はじめに
先日、dbt Cloudのローコード開発機能「dbt Canvas」(旧名称「dbt Visual Editor」)のGAを記念して、dbt Canvasを使ったモデルの作成や編集方法についての記事を投稿しました。
dbt Canvasは、GUIによる直感的な操作で、ローコードでモデルを作成・編集できる機能です。
dbt Canvasで作成したコードを後から手動で修正するケースを考えると、自動生成されるSQLを理解しておくことは非常に重要です。
本記事では、dbt の基本的な知識があり、dbt Canvasで生成されるSQLに関心がある方向けに、dbt Canvas上で利用できる「オペレーター」の操作によって、実際にどのようなSQLが生成されるのかを紹介します。
💡オペレーターとは?
データに対して行いたい操作(例:結合・フィルター)を、dbt Canvas上で設定するためのブロックです。
なお、dbt Canvasの利用に必要な事前準備やアクセス方法については公式ドキュメント(Quickstart for dbt Cloud Canvas)、基本的な操作方法については前回の記事をご参照ください。
dbt CanvasにおけるSQL生成の基本構成
dbt Canvasでは、基本的には各オペレーターに1つずつ共通テーブル式(以下、CTE)が生成されます。ただし、Output modelオペレーターでは、ターゲットとなるテーブルのカラムを定義するCTEに加え、そのCTEを参照して結果を出力する SELECT * 文が最後に追加されます。これにより、デバッグ時には、必要に応じて柔軟に絞り込むことが可能です。

また、SQLはオペレーターでの操作に合わせて、リアルタイムで生成されます。
画質が少し粗いですが、右側でSQLが即座に更新されていく様子をご確認いただけるかと思います。
