はじめに
はじめまして。NTTデータでデータサイエンティストをしております @shosuke_kondo です。
本記事では、DataRobotで手軽に未来を予測し、Tableauで予測結果を速く簡単に視覚的な形でデータ分析した「携帯キャリアの解約予測に基づくLTV(ライフタイムバリュー)算出による優良顧客分析」の仮想事例をご紹介します。
DataRobotとは
DataRobot社は、人工知能(AI)に対するユニークなコラボレーション型のアプローチであるバリュー・ドリブン AIのリーダーです。
DataRobotは、ビジネスリスクを最小化し、インパクトを最大化するAIを提供します。
当社のAIアプリケーションとプラットフォームは、主要な業務プロセスに統合され、お客様がAIを大規模に開発、運用、管理できるよう支援します。DataRobotは、実務者が予測AIおよび生成AIを提供できるようにし、管理・推進者がAIアセットを保護することを可能にします。
Tableauとは
Tableauは膨大なデータをわかりやすく視覚化する分析プラットフォームであり、Excelでは扱えないような膨大なデータでも、ドラッグアンドドロップなどの簡単な操作で、様々な形式に視覚化することができます。Tableauはその使い勝手と視覚表現の豊富さから多くのユーザに支持されており、世界中の企業・ユーザに利用されています。多種多様なデータを一元的にビジュアル化することを目的に作られているため、多岐にわたるデータソースから情報を抽出・結合させ、分析において必要な項目を任意にグラフへと落とし込める点は特徴として上げられます。
本テーマの全体像
架空の携帯キャリアのマーケティング部門において、顧客のLTVを起点としたマーケティング戦略を立てたいという要望があった際に想定される分析の流れを説明します。LTV算出を行えば、顧客生涯価値が高い優良顧客の特徴が分かるので、その後のアクションとして、マーケティング投資の最適化、顧客維持戦略の強化、商品やサービスの改善、新規顧客獲得戦略の立案、クロスセルとアップセルの機会の特定などがデータドリブンに行えるようになります。
本記事ではDataRobotを使ってLTV予測に必要な解約予測用のAIを素早く作成し、Tableauを使ってLTVの高い顧客の特性を素早く・綺麗に可視化していきます。実際のビジネス案件では、データ準備の前段階で業務要件を整理したり、モデル構築前にモデル精度改善のためのデータ加工、予測前に精度の確認を行う必要がありますが、今回は流れを簡単化しております。前編ではDataRobotを使ってデータ準備・モデル構築・解約予測を行い、後編ではLTVの算出及びTableauを使ったLTVの高い顧客の特性の可視化及び戦略立案を行います。
データ準備
下表のような顧客データを下記のPythonコードで作成しました。今回作成するデータは顧客IDに対して、顧客情報を付加したデータです。様々な切り口から分析できるように、16種類のカラムを作成しました。顧客IDと予測対象カラム(解約)を除いた14種類のカラムから、予測対象カラムである「解約」の値(0,1)を推定します。
| 項目名 | 内容 | 入力値の例 |
|---|---|---|
| 顧客ID | 顧客の一意の識別子 | 11111 |
| 加入日 | サービスに加入した日付 | 2023-07-01 |
| 購入場所 | 顧客が購入した場所 | 大手家電量販店 |
| 性別 | 顧客の性別 | 男性 |
| 年齢 | 顧客の年齢 | 35 |
| 都道府県 | 顧客が住んでいる都道府県 | 東京都 |
| シニア | 顧客がシニアかどうかを示す指標 (1: シニア, 0: シニアでない) | 1 |
| パートナー | 顧客がパートナー(配偶者)を持っているかどうか | はい |
| 扶養家族 | 顧客が扶養家族を持っているかどうか | あり |
| 在職期間 | 顧客が現在の会社で働いている期間(年数) | 10 |
| 契約期間 | 顧客の契約期間 | 1年 |
| 毎月の請求額 | 毎月の請求金額 | 5000.00 |
| 合計請求額 | 合計の請求金額 | 60000.00 |
| 次回も同じブランドを買いたいか | 次回も同じブランドを買いたいと思う頻度 | 高頻度 |
| 契約のきっかけ | 顧客が契約を決めた理由 | 他社に比べて価格が安いため |
| 乗り換え頻度 | 顧客が他のサービスに乗り換える頻度 | 低頻度 |
| 解約 | 1年以内に解約したかどうか (1: 解約した, 0: 解約してない) | 1 |
import numpy as np
import pandas as pd
import random
from faker import Faker
fake = Faker('ja_JP') # 日本語のデータを生成
# データ数を設定
num_records = 90000 # 顧客数
num_years = 3 * 12 # 3年間のデータ:月単位
# 加入日の範囲設定
start_date = pd.Timestamp('2022-01-01')
end_date = pd.Timestamp('2024-12-31')
# 各説明変数の生成
data = {
