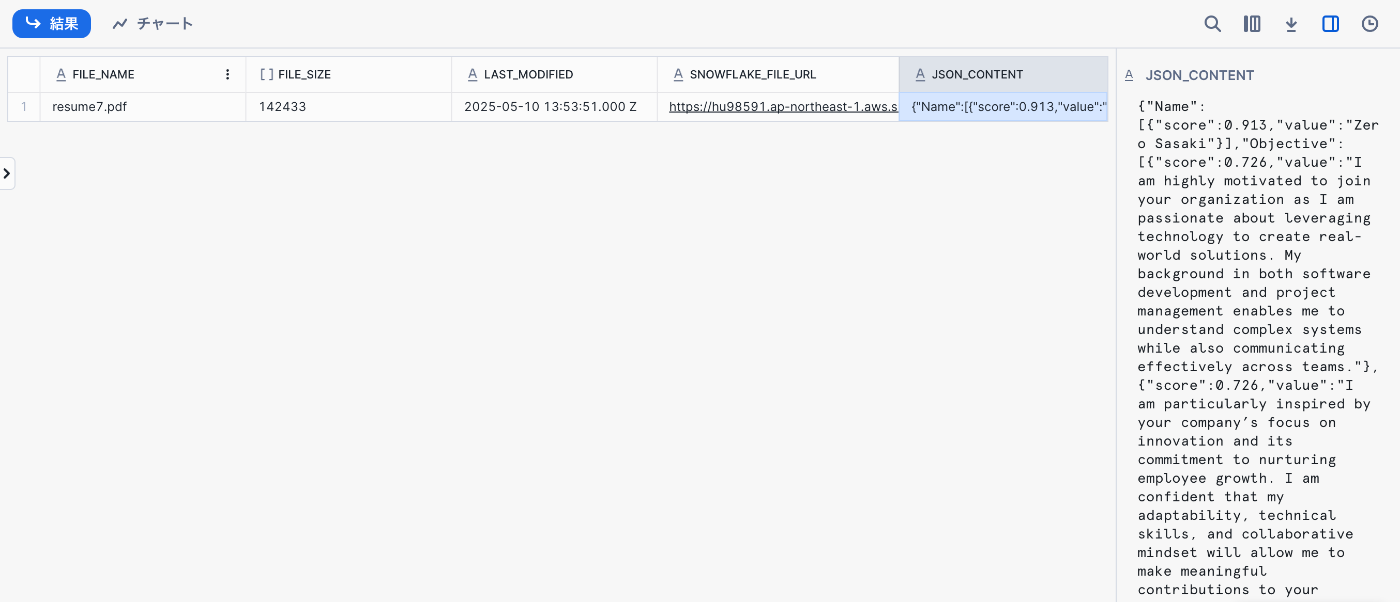
JSON_CONTENT列は以下のとおりです。
{
"Name": [
{
"score": 0.913,
"value": "Zero Sasaki"
}
],
"Objective": [
{
"score": 0.726,
"value": "I am highly motivated to join your organization as I am passionate about leveraging technology to create real-world solutions. My background in both software development and project management enables me to understand complex systems while also communicating effectively across teams."
},
{
"score": 0.726,
"value": "I am particularly inspired by your company’s focus on innovation and its commitment to nurturing employee growth. I am confident that my adaptability, technical skills, and collaborative mindset will allow me to make meaningful contributions to your team."
}
],
"__documentMetadata": {
"ocrScore": 0.896
},
"certifications": [
{
"score": 0.904,
"value": "TOEIC Score: 750"
},
{
"score": 0.904,
"value": "Applied Information Technology Engineer"
},
{
"score": 0.904,
"value": "AWS Certified Solutions Architect – Associate"
}
],
"university": [
{
"score": 0.898,
"value": "2009"
}
]
}
追加検証(Complete関数で日本語履歴書を解析してみた)
Document AIでは、日本語のドキュメントを処理できなかったため、Complete関数を用いた追加検証を行います。Cortex COMPLETE Multimodal
-
準備
// complete関数用のデータベース・スキーマ作成 CREATE DATABASE complete_db; //内部ステージの作成 CREATE OR REPLACE STAGE input_stage DIRECTORY = (ENABLE = true) ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE'); //クロスリージョン推論を設定 ALTER ACCOUNT SET CORTEX_ENABLED_CROSS_REGION = 'AWS_US'; -
内部ステージに履歴書をアップロード
アップロードした履歴書の内容

※2025年5月時点では、Complete関数はpdfには対応していないため、事前に履歴書をjpgに変換 -
実行
//TOEICスコアと住所の抽出を指示 SELECT 'TOEIC Score' AS question, SNOWFLAKE.CORTEX.COMPLETE( 'claude-3-5-sonnet', 'What is your TOEIC score', TO_FILE('@input_stage', 'Resume_Jap01_page-0001.jpg') ) AS response UNION ALL SELECT 'Address' AS question, SNOWFLAKE.CORTEX.COMPLETE( 'claude-3-5-sonnet', 'What is your address', TO_FILE('@input_stage', 'Resume_Jap01_page-0001.jpg') ) AS response; -
結果
指示通りに住所とTOEICスコアをを抽出できました。

おわりに
最終的には、Document AI,Complete関数を使用することで、英語・日本語のいずれの履歴書からも、値を抽出することができました。しかし、今回は限られた数ファイルでの検証となっています。今後は「どれくらいの精度で抽出できるか?」「精度向上のためにはなにをするべきか」といった検証にもtryしていきたいと思いました。
仲間募集
NTTデータ コンサルティング事業本部 では、以下の職種を募集しています。
Snowflake、生成AIを活用したデータ基盤構築/活用支援(Snowflake Data Superheroesとの協働)
Databricks、生成AIを活用したデータ基盤構築/活用支援(Databricks Championとの協働)
プロジェクトマネージャー(データ分析プラットフォームソリューションの企画~開発~導入/生成AI活用)
クラウドを活用したデータ分析プラットフォームの開発(ITアーキテクト/PM/クラウドエンジニア)
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとSnowflakeについて
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。
NTTデータとInformaticaについて
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。