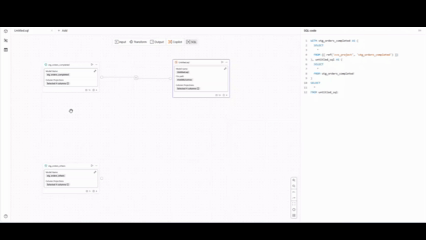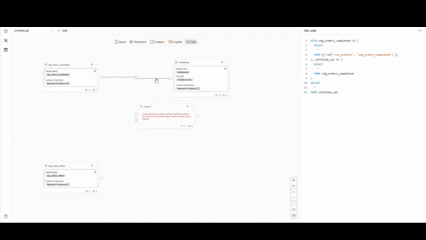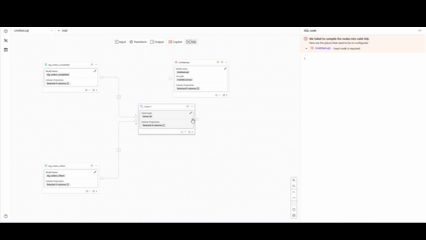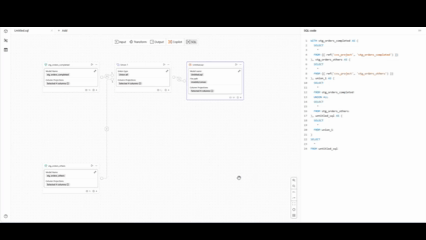
各オペレーターで生成されるSQL
Input model、Transform、Output modelオペレーターごとに生成されるSQLを紹介します。
カラム選択・コメント付与・CTE名の変更といった、オペレーター共通の操作によって生成されるSQLについては、次の章で取り上げます。
Input modelオペレーター
Input modelオペレーターでは、ソーステーブルとしてdbtのモデルを指定できます。指定されたモデルは、依存関係を自動的に管理する ref() を通じてSQLに取り込まれ、他のオペレーターで参照できるようになります。
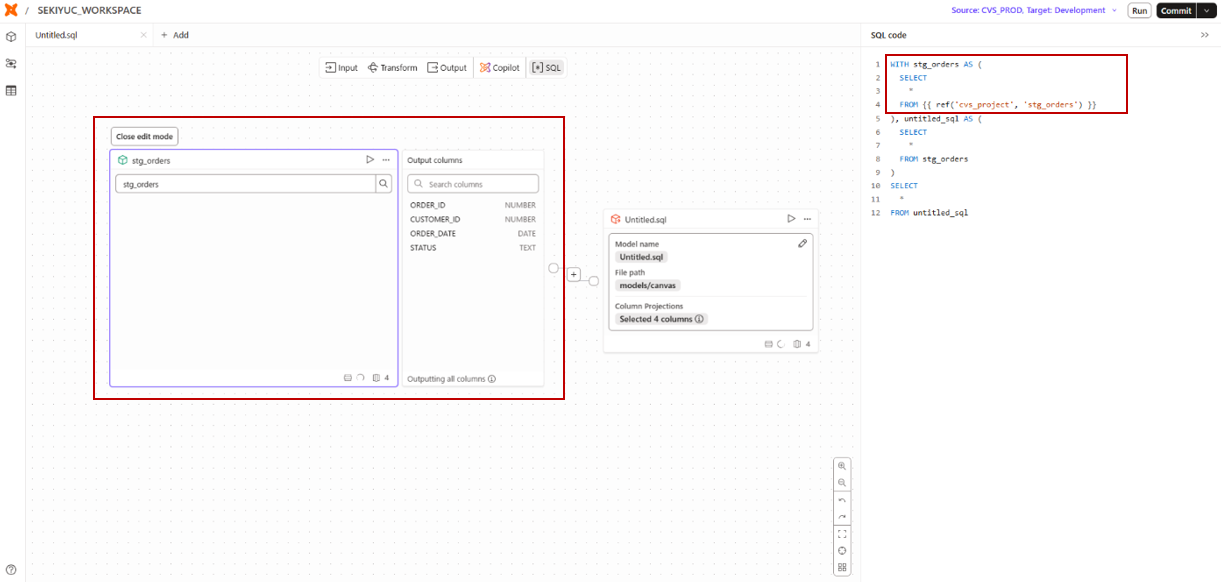
たとえば、cvs_project プロジェクトにある stg_orders モデルをソースとして設定した場合、以下のようなSQLが生成されます。
Input modelオペレーターで生成されるSQL
WITH stg_orders AS ( -- Input modelオペレーターによって追加されたCTE
SELECT
*
FROM {{ ref('cvs_project', 'stg_orders') }}
),
Transformオペレーター
dbt Canvasには以下のようなTransformオペレーターが用意されています。オペレーターごとに生成されるSQLを紹介します。

Join
Joinオペレーターを使用すると、指定した結合条件に基づき、複数のテーブルを組み合わせることができます。
たとえば、stg_ordersテーブルとstg_customersテーブルをCUSTOMER_IDで結合した場合、以下のようなSQLが生成されます。