'顧客ID': [fake.uuid4() for _ in range(num_records)],
'加入日': [fake.date_between_dates(date_start=start_date, date_end=end_date) for _ in range(num_records)],
'購入場所': [random.choice(['大手家電量販店', 'ショッピングモール', '自社ショップ']) for _ in range(num_records)],
'性別': [random.choice(['男性', '女性']) for _ in range(num_records)],
'年齢': [random.randint(18, 80) for _ in range(num_records)],
'都道府県': [fake.prefecture() for _ in range(num_records)],
'シニア': [random.choice([1, 0]) for _ in range(num_records)],
'パートナー': [random.choice(['はい', 'いいえ']) for _ in range(num_records)],
'扶養家族': [random.choice(['あり', 'なし']) for _ in range(num_records)],
'在職期間': [random.randint(1, 40) for _ in range(num_records)],
'契約期間': [random.choice(['1年', '2年', '指定なし']) for _ in range(num_records)],
'毎月の請求額': [round(random.uniform(3000, 10000), 2) for _ in range(num_records)],
'合計請求額': [round(random.uniform(3000, 10000) * num_years, 2) for _ in range(num_records)],
'次回も同じブランドを買いたいか': [random.choice(['高頻度', '中頻度', '低頻度']) for _ in range(num_records)],
'契約のきっかけ': [random.choice(['他社に比べて価格が安いため', '旧キャリアは電波が繋がりにくいため', '割引やキャンペーン目当て', '親族や友人とのキャリア統一', '国際ローミングの利便性']) for _ in range(num_records)],
'乗り換え頻度': [random.choice(['高頻度', '中頻度', '低頻度']) for _ in range(num_records)]
}
# データフレームの生成
df = pd.DataFrame(data)
# 解約フラグを設定する関数
def determine_cancellation(row):
if (row['乗り換え頻度'] == '高頻度' or
row['契約のきっかけ'] in ['他社に比べて価格が安いため', '割引やキャンペーン目当て']):
return 1 if random.random() < 0.6 else 0 # 解約率を60%に設定
elif (row['性別'] == '男性' or
row['都道府県'] in ['千葉県', '埼玉県', '神奈川県', '大阪府', '東京都'] or
row['年齢'] <= 30 or
row['毎月の請求額'] >= 8000):
return 1 if random.random() < 0.3 else 0 # 解約率を30%に設定
else:
return 1 if random.random() < 0.05 else 0 # 解約率を5%に設定
# 解約フラグの設定
df['解約'] = df.apply(determine_cancellation, axis=1)
# 加入日を基準にデータを分割
df['加入日'] = pd.to_datetime(df['加入日'])
train_df = df[(df['加入日'] >= start_date) & (df['加入日'] <= pd.Timestamp('2023-12-31'))]
test_df = df[(df['加入日'] >= pd.Timestamp('2024-01-01')) & (df['加入日'] <= end_date)]
# データをファイルに保存
train_df.to_csv('train_data.csv', index=False)
test_df.to_csv('test_data.csv', index=False)
モデル構築
続いて、DataRobotでのモデル構築手順をご説明します。流れとしては、データセットの登録・確認 → モデリングの設定 → モデリング開始といった流れになっております。
(1)DataRobotにサインインし、最近のアクティビティからユースケースを作成します。ユースケースの名前(解約予測)を設定し、上記プログラムで作成したtrain_data.csvをドラッグ&ドロップして、データセットの登録を行います。


