はじめに
これは「Cortex AnalystをLevel別に検証してみよう」シリーズの パート2 です。
本稿はLevel 3(JOIN 前提) の検証と、そこから得た 設計上の考慮事項の整理にフォーカスしています。
前回(Part 1)の要点
- 単表〜マルチターン(Level1・2)では、初期設定のままでも、正答率は約7割。
- 単表〜マルチターン(Level1・2)では、“セマンティック”を整えることで正答率が改善
この記事でわかること(Part 2)
- relationships設計(SALES→STORE→REGION/SALES→ITEM)
- ピボット体裁を崩さないVerified Query化
- 導入時に使える設計チェックリスト
1. 検証シナリオ(再掲)
本シリーズの検証は、Cortex Analystの実力を3段階で実施していきます。
(本稿は Level 3 にフォーカスします)
| Level | 目的 | データ/前提 | 代表タスク/質問例 |
|---|---|---|---|
| 1(単一テーブル) | 単一テーブルで自然言語→SQLの正確性を確認 | 1テーブル(例:SALES) | 「2024年の売上合計」「月次売上の推移」「上位5商品」/ 同義語テスト |
| 2(単表×マルチターン) | 文脈の引き継ぎ(参照・省略・曖昧解消) | Level1と同一データ | ①「2024年の売上」→②「Q2だけ」→③「カテゴリTOP3」→④「前年同期比」 |
| 3(複数テーブル) | 複数テーブルJOIN前提の質問の正確性 | SALES × STORE(+α) | 「店舗別売上TOP3(SALES×STORE)」 |
結果の評価は、以下の観点で行いました。
| 観点 | 評価内容 | 指標例 | ポイント |
|---|---|---|---|
| 1. 複数質問での再現性 | 各Levelごとに質問カタログを用意(10問程度) | ― | 単発の成功に左右されないよう全体傾向を確認 |
| 2. 回答が返らないケース | 「SQLが生成されなかった」「生成されたSQLが実行エラーになった」を分けて集計 | - SQL生成失敗率 - SQL実行失敗率 |
正答率とは別に扱うことで、「出ない vs 出たけど間違い」を切り分け |
| 3. チューニング効果の比較 | セマンティック定義やモデル改善の前後を比較 | - 初回正答率(最初の試行で正答) - 最終正答率(修正後に正答) - 訂正率(最終−初回) |
Before/Afterで改善度を可視化 |
2. Level3:複数テーブルJOIN
2.1 環境準備
Level3 では、JOINを前提とした検証のために 4つのテーブルを用意します。
粒度は「注文明細(SALES)」、ディメンションとして「商品(ITEM)」「店舗(STORE)」「地域(REGION)」を参照する構成です。
Level3の検証用として以下のテーブルを用意しました。
① SALES_L3(売上明細:ファクト)
サンプルデータはランダム生成で約3,000件投入し、複数年・複数カテゴリに分布させています。
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| ORDER_ID | NUMBER | NOT NULL | 注文ID(明細単位でユニーク可) |
| ORDER_DATE | DATE | NOT NULL | 注文日 |
| ITEM_ID | NUMBER | NOT NULL | 商品ID(→ ITEM_DIM) |
| STORE_ID | NUMBER | NOT NULL | 店舗ID(→ STORE_DIM) |
| QUANTITY | NUMBER(4) | NOT NULL | 注文数量 |
| PRICE | NUMBER(10,2) | NOT NULL | 単価 |
② ITEM_DIM(商品ディメンション)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| ITEM_ID | NUMBER | PRIMARY KEY | 商品ID |
| ITEM_NAME | STRING | NOT NULL | 商品名 |
| CATEGORY | STRING | NOT NULL | 商品カテゴリ |
| BRAND | STRING | NULL | ブランド |
③ STORE_DIM(店舗ディメンション)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| STORE_ID | NUMBER | PRIMARY KEY | 店舗ID |
| STORE_NAME | STRING | NOT NULL | 店舗名(例:Tokyo_Store) |
| REGION_ID | NUMBER | NOT NULL | 地域ID(→ REGION_DIM) |