Joinオペレーターで生成されるSQL
join_1 AS ( -- Joinオペレーターによって追加されたCTE
SELECT
*
FROM stg_orders
LEFT JOIN stg_customers -- 設定に基づきJoin句を追加
ON stg_orders.CUSTOMER_ID = stg_customers.CUSTOMER_ID
)

Union
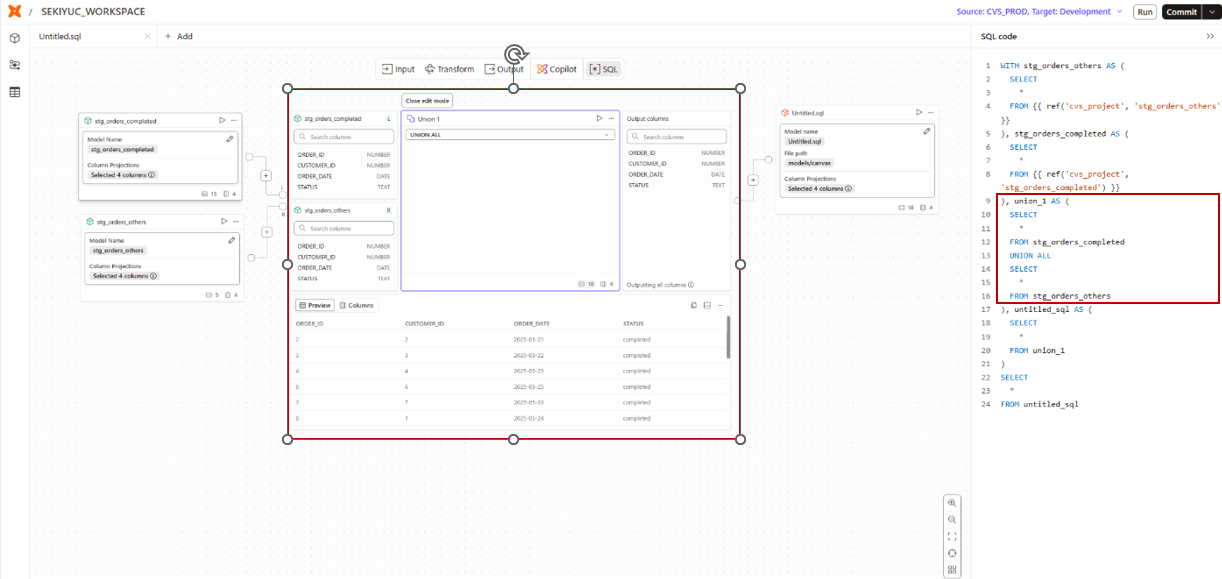
Unionオペレーターを使用すると、複数のテーブルを縦方向に連結し、1つのテーブルとしてまとめることができます。
たとえば、stg_orders_completedテーブルとstg_orders_othersテーブルを統合し、1つの注文データセットとして扱った場合、以下のようなSQLが生成されます。
Unionオペレーターで生成されるSQL
union_1 AS ( -- Unionオペレーターによって追加されたCTE
SELECT
*
FROM stg_orders_completed
UNION ALL -- 設定に基づきUnionを追加
SELECT
*
FROM stg_orders_others
)
Formula
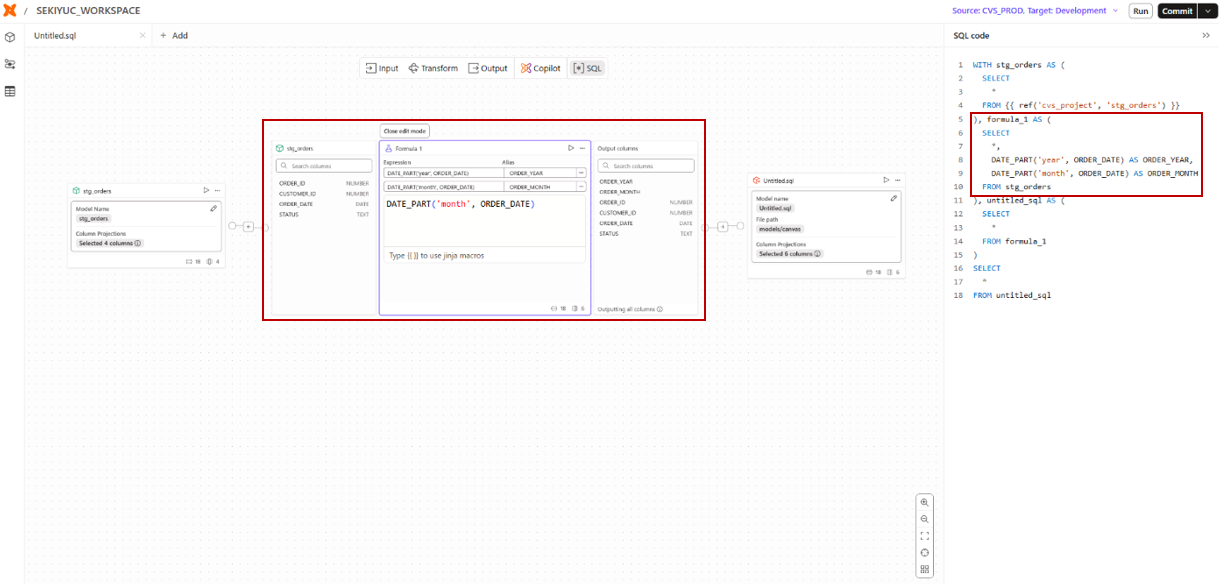
Formulaオペレーターを使用すると、式や関数を使って新しい列を追加することができます。
たとえば、stg_ordersテーブルのORDER_DATEカラムから年と月の情報を抽出した場合、以下のようなSQLが生成されます。
なお、マクロも問題なく利用することができます。
Formulaオペレーターで生成されるSQL
formula_1 AS ( -- Formulaオペレーターによって追加されたCTE
SELECT
*,
DATE_PART('year', ORDER_DATE) AS ORDER_YEAR, -- 設定に基づき関数を用いたカラムを追加