データセットを登録すると探索的データ分析が自動で行われ、特徴量のヒストグラムや欠損値、平均値といったデータセットに関する基礎的な分析結果を見ることが出来ます。


(2)データを登録・確認し終えたら、モデリングを行います。モデリングの流れはデータセットの選択 → モデリング方法の設定 → 追加設定の順で行います
登録したデータセットの右側にある3つの点からモデリングを開始を選択し、遷移先の画面で学習方法やターゲット(目的変数)の設定といったモデリング設定を行います。
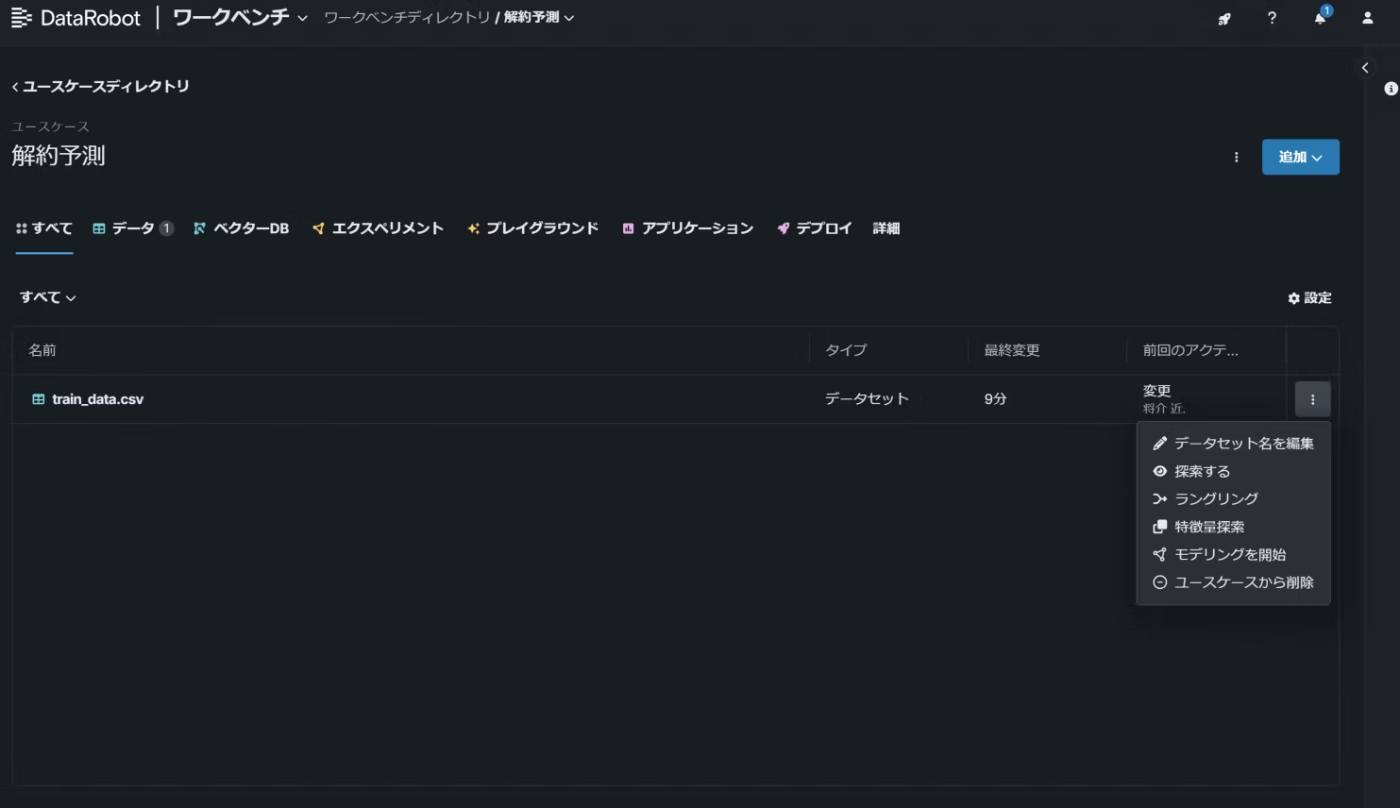