| STORE_TYPE | STRING | NULL | 店舗種別(例:Online, Physical) |
④ REGION_DIM(地域ディメンション)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| REGION_ID | NUMBER | PRIMARY KEY | 地域ID |
| REGION_NAME | STRING | NOT NULL | 地域名(例:Kanto, Kansai など) |
次に、セマンティックビューを定義します。
詳細な説明は省略しますが、テーブル間の結合に必要な最低限のrelationshipsを定義しています。
以下はそのイメージです。
name: L3_SEMANTIC
tables:
- name: SALES_L3
base_table: { database: CORTEX_LAB, schema: L3, table: SALES_L3 }
primary_key: { columns: [ORDER_ID] }
dimensions:
- { name: ITEM_ID, expr: ITEM_ID, data_type: NUMBER(38,0), description: "FK to ITEM_DIM.ITEM_ID" }
- { name: STORE_ID, expr: STORE_ID, data_type: NUMBER(38,0), description: "FK to STORE_DIM.STORE_ID" }
time_dimensions:
- { name: ORDER_DATE, expr: ORDER_DATE, data_type: DATE }
metrics:
- { name: REVENUE, expr: PRICE * QUANTITY, data_type: NUMBER(18,2) }
- name: ITEM_DIM
base_table: { database: CORTEX_LAB, schema: L3, table: ITEM_DIM }
primary_key: { columns: [ITEM_ID] }
dimensions:
- { name: ITEM_NAME, expr: ITEM_NAME }
- { name: CATEGORY, expr: CATEGORY }
- { name: BRAND, expr: BRAND }
- name: STORE_DIM
base_table: { database: CORTEX_LAB, schema: L3, table: STORE_DIM }
primary_key: { columns: [STORE_ID] }
dimensions:
- { name: STORE_NAME, expr: STORE_NAME }
- { name: STORE_TYPE, expr: STORE_TYPE }
- { name: REGION_ID, expr: REGION_ID, data_type: NUMBER(38,0), description: "FK to REGION_DIM.REGION_ID" }
- name: REGION_DIM
base_table: { database: CORTEX_LAB, schema: L3, table: REGION_DIM }
primary_key: { columns: [REGION_ID] }
dimensions:
- { name: REGION_NAME, expr: REGION_NAME }
relationships:
- name: Sales_to_Store
left_table: SALES_L3
right_table: STORE_DIM
relationship_columns:
- { left_column: STORE_ID, right_column: STORE_ID }
- name: Store_to_Region
left_table: STORE_DIM
right_table: REGION_DIM
relationship_columns:
- { left_column: REGION_ID, right_column: REGION_ID }
- name: Sales_to_Item
left_table: SALES_L3
right_table: ITEM_DIM
relationship_columns:
- { left_column: ITEM_ID, right_column: ITEM_ID }
2.2 実行:質問ごとの評価
本セクションでは、JOINを伴う自然言語クエリに対してCortex Analystが正しい結合経路を自動で選べるかを主に検証します。
具体的には、次の経路が意図通りに選ばれるかを確認します。
• SALES_L3 → STORE_DIM → REGION_DIM(地域・店舗関連の質問)
• SALES_L3 → ITEM_DIM(商品・カテゴリ・ブランド関連の質問)