DATE_PART('month', ORDER_DATE) AS ORDER_MONTH
FROM stg_orders
)
Aggregate
Aggregateオペレーターを使用すると、集計関数とグループ化に使用するカラムを指定して集計することができます。
たとえば、stg_ordersテーブルからORDER_IDごとに最初と最新の注文日、さらに注文回数を集計した場合、以下のようなSQLが生成されます。
なお、dbt Canvasではカラム名に日本語を使用すると、自動的にダブルクオーテーションが付けられます。
Aggregateオペレーターで生成されるSQL
aggregate_1 AS ( -- Aggregateオペレーターによって追加されたCTE
SELECT
ORDER_ID,
MIN(ORDER_DATE) AS FIRST_ORDER, -- 設定に基づき集計処理を追加
MAX(ORDER_DATE) AS MOST_RECENT_ORDER,
COUNT(ORDER_ID) AS NUMBER_OF_ORDERS
FROM stg_orders
GROUP BY
ORDER_ID
)

Limit
Limitオペレーターを使用すると、返す行数の上限を設定することができます。
たとえば、stg_ordersテーブルの先頭5件だけにレコードを制限した場合、以下のようなSQLが生成されます。
なお、Limitオペレーターでは他のオペレーターと違い、専用のCTEは作成されず、直前のCTEに LIMIT 句が直接追加される形で出力されます。
Limitオペレーターで生成されるSQL
WITH stg_orders AS (
SELECT
*
FROM {{ ref('cvs_project', 'stg_orders') }}
LIMIT 5 -- LimitオペレーターはCTEを追加せず、直前のCTEに直接LIMIT句を挿入