その後パーティションの設定やウェイトの設定などの追加設定を行い、右上のモデリングを開始をクリックします。


(3) 特徴量の解析・加工が終わると、モデルが作成され始めます。

(4)モデル構築が終わると、モデルタブの最上部にデプロイ推奨モデル(複数のアルゴリズムとデータ処理の組み合わせの中で最も精度が高い組み合わせとなったブループリント)が表示されます。説明タブからは予測の根拠などモデルの説明性、パフォーマンスタブからはROC曲線やリフトチャートなどモデルの精度を確認できますが、ここでは省略します。

予測
最も精度が高いデプロイ推奨モデルで予測を行います。モデルのアクション>予測を作成から、下画像の画面に遷移し、データ準備で作成したtest_data.csvをドラッグ&ドロップして予測を実行します。予測が完了したら、予測結果をダウンロードします。

前編まとめ
DataRobotを使って顧客の解約率を予測することで、予測結果のダウンロードまで出来ました。後編では実際にLTV(ライフタイムバリュー)を算出し、セグメントごとに優良顧客を可視化し、マーケティング戦略を考案します。この記事はあくまで、LTV予測~戦略決定の流れの理解を目的としており、途中のビジネス要件の確認やモデル精度向上の取り組み、競合分析などを省略しているため、実際のビジネスでの利用を踏まえるとより詳細の要件確認や公平で深いデータ分析が必要となります。DataRobotやTableauの導入のご相談は是非NTTデータ TCS分野 ソリューション事業本部 デジタルサクセスソリューション事業部 AI&データアナリティクス統括部までお願い致します。拝読ありがとうございました!
後編に続きます。
仲間募集
NTTデータ TC&S分野 では、以下の職種を募集しています。
1. データドリブンDXを推進するデータサイエンティスト
データサイエンティストとして、ビッグデータ/情報処理/AI/BI/統計学などの情報科学を活用したお客様の事業課題解決を支援します。
2. データエンジニア(データ利活用促進に向けたデータモデル/データ加工処理/BI/データカタログの設計開発、生成AI活用:リーダーポジション)
お客様企業のデータドリブンカンパニーへの変革に向けて、データエンジニアリングの知見に基づき、データエンジニア/PMとしてデータレイク、DWH、ETL、BI、AI領域におけるソリューション開発の推進、および、お客様企業のデータ利活用の促進業務を実施します。
3.データマネジメントコンサルタント(データ利活用促進/データマネジメント人材育成/ポリシー策定/生成AI活用)
お客様企業のデータドリブンDXの実現に向けたデータマネジメントプロセスを策定し、高品質かつ安全・安心でありながら、DX施策推進者にとって利便性の高いデータ提供を行うためのあらゆる活動を行います。
4.生成AI領域におけるデータ分析コンサルティング/サービス開発
データサイエンティストとして、深層学習技術をベースとしたNTTデータ独自開発の生成AIサービス「LITRON®Generative Assistant」のサービス開発及びデリバリを行います。生成AIのビジネス適用において、NTTデータは業界をリードすべく取り組んでおり、私たちのチームは、この革新的技術を活用し、Pocから業務適用、定着まで広く顧客を支援し、生成AI分野でのNTTデータの実績を素早く確立することをミッションとしています。
5.アナリティクスエンジニア(CX領域)
お客様企業のCX変革、データドリブンな意思決定実現、ビジネス成果創出のため、アナリティクスエンジニアとしてデータマネジメント、データ利活用を一気通貫/領域横断で支援することで、経営資源としてのデータの価値を引き出す仲間を募集します。お客様の事業・業務・データ活用目的といったビジネス領域の理解をしたうえで、必要となるIT/データ整備を実施することで、お客様と共に成果創出を実現します。
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、Deep Learningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~ TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「Databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
DataRobotは、包括的なAIライフサイクルプラットフォームです。
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。