今回の検証は「試す → NGなら直す → 直した状態で次へ進む」という流れで行いました。こうして逐次的に改善しながら、Cortex Analystの挙動を確認しています。
| # | 質問 | 意図 | 初回結果 | SQL生成失敗 | チューニング後 |
|---|---|---|---|---|---|
| 1 | 2024年の地域別売上を教えて | REGION_DIMとのJOIN+GROUP BY | × | × | ⚪︎ |
| 2 | 店舗ごとの売上トップ3を表示して | STORE_DIMとのJOIN+RANK | ⚪︎ | - | - |
| 3 | 2024年に一番売れたブランドは? | ITEM_DIMとのJOIN+SUM+RANK | ⚪︎ | - | - |
| 4 | Kanto地域の2023年と2024年の売上を比較して | REGIONフィルタ+複数年比較 | ⚪︎ | - | - |
| 5 | Dairyカテゴリの商品で一番売れた店舗は? | ITEM_DIMカテゴリ+STORE集計 | ⚪︎ | - | - |
| 6 | 2024年の月ごとの売上推移を地域別に出して | GROUP BY(月×地域) | ⚪︎ | - | - |
| 7 | ブランドごとの売上構成比を出して | ITEM_DIMブランド+比率計算 | ⚪︎ | - | - |
| 8 | 1件あたりの平均売上金額を地域別に出して | 平均計算+REGION別集計 | × | - | ⚪︎ |
| 9 | 2024年の売上が最も多い地域を教えて | REGION別集計+順位付け | ⚪︎ | - | - |
| 10 | 店舗×カテゴリごとの売上クロス集計を出して | STORE_DIM × ITEM_DIM ピボット | × | - | ⚪︎ |
2.3 初回結果NGの考察と対処
質問 1
- 質問:2024年の地域別売上を教えて
- 期待:2024年の地域別売上を集計
- 回答:「提供された表に記載されている以上の情報が必要です」→ NG
対処:セマンティックビューを編集する
- 背景推測:
- 「単年の売上合計」は SALES_L3 内で完結 → 実行可
- 「地域別売上」は REGION_DIM の属性参照が必要 → JOIN は可能
- しかし “売上”に対応する measure 未定義 → 「何を集計?」が解けず 拒否
→ measure を明示(REVENUE)すると、JOIN+集計の両方が解決
- 対処:SALES_L3のmetricに「売上」を定義
- Expression:SUM(PRICE * QUANTITY)
- Synonyms :売上, 売上高
- 結果:期待通りの出力を得られた。
(生成SQLイメージ)
SELECT r.region_name, SUM(s.price * s.quantity) AS revenue
FROM sales_l3 s
JOIN store_dim sd ON s.store_id = sd.store_id
JOIN region_dim r ON sd.region_id = r.region_id
WHERE DATE_PART('YEAR', s.order_date) = 2024
GROUP BY r.region_name;
→ SALES_L3 → STORE_DIM → REGION_DIM の結合経路を自動で辿り、3表をまたいだ集計が実行できた。
質問 8
- 質問:1件あたりの平均売上金額を地域別に出して
- 期待:地域別に SUM(売上) / 明細件数(= AVG(PRICE*QUANTITY))
- 回答:NG(COUNT(DISTINCT ITEM_ID) で割っており「商品数あたり」になっていた)
対処:プロンプトを修正する
- 対処(プロンプト修正):「注文明細件数1件あたり」と分母の粒度を明示
- 結果:期待どおりに出力
質問 10
- 質問:店舗×カテゴリごとの売上クロス集計を出して
- 期待:
| STORE_NAME | Beverage | Snack | Sweets | Meat | Seafood | Vegetable | Fruit | Dairy | Staple | Other | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Store_001 | |||||||||||
| Store_002 | |||||||||||
| Store_003 | |||||||||||
| Store_004 | |||||||||||
| Store_005 |
- 回答:
| STORE | CATEGORY | TOTAL_SALES |
|---|---|---|
| 100 | Beverage | |
| 100 | Snack | |
| 100 | Sweets | |
| 100 | Meat | |
| 100 | Seafood | |