)

Order
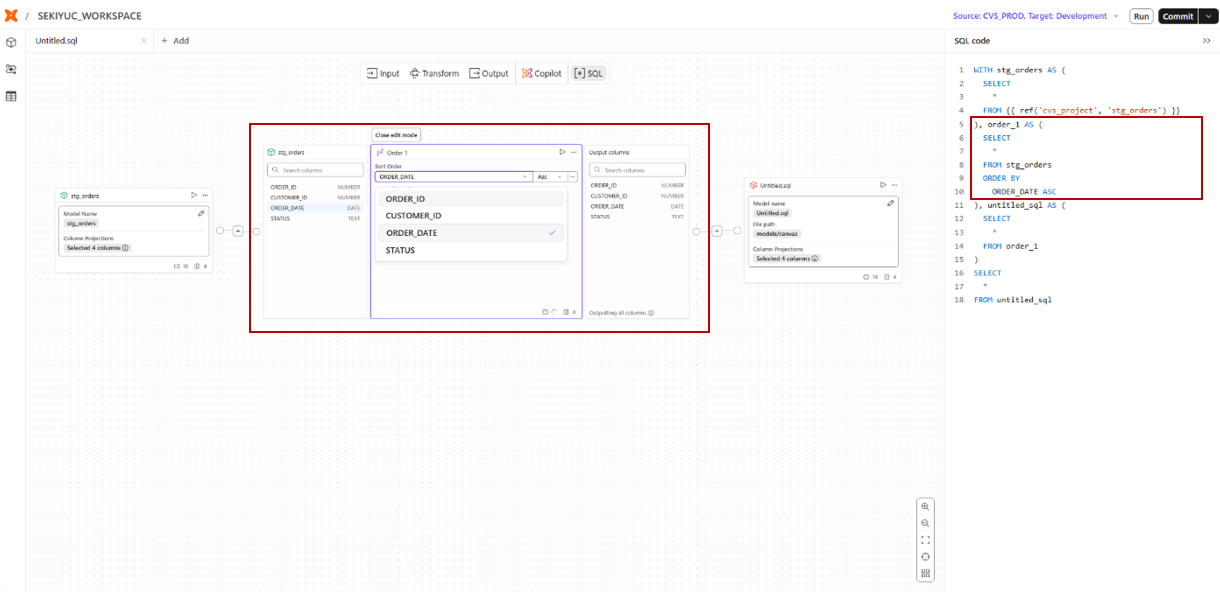
Orderオペレーターを使用すると、並び替え対象の列と、その昇順・降順を指定することができます。
たとえば、stg_ordersテーブルをORDER_DATEの昇順に並び替えた場合、以下のようなSQLが生成されます。
Orderオペレーターで生成されるSQL
order_1 AS ( -- Orderオペレーターで生成されたCTE
SELECT
*
FROM stg_orders
ORDER BY -- 指定条件に基づきORDER BY句を追加
ORDER_DATE ASC
)
Filter
Filterオペレーターを使用すると、条件を指定して、必要なデータを抽出することができます。
たとえば、stg_ordersテーブルから2025年5月24日以降の注文データのみを抽出した場合、以下のようなSQLが生成されます。
Filterオペレーターで生成されるSQL
filter_1 AS ( -- Filterオペレーターで生成されたCTE
SELECT
*
FROM stg_orders
WHERE -- 指定条件に基づきWHERE句を追加
ORDER_DATE > '2025-05-24'
)
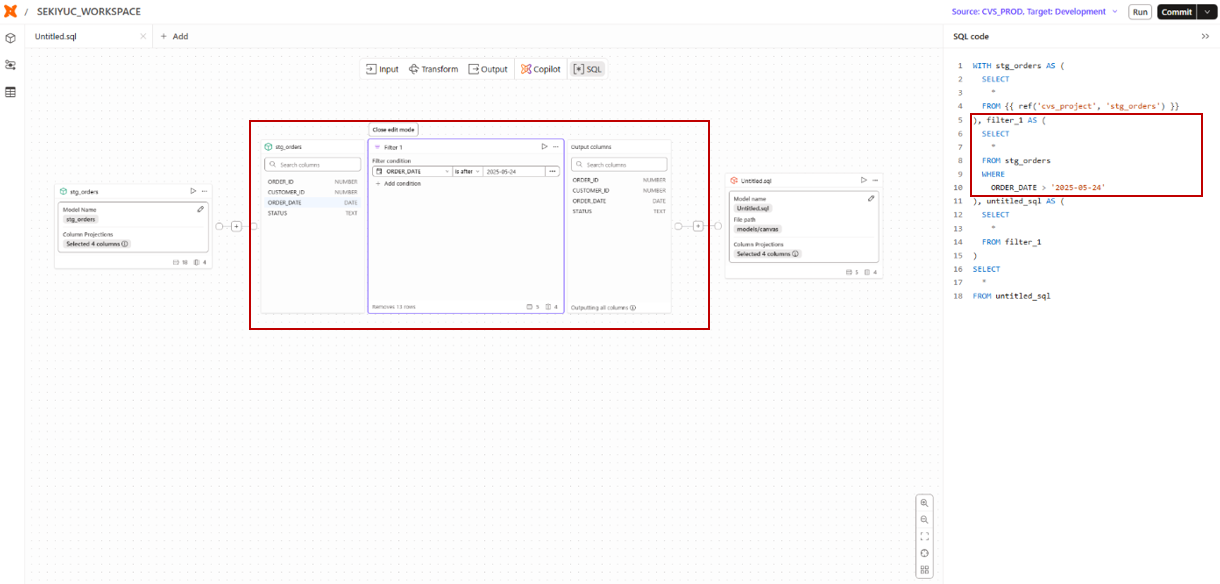
Rename
Renameオペレーターを使用すると、カラム名を変更することができます。
たとえば、stg_ordersテーブルのORDER_IDをIDに、STATUSをORDER_STATUSに名称を変更した場合、以下のようなSQLが生成されます。
Renameオペレーターで生成されるSQL
rename_1 AS ( -- Renameオペレーターで生成されたCTE
SELECT
*
RENAME (ORDER_ID AS ID, STATUS AS ORDER_STATUS) -- 設定に基づきRenameを定義
FROM stg_orders
)
Output modelオペレーター
Output modelオペレーターは、dbt Canvas上で作成したモデル名や出力カラムの設定に使用します。
たとえば、モデル名を test_model に設定した場合、以下のようなSQLが生成されます。
なお、出力カラムの設定については、次の章で取り上げます。
Output modelオペレーターで生成されるSQL
test_model_sql AS ( -- Output modelオペレーターで生成されたCTE
SELECT
*
FROM stg_orders
)
SELECT -- Output modelオペレーターによって生成された最終出力ステップ
*
FROM test_model_sql

オペレーター共通操作で生成されるSQL
カラム選択・コメント付与・CTE名の変更といった、オペレーター共通の操作によって生成されるSQLについて紹介します。
カラム選択
各オペレーターでは、デフォルトで全カラムが出力されますが、手動でカラムを選択することで、出力対象を制限することができます。
たとえば、Input modelオペレーターで stg_orders モデルの CUSTOMER_ID を出力対象から除外した場合、以下のようなSQLが生成されます。
カラム選択で生成されるSQL
WITH stg_orders AS (
SELECT
CUSTOMER_ID, --SELECT *が消え、出力対象のカラムが表示される
ORDER_DATE,
STATUS
FROM {{ ref('cvs_project', 'stg_orders') }}
)

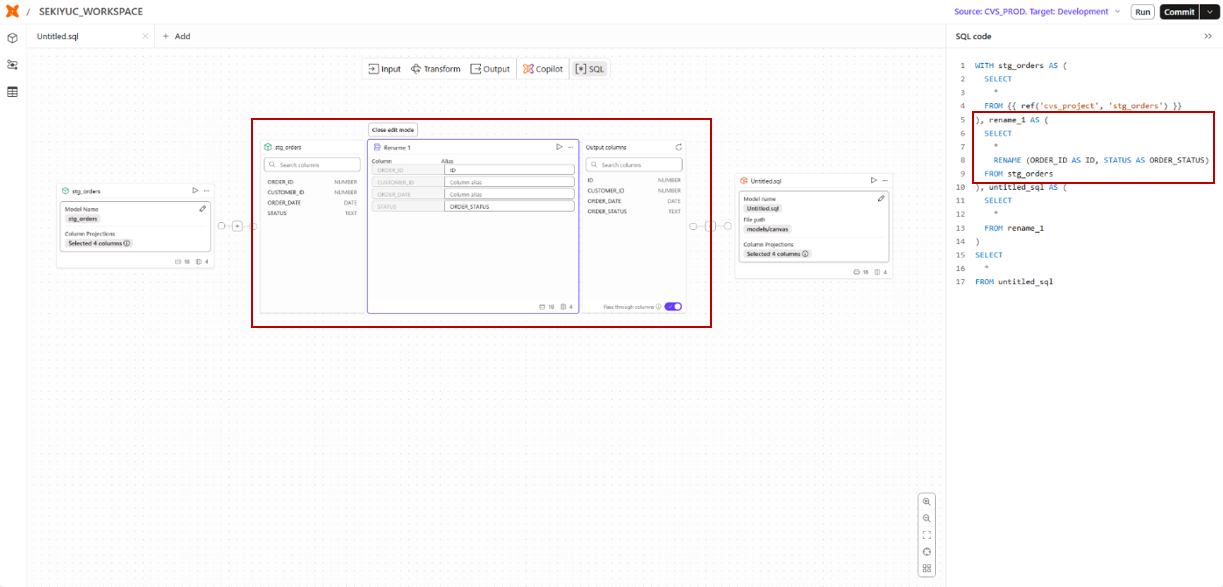
コメント付与
コメントは、クエリ中に補足説明や意図を明示するための記述であり、dbt CanvasでもGUI上から簡単に追加できます。