| 100 | Vegetable | |
| 100 | Fruit | |
| 100 | Dairy | |
| 100 | Staple | |
| 100 | Other |
対処1:プロンプトを修正する
- 対処:2024年の売上(PRICE×QUANTITYの合計)を、行=店舗名(STORE_NAME)・列=カテゴリ(CATEGORY) の**ピボット表(横持ち)**で出して。 列順は Beverage, Snack, Sweets, Meat, Seafood, Vegetable, Fruit, Dairy, Staple, Other。 NULLは0で、行合計・列合計も入れて。
- 結果:期待どおりに出力
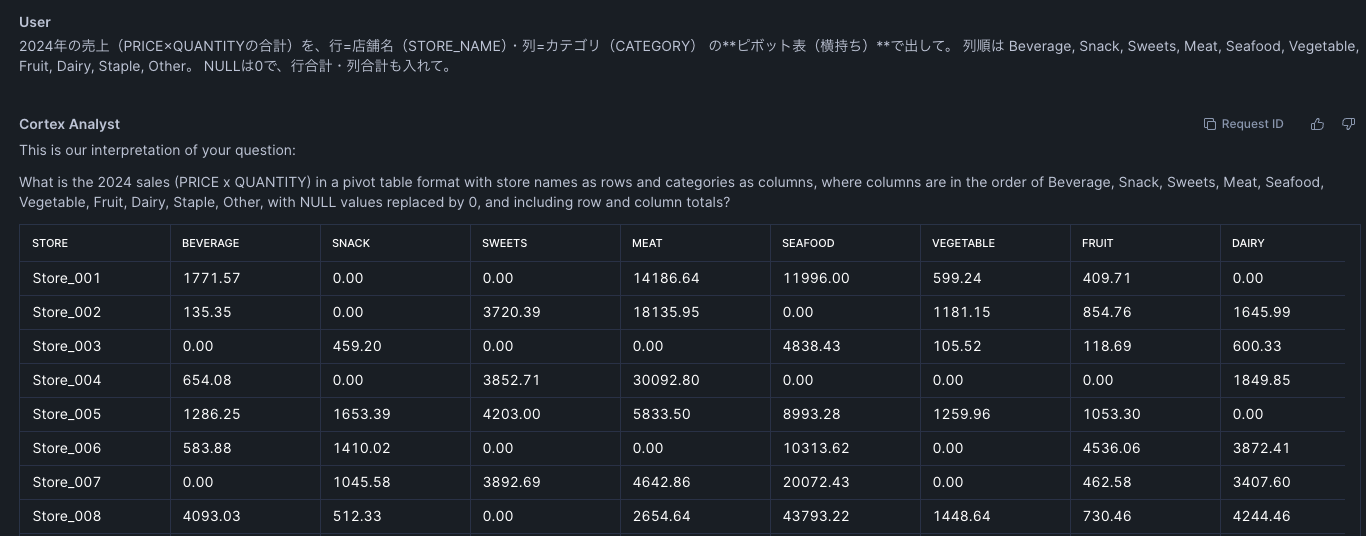
対処2:セマンティックビューを編集する
対処1のような複雑なプロンプトをビジネスユーザが指示することは困難と考えるため、検証済みクエリを設定する
- 対処:検証済みクエリを定義
- 質問:店舗×カテゴリごとの売上クロス集計を出して
- 検証済みクエリ :実行して欲しいクエリ

- 結果:「店舗×カテゴリごとの売上クロス集計を出して」という当初のプロンプトから期待通りの結果を生成できた。
2.4 Level3の評価まとめ
今回のLevel3(複数テーブルJOIN)検証を、以下の3指標で評価しました。
- 初回正答率:7/10(70%)
- 最終正答率:10/10(100%)
- 訂正率:+30%(改善により正答率が向上した割合)
※ #1 は「売上の定義が曖昧」で拒否された、#8 は分母の解釈ミス、#10 は縦持ち出力(ピボット未適用)が主因。
所感(なにが効いたか)
JOIN前提でも十分実用的と考える。一方で、以下はあらかじめ考慮しておくと良い。
- relationshipsを定義 → 結合経路(SALES→STORE→REGION / SALES→ITEM)は安定。
- 粒度の明示(例:「注文明細件数あたり」)で計算の取り違え防止。
- Verified Query(検証済みクエリ)でピボット等の出力体裁を固定(列順/NULL→0/合計列)
まとめ:Cortex Analystは実用的。鍵は定義と運用
Level1〜3の検証から、JOIN 前提でも十分に実務投入可能と判断しました。
一方で本番データは「テーブル数・カラム数が多い」「問いの種類が多様」という現実があります。だからこそ、セマンティックは最小で始めて、運用で育てるのが効くと考えます。
設計の方針(最小で始めて必要なものだけ足す)
- セマンティックに置くもの:恒久的・全社共通の定義
例)REVENUE = PRICE × QUANTITY、YEAR/MONTH、SALES→STORE→REGION の関係 - Verified Queryに置くもの:体裁が重要で毎回同じ形にしたいレポート
例)ピボット、固定のランキング表 - ユーザプロンプトに任せるもの:一時的な条件・粒度・比較軸
例)「Q2だけ」「Kantoだけ」「注文明細件数あたり」など
過剰定義は逆効果。セマンティックを厚くしすぎると、LLMに渡す情報が増えて解釈の曖昧さや性能劣化を招きます。Snowflakeのドキュメントでも、テーブル数や列数の上限を抑える推奨があります(例:10テーブル/50列を超えない設計を目安に)。
出典:Cortex Analystセマンティックビュージェネレーターの使用
運用面での留意点
- Cortex Analystの出力が誤っている場合、ビジネスユーザ自身は気づきにくい可能性があります。そのため、モニタリングやレビューの仕組みが必要ではないでしょうか。
- また、セマンティックモデルを修正して精度を高めたつもりが、別の質問で誤答を招くリスクもあります。つまり「新しい質問への最適化」と「既存質問への互換性維持」を両立させる観点が重要です。
こうした課題に対しては、SnowflakeのAI Observabilityを活用できるのか、今後調査を進めていきたいと考えています。
結論として、薄く始めて、育てる。この方針がCortex Analystを“実用”で回す最短ルートだと感じました。
仲間募集
NTTデータ ソリューション事業本部 では、以下の職種を募集しています。
Snowflake、生成AIを活用したデータ基盤構築/活用支援(Snowflake Data Superheroesとの協働)
Databricks、生成AIを活用したデータ基盤構築/活用支援(Databricks Championとの協働)
プロジェクトマネージャー(データ分析プラットフォームソリューションの企画~開発~導入/生成AI活用)
クラウドを活用したデータ分析プラットフォームの開発(ITアーキテクト/PM/クラウドエンジニア)
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~ TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。