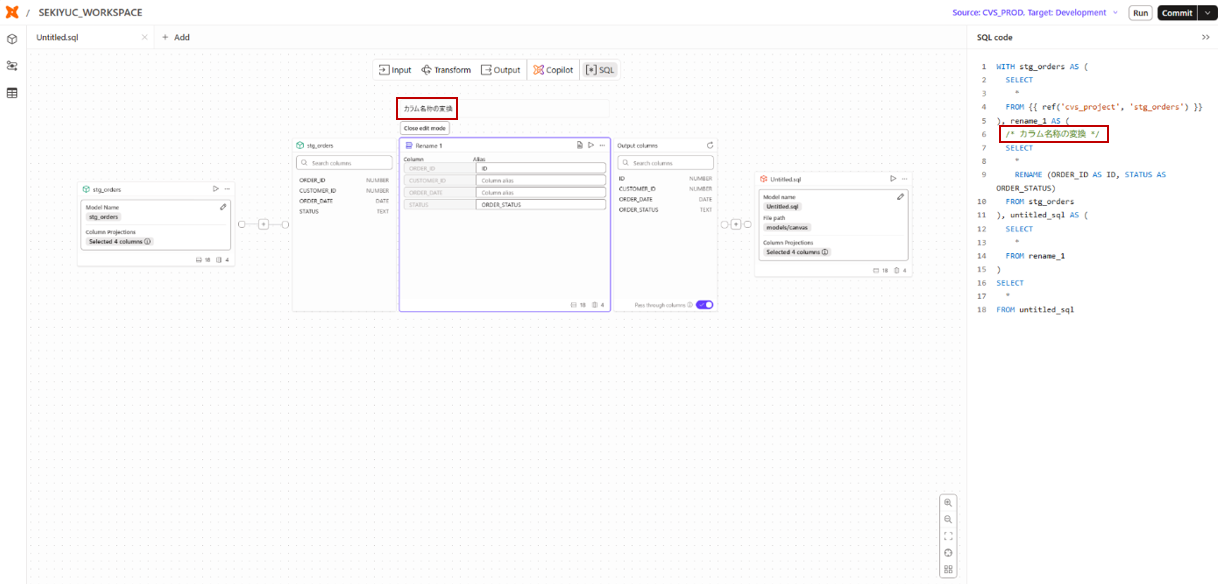
たとえば、stg_orders テーブルのカラム名を変更する処理に対して「カラム名称の変換」というコメントを付与した場合、以下のようなSQLが生成されます。
コメント付与で生成されるSQL
rename_1 AS (
/* カラム名称の変換 */ -- 付与されたコメント
SELECT
*
RENAME (ORDER_ID AS ID, STATUS AS ORDER_STATUS)
FROM stg_orders
)
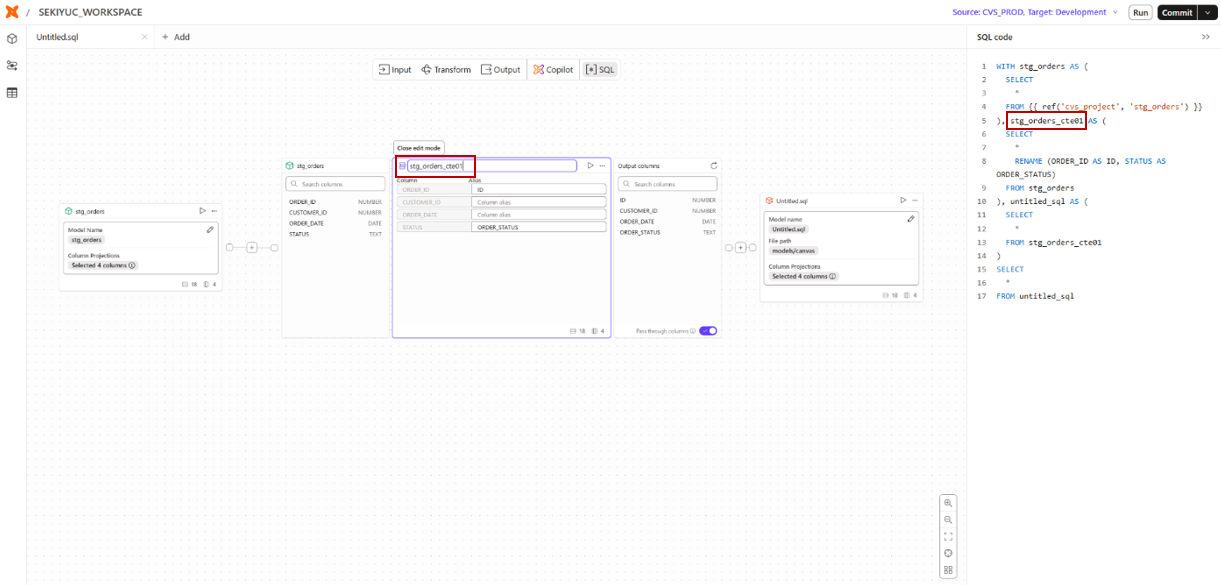
CTE名変更
前述の通り、dbt Canvasでは各オペレーターの処理ステップが自動的に CTE としてSQLに変換されます。
CTE名は、デフォルトでは以下のようにオペレーターの種類や設定に応じて自動的に命名されます:
- Input modelオペレーター:インプットモデルの名称
- Transformオペレーター:使用したオペレーターの種類に応じた名称(例:
formula_1、filter_1など) - Output modelオペレーター:アウトプットモデルの名称
このCTE名は、GUI上で手動で変更することも可能です。
たとえば、stg_orders テーブルに対してリネーム処理を行い、そのステップに明示的に stg_orders_cte01 という名前を設定した場合、以下のようなSQLが生成されます。
CTE名変更で生成されるSQL
stg_orders_cte01 AS ( -- 手動で指定したCTE名
SELECT
*
RENAME (ORDER_ID AS ID, STATUS AS ORDER_STATUS)
FROM stg_orders
)
まとめ
本記事では、dbt Canvasにおいて各オペレーターの操作に応じて、どのようなSQLが生成されるのかを、具体的なコード例とともに紹介しました。
dbt CanvasのシンプルなSQL生成について、理解を深めていただけたのではないでしょうか。
また、オペレーターごとにCTEを生成して処理の流れを明確にしている点や、デバッグを考慮したOutput modelの構成から、dbt Canvasの実用性の高さも感じていただけたかと思います。
興味のある方は、ぜひ実際にdbt Canvasを触って、リアルタイムに生成されるSQLを体感してみてください!
仲間募集
NTTデータ コンサルティング事業本部 では、以下の職種を募集しています。
Snowflake、生成AIを活用したデータ基盤構築/活用支援(Snowflake Data Superheroesとの協働)
Databricks、生成AIを活用したデータ基盤構築/活用支援(Databricks Championとの協働)
プロジェクトマネージャー(データ分析プラットフォームソリューションの企画~開発~導入/生成AI活用)
クラウドを活用したデータ分析プラットフォームの開発(ITアーキテクト/PM/クラウドエンジニア)
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~ TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。
NTTデータとInformaticaについて
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
NTTデータとTableauについて
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータとDataRobotについて
DataRobotは、包括的なAIライフサイクルプラットフォームです。
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。